来啦来啦~我们来兑现承诺啦~
本期我们提供 MMTracking 里视频目标目标检测(VID)任务的食用指南,以及 AAAI(人工智能(Artificial Intelligence))2021 论文《Temporal RoI Align for Video Object Recognition》的论文解读以及其在 MMTracking 下的实现细节。后续多目标跟踪、单目标跟踪的食用指南也在路上哦~
一、VID 任务简介
VID 旨在目标检测视频中每一帧出现的物体。
与目标目标检测相比, VID 允许来自一个视频里的多帧作为输入(input),但输出形式与目标目标检测一致。
与多目标跟踪相比, VID 不要求对不同帧中的同一目标进行关联,只需目标检测出目标即可。
 看,MMTracking追踪套马杆的汉子https://www.zhihu.com/video/1424122028240990208
看,MMTracking追踪套马杆的汉子https://www.zhihu.com/video/1424122028240990208
【视频素材来源:B站游牧之心】
二、VID 数据集(Dataset)介绍
目前 VID 领域主流(stream)的数据集(Dataset)为 ImageNet VID,它包含了 30 个类(Cluster)别。其中训练集共 3862 个视频,验证集(validation set)共 555 个视频。在该数据集(Dataset)上的评估,一般以 IOU = 0.5 为阈值(Threshold)进行 mAP 的计算。
三、MMTracking 支持的 VID 算法
MMTracking 目前支持以下 VID 算法:
- DFF (CVPR 2017)
- FGFA (ICCV 2017)
- SELSA (ICCV 2019)
- Temporal RoI Align (AAAI(人工智能(Artificial Intelligence)) 2021)
其中,Temporal RoI Align 以 84.1 mAP@50 的性能在 ImageNet VID 数据集(Dataset)上达到了 SOTA 水平。
四、上手指南
接下来,我们将通过 MMTracking 来一步一步详细地教大家如何运行 VID 演示demo、测试 VID 模型、训练 VID 模型。
使用 MMTracking,你只需要克隆一下 github 上面的仓库到本地,然后按照安装手册配置一下环境即可,如果安装遇到什么问题,可以给 MMTracking 提 issue,我们会尽快为小伙伴们解答。
假设(Hypothesis)我们已经将预训练(pretraining)权重放置在 MMTracking 根目录下的 checkpoints/ 文件夹下(预训练(pretraining)权重可以在相应的 configs 页面下载)。
1、运行 VID 演示demo
在 MMTracking 根目录下只需执行以下命令,即可使用 SELSA Temporal RoI Align 算法运行 VID 演示demo
python ./演示demo/演示demo_vid.py \
./configs/vid/temporal_roi_align/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid.py \
--input ${VIDEO_FILE} \
--checkpoint checkpoints/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid_20210822_111621-22cb96b9.pth \
--output ${OUTPUT} \
--show2、测试 VID 模型
在 MMTracking 根目录下使用以下命令即可测试 VID 模型,并且评估模型的 bbox mAP
./tools/dist_test.sh configs/vid/temporal_roi_align/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid.py 8 \
--checkpoint checkpoints/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid_20210822_111621-22cb96b9.pth \
--out results.pkl \
--eval bbox3、训练 VID 模型
在 MMTracking 根目录下使用以下命令即可训练 VID 模型,并且在最后一个 epoch 评估模型的 bbox mAP
./tools/dist_train.sh ./configs/temporal_roi_align/selsa_troialign_faster_rcnn_r101_dc5_7e_imagenetvid.py 8 \
--work-dir ./work_dirs/其实在 MMTracking 当中已经支持了很多的 VID 模型,并且提供了公共的 checkpoint 供大家把玩,在我们的快速上手教程中有更详细地介绍,欢迎大家来试用并且提出你们宝贵的意见。
五、AAAI(人工智能(Artificial Intelligence))2021 论文原理解析
经过上述步骤,相信大家已经了解了怎样运行 VID 算法,但同时也对算法细节以及实现方式产生了一些兴趣,接下来我们将详细的介绍 AAAI(人工智能(Artificial Intelligence))2021 的论文 Temporal RoI Align for Video Object Recognition (以下简称 Temporal RoI Align),在理解算法细节的基础上,我们将为大家解析算法在 MMTracking 下的具体实现。
1、Motivation

如上图所示,现有的 VID 算法通常使用 RoI Align 为 proposals 提取特征,然而 RoI Align 被设计用来从单张图片中提取特征,这使得提取出的 RoI Features 缺少了来自视频的时域信息。
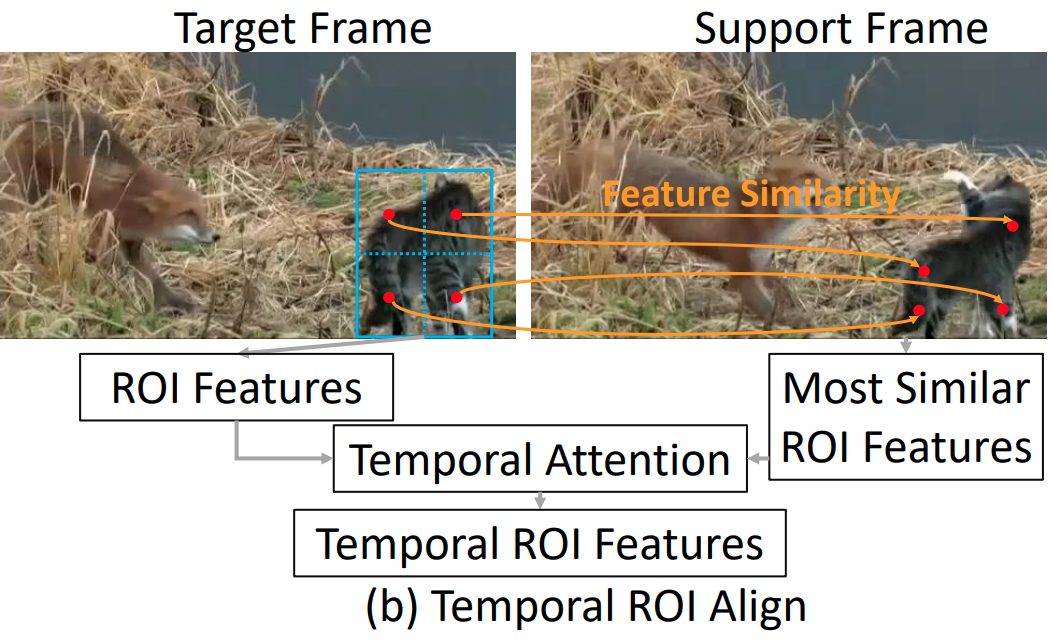
本文提出了 Temporal RoI Align 来处理这个问题。考虑到视频里,同个物体在不同的视频帧中的特征具有高度的相似性,如上图所示,Temporal RoI Align 利用这种相似性,从其它帧(Support Frame)的特征图中,为当前帧(Target Frame)的 proposals 提取特征,使得提取出的 Temporal RoI Features 包含了来自整个视频的时域信息。
2、Method
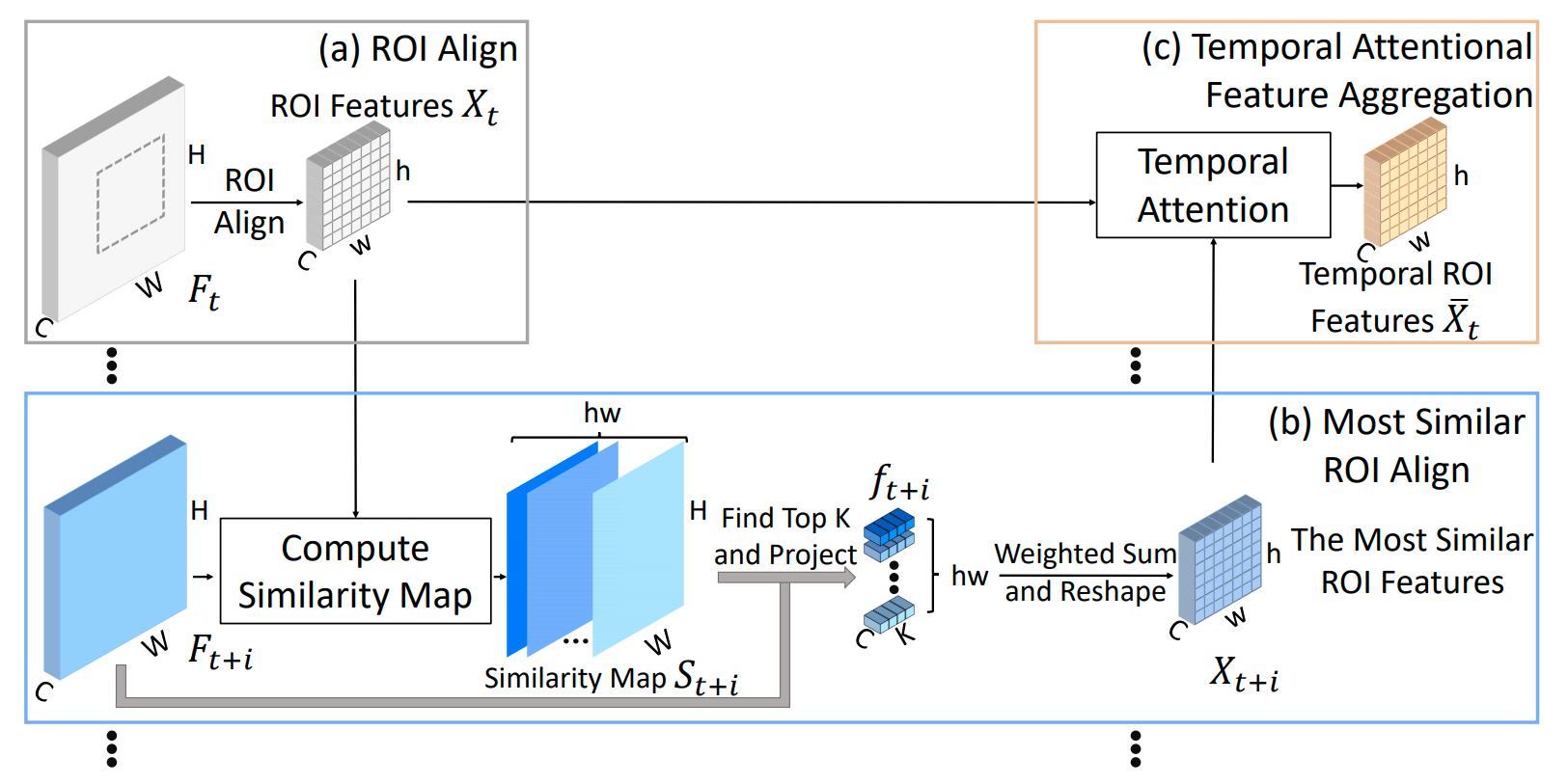
如上图所示,Temporal RoI Align 主要可以分为 3 步:
第一步使用 RoI Align 为 proposals 从当前帧(白色)的特征图提取 RoI Features
第二步使用 Most Simliar RoI Align 为 proposals 从其它帧(蓝色)的特征图 提取 Most Similar RoI Features
第三步使用 Temporal Attention Feature Aggregation 将 RoI Features 与多个 Most Similar RoI Features 聚合起来得到最终的 Temporal RoI Features。
接下来我们详细介绍第二步、第三步
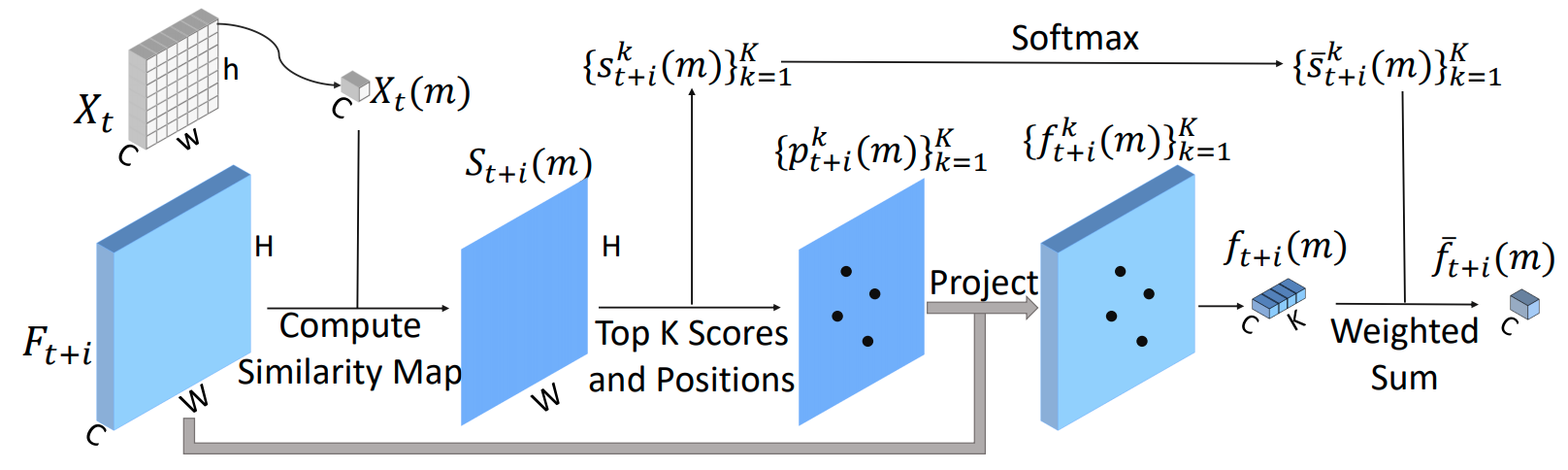
在第二步中,如上图所示,我们以 RoI Features 中的一个 pixel 为例,其它 pixels 是类(Cluster)似的做法。首先计算该 pixel 对应的特征与其它帧特征图的 Cosine 相似度图,在得到的 Cosine 相似度图中挑选出相似度最大的 K 个点,并将这些点投射到其它帧的特征图上,然后从其它帧的特征图中抽出投射点的特征,最后使用最大的 K 个点对应的相似度得分进行加权,就可以得到该 pixel 在其它帧特征图提取出的特征。由于提取的是最相似的特征,所以 Most Similar RoI Features 可以被认为是为当前帧的 proposals 从其它帧的特征图中提取出的 RoI Features。
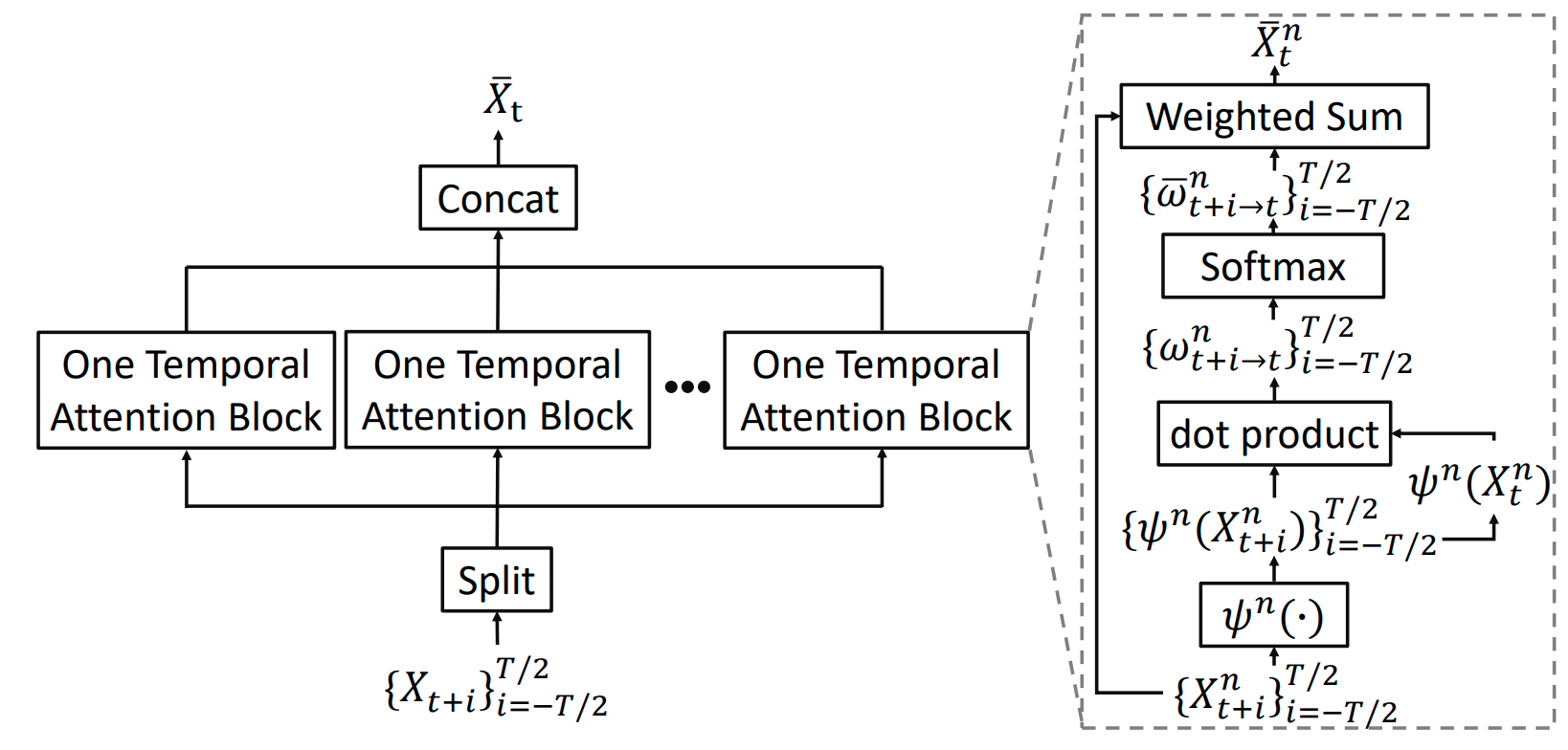
在第三步中,如上图所示,我们现在已经得到了 proposal 对应的 RoI Features 以及多个 Most Similar RoI Features,接下来我们采用 Multi-head attention 的思想,将这些特征沿着时间维度聚合起来,就可以得到最终的 Temporal RoI Features。Temporal RoI Features 拥有着和 RoI Features 一样的大小,但是 Temporal RoI Features 包含了该物体在整个视频里的时域信息。
六、AAAI(人工智能(Artificial Intelligence))2021 论文实现解析
在了解了 Temporal RoI Align 的算法细节,我们接下来介绍 Temporal RoI Align 在 MMTracking 下的实现。
bbox_roi_extractor=dict(
type='TemporalRoIAlign',
num_most_similar_points=2,
num_temporal_attention_blocks=4,
roi_layer=dict(
type='RoIAlign', output_size=7, sampling_ratio=2),
out_channels=512,
featmap_strides=[16])Temporal RoI Align 的配置文件如上图所示,可以看到它主要有 2 个超参,分别是 num_most_similar_points 代表寻找的最大的 K 个点,num_temporal_attention_blocks 代表使用多少个 attention block。
from mmdet.models.roi_heads.roi_extractors import SingleRoIExtractor
class TemporalRoIAlign(SingleRoIExtractor):
"""Temporal RoI Align 组件.
本组件在以下论文中提出
"Temporal ROI Align for Video Object Recognition".
`TRoI Align <https://arxiv.org/abs/2109.03495>`_.
Args:
num_most_similar_points (int): 代表寻找的最大的 K 个点。 默认为 2
num_temporal_attention_blocks (int):代表使用多少个 attention block 来聚合
特征,如果该值小于等于 0,则使用平均池化(Pooling)(Average-Pooling)来聚合特征。默认为 4
"""
def __init__(self,
num_most_similar_points=2,
num_temporal_attention_blocks=4,
*args,
**kwargs):
super(TemporalRoIAlign, self).__init__(*args, **kwargs)
self.num_most_similar_points = num_most_similar_points
self.num_temporal_attention_blocks = num_temporal_attention_blocks
def temporal_attentional_feature_aggregation(self, x, ref_x):
"""聚合 RoI features `x` 和 Most Similar RoI features `ref_x`.
聚合主要包含 3 步:
1. 通过一个小的 embed network 提取特征
2. 使用 multi-head attention 计算 `x` 和 `ref_x` 之间的权重
3. 使用归一化(Normalization)之后的权重聚合 `x` 和 `ref_x`
Args:
x (Tensor): 大小为 [1, roi_n, C, roi_h, roi_w]。 roi_n, roi_h 和
roi_w 分别代表当前帧 proposals 的数量, RoI Features 的高和宽。
ref_x (Tensor): 大小为 [img_n, roi_n, C, roi_h, roi_w]。 img_n 是其
它帧的数量。
Returns:
Tensor: 聚合之后的 Temporal RoI Features,大小为
[roi_n, C, roi_h, roi_w]。
"""
def most_similar_roi_align(self, roi_feats, ref_feats):
"""基于 RoI Features `roi_feats` 来从其它帧的特征图 `ref_feats` 提取
Most Similar RoI features。
提取过程主要包含 3 步:
1. 计算 `roi_feats` 和 `ref_feats`之间的 cosine 相似度图
2. 在相似图中挑去 Top K 个点
3. 将 Top K 个点投射到 `ref_feats` 中提取 Most Similar RoI features
Args:
roi_feats (Tensor): 大小为 [roi_n, C, roi_h, roi_w]。
roi_n, roi_h 和 roi_w 分别代表当前帧 proposals 的数量
RoI Features 的高和宽。
ref_feats (Tensor): 大小为 [img_n, C, img_h, img_w]。
img_n, img_h 和 img_w 分别达标其它帧的数量,其它帧特征图的高和宽
Returns:
Tensor: 从其它帧特征图提取出的 Most Similar RoI features,
大小为 [img_n, roi_n, C, roi_h, roi_w]。
"""
def forward(self, feats, rois, roi_scale_factor=None, ref_feats=None):
"""Forward function."""
# 第一步
roi_feats = super().forward(feats, rois, roi_scale_factor)
if ref_feats is None:
# 当没有其它帧的特征图时,直接返回 RoI Features
return roi_feats
else:
# 第二步
# 我们只用其它帧特征图的最后一层特征图来计算 Most Similar RoI Align
ref_roi_feats = self.most_similar_roi_align(
roi_feats, ref_feats[-1])
roi_feats = roi_feats.unsqueeze(0)
if self.num_temporal_attention_blocks > 0:
# 第三步
temporal_roi_feats = \
self.temporal_attentional_feature_aggregation(
roi_feats, ref_roi_feats)
else:
temporal_roi_feats = torch.cat((roi_feats, ref_roi_feats),
dim=0)
temporal_roi_feats = temporal_roi_feats.mean(dim=0)
return temporal_roi_featsTemporal RoI Align 的实现方式在 $MMTracking/mmtrack/models/roi_heads/roi_extractors/temporal_roi_align.py 下可以找到,在这里我们只将 forward 函数以及两个核心函数的 docstring 翻译并贴进来。
在 forward 函数中,输入(input)通常为, feats :当前帧的特征图,rois:当前帧的proposals,ref_feats:其它帧的特征图。forward 函数的步骤根据算法原理主要也分为三步:
第一步: roi_feats = super().forward(feats, rois, roi_scale_factor) 提取 RoI Features
第二步:ref_roi_feats = self.most_similar_roi_align(roi_feats, ref_feats[-1])提取 Most Similar RoI Feautres,这里我们将self.most_similar_roi_align 函数的 docstring 贴上来,来方便大家了解函数内部的处理逻辑,具体代码大家可以查看源码
第三步:temporal_roi_feats = self.temporal_attentional_feature_aggregation(roi_feats, ref_roi_feats)聚合得到 Temporal RoI Features,这里我们将self.temporal_attentional_feature_aggregation 函数的 docstring 贴上来,来方便大家了解函数内部的处理逻辑,具体代码大家可以查看源码。
更具体的实验部分大家可以参考论文,我们在 VID 与 VIS(视频个例分割)任务上,共计 3 个公开学术数据集(Dataset)上都验证了 Temporal RoI Align 的有效性。
七、写在最后
作为 MM 系列的成员, MMTracking 要持续更新,力图早日成长为一个完善的视频目标感知平台,而社区的声音能够帮助我们更好地了解到大家的需求,所以如果大家在使用的过程中遇到什么问题、想法、建议,或者有想支持的新数据集(Dataset)、新方法、新任务,欢迎在评论区里发言。
请记住我们的 repo 是您永远的家!喜欢MMTracking,就请 Star Star哦 :
同时我们非常欢迎对计算机视觉(Computer vision)前沿技术、开源项目开发有兴趣的同学以全职或实习的身份加入 OpenMMLab 团队。
欢迎大家联系小编我,或者将简历发送至 hr@openmmlab.com。更多岗位可以了解:
版权声明:本文为博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!