数据漂移可解释性:使用 NannyML 进行可解释的移位检测
提醒有意义的多变量漂移并确保数据质量

模型监控正在成为机器学习的热门趋势。随着有关 MLOps 活动的新月炒作,我们记录了有关该主题的工具和研究的兴起。
其中最有趣的肯定是 NannyML 开发的基于置信度的性能估计 (CBPE) 算法。他们实施了一种新颖的程序来估计未来模型在没有基本事实的情况下的性能下降。它在检测性能下降方面可能会产生很大的优势,因为在实际应用中,标签的收集成本可能很高并且延迟可用。[0][1]
NannyML 包中提供了 CBPE 算法以及一些有趣的移位检测策略。从标准的单变量漂移检测方法到更先进的多变量特征漂移方法,我们拥有一个强大的武器库来自动检测静默模型故障。[0]
在这篇文章中,我们专注于多变量移位检测策略。我们想研究如何检测多变量特征偏移。我们与单变量案例进行比较,以说明为什么后者在某些情况下不足以提醒数据漂移。最后,我们更进一步,引入了一种混合方法来提供可解释的多变量漂移检测。
单变量与多变量漂移
当一个变量在分布上有显着差异时,就会发生单变量漂移。实际上,我们独立监控每个特征并检查其分布是否随时间变化。它可以通过比较新观测值和过去观测值之间的统计数据来直接执行。由于这些原因,单变量检测易于沟通且完全可以理解。
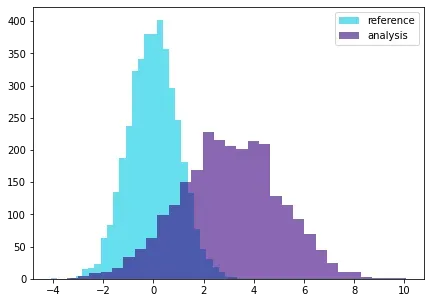
当输入数据之间的关系发生变化时,就会出现多变量漂移。检测多变量变化可能更难以解释,但通常需要克服单变量检测的缺陷。
单变量和多变量漂移背后的原因可能因用例而异。无论是何种应用,单变量特征漂移的结果都可能具有误导性。让我们调查一下原因。
单变量漂移检测的局限性
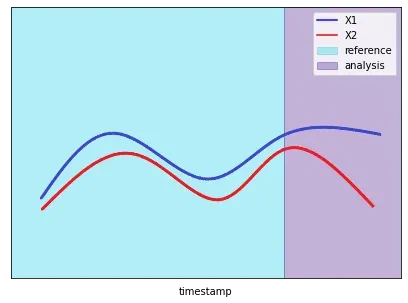
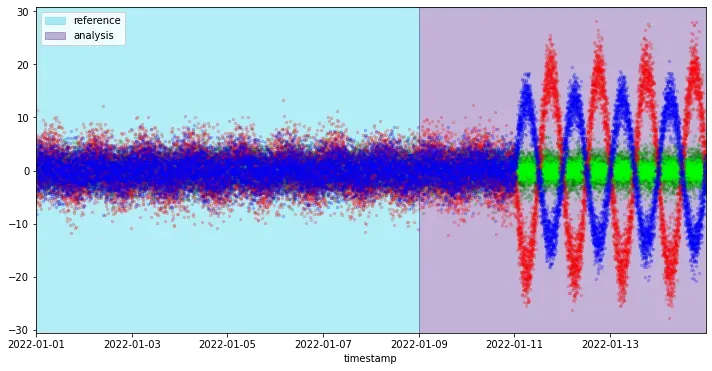
假设我们有四个系列的数据(通过模拟获得):两个相关的正弦曲线和两个随机噪声特征。我们还考虑了两个数据子集(时期)来进行我们的实验。对于“参考”期,我们指的是我们掌握的历史数据。在“分析”期间,我们指的是我们要分析的新样本。
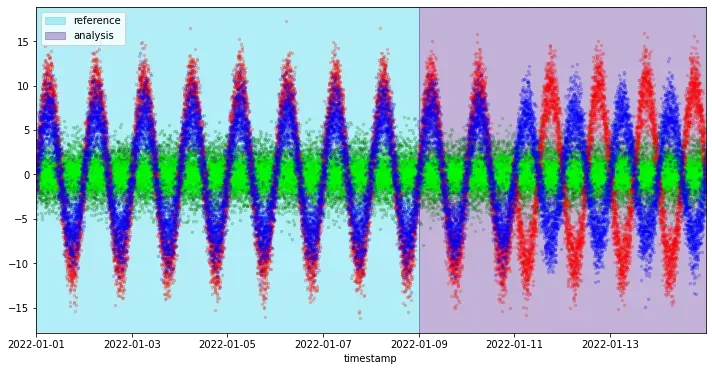
在我们的“参考”期间,数据遵循相同的模式,保持它们之间的关系不变。在“分析”期间,我们观察到蓝色和红色正弦曲线之间关系的变化。更准确地说,这两个特征在“参考”期间呈正相关,而在“分析”期间结束时它们变为负相关。
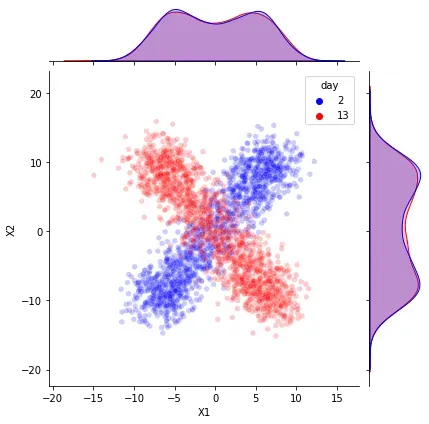
关系发生了变化,但单变量分布保持不变。我们的单变量漂移检测能有效吗?
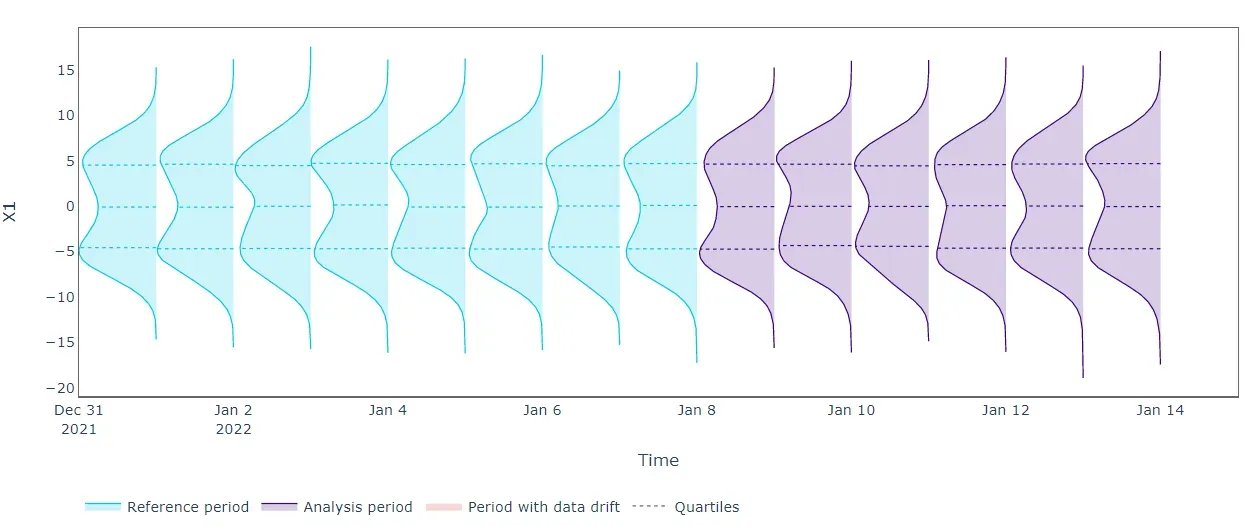
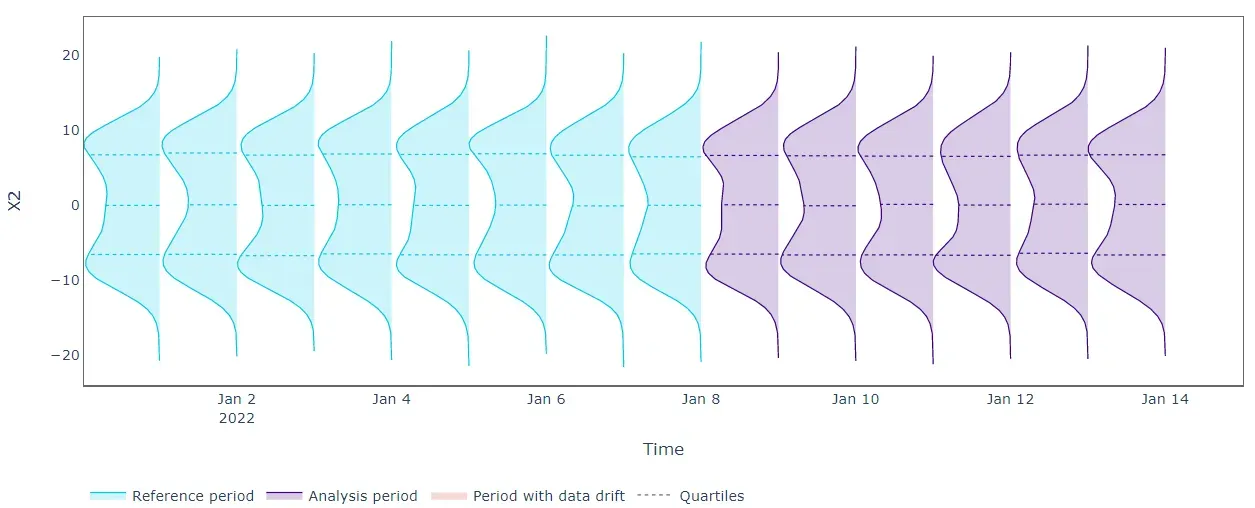
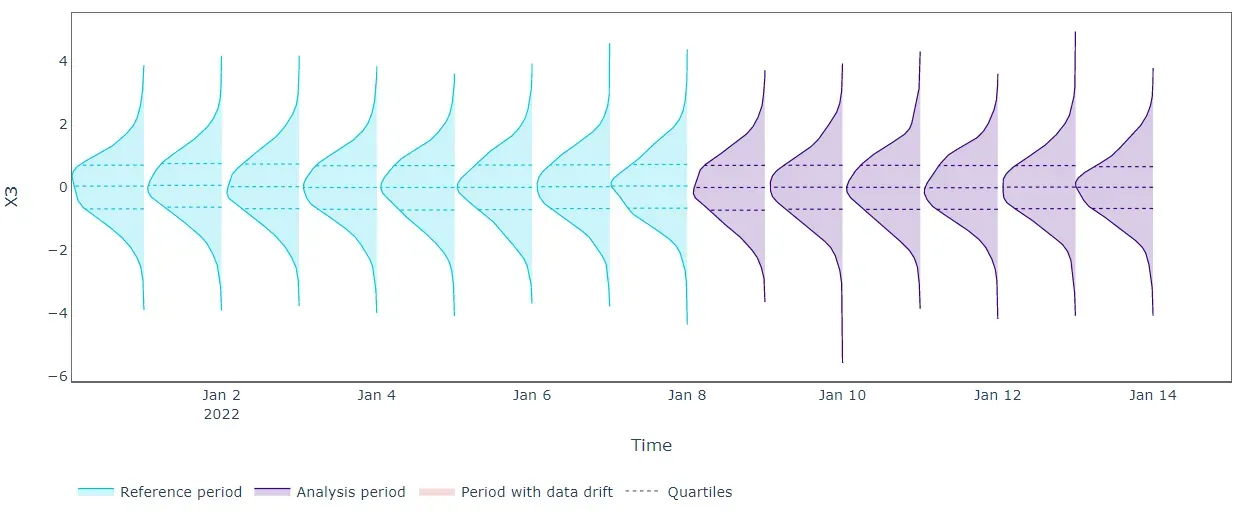
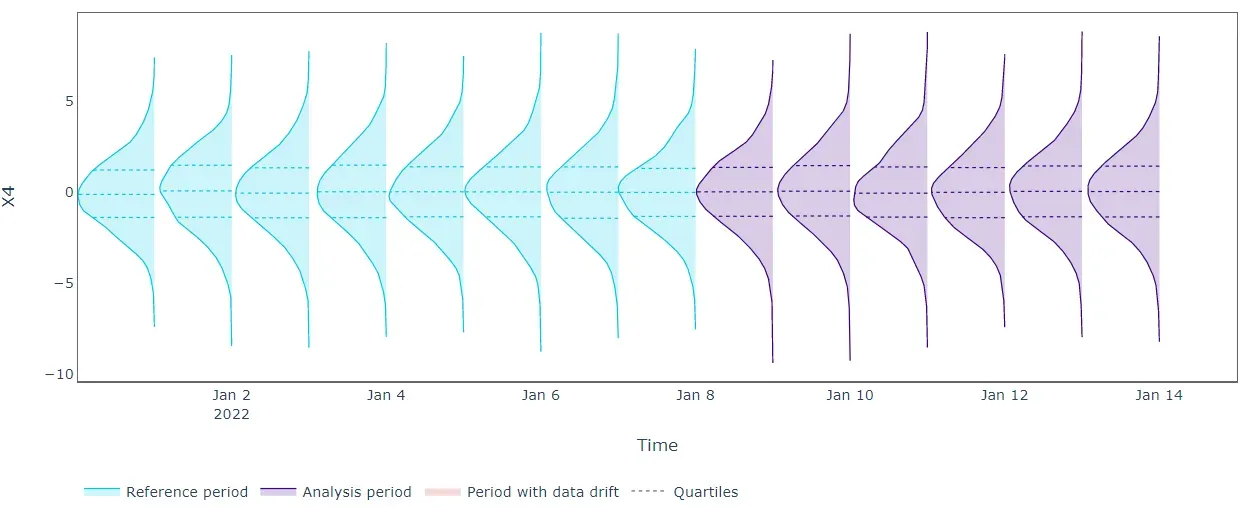
正如预期的那样,单变量数据漂移检测算法并没有揭示所有正在分析的特征的任何漂移。从上图中,我们可以看到单变量分布不会随时间变化,因此 Kolmogorov-Smirnov 检验无法提醒移位。我们需要一种更有效的方法。
使用 PCA 进行多变量特征漂移
每个参加过基础机器学习课程的人都已经接触过主成分分析(PCA)。这是一种对表格数据集进行降维的技术,以保留最显着的交互。同时,我们可以使用 PCA 将压缩数据反转为其原始形状。这种重建过程可以在释放噪声的同时仅保留数据中有意义的模式。
NannyML 利用 PCA 的重建能力开发了一种简单有效的多变量漂移检测方法。[0]
一组数据首先被压缩到较低维度的空间中,然后被解压缩以恢复到原始的特征维度。这个转换过程是重建我们的数据只保留相关交互的关键。此时,可以计算原始数据和转换后的数据之间的一系列重建误差(作为简单的欧几里得距离)。一系列重建误差中的任何有意义的尖峰都可以被视为数据关系的变化,也就是多变量漂移。
让我们看看这种方法在我们的数据上的作用。
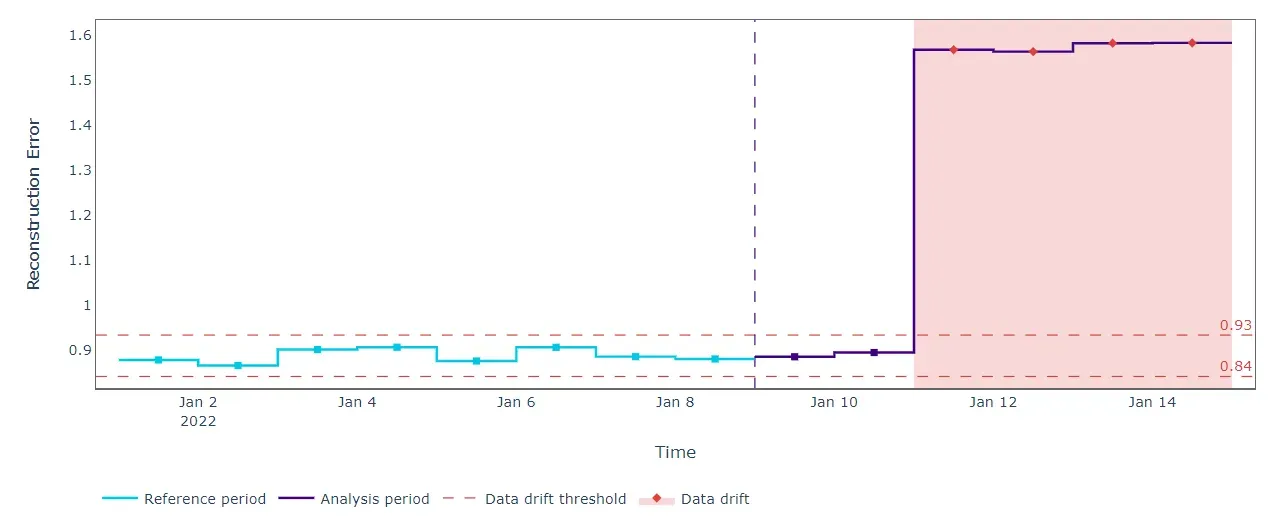
我们在我们的“参考”数据集上拟合 PCA 并计算重建误差。这对于建立用于检测未来“分析”数据变化的上限和下限很有用。当新数据可用时,我们只需使用拟合的 PCA 压缩和重建它们。如果重建错误超出预期阈值,我们应该记录特征关系的变化。这正是我们的数据所发生的事情。
PCA 方法为多变量漂移检测提供了有用的见解。通过一个 KPI,我们可以控制整个系统的状态。同时,分离每个特征的贡献可能会增加价值。
可解释的多元特征漂移
使用 PCA,我们的目标是在一个学习步骤中学习模式。这很好,并且在大多数情况下和一些应用程序中都显示出有效。如果我们的目标是发现特征之间的未知关系,我们可以直接做同样的事情。
我们可以将关系发现想象为一项有监督的任务。换句话说,给定一组特征,我们可以使用它们来相互预测,并使用生成的残差作为漂移的度量。如果残差随着时间的推移而变化,我们会通知一个班次。
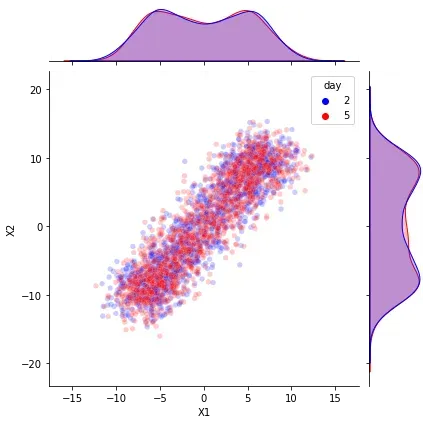
回到我们的模拟场景,我们在“参考”数据上为我们可以使用的每个特征拟合一个模型。每个模型都适合使用所有其他特征作为预测变量来预测所需的特征。然后我们在“参考”和“分析”数据上生成残差。拥有一系列残差,我们可以使用单变量方法检测漂移。
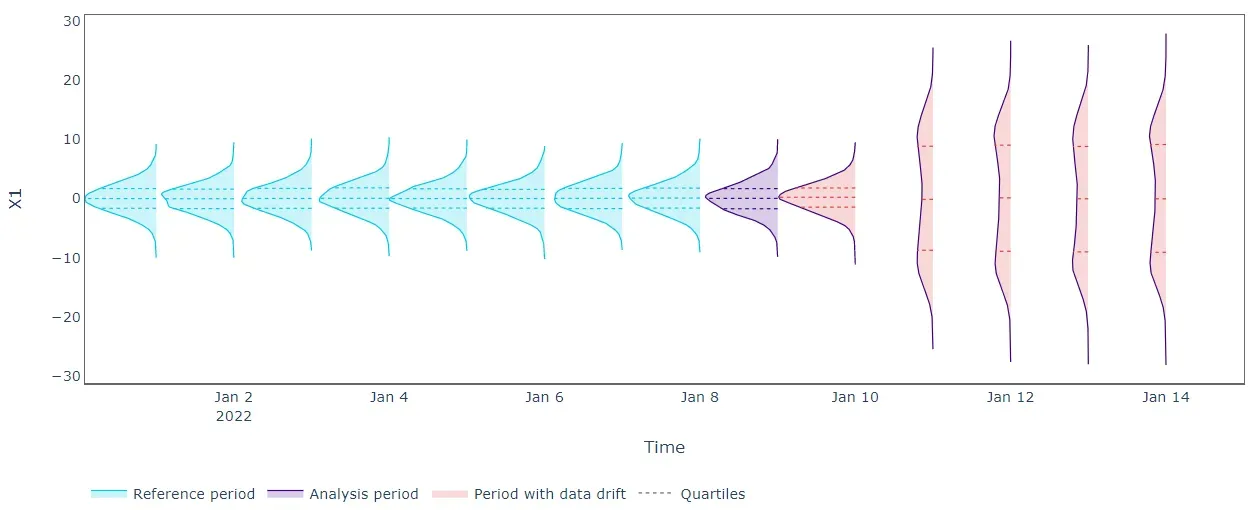
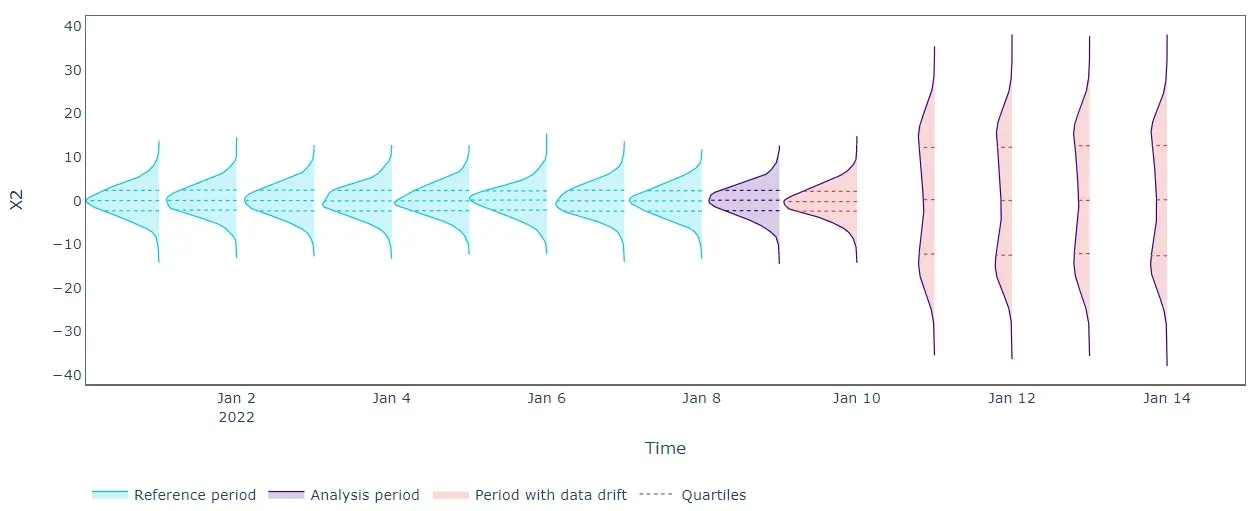
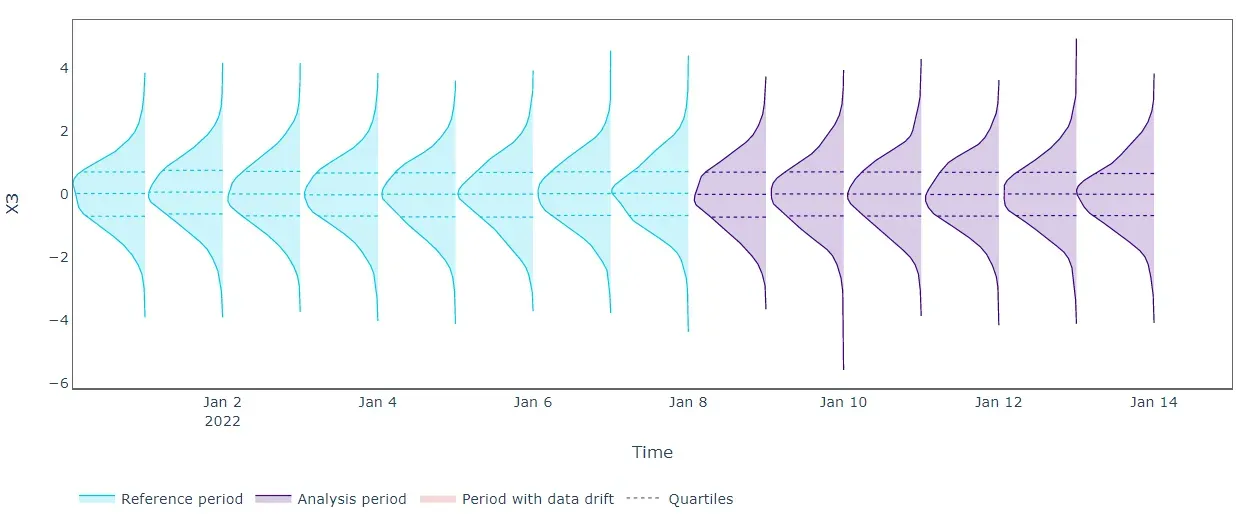
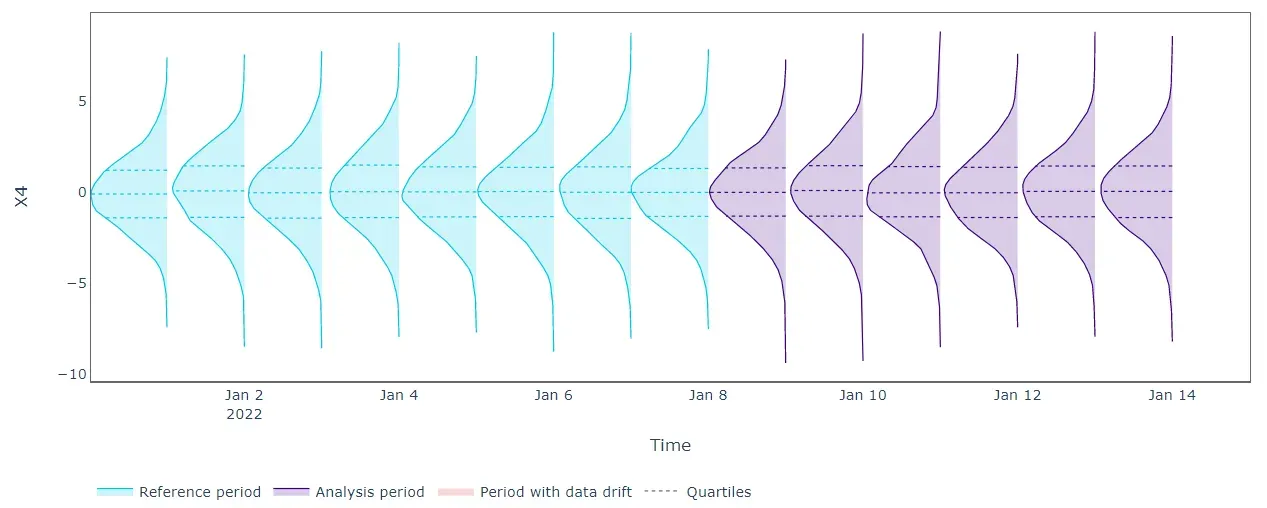
使用单变量方法检测漂移现在更有效。我们在 X1 和 X2 的“分析”期结束时记录了高错误。更准确地说,我们没有证据表明 X1 和 X2 在同一时期存在单变量分布漂移。因此,高错误可能表明 X1 与其余输入数据之间的关系发生了变化(X2 也是如此)。换句话说,单变量重建误差分布的变化可能表明所涉及的特征已经改变了它们的相互作用。
SUMMARY
在这篇文章中,我们介绍了一些可用于有效数据漂移监控的最新技术。我们还了解只有单变量方法会如何以及为什么会受到影响。我们发现了多变量特征偏移的重要性,并试图提供一种可解释的方法来识别可能的多变量漂移的来源。
References
要发现检测静默模型故障的尖端技术,请查看 NannyML 项目:https://github.com/NannyML/nannyml[0]
内容是我自己的,我自己写的,按照我的意愿发布(一如既往)。感谢 NannyML 团队收到的反馈
检查我的 GitHub 存储库[0]
保持联系:领英[0]
文章出处登录后可见!