
Data Cleaning Toolbox
在分析数据之前编译需要注意的方面
在分析中,洞察的质量很大程度上取决于所使用数据的质量。正如众所周知的计算机科学谚语“垃圾进,垃圾出”,对于分析上下文,它可以翻译为“垃圾数据进,垃圾洞察出”。为确保此类垃圾不会污染用于分析的良好数据,需要在开始数据整理或转换过程之前进行一些预处理。[0]
引用维基百科,数据清理/清理是从记录集、表或数据库中检测和纠正(或删除)损坏或不准确记录的过程,是指识别数据的不完整、不正确、不准确或不相关部分,然后替换,修改或删除脏数据或粗数据。消除此过程可能会导致分析中产生不正确、有偏见和误导性的见解。[0]
Data Cleaning Framework
进行数据清理的过程非常简单。
- 检查数据:识别数据质量异常(即不正确、不一致的数据)
- 处理数据异常:以不误导分析的最佳方式修复数据异常。这可以通过删除、转换或插补来完成。
- 验证并报告清洗结果:检查数据质量异常是否从处理中得到修复,并记录过程和结果。
数据清洗要注意哪些方面?
数据清洗本质上是为了对数据进行预处理,使其具有最佳分析质量。因此,在进行数据清洗时,我们应该寻找数据质量的各个方面并对其进行检查。
Accuracy
表示一条信息反映现实的程度。
评估准确性可能特别棘手,因为您可能无法使用数据本身进行评估。例如,您正在评估客户数据,其中包括他们的地址。该地址可能是假地址(完全不存在),或部分是假的(城市或邮政编码存在,但街道名称或建筑物不存在)。为了对此进行评估,您将需要外部数据进行验证,例如 Google 地图坐标。
此外部数据源可能并不总是可用,因此有时您需要依赖您作为数据分析师的领域知识。例如,如果在距离应该是几公里的情况下找到几秒钟的交货时间数据,您有权质疑数据的准确性。
Validity
遵循特定业务规则以特定格式收集信息的程度。
规则可以从数据类型约束(即年龄值的整数)、范围约束(即出生日期不能是未来日期)到正则表达式约束(即电话号码或电子邮件格式)。
虽然这些规则可以在数据输入/收集上实施(并防止额外的数据清理工作),但有时它们无法设置(即出于设计或用户方便的目的)或存在一些后端错误。这包括从各种来源/输入方法收集并在合并时存在有效性错误的数据。
Consistency
检查存储在一个地方的信息是否与存储在其他地方的相关数据相匹配。
一致性可以是数据定义或引用的形式(即一个表中的“客户 ID”数据需要引用组织内其他表中的相同“客户 ID”实体),也可以是度量和格式的单位(即所有每个数据源的日期/时间指的是相同的时区)。
这与有效性高度相关,因为在某些方面可以制定规则来确保数据源的一致性。
Completeness
表示数据满足您对全面性的期望的程度;是否具备所有必要的措施。
这在很大程度上取决于数据收集,一旦丢失数据,可能很难重新填充。当然,我们可以寻找其他数据源,看看那里是否有任何准确的副本,或者可以回去收集(即通过电子邮件发送客户再次填写)。
在数据清洗中,我们需要非常小心地处理完整性,因为它可能会扭曲分析结果并带来误导性的见解。
Uniqueness
检查实体是否是数据集中存在此信息的唯一实例。
检查唯一性也取决于数据上下文。有时需要唯一性(即只能有一个客户拥有这个特定的社会安全号码),但有时也可能无法保持唯一性(即一个电话号码可以列在两个客户下,因为他们属于同一家庭)。我们需要了解上下文以及何时应用此规则。
检查数据异常的工具和技术
Generic data attributes
我们可以首先检查通用数据属性(行数、数据类型)并了解是否有任何问题。具体来说,在 Python 中,我们可以使用 dataframe.info 函数来获取数据集中的可用列、非空计数和数据类型。[0]
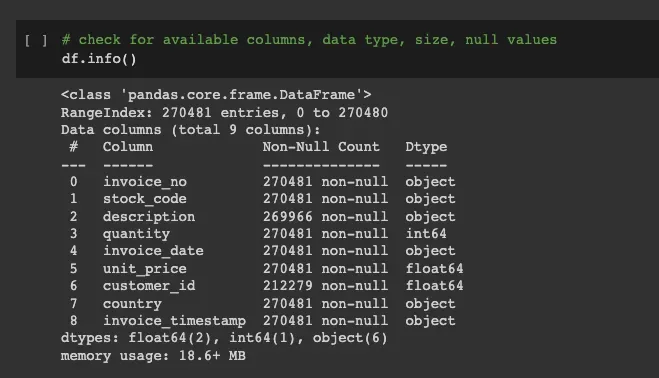
这个函数将帮助我们快速了解我们是否拥有我们需要的所有字段(列名),是否有任何缺失的数据(非空计数),以及数据是否属于预期的数据类型(即项目的数值数量)。
Missing Data
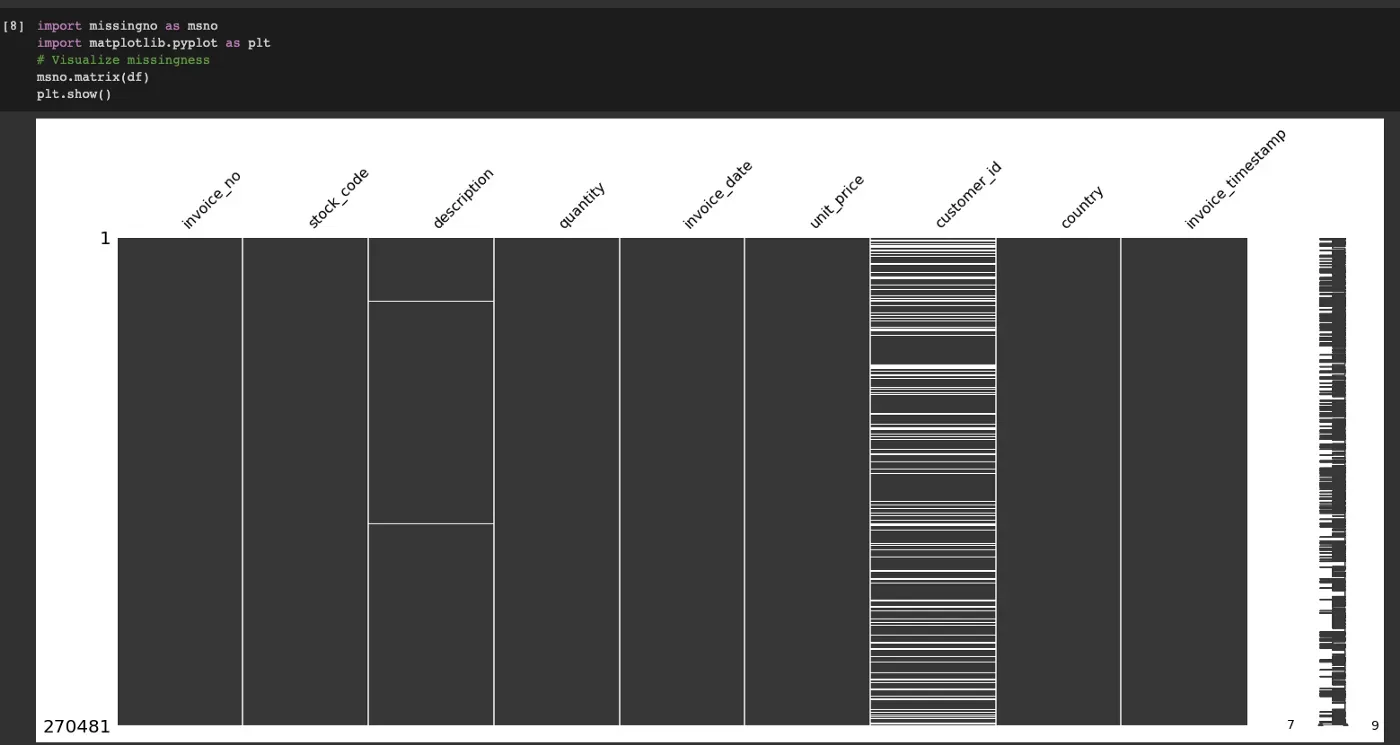
上面的 dataframe info 函数可以为我们提供缺失值的高级概述。为了对缺失数据进行更广泛的评估,我们还可以使用 missingno 库对其进行可视化。[0]
库中的矩阵函数提供了空数据的可视化,让我们了解空数据是如何分布的。我们还可以在可视化之前对数据框进行排序,以检查一列中缺失的数据是否与其他列相关(即,如果空客户 ID 数据都来自特定国家,则可能存在来自该国家的数据收集问题) .
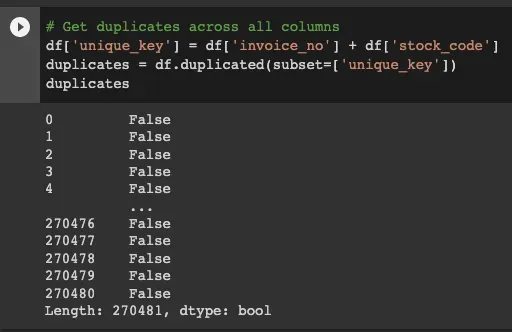
Uniqueness
可以使用 Pandas 中的重复函数来评估唯一性。您可以定义列来检查重复(或让它检查所有列),并且该函数将输出一个布尔值,无论该特定行是否重复。[0]
Range constraints
由于不同的数据字段可以根据上下文处于不同的范围约束中(即出生日期只能是过去的日期值,而计划的约会日期只能是未来的值),可以以各种方式评估范围约束。数据分析师使用他们的领域知识来调整这一点很重要。
为了识别此类问题,我们可以探索数据集的统计分布并对其进行评估。一个常用的函数是 Dataframe.describe() 。该函数提供数据集的描述性统计,包括集中趋势和离散度。[0]
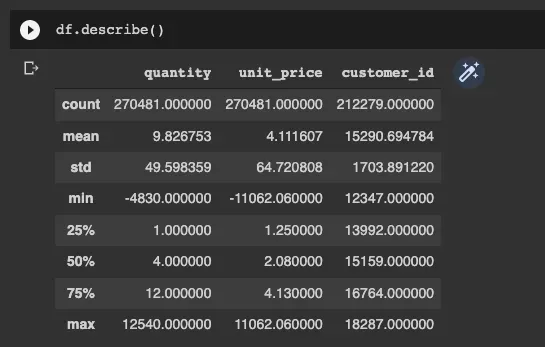
使用 describe 函数,我们可以轻松识别数量和 unit_price 字段的异常最小值,该值低于零。
除了上面的数值描述性统计,我们还可以使用数据可视化来了解数据集分布并识别超出预期数据范围值的分布。可用于此可视化的一个函数是 distplot 。
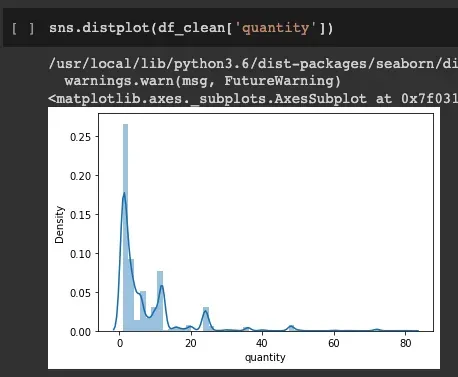
使用分布图,我们可以清楚地看到有些值超出了范围;低于 0。我们还可以看到,与整个数据集相比,低于 0 的值非常低。这对于确定可以采取哪些措施来解决此问题很有用。
Consistency
有各种各样的一致性问题需要不同的工具来检测。
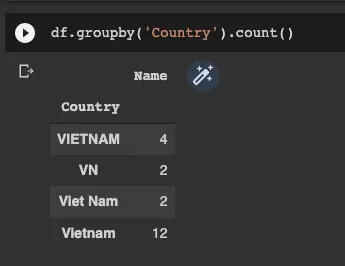
最常见的一致性问题之一是分类标签值不一致。例如在客户国家列中,对于同一个国家越南,我们可以找到不同的值:“Vietnam”、“Viet Nam”、“VN”、“VIETNAM”等。
另一个最重要的一致性问题是格式问题。这可以是日期列(即 DD/MM/YY 与 DDDD/MM/YYY 等)、电话号码(即 +12345678890 与 +1–234–567–8890)或 URL(即 http://hello. com 与 www.hello.com)。[0][1]
为了识别这个问题,我们可以使用 Dataframe.groupby 函数。使用此函数,我们可以探索列中可用的不同值以及相关的值计数。这对于查找需要更新和修复的值很有用。[0]
Treating data anomalies
关于如何处理上面列出的数据异常,没有一个正确的答案。但是有三个主要选项可用于处理这些异常并准备更好的数据进行分析。
1.删除/删除数据
对于任何数据异常问题,我们都可以执行数据删除。在这种处理中,当我们发现它有问题时,我们会丢弃整个观察(即数据集上的整行)。
但是,只有在我们确定要删除的数据不提供信息的情况下才能这样做。不提供信息的可能是数量相对较少(即百万行中的 1 行)、重复值(只需要保留一条记录)或损坏太大(即 90% 的字段值丢失或不准确)。在其他情况下,我们应该在执行数据删除之前考虑其他处理选项。
# dropping the problematic data : description_id is nulldf.dropna(subset = ["description"], inplace=True)
我们可以使用 Dataframe.drop 及其相关函数( dropna 、 drop_duplicates )在 Python 中执行此操作。[0][1][2]
2. Uniformization
统一化主要可以解决数据不一致的问题。为了进行统一,我们需要充分了解数据背景——可用的不一致(即国家案例:“Vietnam”、“Viet Nam”、“VN”、“VIETNAM”)和期望的最终统一结果(即“越南”)。
尽管在大多数情况下,我们需要根据具体情况进行统一化(因为分类变量因一个数据集而异),但仍有一些工具可用于格式化不一致。
- 对于日期/时间:使用 Pandas.to_datetime 以编程方式将具有多种不同格式的数据转换为统一的 DateTime 格式[0]
- 对于电话号码:使用 Python 中的 phonenumbers 库获取标准化的国家代码和国家电话号码[0]
- 对于 URL:自定义函数定义 [示例][0]
3. Replacement/Imputation
可以对具有超出范围值和/或缺失值问题的数据进行替换。特别是对于数值数据类型的缺失值问题,替换可以来自数据集中的指定统计值,我们主要将其称为插补。[0]
为了能够替换数据值,我们需要利用我们作为数据分析师的领域知识。对于超出范围或无效的数据,替换源可以来自数据集之外(即根据城市值更新国家/州值),或在数据集中(即使用出现次数最多的电话号码作为客户电话号码的真实值)。
对于插补,有可以插补到数据集的统计值选项。最重要的方法是在该值中的数据频率与其他值相比明显高并且缺失数据看起来像它的可能性很高时使用众数值。另一种选择是使用中间值。当数据集不是高度偏斜时,我们可以使用平均值/平均值,或者当数据集更偏斜时使用中值。
在工具方面,我们可以使用 Python 中的 scikitlearn.impute 库根据定义的插补类型自动插补数据集。查看 Analytics Vidhya 的这篇文章,了解详细的估算技术。[0][1]
Report and conclude
对数据集进行的任何处理都可能改变数据分析产生的见解。因此,记录所有已识别的质量问题以及针对这些异常情况所做的处理是很重要的。

此报告/文档对以下情况特别有用:
- 改进数据收集过程。我们可以添加业务规则来验证数据输入或评估发现高缺失数据的数据管道。
- 如果将来有任何数据修复可用,请重新进行分析。
由于不正确/标准化的业务流程或数据管道中的谬误,数据异常很常见。由于数据分析师负责从给定的数据集中产生最大的洞察力,因此进行数据清理以确保数据具有最佳分析质量是正确的。
这将通过 (1) 识别可用的异常,(2) 相应地处理它们,以及 (3) 验证/报告清洁过程和结果来完成。
文章出处登录后可见!