前馈神经网络示例(神经网络系列)——第 2 部分
本文将构建到本系列的前一部分。我们将介绍前馈神经网络 (FF-NN),重点讨论由 NN 完成的计算。
该系列的上一部分:神经网络基础(神经网络系列)- 第 1 部分[0]
神经网络设计(回顾)
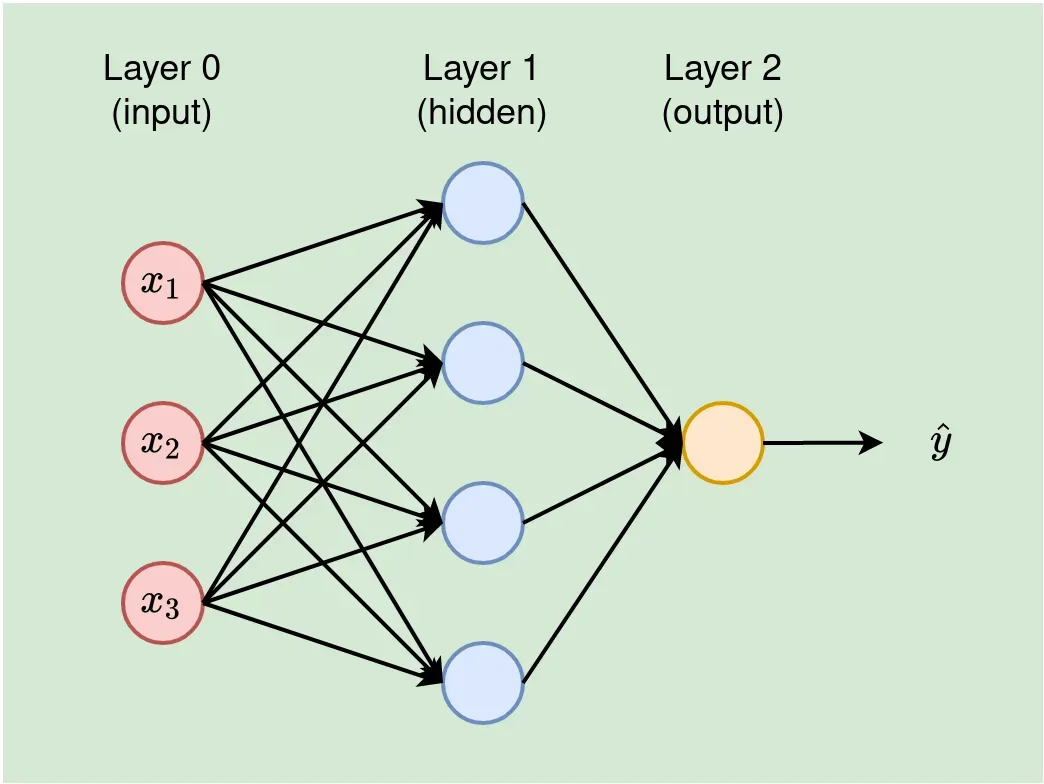
神经网络是一个由许多神经元堆叠成层组成的系统。第一层,输入层(我们将其称为第 0 层)除了传递输入值外不执行任何计算。因此,在计算 NN 中的层数时,我们会忽略输入层。因此,下面的图 1 是一个 2 层网络。
输出层计算网络的最终输出。输入层和输出层之间的层称为隐藏层。下面图 1 中的 NN 被描述为 3-4-1 网络,输入层有 3 个单元,输入层有 4 个单元,输出为一值。
NN 中的层数决定了网络的深度。基于此,具有许多隐藏层的 NN 被称为深度神经网络 (DNN)。
NN 的设计由层数和每层中的神经元数来解释,通常被称为 NN 的体系结构。在本系列中,我们交替使用这些术语(NN 设计和 NN 架构)。
前馈神经网络 (FF-NN)
前馈网络,也称为前向传递,逼近一些函数
y=f(x|θ) 用于输入值 x 和已知输出 y。网络学习 θ 中最近似函数 f 的参数,以建立良好的映射 ŷ=f(x|θ)。 ŷ 是模型的预测。在 NN 中,w, b ∈ θ — 即我们在模型训练期间优化的参数是 2 个权重 (w) 和偏差 (b)。
前馈神经网络的关键特征——前馈网络允许信息仅在一个方向上流动(无反馈回路或连接)。
定义:多层感知器(MLP)
MLP 是前馈神经网络的一个特例。在 MLP 中,所有节点都是密集连接的,即每个神经元/节点都连接到前一层的所有节点。实际上,图 1 中的 NN 是一个多层感知器。
前馈神经网络 (FF-NN) — 示例
本节将展示如何执行 FF-NN 完成的计算。本节要掌握的基本概念是描述不同参数和变量的符号,以及如何进行实际计算。我们将使用图 1 所示的 NN 架构。
1. 架构和符号
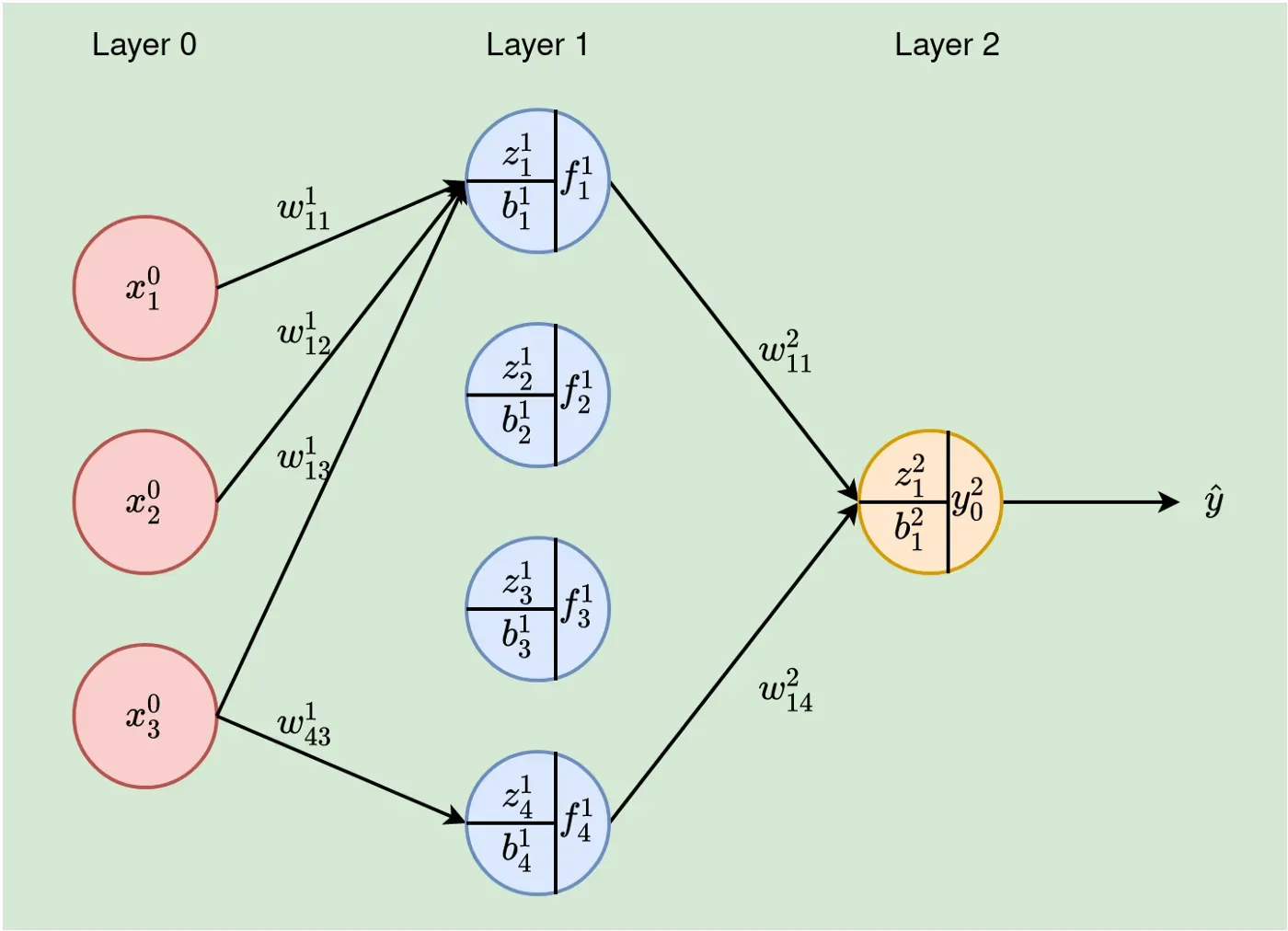
让我们重新绘制图 1 以显示 NN 的基本变量和参数。请注意,在此图中(下图 2),节点之间的其他连接被消除,只是为了使绘图不那么混乱;否则,这个 NN 是一个多层感知器(任何两个相邻层中的所有节点都是互连的)。
where:
- x⁰ᵢ — iᵗʰ 输入值。输入层(第 0 层)的特征 i 的值,
- wˡⱼᵢ — 权重来自第 l-1 层的神经元 i 到当前层 l 的神经元 j,
- fˡⱼ — 第 l 层中单元 j 的输出。这成为下一层(第 l+1 层)中单元的输入,
- zˡⱼ — l 层 jᵗʰ 神经元的加权输入,
- bˡⱼ — 第 l 层 jᵗʰ 神经元的偏差,
- nˡ – 第 l 层的神经元数量,
- fˡⱼ = gˡ(zˡⱼ+bˡⱼ) — gˡ是第l层的激活函数。与往常一样,我们将对给定层中的所有神经元应用一个激活函数,因此,我们不需要为每个神经元指定激活函数,因此 g 没有下标。
- l — 给定层。对于,l =0, 1, …, L。在我们的例子中,神经网络为 2 层,因此 L=2(记住我们说过我们不计算输入层)
以下是解释参数和变量的一些示例:
- x⁰₂ — 第二个输入值,
- w¹₄₃ — 从第 0 层神经元 3 到第 1 层神经元 4 的连接权重,
- z¹₃ — 第 1 层中单元 3 的加权输入,
- g¹(z¹₃) — 在 z¹₃ 上应用激活函数 g¹。
- 每层的单元数——输入层为 3 个单元(n⁰=3),隐藏层有 4 个单元(n¹=4),最后一层为一个神经元(n²=1),以及
- b²₁ — 第 2 层(在我们的例子中为输出层)中神经元 1 的偏差。
2. The Data
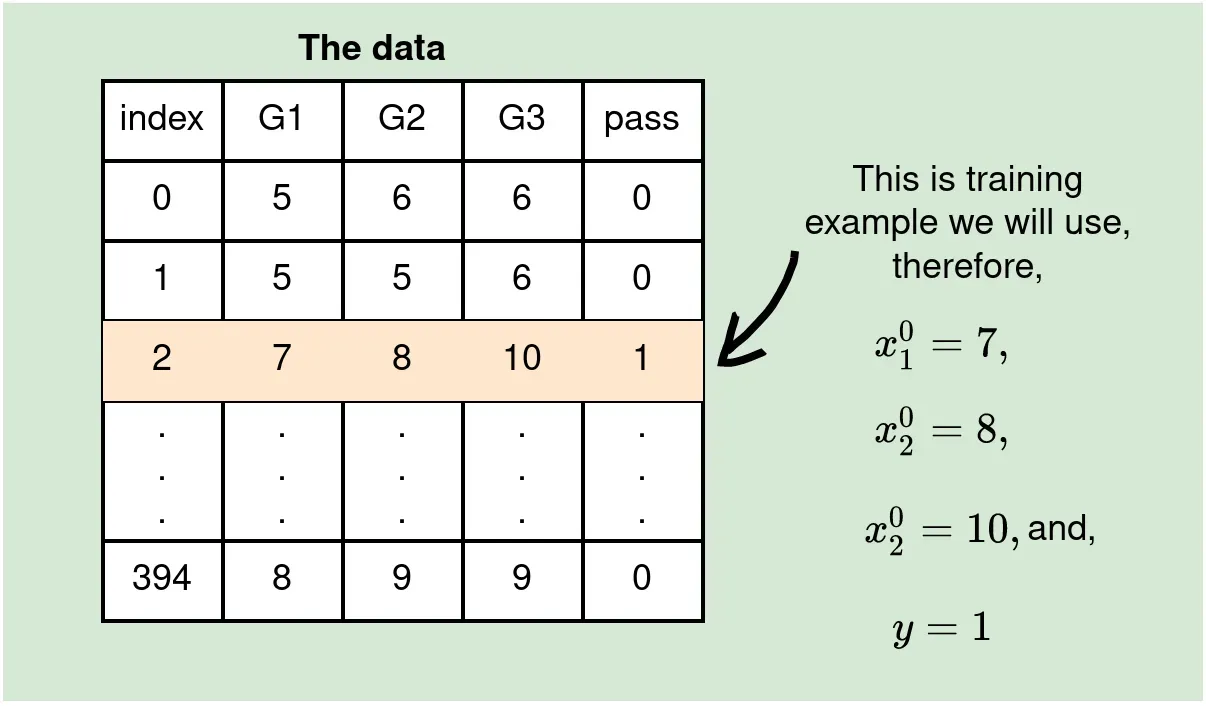
我们将在本例中使用的数据包含 3 个特征 G1、G2 和 G2(这是我们在架构的输入层中选择 3 个神经元的原因,顺便说一下)和一个目标,通过(我们将其称为 y ) 分别为 0 或 1 表示失败和通过。这意味着我们正在处理一个二元分类问题。
原始数据包含 30 个特征和 395 行(数据点),但我们将仅使用这 3 个特征来有效地显示必要的计算。我们将在本系列的后面处理整个数据集。[0]
同样,为了使概念易于掌握,我们将展示如何在单个 Forward Pass 中通过网络传递单个数据点(训练示例)。
3. Parameter Initialization
我们将使用 0 和 1 之间的值随机初始化权重,而偏差将始终使用 0 初始化。我们将在本系列后面讨论更多关于此的内容,请记住,权重最好初始化为 0-1,但不是零,和偏差最好在开始时保持为 0。
4. 隐藏层神经元的计算
对于隐藏层中的第一个神经元,我们需要计算 f1₁,这意味着我们需要三个权重 w1₁₁、w1₁2 和 w1₁₃ 的初始值。
让我们将它们初始化为 w¹₁₁=0.3、w¹₁₂=0.8 和 w¹₁₃=0.62。如前所述,我们将设置偏差 b¹₁=0。让我们介绍一个称为 Rectified Linear Unit (ReLU) 的激活函数,我们将其用作函数 g¹(这只是一个任意选择)。如前所述,稍后我们将讨论更多关于激活函数的信息,但现在,我们可以定义 ReLU 并使用它。
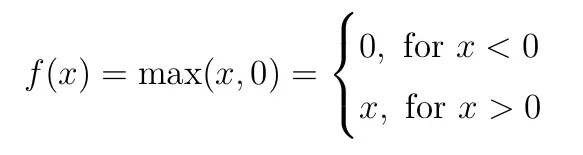
Therefore,

你可以用同样的方法计算 f¹₂、f¹₃ 和 f¹₄,假设
- w121=0.9,w122=0.1,w123=0.1,b12=0,计算f12,
- w¹₃₁=0.7,w¹₃₂=0.2,w¹₃₃=0.4,b¹₃=0,用于计算 f¹₃,并且,
- w¹₄₁=0.01,w¹₄₂=0.5,w¹₄₃=0.2,b¹₄=0,用于计算 f¹₄。
确认 f¹₂=8.1、f¹₃=10.5 和 f¹₄=6.07。
5. 最后一层的计算
在最后一层,让我们初始化参数(权重)和偏差:w²₁₁=0.58,w²₁₂=0.1,w²₁₃=0.1,w²₁₄=0.42,b²₁=0。
关于这一层的激活函数——因为我们正在处理二进制分类,我们可以使用 sigmoid/logistic 函数,因为这个函数输出的值介于 0 和 1 之间,因此可以解释为一个类的预测概率。 Sigmoid 函数定义为:
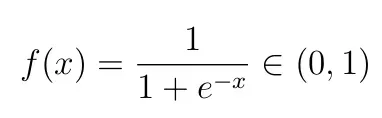
Therefore,
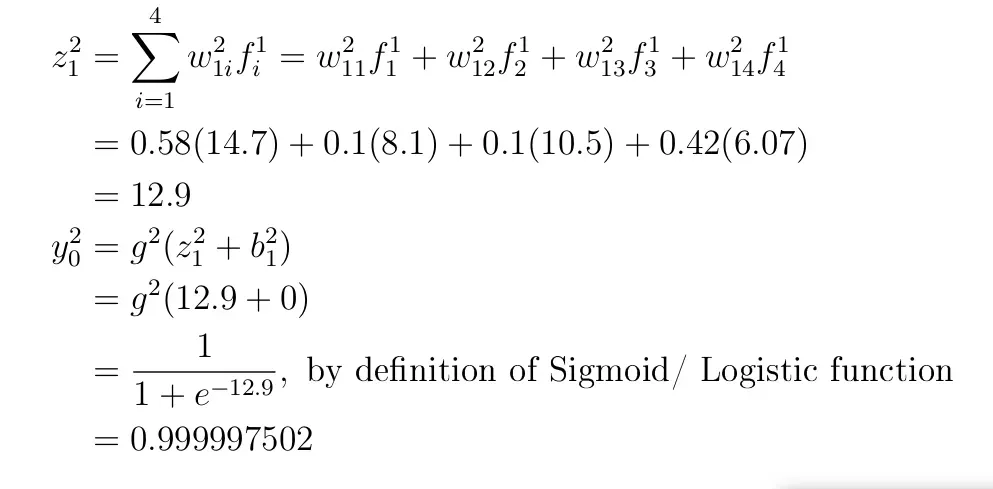
由于最后一层的输出是由 Sigmoid 生成的(范围从 0 到 1),因此结果可以解释为概率。 y²₀=0.999997502 表示通过的可能性几乎为 1。从数据来看,真实值为 1 意味着 Forward Pass 得到了正确的预测。然而,这并非纯属巧合,因为尚未进行任何培训。权重是随机生成的,所有偏差值都设置为 0。
我希望这篇文章为理解神经网络中发生的计算奠定了良好的基础。这是该系列上一篇文章的基础。本系列的下一篇文章将于 2022 年 5 月 16 日发布。[0]
请以每月 5 美元的价格注册媒体会员,以便能够阅读我在媒体上和其他作家的所有文章。[0]
当我发布时,您也可以订阅将我的文章放入您的电子邮件收件箱。[0]
感谢阅读,下一篇!!!
文章出处登录后可见!