Hands-on Tutorials
主动学习:改善数据标记体验的实用方法
使用 doccano 和 modAL 的更智能的人类标记方式

Table of Contents· Human Labeling
· Active Learning
∘ Performance with all observations
∘ Performance with active learning
· Wrapping Up
好的,让我们谈谈在数据科学领域没有那么大的吸引力的一件事:标记你的数据。这是一个痛苦的过程,这可能会导致你在互联网上找到的教程或你加入的训练营中忽视它。然而,它是数据管道中最关键的组件之一,你知道,垃圾进垃圾出。糟糕的标签会导致糟糕的模型和糟糕的生产实践。
最近,一种以数据为中心的机器学习方法将这个想法引发了一个全新的研究领域。
这个故事是一个关于如何执行人类标签的教程。我们将看到这是一项费力的活动,因此稍后我们会寻求替代方案,例如主动学习。主动学习的想法是智能地查询信息最丰富的观察结果,以便您进行标记。
作为主动学习的一个例子,请看下图。有 100 个二维观测值,分为两类:红色和蓝色。主动学习仅查询 13 个观察值,准确率已达到 91%(见右图右下角)。在这种情况下,主动学习的最终决策边界也相当不错。

在这个故事中,为了让自己在主动学习中脱颖而出,我们将使用一个名为 issues.json 的数据集,它有两个键:包含 LaTeX 格式的数学问题的问题键和标签键很快将填充代数、组合学中的一两个类、几何或数论。

请注意,一个问题可以分为多个类别。例如,下面的这个问题被归类为代数和组合。
总共有 181 个不同的问题。目前,这些问题没有任何标签。在这个故事中,我们的主要目标是给他们适当的标签。
Human Labeling
社区一直在为数据标记构建多种工具。对于一般用途和数据类型,我们有 Prodigy、Labelbox 或 Label Studio 等等。但是,我们将使用 doccano,这是一种用于文本分类、序列标记和序列到序列任务的开源文本注释工具。原因是 doccano 是专门为文本数据构建的,所以我们不需要安装通用标签工具有时需要的额外库。我们不需要手动将数据连接到数据库并担心数据安全性。此外,doccano 是免费的,并且具有暗模式功能😄[0][1][2][3]
如果您没有安装 doccano,请立即在终端中使用 pip 命令进行安装。
$ pip install doccano然后,如果您是第一次运行 doccano,请执行以下命令。他们将初始化一个数据库并使用用户名“admin”和密码“pass”创建一个超级用户。您可以随意更改用户名和密码。如果您之前已完成此步骤,则可以跳过此步骤。
$ doccano init$ doccano createuser --username admin --password pass
之后,在本地机器上启动一个网络服务器。
$ doccano webserver --port 8000现在,在另一个终端中,启动任务队列来处理文件上传/下载。
$ doccano task打开http://127.0.0.1:8000/,会跳转到doccano主页。使用您的用户名和密码登录,导入问题.json 文件,然后开始标记![0]
您可以从 doccano 网络服务器导出标记数据并从那里开始工作。让我们将其命名为 questions_labeled.json,稍后将其作为 pandas DataFrame 读取。
正如您可能已经猜到的那样,人工标记需要很长时间。我们需要另一种方法。
Active Learning
我们了解到的一点是,人工标记的成本很高,即使使用您拥有的最复杂的标记工具也是如此。一个原因是观察到的标签太多。那么,如果我们只标记值得的观察结果,那些我们的模型最困惑的观察结果,假设其他观察结果很容易预测,因此没有太多新信息要学习。因此,新的工作流程不是标记所有观察结果,而是:
- 标记一个小的初始观察组以训练模型
- 要求训练好的模型预测未标记的数据
- 根据预测置信度最低的样本(不确定性抽样),确定要从未标记数据中标记哪个新观察值
- 重复直到达到所需的性能
此工作流程称为主动学习。幸运的是,对于第 1 步,我们已经有一些来自 doccano 的标记数据,并且可以从中进行初始化。[0]
这种技术的一个缺点是需要模型,因此需要先预处理数据。但是,您不必实施花哨的预处理或最先进的模型,因为它们仅用于选择需要标记的最佳观察结果,仅此而已。
为了将主动学习与纯人类标签进行比较,我们将对两者拟合相同的模型。主动学习将从 doccano 的 50 个标记观察开始。您将看到主动学习的性能将接近使用更少数据的人工标记。

探索性数据分析提出了一些清洁策略:
- Lowercase all text
- Remove URLs
- 删除所有 LaTeX 数学表达式和渐近线代码块。它们可能会传达有用的信息,但就目前而言,我们不想太先进。[0]
- 删除错误的 LaTeX 语法和停用词
- 处理过滤器和非字母数字字符
- Stemming
上述清洁步骤中的第 3 步是最具挑战性的一步。为此,我们形式化了 4 种类型的数学表达式:
- 单或双美元符号,\$…\$ 或 \$\$…\$\$
- 一对括号 (…)
- 一对支架 […]
- \begin…\end command
为了使用正则表达式匹配 LaTeX 语法,我们使用递归,因为这四种类型中的每一种都可以在其他类型中。该模式相当复杂,如下所示。
equation_pattern = (
r'(?\\)' # negative look-behind to make sure start is not escaped
r'(?:' # start non-capture group for all possible match starts
# group 1, match dollar signs only
# single or double dollar sign enforced by look-arounds
r'((?<!\$)\${1,2}(?!\$))|'
# group 2, match escaped parenthesis
r'(\\\()|'
# group 3, match escaped bracket
r'(\\\[)|'
# group 4, match begin equation
r'(\\begin)'
r')'
# if group 1 was start
r'(?(1)'
# non greedy match everything in between
# group 1 matches do not support recursion
r'(.*?)(?<!\\)'
# match ending double or single dollar signs
r'(?<!\$)\1(?!\$)|'
# else
r'(?:'
# greedily and recursively match everything in between
# groups 2, 3 and 4 support recursion
r'(.*(?R)?.*)(?<!\\)'
r'(?:'
# if group 2 was start, escaped parenthesis is end
r'(?(2)\\\)|'
# if group 3 was start, escaped bracket is end
r'(?(3)\\\]|'
# else group 4 was start, match end equation
r'\\end'
r')'
r'))))'
)</code这同样适用于渐近线模式。
asymptote_pattern = (
r'(?\\)' # negative look-behind to make sure start is not escaped
r'(?:' # start non-capture group for all possible match starts
# group 1, match begin asymptote
r'(\[asy\])'
r')'
# if group 1 was start
r'(?(1)'
# non greedy match everything in between
# group 1 matches do not support recursion
r'(.*?)(?<!\\)'
# match ending asymptote
r'\[/asy\]'
r')'
)</code现在,是清洁时间!
def preprocess_problem(x, lower=True, stem=True):
# lowercase all
if lower:
x = x.lower()
x = re.sub(r'http\S+', '', x) # remove URLs
x = x.replace('$$$', '$$ $') # separate triple dollars
x = x.replace('\n', ' ') # remove new lines
x = re.sub(equation_pattern, '', x) # remove math expressions
x = re.sub(asymptote_pattern, '', x) # remove asymptote
# remove erroneous LaTeX syntax and stopwords
x = x.replace('\\', ' \\')
temp = []
for word in x.split():
if not word.startswith('\\') and not word in stopwords:
temp.append(word)
x = ' '.join(temp)
x = re.sub(r'([-;.,!?<=>])', r' \1 ', x) # separate filters from words
x = re.sub('[^A-Za-z0-9]+', ' ', x) # remove non-alphanumeric chars
# stemming
if stem:
x = ' '.join(porter.stem(word) for word in x.split())
return x
df['token'] = df['problem'].apply(preprocess_problem)我们可以查询一些标签和令牌,看看从给定令牌中猜测标签是否有意义。
np.random.seed(42)
idx = np.random.choice(range(len(df.head(n))), size=5, replace=False)
for i in idx:
print(df.iloc[i]['tags'])
print(df.iloc[i]['token'], end='\n\n')['number theory']
let let let product element prove nanang susyanto jogjakarta['combinatorics', 'number theory']
determin proof number permut valu fix valu integ multipl['algebra']
let real number ration number prove integ['combinatorics', 'geometry']
hall castl regular hexagon side length 6 meter floor hall tile equilater triangular tile side length 50 centimet tile divid three congruent triangl altitud orthocent see below small triangl color tile differ color two tile ident color mani color least requir tile s pattern is['geometry']
given triangl right angl show diamet incent
正如我们在上面看到的,从令牌中猜测标签是合理的。例如,如果一个标记包含“triangl”或“incircl”,则其中一个标签很可能是“geometry”。
主动学习的策略类似于您进行通常的机器学习建模:将数据集拆分为训练和测试,在训练数据集上训练模型,并在测试数据集上寻找性能。训练和测试数据集是根据标记的观察结果构建的。如果您目前没有这些,请先标记一小部分观察结果。未标记的观察结果将由人类标记(不是全部,只有您的模型最容易混淆的一些)并包含在我们所谓的池数据集中。
X, y = df.loc[:n-1, 'token'], df.loc[:n-1, 'tags']
X_init, X_test, y_init, y_test, idx_init, idx_test = \
train_test_split(X.values, y, y.index, test_size=0.9, random_state=42)
X_pool = df.loc[n:, 'token'].values
unlabeled_prob = df.loc[n:, 'problem'].values将标签转换为 4 个二进制列,依次代表代数、组合、几何和数论。
mlb = MultiLabelBinarizer()
y_init = mlb.fit_transform(y_init)
y_test = mlb.transform(y_test)
classes = mlb.classes_
print('Classes:', classes)Classes: ['algebra' 'combinatorics' 'geometry' 'number theory']对于模型管道,我们将首先将文本特征提取到 TF-IDF 矩阵中,然后使用具有平衡类权重的逻辑回归(以解决类不平衡问题)。该模型将在 One-Vs-The-Rest 的多类设置中进行训练。
clf = make_pipeline(
TfidfVectorizer(),
OneVsRestClassifier(
LogisticRegression(class_weight='balanced', random_state=42)
)
)然后,创建下面的 calc_score 函数来计算模型在加权精度、召回率和 f1 分数方面的性能。
def calc_score(model, X_test):
y_pred = model.predict(X_test)
metrics = precision_recall_fscore_support(y_test, y_pred, average='weighted')
performance = {
'precision': '{:0.2f}'.format(metrics[0]),
'recall': '{:0.2f}'.format(metrics[1]),
'f1': '{:0.2f}'.format(metrics[2])
}
return performance所有观察结果的表现
首先,让我们使用来自 doccano 标记过程输出的所有观察结果来查看模型的性能。请记住,我们希望以后主动学习者的表现会使用更少的数据来接近这个表现。
# split data
V_train = df.loc[~df.index.isin(idx_test), 'token'].values
V_test = df.loc[idx_test, 'token'].values
w_train = df_ori.loc[~df_ori.index.isin(idx_test), 'tags']
w_test = df_ori.loc[idx_test, 'tags']
# tranform tags
binarizer = MultiLabelBinarizer()
w_train = binarizer.fit_transform(w_train)
w_test = binarizer.transform(w_test)
# calculate performance score
clf.fit(V_train, w_train)
calc_score(clf, V_test){'precision': '0.87', 'recall': '0.83', 'f1': '0.84'}主动学习的表现
对于这个,使用 min_confidence 将分类器包装在 ActiveLearner 模型中,以实现多标签查询策略。
learner = ActiveLearner(
estimator=clf,
query_strategy=min_confidence,
X_training=X_init, y_training=y_init
)让我们训练模型,看看它在精度、召回率和 f1 分数方面的表现。
learner.fit(X_init, y_init)
score = calc_score(learner, X_test)
score{'precision': '0.29', 'recall': '0.19', 'f1': '0.19'}正如预期的那样,该模型最初的表现非常糟糕。主动学习一次从池数据集中查询一个观察结果,人工标记观察结果(使用 python 中的 input() 函数),然后主动学习用新观察结果的额外知识教授模型。
查询完成后,查询的观察是模型最不确定它属于哪个标签的观察。如果模型性能已经足够好,可以停止该过程。具体来说,让我们一一查询 90 个观测值。
scores = defaultdict(list)
for key, value in score.items():
scores[key].append(value)
n_queries = 90
for i in range(n_queries):
# learn
query_idx, query_inst = learner.query(X_pool)
print('Available tags:', classes, end='\n\n')
print(unlabeled_prob[query_idx].item(0))
y_new = [int(item) for item in input('Give tags in binary format: ').split()]
y_new = np.array(y_new, dtype=int).reshape(1, -1)
X_pool = np.delete(X_pool, query_idx, axis=0)
unlabeled_prob = np.delete(unlabeled_prob, query_idx, axis=0)
learner.teach(query_inst, y_new)
score = calc_score(learner, X_test)
# plot
display.clear_output()
fig, ax = plt.subplots(3, 1, sharex=True, figsize=(10,10))
fig.suptitle('Active Learning Scores')
for j, (key, value) in enumerate(score.items()):
scores[key].append(value)
ax[j].plot(range(i+2), scores[key])
ax[j].set_title(key)
plt.xlabel('Number of query')
plt.tight_layout()
plt.show()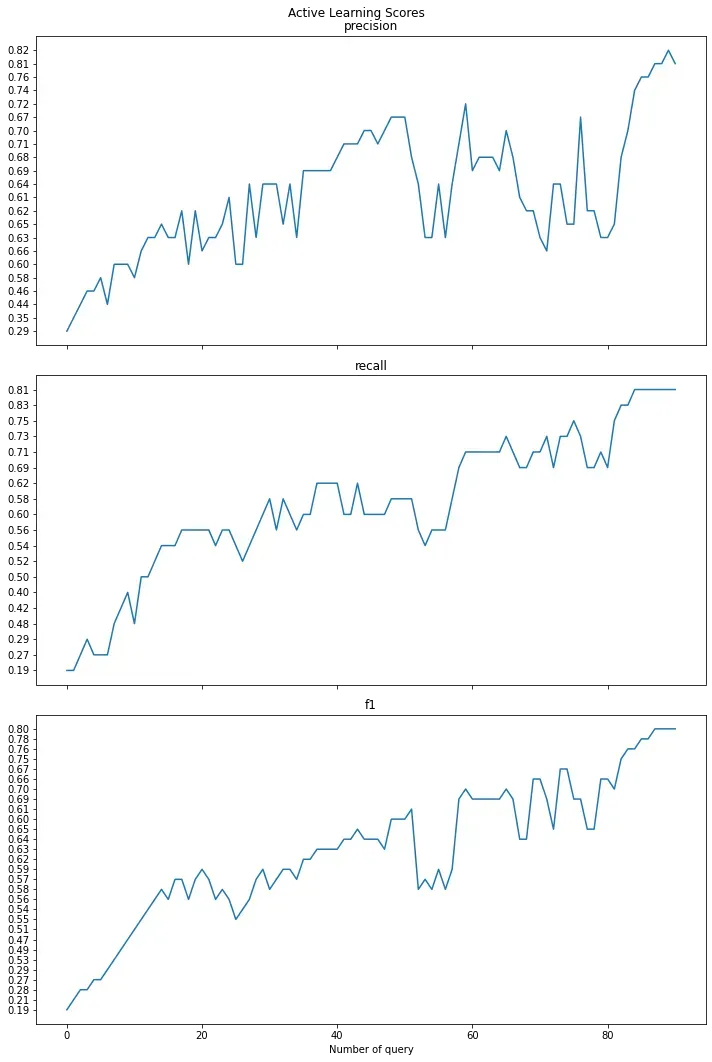
Scores after active learning
============================
precision: 0.81
recall: 0.81
f1: 0.80通过仅使用所有观察值的 70%,我们看到所有分数从 0.2-0.3 显着提高到 0.8。使用所有观察值,这接近同一模型的 0.83-0.87 分数。来自 X_pool 的标记观察结果附加到 X_init 中,未标记的观察结果保留在 X_pool 中。让我们保存所有这些以备将来使用。
np.save('X_init.npy', X_init)
np.save('X_pool.npy', X_pool)
np.save('X_test.npy', X_test)
np.save('y_init.npy', y_init)
np.save('y_test.npy', y_test)Wrapping Up
主动学习是一种数据标记方法,其中模型应用于小型手工标记数据集,以查询模型最不自信的未标记数据点。因此,主动学习为标记者提供了一种选择值得标记的数据点的方法,从而节省了大量时间。在这个故事中,我们看到主动学习应用于多标签分类任务。我们只使用了所有数据点的 70%,从而获得了高质量的标签。
🔥 谢谢!如果您喜欢这个故事并想支持我作为作家,请考虑成为会员。每月只需 5 美元,您就可以无限制地访问 Medium 上的所有故事。如果您使用我的链接注册,我将赚取少量佣金。[0]
📧 如果您是我推荐的 Medium 成员之一,请随时通过 geoclid.members[at]gmail.com 给我发送电子邮件,以获取此故事的完整 Python 代码。[0]

您可能想继续阅读这些相关故事:
Albers Uzila[0]
MLOps Megaproject
View list4 stories


文章出处登录后可见!