目录
1.算法伪代码
输入:
D:事务数据库。
min_sup:最小支持度阈值。
输出:
频繁模式的完全集。
方法:
1.按照以下步骤构造FP树:
(a)扫描事务数据库D一次。收集频繁项的集合F和他们的支持度。对F按照支持度计数降序排序,结果为频繁项集L。
(b)创建FP树的根节点,以“null”标记它。对于D中每一个事务trans,执行:
选择trans中的频繁项集,并且按照L中的次序排序。设trans排序后的频繁项集列表为[p|P],其中p是第一个元素,而P是剩余元素的列表。调用insert_tree([p|P],T)。该过程执行情况如下。如果T有子女N使得N.item-name = p.item-name,则N的计算加一;否则,创建一个新节点N,把它的计算设置为一,连接到它的父节点T,并且通过节点链结构把它连接到具有相同item-name的节点。如果P非空,则递归调用insert_tree(P,N)。
2.FP树的挖掘通过调用FP-growth(FP_tree,null)实现。过程如下:
Procedure FP_growth(tree,α)
(1)if tree包含单个路径P then;
(2)for路径P中结点的每个组合(记作β);
(3)产生模式β Uα,其支持度计数support_count等于β中的结点的最小支持度计数;
(4)else for Tree的头表中的每个ai {
(5)产生一个模式β = aiUα,其支持度计数support_count = ai,support_count;
(6)构造β的条件模式基,然后构造β的条件FP树Treeβ;
(7)If Treeβ ≠Øthen
(8)调用FP_growth(Treeβ,β);}
2.算法代码
# -*- coding: utf-8 -*-
from tqdm import tqdm
import time
import psutil
import os
def load_data(): # 根据路径加载数据集
ans = [] # 将数据保存到该数组
reader = [
['M', 'O', 'N', 'K', 'E', 'Y'],
['D', 'O', 'N', 'K', 'E', 'Y'],
['M', 'A', 'K', 'E'],
['M', 'U', 'C', 'K', 'Y'],
['C', 'O', 'O', 'K', 'I', 'E']
]
for row in reader:
row = list(set(row)) # 去重,排序
row.sort()
ans.append(row) # 将添加好的数据添加到数组
return ans # 返回处理好的数据集,为二维数组
def show_confidence(rule):
index = 1
for item in rule:
s = " {:<4d} {:.3f} {}=>{}".format(index, item[2], str(list(item[0])), str(list(item[1])))
index += 1
print(s)
class Node:
def __init__(self, node_name, count, parentNode):
self.name = node_name
self.count = count
self.nodeLink = None # 根据nideLink可以找到整棵树中所有nodename一样的节点
self.parent = parentNode # 父亲节点
self.children = {} # 子节点{节点名字:节点地址}
class Fp_growth_plus():
def data_compress(self, data_set):
data_dic = {}
for i in data_set:
if frozenset(i) not in data_dic:
data_dic[frozenset(i)] = 1
else:
data_dic[frozenset(i)] += 1
return data_dic
def update_header(self, node, targetNode): # 更新headertable中的node节点形成的链表
while node.nodeLink != None:
node = node.nodeLink
node.nodeLink = targetNode
def update_fptree(self, items, count, node, headerTable): # 用于更新fptree
if items[0] in node.children:
# 判断items的第一个结点是否已作为子结点
node.children[items[0]].count += count
else:
# 创建新的分支
node.children[items[0]] = Node(items[0], count, node)
# 更新相应频繁项集的链表,往后添加
if headerTable[items[0]][1] == None:
headerTable[items[0]][1] = node.children[items[0]]
else:
self.update_header(headerTable[items[0]][1], node.children[items[0]])
# 递归
if len(items) > 1:
self.update_fptree(items[1:], count, node.children[items[0]], headerTable)
def create_fptree(self, data_dic, min_support, flag=False): # 建树主函数
item_count = {} # 统计各项出现次数
for t in data_dic: # 第一次遍历,得到频繁一项集
for item in t:
if item not in item_count:
item_count[item] = data_dic[t]
else:
item_count[item] += data_dic[t]
headerTable = {}
for k in item_count: # 剔除不满足最小支持度的项
if item_count[k] >= min_support:
headerTable[k] = item_count[k]
freqItemSet = set(headerTable.keys()) # 满足最小支持度的频繁项集
if len(freqItemSet) == 0:
return None, None
for k in headerTable:
headerTable[k] = [headerTable[k], None] # element: [count, node]
tree_header = Node('head node', 1, None)
if flag:
ite = tqdm(data_dic)
else:
ite = data_dic
for t in ite: # 第二次遍历,建树
localD = {}
for item in t:
if item in freqItemSet: # 过滤,只取该样本中满足最小支持度的频繁项
localD[item] = headerTable[item][0] # element : count
if len(localD) > 0:
# 根据全局频数从大到小对单样本排序
order_item = [v[0] for v in sorted(localD.items(), key=lambda x: x[1], reverse=True)]
# 用过滤且排序后的样本更新树
self.update_fptree(order_item, data_dic[t], tree_header, headerTable)
return tree_header, headerTable
def find_path(self, node, nodepath):
'''
递归将node的父节点添加到路径
'''
if node.parent != None:
nodepath.append(node.parent.name)
self.find_path(node.parent, nodepath)
def find_cond_pattern_base(self, node_name, headerTable):
'''
根据节点名字,找出所有条件模式基
'''
treeNode = headerTable[node_name][1]
cond_pat_base = {} # 保存所有条件模式基
while treeNode != None:
nodepath = []
self.find_path(treeNode, nodepath)
if len(nodepath) > 1:
cond_pat_base[frozenset(nodepath[:-1])] = treeNode.count
treeNode = treeNode.nodeLink
return cond_pat_base
def create_cond_fptree(self, headerTable, min_support, temp, freq_items, support_data):
# 最开始的频繁项集是headerTable中的各元素
freqs = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1][0])] # 根据频繁项的总频次排序
for freq in freqs: # 对每个频繁项
freq_set = temp.copy()
freq_set.add(freq)
freq_items.add(frozenset(freq_set))
if frozenset(freq_set) not in support_data: # 检查该频繁项是否在support_data中
support_data[frozenset(freq_set)] = headerTable[freq][0]
else:
support_data[frozenset(freq_set)] += headerTable[freq][0]
cond_pat_base = self.find_cond_pattern_base(freq, headerTable) # 寻找到所有条件模式基
# 创建条件模式树
cond_tree, cur_headtable = self.create_fptree(cond_pat_base, min_support)
if cur_headtable != None:
self.create_cond_fptree(cur_headtable, min_support, freq_set, freq_items, support_data) # 递归挖掘条件FP树
def generate_L(self, data_set, min_support):
data_dic = self.data_compress(data_set)
freqItemSet = set()
support_data = {}
tree_header, headerTable = self.create_fptree(data_dic, min_support, flag=True) # 创建数据集的fptree
# 创建各频繁一项的fptree,并挖掘频繁项并保存支持度计数
self.create_cond_fptree(headerTable, min_support, set(), freqItemSet, support_data)
max_l = 0
for i in freqItemSet: # 将频繁项根据大小保存到指定的容器L中
if len(i) > max_l: max_l = len(i)
L = [set() for _ in range(max_l)]
for i in freqItemSet:
L[len(i) - 1].add(i)
for i in range(len(L)):
print("frequent item {}:{}".format(i + 1, L[i]))
return L, support_data
def generate_R(self, data_set, min_support, min_conf):
L, support_data = self.generate_L(data_set, min_support)
rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(
freq_set) and freq_set - sub_set in support_data: # and freq_set-sub_set in support_data
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in rule_list:
rule_list.append(big_rule)
sub_set_list.append(freq_set)
rule_list = sorted(rule_list, key=lambda x: (x[2]), reverse=True)
return rule_list
if __name__ == "__main__":
begin_time = time.time()
min_support = 3 # 最小支持度
min_conf = 0.8 # 最小置信度
data_set = load_data()
print(data_set)
fp = Fp_growth_plus()
rule_list = fp.generate_R(data_set, min_support, min_conf)
print("confidence:")
show_confidence(rule_list)
end_time = time.time()
timeget = end_time - begin_time
print("程序开始时间:",begin_time)
print("程序结束时间:",end_time)
print("程序花费时间:",timeget)
print(u'当前进程的内存使用:%.4f GB' % (psutil.Process(os.getpid()).memory_info().rss / 1024 / 1024 / 1024))注:代码来源已找不到!
3.测试数据
[‘M’, ‘O’, ‘N’, ‘K’, ‘E’, ‘Y’],
[‘D’, ‘O’, ‘N’, ‘K’, ‘E’, ‘Y’],
[‘M’, ‘A’, ‘K’, ‘E’],
[‘M’, ‘U’, ‘C’, ‘K’, ‘Y’],
[‘C’, ‘O’, ‘O’, ‘K’, ‘I’, ‘E’]
4.结果
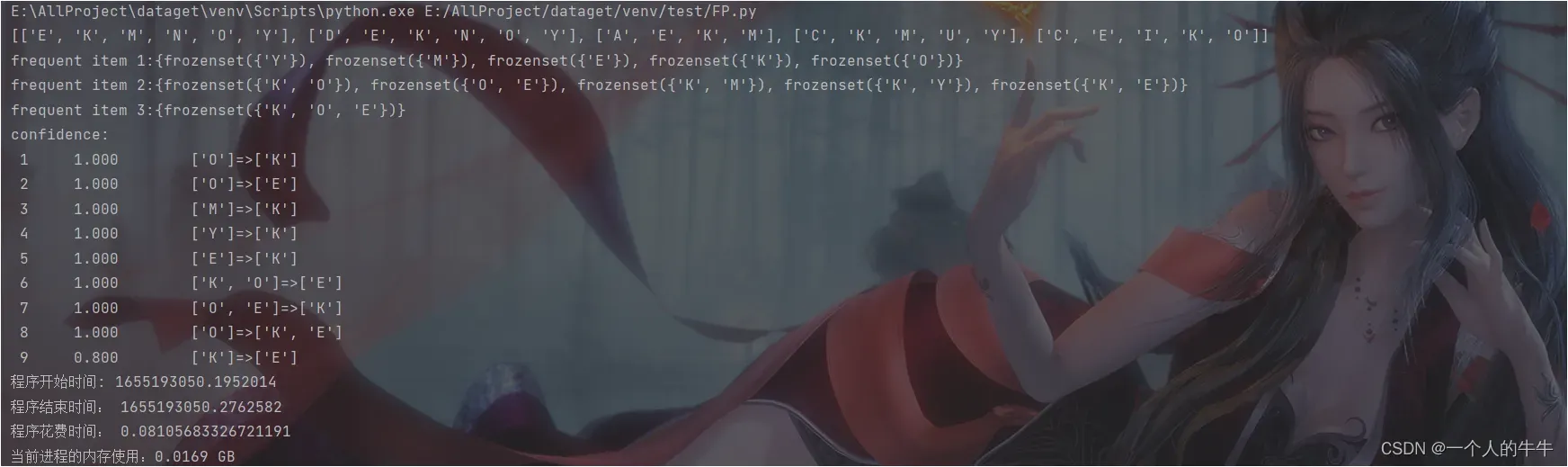
各频繁集
E/K/M/O/Y
KE/OE/KM/OK/YK/OKE
各强关联规则及其置信度
K –> E: 0.8
E –> K: 1.0
O –> E: 1.0
M –> K: 1.0
O –> K: 1.0
Y –> K: 1.0
O–> E K: 1.0
程序开始时间: 1655193050.1952014
程序结束时间: 1655193050.2762582
程序花费时间: 0.08105683326721191
当前进程的内存使用:0.0169 GB
基础知识参考:
机器学习实战(十一)FP-growth算法_Qxw1012的博客-CSDN博客_fpgrowth算法步骤
FP-growth算法,fpgrowth算法详解_javastart的博客-CSDN博客_fpgrowth算法
FP-growth算法理解和实现_木百栢的博客-CSDN博客_fp growth
本文仅仅是个人学习笔记,如有错误,敬请指正!
文章出处登录后可见!