Resnet
论文部分
以前出现的问题及ResNet如何解决
在2015年之前,如果是卷积神经网络的话只顾加深加宽,导致的问题就是梯度消失或者梯度爆炸。那么一个接近办法是初始的权重不要特别大,也不要特别小。包括在中间加入一些BatchNormalization(也就是BN层),是可以训练一些相对较深的网络的。这样是能训练的,但是是说在网络加深的时候,性能是在变差的。如下图所示:
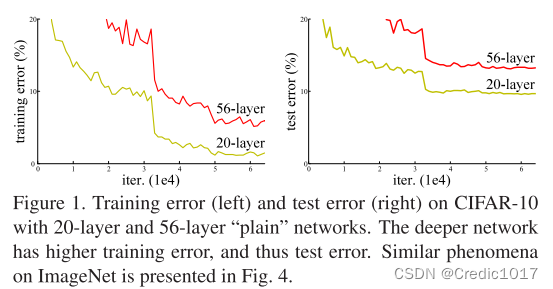
并且这种情况不是过拟合,因为训练集上的误差也变高了。(如果是训练集误差低测试集误差高的话就是过拟合,欠拟合就对应训练集误差高测试集误差高,也就是性能变差了)
按理说如果浅的网络效果好,在此基础上加更多网络效果应该会是更好的,不应该会变差。那么对于一个更深的网络而言,我们完全可以做一个identity mapping,也就是让多出来的更深的网络什么事也不做的话,深层的网络可以保持一个和浅层的网络一样的效果,至少是等于浅层网络的精确度,但实际上去做的时候,发现sgd是做不到的。
而现在的话,我们是显式的去做这么一个identity mapping,从而去保证深的网络效果不会比浅的网络效果差。
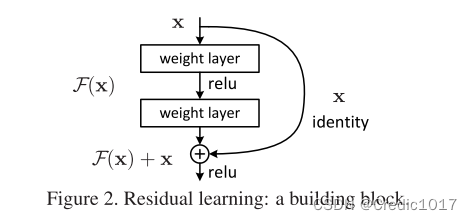
具体是这么做的:可以假设原先的浅层网络输出为x,所需的底层映射为H(x),我们令新加的网络映射为F(x),那么这里新的网络映射F(x)其实就等于H(x)-x。所以说这里的这么一个块叫做残差块,做的就是学习映射后的数据与真实输入数据的一个残差。这就是Resnet两种基本结构之一 building block,还有一种基础残差块(bottleneck building block)后面会介绍。
所以可以看到和普通的深层卷积神经网络对比的话,其实就是加了旁边一条路(identity mapping)。
那么说这个多加的identity mapping好在哪呢,由于没有多加多余的参数,不会增加模型复杂度,不会增加多余的计算。
所以,关于ResNet论文中主要的一点,就是提出了residual connect。
然后有输入和输出不匹配的时候,残差连接是怎么做的。
1.在输入和输出上分别添0,使得能够匹配维度,然后可以做相加。
2.做投影,卷积上做投影是通过1×1的卷积层,1×1的卷积层特点是:在空间上不做任何事情,主要是在通道维度上改变。这样使得输出通道是输入通道的两倍。(如果是在卷积中,如果输出的通道数变为了两倍,那么输入的高宽都会变为原先的一半,所以我们在使用1×1的卷积的时候,使用步幅为2,这样输出的通道、高和宽都能对应上了)。
没有用dropout,因为没有全连接层,所以这里的话就没用。
具体网络部分
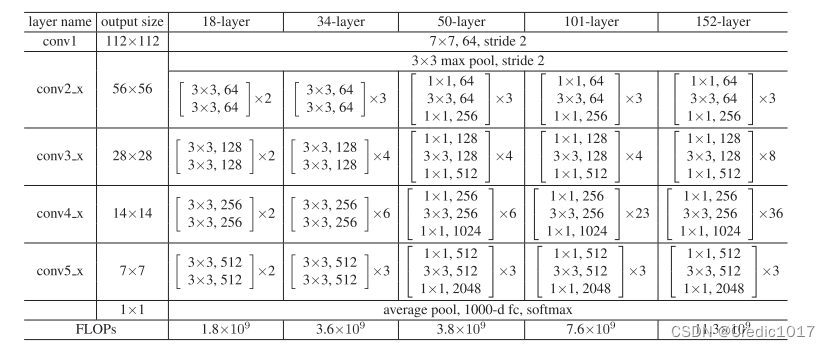
论文中其实主要提出了五种ResNet,可以发现ResNet18和ResNet34使用的基础的残差块都是一样的,也就是在残差块都是在只有两层的基础上。而ResNet50,ResNet101,ResNet152可以发现里面都是残差块为3层的基础上。以ResNet18为例,为什么是18层呢,可以看到一开始有个初始的卷积,也就是conv1,每个网络都会有的,后面四个卷积层,每个里面包含了两个残差块,每个残差块里面均有两个卷积层,最后还有个全局池化,1000维的一个全连接,再经过softmax进行分类。故层数为1+4x2x2+1=18,没有参数的池化就不算层。
ResNet中常用的两个残差块:building block和BottleNeck building block。为什么要有两种残缺块,一种不行吗,从上图中我们可以很明显的看到,在ResNet层数较少的时候,也就是18,34层的时候使用的是building block,而在层数较深的时候使用的是BottleNeck building block,那么这么做的好处是什么呢?原因就在于BottleNeck building block使用的结构不一样,从而在网络较深的时候减少了参数量,上表的最后一行代表的就是模型的一个总参数量FLOPs。从结论上来看,34层的ResNet和50层的ResNet参数量是差不多的。这其实就是50层的ResNet使用的是BottleNeck building block,而34层的ResNet使用的是building block。下面介绍ResNet中间shape的变化,以此来感受使用不同残差模块的一个参数量的变化。
ResNet中间shape的变化
下面是介绍中间层的一个feature map变化情况及残差连接是如何做的(以上图中ResNet18为例,3x224x224作为原始输入):
可以看到相关的卷积层中输出shape的变化:
图像宽为W,高为H,通道数为C;
卷积核尺寸为K,通道数为D,个数为N;
卷积运算步长为S,填充大小为P;
输入和输出量分别以1和2表示。
卷积:
W2 = (W1 – K + 2×P) / S + 1
H2 = (H1 – K + 2×P) / S + 1
C2 = N
1.3x224x224的输入经过一个7x7x64的卷积,由于步幅S为2,W1=224,卷积核尺寸K=7,填充大小P=3,那么计算出W2为112,同理H2也为112,输出的通道数C2等于卷积核的个数N,即C2=N=64。
2.同样是在别的卷积层,只要知道了对应的W,H,S,P,那么对应的输出的W,H就可以知道了,而输出的通道即为卷积核的个数。
关于卷积核的具体细节参数参考何大神的论文,在下面的代码中也有体现,比如padding、dilation和stride。
代码部分
代码实验环境
基于pytorch框架,显卡为RTX 2060。torch版本1.10.0,torchvision版本为0.11.1。
两种基础残差块
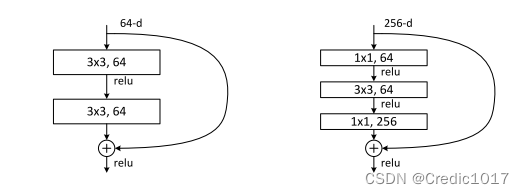
1.building block
(也就是在较为浅层的ResNet18和ResNet34中出现的模块)
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(in_channels)
def forward(self, x):
residual = self.conv1(x)
residual = self.bn1(residual)
residual = self.relu(residual)
residual = self.conv2(residual)
residual = self.bn2(residual)
out = self.relu(x + residual)
return out
2.building block
(也就是在较为深层的ResNet50、ResNet101和ResNet152中出现的模块)
class BottleNeck(nn.Module):
def __init__(self,in_channels):
super(BottleNeck, self).__init__()
self.main = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=1,stride=1,padding=0),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(63,in_channels,kernel_size=1,stride=1,padding=0),
nn.BatchNorm2d(in_channels),
)
self.shortcut = nn.Sequential()
def forward(self,x):
shortcut = self.shortcut(x)
residual = self.main(x)
out = nn.ReLU(shortcut + residual )
return out
ResNet18在FashionMinist上的整体代码
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader,Dataset
from torchvision import transforms
from d2l import torch as d2l
from torch.nn import functional as F
#数据集
def load_data_fashion_mnist(batch_size,resize):
trans = []
if resize:
trans.append(transforms.Resize(size=resize))
trans.append(transforms.ToTensor())
transform = transforms.Compose(trans)
#准备数据集
train_data = torchvision.datasets.FashionMNIST(root='./data', train=True, transform=transform,
download=True)
test_data = torchvision.datasets.FashionMNIST(root='./data', train=False, transform=transform,
download=True)
#加载数据集
train_dataloader = DataLoader(dataset=train_data,batch_size=batch_size,shuffle=True)
test_dataloader = DataLoader(dataset=test_data,batch_size=batch_size,shuffle=False)
return train_dataloader,test_dataloader
#搭建网络
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
#Accumulator 实例中创建了 2 个变量,用于分别存储正确预测的数量和预测的总数量
class Accumulator:
"""在`n`个变量上累加。"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
#GPU训练
def try_gpu(i=0):
if torch.cuda.device_count() >= 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
#计算预测正确的数量
def accuracy(y_hat,y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
#使用GPU计算模型在数据集上的精度
def evaluate_accuracy_gpu(net,data_iter,device=None):
if isinstance(net,nn.Module):
net.eval() #设置为评估模式
if not device:
device = next(iter(net.parameters())).device
#正确预测的数量,总预测的数量
metric = Accumulator(2)
with torch.no_grad():
for X,y in data_iter:
if isinstance(X,list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(accuracy(net(X),y),y.numel())
return metric[0]/metric[1]
def train(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)。"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
metric = Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
if __name__ == '__main__':
batch_size = 256
lr = 0.05
num_epochs = 10
train_iter,test_iter = load_data_fashion_mnist(batch_size=batch_size,resize=96)
train(net,train_iter=train_iter,test_iter=test_iter,num_epochs=num_epochs,lr=lr,device=try_gpu())
d2l.plt.show()
最后的运行结果:
问题及思考
1.sgd为什么做不到在深层网络的效果比浅层网络好?
自我理解:比如说在20层的网络和34层网络的一个情况下,假设20层的网络效果较好,34层的效果不好。那么后14层依旧是有参数的,由于前20层效果已经较好了,那么这些参数在学习的时候依旧发挥作用,在计算梯度的时候依旧参与其中,那么导致而来的是一个梯度消失,梯度消失导致的效果就是模型训练不动了,因为参数没有变化了或者说变化很小,所以整体导致的效果就是反而没有浅层的网络效果好。
2.为什么ResNet论文当中给出的经典模型层数为18,34,50,101,152,而不是别的层数,以及它的一个残差块堆叠方式为什么是那样的?
自我理解:调参大法好,何大神给出这样的网络想必也是花了不少的时间精力调参 的。
参考
本文参考了如下资料,学习整理而得,但是仍有颇多不足之处,欢迎大家批判指出错误。
视频:李沐:跟我动手学深度学习
论文:HE K, ZHANG X, REN S, et al. Deep Residual Learning for Image Recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).2016:770-778. 10.1109/CVPR.2016.90.
博客:https://blog.csdn.net/a_piece_of_ppx/article/details/125960098
博客:https://zhuanlan.zhihu.com/p/549010081
博客:https://blog.csdn.net/qq_42103167/article/details/105056598
文章出处登录后可见!