一般而言,计算机视觉领域包含三大主流任务:分类、检测、分割。其中,分类任务对模型的要求较为简单,在之前的Pytorch入门教程中已进行了较为详尽的介绍,有兴趣的小伙伴可以查看之前的博客;而检测和分割任务是比较需要多尺度的高层特征信息的,所以对模型的构架要求也稍复杂一些。在本篇文章中,我将主要基于肺部CT影像和UNet网络对语义分割任务进行全流程介绍。话不多说,进入正题。
1 什么是语义分割?
语义分割是计算机视觉领域的核心技术,通过对图像中的每个像素点进行分类,将图像分割成若干个具有特定语义类别的区域。通俗一些讲,目标检测任务是对图像中的前景(各种目标对象)进行定位和分类,检测出猫猫狗狗人人之类的实例对象,而语义分割任务则要求网络对图像前景中的每个像素点所属类别进行判断,进行像素级别的精准分割,在自动驾驶领域应用较为广泛。

2 肺部CT影像分割案例
对于语义分割入门者而言,肺部影像分割确实是一个比较容易理解、不具有太大上手难度的项目,下面我主要从数据、模型、结果及预测三个方面来介绍案例。
2.1 数据集制作
2.1.1 数据集概况
本次语义分割主要使用2D图像,包括了CT影像图和label图,两者均是单通道图像,分辨率为512×512,各267张。数据展示如下:
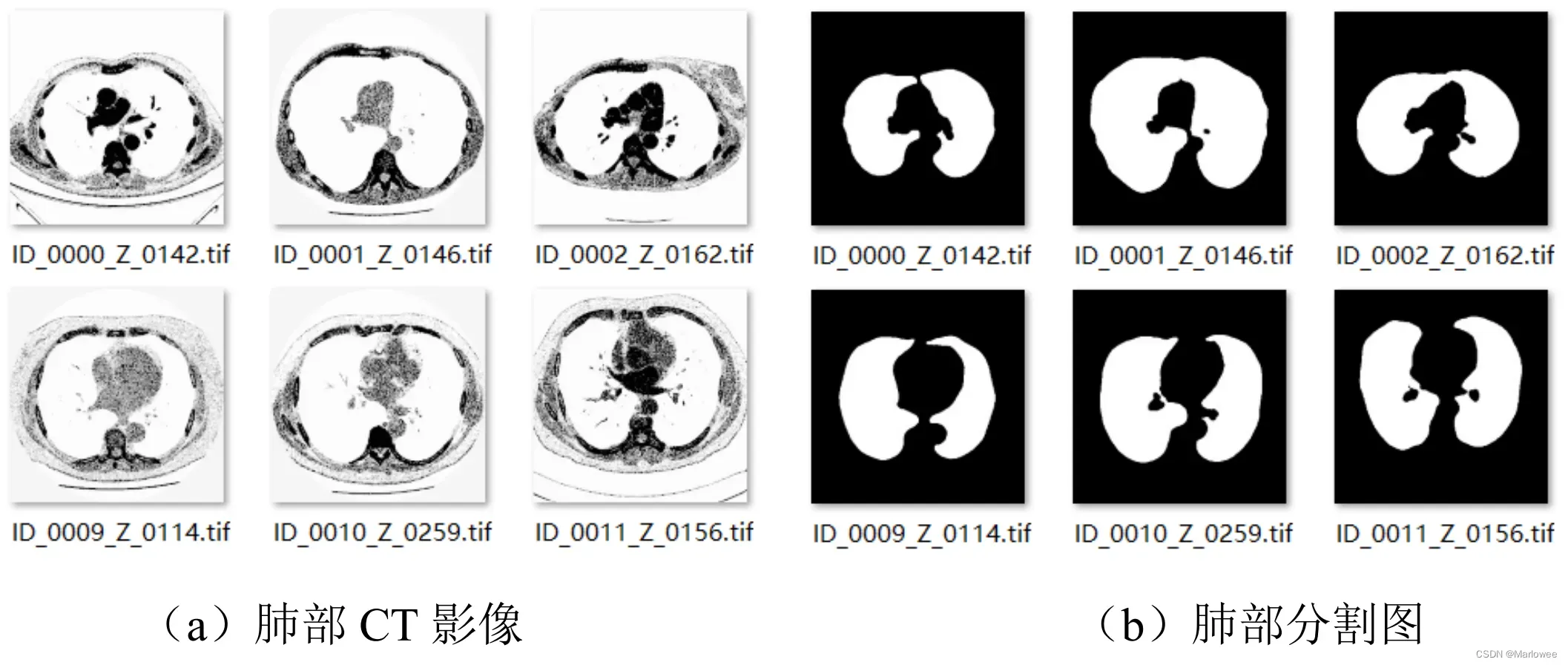
2.1.2 数据预处理
由于label图像中的背景用0表示,肺部影像用255表示,但是在使用pytorch分类时,类别需要按顺序从0开始表示(类别需要是从雷开始的连续张量,这个之前已经提到过)。因此,我们需要表肺部影像的255值变为1。相关主要代码如代码清单1所示。
# 代码清单1
# 介绍:读入原始2D图像数据,对像素标签进行映射:0=>0 255=>1
image = cv.imread(image_fullpath,0)
img_array = np.asarray(image)
for i in img_array:
for j in i:
if j == 255:
label_img.append(1)
else:
label_img.append(0)
output_img = op_dir + each_image
label_img = np.array(label_img)
label_img = label_img.reshape((512, 512))
cv.imwrite(output_img, label_img)
n = n + 1
print("处理完成label: %d" % n)
像素值映射完毕后通过resize函数进行图片大小的标准化,最后得到512*512且只包含0和1像素值的图片。由于1表示的亮度很低,所以处理完的label图在肉眼上呈现全黑,处理完后的图片label如图所示。

这里可能有同学就问了,处理完了怎么看不出CT影像了呢,是不是有问题啊?其实不然,因为我们需要将像素值映射到0和1,所以标签图片的像素就只有0和1组成,对于人眼来说,很难分辨这种细微的像素值差距,除非你的眼睛是电子眼…如果不放心,其实可以随机选几张label图片用opencv或者PIL读入,打印出其图片的像素值进行结果的核对。
2.1.3 生成数据路径
为了方便读取图片,我们需要生成三个txt文件记录原始图像和其对应label图像的路径(相关图像处理基础之前博客提到过,有疑问的小伙伴可以自行查阅)。图像生成路径及对应标签的代码清单如下所示:
# 代码清单2
# 介绍:读入原始2D图像数据,生成路径及标签
import os
def walk_dir(dir):
dir_list=[]
for image in os.listdir(dir):
dir_list.append(os.path.join(dir,image))
return dir_list
original_dir=r'CT_image'
save_dir=r'CT_txt'
if not save_dir:
os.mkdir(save_dir)
img_dir=os.listdir(original_dir)
img_test=walk_dir(os.path.join(original_dir,img_dir[0]))
img_test_label=walk_dir(os.path.join(original_dir,img_dir[1]))
img_t_v=walk_dir(os.path.join(original_dir,img_dir[2]))
img_t_v_label=walk_dir(os.path.join(original_dir,img_dir[3]))
img_train=img_t_v[:188]
img_val=img_t_v[188:]
img_train_label=img_t_v_label[:188]
img_val_label=img_t_v_label[188:]
# 查看每个图片与标签是否对应
# sum=0
# for index in range(len(img_train)):
# train=img_train[index].split("\\")[-1]
# train_label=img_train_label[index].split("\\")[-1]
# if train==train_label:
# print(train," ",train_label)
# sum+=1
# print(sum)
# 将训练集写入train.txt
with open(os.path.join(save_dir, 'train.txt'), 'a')as f:
for index in range(len(img_train)):
f.write(img_train[index]+'\t' +img_train_label[index]+'\n')
print("训练集及标签写入完毕")
# 将验证集写入val.txt
with open(os.path.join(save_dir, 'val.txt'), 'a')as f:
for index in range(len(img_val)):
f.write(img_val[index] + '\t' +img_val_label[index] + '\n')
print("验证集及标签写入完毕")
# 测试集
with open(os.path.join(save_dir, 'test.txt'), 'a')as f:
for index in range(len(img_test)):
f.write(img_test[index] + '\t' +img_test_label[index]+ '\n')
运行之后得到train.txt、val.txt、test.txt三个文本文档。train和val用于训练并验证模型,包含数据路径及标签;test用于测试模型,只包含数据路径。
2.1.4 定义Dataset
在Pytorch中,网络能够处理的是张量,所以我们需要把读取后的图片转化为张量数据输入到网络中,这里用到一个很重要的库:torch.utils.Dataset库。
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。要想继承Dataset类,里边的__len__方法、__getitem__方法是必须要重写的,__len__返回dataset的长度,__getitem__可实现按索引得到数据,其实现如代码清单3所示。
# 代码清单3
# 介绍:将读取到的图像数据转化为张量
import torch
import numpy as np
from PIL import Image
from torch.utils.data.dataset import Dataset
def read_txt(path):
# 读取文件
ims, labels = [], []
with open(path, 'r') as f:
for line in f.readlines():
im, label = line.strip().split("\t")
ims.append(im)
labels.append(label)
return ims, labels
class UnetDataset(Dataset):
def __init__(self, txtpath, transform):
super().__init__()
self.ims, self.labels = read_txt(txtpath)
self.transform = transform
def __getitem__(self, index):
im_path = self.ims[index]
label_path = self.labels[index]
image = Image.open(im_path)
image = self.transform(image).float().cuda()
label = torch.from_numpy(np.asarray(Image.open(label_path), dtype=np.int32)).long().cuda()
return image, label
def __len__(self):
return len(self.ims)
2.2 网络结构概述
UNet网络结构类似于一个大大的U字母:首先进行Conv+Pooling下采样;然后Deconv反卷积进行上采样,crop之前的低层feature map,进行融合;然后再次上采样。重复这个过程,直到获得输出3883882的feature map,最后经过softmax获得output segment map。与FCN逐点相加不同,U-Net采用将特征在channel维度拼接在一起,形成更“深”的特征。具体网络结构细节内容这里不再赘述。
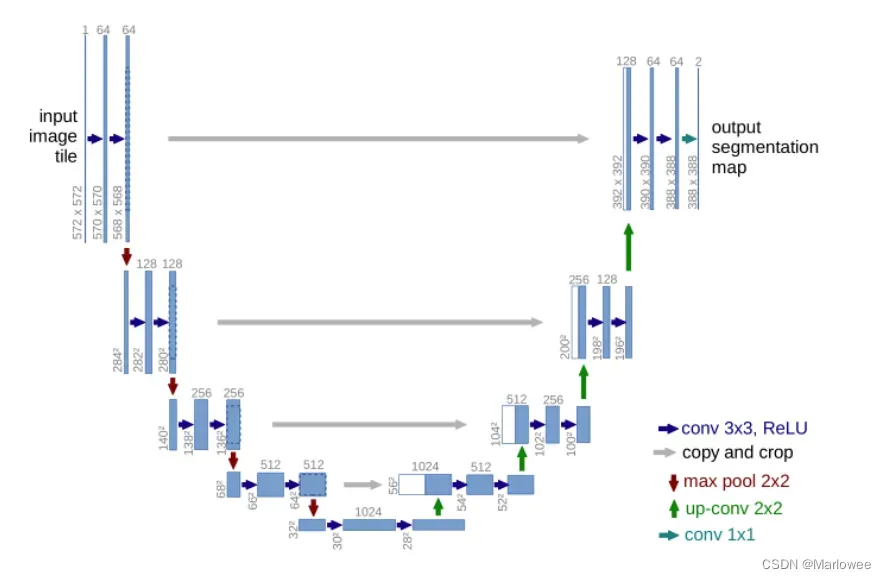
2.3 结果及预测
2.3.1 预测结果转化
预测函数在文章末尾的分享链接中,代码太长不再展示,主要说一下结果的转化。在数据制作过程中我们把像素值为255的数据映射到1,网络的预测也是0和1,所以我们需要把1再转成255的像素值进行结果输出,其过程如下。
# 代码清单4
# 介绍:将预测结果转化为实际黑白影像
def translabeltovisual(save_label, path):
visual_img = []
im = cv2.imread(save_label, 0)
img_array = np.asarray(im)
for i in img_array:
for j in i:
if j == 1:
visual_img.append(255)
else:
visual_img.append(0)
visual_img = np.array(visual_img)
visual_img = visual_img.reshape((Height, Width))
cv2.imwrite(path, visual_img)
2.3.2 结果展示

2.3.3 模型评估函数部分解释

2.3.4
使用Tensorboard对训练过程中的损失、精度、IOU进行记录,以训练轮次作为横轴、各指标作为纵轴,各自的曲线如图所示。
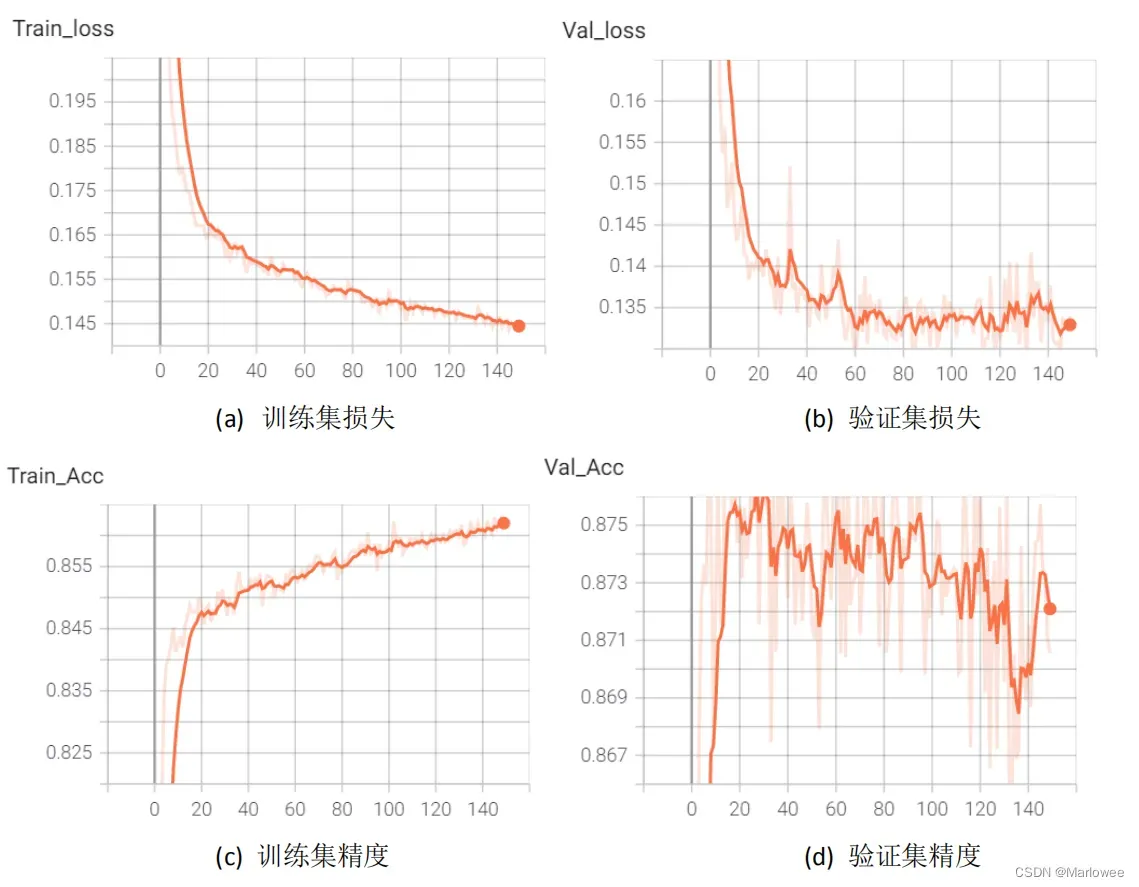
由训练过程中的曲线可以得出以下结论:
第一,模型在训练数据上的训练过程总体损失缓慢下降,没有震荡的情况;但是在验证集上震荡明显,说明初始的训练参数并不合适。
第二,语义分割中的精度并不能完全代表算法性能,真实表现更要看平均交并比的得分。无论是训练集还是验证集,精度与IoU得分差距都有20个百分点左右,所以语义分割任务不仅要关注精度,更要关注模型的IoU得分。
3 源码及数据分享
链接:https://pan.baidu.com/s/1NgKil7ub-oNEV0ei0QM90w
提取码:qo7q
文章出处登录后可见!