使用 nflfastpy 和 Plotly 分析和绘制 NFL 数据
使用 nflfastpy 从 NFL 播放数据创建可视化

我是旧金山 49 人队的忠实粉丝,也是数据可视化爱好者,所以我一直在寻找将体育数据与数据科学和分析相结合的机会。对我们来说幸运的是,有一个很棒的 Python 包,叫做 nflfastpy,它是 R 包 nflfastR 的镜像,它允许我们提取逐个播放的 NFL 数据并对其进行分析。在本文中,我将介绍使用 nflfastpy 提取数据并使用 plotly 为传球码和达阵创建两个可视化。
获取播放数据
首先,我们需要确保我们拥有分析所需的包。
pip install pandas plotly nflfastpy现在,让我们导入我们的包并加载 2021-22 NFL 赛季的三个数据集:逐场比赛数据、名单数据和球队信息。
# import packages
import pandas as pd
import plotly.graph_objects as go
import nflfastpy as npy# load data
df_2021 = npy.load_pbp_data(2021)
df_teams = npy.load_roster_data(2021)
df_teams = npy.load_team_logo_data()
我们加载到“df_2021”中的数据具有从 NFL API 获取的极其丰富的逐场比赛数据。举个例子,让我们打印出数据集中的列:
# print columns
df_2021.columns>> Index(['play_id', 'game_id', 'old_game_id', 'home_team', 'away_team',
'season_type', 'week', 'posteam', 'posteam_type', 'defteam',
...
'out_of_bounds', 'home_opening_kickoff', 'qb_epa', 'xyac_epa',
'xyac_mean_yardage', 'xyac_median_yardage', 'xyac_success', 'xyac_fd',
'xpass', 'pass_oe'],
dtype='object', length=372)
每场比赛我们都有 372 个独特的专栏!如此之多,以至于默认情况下它们不会全部打印 – 使用此数据集,您可以进行的分析的可能性基本上是无穷无尽的。在本文中,我们将检查传球码数和达阵数,因此我们必须先使用 `pandas` 进行一些过滤,以使数据帧成为我们想要的形式。
过滤数据以通过播放
首先,当前的逐场比赛数据框包含常规赛和季后赛的所有比赛,因此我们将要过滤到仅来自常规赛的比赛。
# filter to regular season
df_2021 = df_2021[df_2021["season_type"] == "REG"]我们必须处理的下一个微妙之处是过滤掉任何两点转换,因为这些码对整体统计数据没有贡献。对我们来说幸运的是,有一个名为 two_point_attempt 的布尔列,我们可以直接使用它来为我们执行此操作。
# remove two point attempts
df_2021 = df_2021[df_2021["two_point_attempt"] == False]现在,很自然地,由于我们对传球数据感兴趣,我们可以另外过滤到只有传球的比赛。同样,我们有一个名为 play_type 的键,我们可以使用它来过滤以通过播放。希望现在您开始看到 nflfastpy 呈现给我们的高粒度的力量。
# filter to pass plays
df_2021 = df_2021[df_2021["play_type"] == "pass"]我们现在应该有我们分析的所有感兴趣的戏剧。现在,我们需要将过滤后的数据框与花名册和团队数据相结合,以获取我们情节的球员姓名和球队颜色。
获取球员姓名和球队颜色
load_pbp_data(2021) 返回的数据不包含任何玩家姓名,但我们确实有玩家 ID 列。此外,我们为涉及传球、冲球和接球的球员 ID 设置了单独的列,因此我们可以更好地控制从名单表中提取哪些球员姓名。在这种情况下,由于我们正在做传递分析,我们将使用列 passer_player_id。
在我们加载的玩家表中,我们看到我们有以下列:
df_players.columns>> Index(['season', 'team', 'position', 'depth_chart_position', 'jersey_number',
'status', 'full_name', 'first_name', 'last_name', 'birth_date',
'height', 'weight', 'college', 'high_school', 'gsis_id', 'espn_id',
'sportradar_id', 'yahoo_id', 'rotowire_id', 'pff_id', 'pfr_id',
'fantasy_data_id', 'sleeper_id', 'years_exp', 'headshot_url'],
dtype='object')
我们看到我们可以得到感兴趣的玩家的全名。对于玩家 ID,我们将加入 gsis_id 列以获得正确的匹配。
# join with the roster table to get player names
df_2021 = df_2021.merge(df_players[["gsis_id", "full_name"]], left_on="passer_player_id", right_on="gsis_id")为了确保我们的连接有效,让我们检查 `full_name` 的值现在是否存在于我们的原始数据框中。
df_2021["full_name"].unique()>> array(['Ryan Tannehill', 'Kyler Murray', 'Matthias Farley', 'Derek Carr',
'Lamar Jackson', 'Andy Dalton', 'Justin Fields',
'Matthew Stafford', 'Baker Mayfield', 'Patrick Mahomes',
'Tom Brady', 'Dak Prescott', 'Daniel Jones', 'Teddy Bridgewater',
'Jameis Winston', 'Aaron Rodgers', 'Taysom Hill', 'Jordan Love',
'Tyrod Taylor', 'Trevor Lawrence', 'Justin Herbert',
'Ryan Fitzpatrick', 'Taylor Heinicke', 'Mac Jones',
'Tua Tagovailoa', 'Kirk Cousins', 'Joe Burrow', 'Justin Jefferson',
'Zach Wilson', 'Sam Darnold', 'Matt Ryan', 'Jalen Hurts',
'Josh Allen', 'Ben Roethlisberger', 'Carson Wentz',
'Russell Wilson', 'Jared Goff', 'Jimmy Garoppolo', 'Trey Lance',
'Josh Rosen', 'Jacoby Brissett', 'Davis Mills', 'Jacob Eason',
'Greg Ward', "D'Andre Swift", 'Mitchell Trubisky', 'Drew Lock',
'Ty Long', 'Jakobi Meyers', 'Geno Smith', 'Blaine Gabbert',
'Kadarius Toney', 'Mike Glennon', 'Cedrick Wilson',
'Cordarrelle Patterson', 'Case Keenum', 'Dawson Knox',
'Brandon Allen', 'John Wolford', 'Dante Pettis', 'Phillip Walker',
'Tyler Huntley', 'Jack Fox', 'Derrick Henry', 'Chad Henne',
'Kendrick Bourne', 'Mike White', 'Brian Hoyer', 'Tyler Boyd',
'Josh Johnson', 'Jamison Crowder', 'Cooper Rush', 'Rex Burkhead',
'Cole Beasley', 'Gardner Minshew', 'David Blough', 'Chris Boswell',
'Trevor Siemian', 'Leonard Fournette', 'A.J. Brown', 'Colt McCoy',
'Christian Kirk', 'C.J. Beathard', 'Danny Amendola',
'Ezekiel Elliott', 'Albert Wilson', 'Joe Flacco', 'Cam Newton',
'Chris Streveler', 'Mason Rudolph', 'Tommy Townsend',
'Johnny Hekker', 'Tim Boyle', 'Feleipe Franks', 'Blake Gillikin',
'Jarvis Landry', 'Cooper Kupp', 'Andy Lee', 'Keenan Allen',
'Kyle Allen', 'Riley Dixon', 'Deebo Samuel', 'Jake Fromm',
'Nick Mullens', 'Keelan Cole', 'Garrett Gilbert', 'Nick Foles',
'Ian Book', 'Chris Banjo', 'Stefon Diggs', 'Brett Rypien',
'Kendall Hinton', 'Marcus Mariota', 'Mike Gesicki', 'Sean Mannion',
'Kellen Mond', 'David Montgomery', 'Brandon Zylstra',
'Tom Kennedy', 'Courtland Sutton', 'Sam Koch', 'Odell Beckham',
'Travis Kelce', 'Bryan Anger', 'Joe Mixon'], dtype=object)
因此,我们现在拥有与 2021-22 NFL 赛季期间传球相关的所有球员姓名。我们已经完成了大部分工作——我们还希望获得每个球员的球队颜色,这样我们就有一个调色板可以在绘图时使用。为此,我们可以使用我们还加载的团队数据集,其中有一个名为 team_color 的列。就我们将用于加入的键而言,我们可以使用逐场比赛数据中的 postteam 列,该列对应于比赛开始时控球的球队。这是有道理的,因为传球的球队自然是控球的球队。团队表中的对应键是 team_abbr。因此,使用此信息,我们可以加入以提取团队颜色。
# join with team table to get team color for plot
df_2021 = df_2021.merge(df_teams[["team_abbr", "team_color"]], left_on="posteam", right_on="team_abbr")我们现在拥有绘制绘图所需的一切——首先我们必须进行聚合,然后我们可以自由地绘制数据。
Aggregation and plotting
我们想要创建的两个图将是球员传球码数和达阵数的累积运行总和。为了做到这一点,我们必须首先进行聚合——我们当前的表只是一堆个人游戏,但我们希望按周和按玩家获得总数。这是 pandas 中 groupby() 和 agg 的完美用例,我们可以轻松地执行以下操作:
# get total passing yards and touchdowns by week
df_agg = (
df_2021.groupby(["full_name", "team_abbr", "team_color", "week"], as_index=False)
.agg({"passing_yards": "sum", "pass_touchdown": "sum"})
)让我们看看如果我们过滤到特定玩家,我们的桌子会是什么样子:
df_agg[df_agg["full_name"] == "Josh Allen"]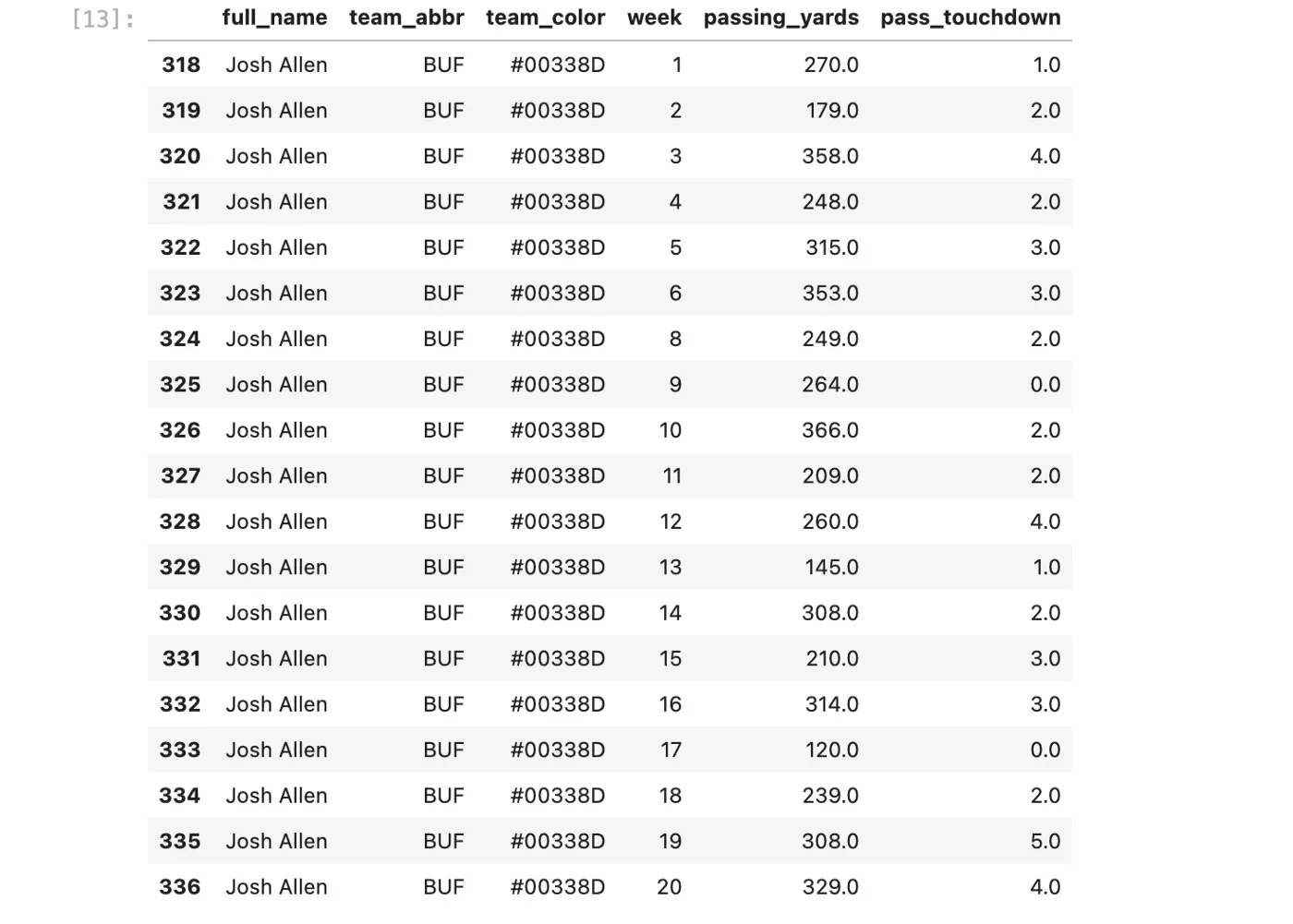
现在我们有了每周的总数(还没有累积,但我们稍后会处理),所以我们可以开始绘图了。
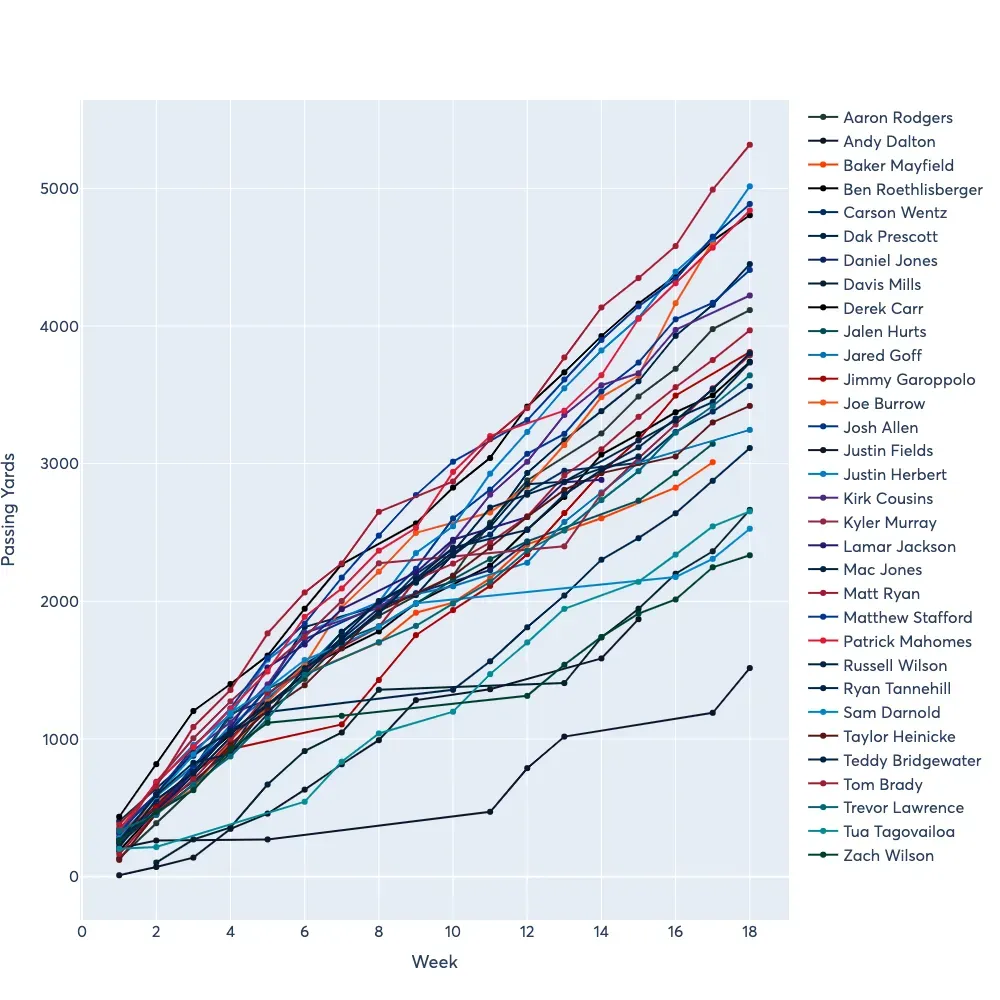
让我们首先绘制传球码图——为了做到这一点,我们将根据球员姓名进行分组,然后将每个单独的组绘制为 plotly 中的新轨迹。我之前有一篇文章更详细地介绍了我们如何获取此代码,因此如果您有任何问题,我会参考该文章。此外,我将只过滤总投掷距离超过 1500 码的球员。通过在绘图时使用 cumsum(),我还将获得我想要的累积总数。
fig = go.Figure()for name, values in df_agg.groupby("full_name"):
if values["passing_yards"].sum() > 1500:
fig.add_trace(
go.Scatter(
x=values["week"],
y=values["passing_yards"].cumsum(),
name=name,
mode="markers+lines",
line_color=values.iloc[0].team_color,
hovertemplate=f"<b>{name}</b><br>%{{y}} yds through week %{{x}}<extra></extra>"
)
)
fig.update_layout(
font_family="Averta, sans-serif",
hoverlabel_font_family="Averta, sans-serif",
xaxis_title_text="Week",
xaxis_title_font_size=18,
xaxis_tickfont_size=16,
yaxis_title_text="Passing Yards",
yaxis_title_font_size=18,
yaxis_tickfont_size=16,
hoverlabel_font_size=16,
legend_font_size=16,
height=1000,
width=1000
)
fig.show()
现在我们可以使用类似的代码来传递达阵并获得累积图。
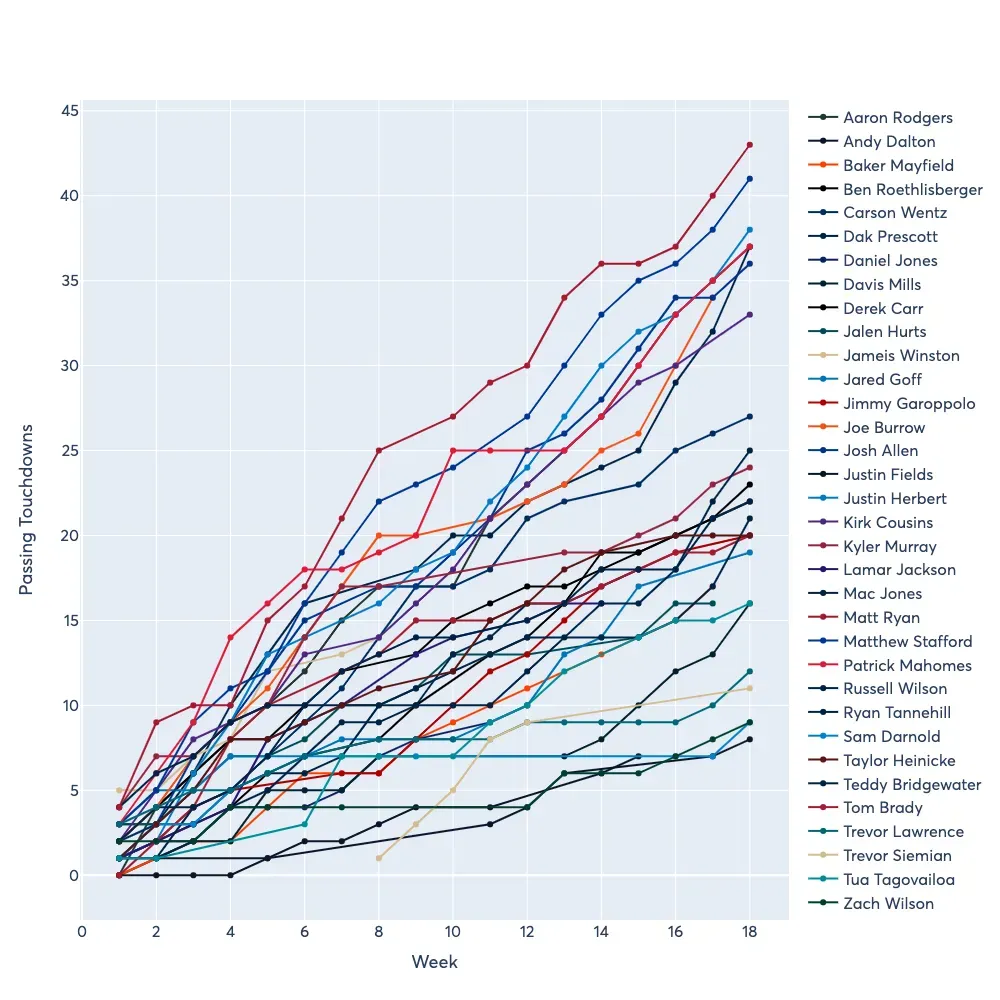
它们就在那里——您可以看到获取 NFL 逐场比赛数据并进行酷炫的数据分析和可视化是多么简单!
如果您想查看我使用 nflfastpy 制作的其他一些信息图表,您可以查看此 GitHub 存储库。[0]
Conclusion
我希望这篇文章有助于介绍如何使用 nflfastpy 处理 NFL 播放数据并进行分析和可视化。用于生成本文中所有代码的笔记本可在此 GitHub 存储库中找到。如果您想了解更多更新,也可以在 Twitter 和 LinkedIn 上关注我。[0][1][2]
References
[1] https://github.com/fantasydatapros/nflfastpy[0]
文章出处登录后可见!