文章目录
1. 介绍
pytorch 多GPU并行训练原理介绍,参考我之前的博客: pytorch中使用多GPU并行训练。
1.1 多GPU训练的命令
(1)指定使用GPU:0运行脚本
方式1:
CUDA_VISIBLE_DEVICES=0 python ***.py
方式2:在python脚本文件中添加如下内容进行指定
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
如果在脚本文件中已经写明了第二种方式,则不支持第一种方式的指定
(2) 指定使用多张显卡运行脚本
在GPU的id为0和1的两张显卡上运行***.py程序
CUDA_VISIBLE_DEVICES=0,1 python ***.py
(3) 指定所有显卡一起运行脚本
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE --use_env train.py
如果提示错误:RuntimeError: The server socket has failed to listen on any local network address. The server socket has failed to bind to [::]:29500 (errno: 98 - Address already in use). The server socket has failed to bind to ?UNKNOWN? (errno: 98 - Address already in use).
则执行:
python -m torch.distributed.launch --nproc_per_node=NUM_GPUS_YOU_HAVE --master_port='29501' --use_env train.py
1.2 查看GPU状态
- 1、
单次查看
nvidia-smi
- 2、
隔一秒查看GPU状态:
watch -n 1 nvidia-smi
pytorch多GPU训练启动方式
- 第一种:torch.distributed.launch
- 第二种: torch.multiprocessing
第一种:torch.distributed.launch,相比于第二种torch.multiprocessing代码量会更少一点,启动速度会更快一点。
项目代码
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/train_multi_GPU,项目中实现了两种GPU启动的方式:
train_multi_gpu_using_launch.py,是基于torch.distributed.launch方法启动的train_multi_gpu_using_spawn.py,是基于torch.multiprocessing方法启动的,这两个脚本只是在启动方式有些差异,但是在功能函数部分基本上是一模一样的,本文以train_multi_gpu_using_launch.py脚本进行介绍。
2. 代码讲解
2.1单GPU训练
在train_multi_GPU中作为参考,首先提供了一个train_single_GPU.py使用单GPU训练的脚本。
训练参数说明
num_classes:训练的类别个数,采用的是花朵数据集,所以默认类别数是5epochs:默认30轮batch-size:默认是16lr: 初始学习率,默认是0.001lrf:最终学习率的倍率因子,默认为0.1。训练到最后,学习率会降到初始学习率的1/10data_path: 花朵数据集保存的路径,数据集下载weight:预训练权重,我这里给的是官方在ImageNet上训练好的resnet34, 权重下载,我这边是没有使用预训练权重,是从0开始训练的。freeze-layers: 是否去冻结全连接层之前的所有网络,默认设置为False,如果设置为True的话仅仅会训练最后一个全连接层。device:默认cuda,因为脚本是基于单GPU进行训练
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.001)
parser.add_argument('--lrf', type=float, default=0.1)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default="/home/w180662/my_project/my_github/data_set/flower_data/flower_photos")
# resnet34 官方权重下载地址
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
parser.add_argument('--weights', type=str, default='resNet34.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
训练脚本
main函数
- 1. 首先判断有没有可用的GPU,如果有的话,将设备指定为我们传入的GPU中
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
- 2. 实例化
Tensorboard:我们会在Tensorboard中写入我们训练过程中的损失以及验证集的准确率,还有学习率的变化曲线
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
- 3. 自定义数据集:数据集划分、训练和验证数据集的预处理、实例化数据集、Dataloader
train_info, val_info, num_classes = read_split_data(args.data_path)
train_images_path, train_images_label = train_info
val_images_path, val_images_label = val_info
# check num_classes
assert args.num_classes == num_classes, "dataset num_classes: {}, input {}".format(args.num_classes,
num_classes)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_data_set = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_data_set = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_data_set.collate_fn)
val_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_data_set.collate_fn)
- 4. 载入预训练权重
1 ) 实例化模型,传入指定的类别数args.num_classes
model = resnet34(num_classes=args.num_classes).to(device)
2 ) 载入模型权重:通过toch.load载入之后,它是有序字典的形式。 遍历权重的有序字典,每遍历一层都会与我们当前model它的权重信息进行对比,我们这里简单粗暴对比两者的权重个数是否一样的。如果一样的话就保存到load_weights_dict当中,如果不一样就不会保存到字段道中。原预训练权重是基于imagenet上训练的,所以全连接层类别个数是1000,我们这里是5,所以最后一层是不匹配的,因此不会将全连接层的权重保存到load_weights_dict中,这样载入就不会出问题。然后我们的model通过load_state_dict去载入权重字典。
if args.weights != "":
if os.path.exists(args.weights):
weights_dict = torch.load(args.weights, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
print(model.load_state_dict(load_weights_dict, strict=False))
else:
raise FileNotFoundError("not found weights file: {}".format(args.weights))
3 ) 冻结权重:如果args.freeze_layers为True的话,就会冻结除fc(全连接)以外的整个网络,如果为False的话就直接训练整个网络权重。
4 ) 将需要梯度更新的参数(require_grad为True),对于参数require_grad为False说明已经被冻结了,就不需要去管它了。然后定义优化器optimizer,传入需要更新的参数,指定初始学习率lr,动量momentum,还有正则项weight_decay.接下来定义了cosine学习率的曲线,然后通过pytorch的LambdaLR方法,传入优化器,然后再指定一个学习率变化的函数,也就是我们定义的lambda函数
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
cosine学习率变化曲线
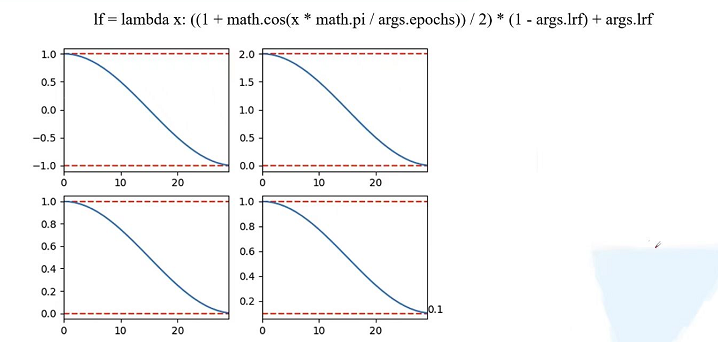
x*math.pi/args.epochs的取值在[0,pi]之间,因此math.cos(x*math.pi/args.epochs)取值范围[-1,1],对它加上1之后 1+math.cos(x*math.pi/args.epochs)的取值在[0,2] ,然后又除以2,取值范围[0,1],然后再乘以(1-args.lrf)加上args.lrf,最终的取值范围就在[args.lrf,1],假设初始化的学习率为为1,最终的学习率为初始化的args.lrf。我们这里设置args.lrf为0.1,也就是学习率会呈现余弦变换,最终迭代了epochs后,最终的学习率变为初始学习率的0.1(args.lrf)倍
- 5. 训练
训练迭代Epoch轮,每一轮会调用train_one_epoch来进行训练
def train_one_epoch(model, optimizer, data_loader, device, epoch):
model.train()
loss_function = torch.nn.CrossEntropyLoss()
mean_loss = torch.zeros(1).to(device)
optimizer.zero_grad()
# 在进程0中打印训练进度
if is_main_process():
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
loss = loss_function(pred, labels.to(device))
loss.backward()
loss = reduce_value(loss, average=True)
mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses
# 在进程0中打印平均loss
if is_main_process():
data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
if not torch.isfinite(loss):
print('WARNING: non-finite loss, ending training ', loss)
sys.exit(1)
optimizer.step()
optimizer.zero_grad()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
return mean_loss.item()
train_one_epoch主要的代码讲解如下:
1 ) 通过model.train()方法进入训练模式,定义损失函数CrossEntropyLoss,清空优化器的梯度信息optimizer.zero_grad()
model.train()
loss_function = torch.nn.CrossEntropyLoss()
mean_loss = torch.zeros(1).to(device)
optimizer.zero_grad()
2 ) 判断当前进程是否是主进程,也就是进程0。由于我们是单GPU训练脚本,当前进程肯定是一个主进程。使用tqdm库来封装data_loader,调用的时候会打印进度条,当使用多GPU的时候,我们通过以下的命令,使得只在主进程打印进度条,在其他进程中不会打印进度条。
# 在进程0中打印训练进度
if is_main_process():
data_loader = tqdm(data_loader, file=sys.stdout)
3 ) 遍历数据,获取图像数据和标签,并将图像指定相应的GPU设备中,传入model正向传播得到预测输出pred,将输出pred与真实标签label计算损失,然后将损失进行反向传播,然后对历史的损失求平均。
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
loss = loss_function(pred, labels.to(device))
loss.backward()
loss = reduce_value(loss, average=True) # 这句是针对多GPU场景使用的,在单GPU中这句话其实是不起作用的
mean_loss = (mean_loss * step + loss.detach()) / (step + 1) # update mean losses # 更新平均损失
通过data_loader的desc参数,这样的话就可以显示当前平均损失的值了
data_loader.desc = "[epoch {}] mean loss {}".format(epoch, round(mean_loss.item(), 3))
4 ) 通过optimizer.step(),利用optimizer优化器去对该step的参数进行更新,然后将优化器的梯度清空。
optimizer.step()
optimizer.zero_grad()
同步多个设备之间的进度,最后会返回该轮的平均损失。
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
执行完train_one_epoch,返回train_single_gpu.py脚本。
执行 schedler.step(),根据定义好的schedler调整策略去更新学习率。然后进入evaluate方法中
- 6. 验证
每个epoch,包含训练过程和验证过程。训练完一个epoch之后紧接着进行evaluate,跳入到evaluate函数中进行代码讲解
def evaluate(model, data_loader, device):
model.eval()
# 用于存储预测正确的样本个数
sum_num = torch.zeros(1).to(device)
# 在进程0中打印验证进度
if is_main_process():
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
sum_num = reduce_value(sum_num, average=False)
return sum_num.item()
- 1)通过
model.eval()来进入到我们的验证模式,进入验证模式之后,它就会关闭BN以及Dropout方法。注意这里使用了torch.no_grad装饰器,在验证过程中我们通常会使用一个with torch.no_grad()上下文管理器,这里可以通过torch.no_grad装饰器实现相同的功能。 - 2)在主进程中包装
data_loader,这样在进程0中会打印验证进度,接着遍历我们的数据,得到图像和标签,图像指定的设备,并输入模型进行正向传播得到预测结果,然后求得预测概率最大的值对应的索引,与真实标签对比获得预测正确的样本个数。
# 在进程0中打印验证进度
if is_main_process():
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
- 3)在迭代完成之后,如果我们使用的是多GPU的话,我们会对所有设备的进程同步,其中
reduce_vale这个也是在多GPU情况下才会使用到的,单GPU不起作用。然后返回统计到预测正确的样本总和
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
sum_num = reduce_value(sum_num, average=False)
执行完 evaluate函数之后,获得正确的样本数,然后除以总的样本个数,就得到准确率了。
acc = sum_num / (val_data_set)
然后通过tensorboard将当前epoch求得的mean_loss,还有准确率acc,还有学习率lr,将他们写入到tensorboard中,最后保存下当前epoch训练完后的权重
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
2.2多GPU训练
对应的脚本为torch_multi_gpu_using_launch.py, 另外一个多GPU的脚本train_multi_gpu_using_spawn.py有兴趣可以看看,其实是差不多的
训练参数说明
- 训练参数:
num_classes,epochs,batch-size,lr,lrf和单GPU脚本的训练参数是一样的,这里就不进行介绍了。但是使用多GPU会引入一个新的参数syncBN,用来同步BN的参数,这里默认设置为True,不想使用的话可以设置为False,因为使用了同步BN,对我们训练速度是有一定影响的。 - 参数
device,world-size,dist-url,注意这3个参数按照默认的即可,不用去修改,特别是device默认成cuda 就好了。
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=30)
parser.add_argument('--batch-size', type=int, default=16)
parser.add_argument('--lr', type=float, default=0.001)
parser.add_argument('--lrf', type=float, default=0.1)
# 是否启用SyncBatchNorm
parser.add_argument('--syncBN', type=bool, default=True)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str, default="/home/wz/data_set/flower_data/flower_photos")
# resnet34 官方权重下载地址
# https://download.pytorch.org/models/resnet34-333f7ec4.pth
parser.add_argument('--weights', type=str, default='resNet34.pth',
help='initial weights path')
parser.add_argument('--freeze-layers', type=bool, default=False)
# 不要改该参数,系统会自动分配
parser.add_argument('--device', default='cuda', help='device id (i.e. 0 or 0,1 or cpu)')
# 开启的进程数(注意不是线程),不用设置该参数,会根据nproc_per_node自动设置
parser.add_argument('--world-size', default=4, type=int,
help='number of distributed processes')
parser.add_argument('--dist-url', default='env://', help='url used to set up distributed training')
opt = parser.parse_args()
主函数介绍
- 1. 首先判断有没有可用的GPU,如果没有的话,这边会报错提醒,因为我们的脚本对针对多
GPU训练的场景的。
if torch.cuda.is_available() is False:
raise EnvironmentError("not find GPU device for training.")
- 2. 初始化各进程环境
def init_distributed_mode(args):
if 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
args.rank = int(os.environ["RANK"])
args.world_size = int(os.environ['WORLD_SIZE'])
args.gpu = int(os.environ['LOCAL_RANK'])
elif 'SLURM_PROCID' in os.environ:
args.rank = int(os.environ['SLURM_PROCID'])
args.gpu = args.rank % torch.cuda.device_count()
else:
print('Not using distributed mode')
args.distributed = False
return
args.distributed = True
torch.cuda.set_device(args.gpu)
args.dist_backend = 'nccl' # 通信后端,nvidia GPU推荐使用NCCL
print('| distributed init (rank {}): {}'.format(
args.rank, args.dist_url), flush=True)
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
dist.barrier()
可以看到这函数中有RANK,WORLD_SIZE,因为distribute_dataparallel它是可以使用在多机多卡场景,也可以使用在单机多卡场景。
-
对于
多机多卡场景,world_size对应于所有机器中使用的进程数量也就是GPU数量(一个进程对应一块GPU);RANK代表所有进程中的第几个进程,LOCAL_RANK对应当前机器中第几个进程,也就是某一台机器上第几块GPU设备。 -
对于单机多卡的情形,
WORLD_SIZE表示总的GPU数量,RANK就是哪块GPU,此时LOCAL_RANK(当前机器的第几块GPU) 跟我们的RANK是一样的,因为是单机多卡。 -
多GPU启动指令:
python -m torch.distributed.launch --nproc_per_node=8 --use_env train_multi_gpu_using_launch.py,指令,nproc_per_node参数为使用GPU数量 。我们使用了use_env传入了这个参数,它就会在环境变量中存入一系列参数,包括RANK,WORLD_SIZE,LOCAL_RANK -
对于
init_distributed_mode,首先从环境变量中获得RANK,WORLD_SIZE,并将字符类型转换为整行。并将LOCAL_RANK传入args.gpu这个变量。 -
然后将
args.distribute设置为True,并对当前进程指定它所使用的GPU,定义了一个参数args.dist_backend并赋值为nccl,对于nvida的GPU推荐使用的是NCCL的通信后端。 -
通过
dist.init_process_group创建进程组,传入dist_backend(通信后端NCCL),dist_url,world_size,rank参数。然后定义dist.barrier()等待每块GPU都运行到这个地方之后,再接着往下走。
初始化进程环境后,对参数进行赋值,其中学习率args.lr *=args.world_size,当我们使用多GPU并行的时候,由于梯度一般在多块GPU上取一个均值,所以一般我们会对学习率进行增大。这里就简单粗暴的进行设置,用几块GPU就将学习率扩大几倍。
args.lr *= args.world_size # 学习率要根据并行GPU的数量进行倍增
- 3. 训练
1 ) 当进程等于0的时候,也就是主进程,我们会在主进程打印args参数,然后实例化tensorboard,然后会在tensorboard中写入一系列参数。像一般写入操作、保存操作一般都是放在主进程中。没必要在每个进程中,都去执行相同的操作。
if rank == 0: # 在第一个进程中打印信息,并实例化tensorboard
print(args)
print('Start Tensorboard with "tensorboard --logdir=runs", view at http://localhost:6006/')
tb_writer = SummaryWriter()
if os.path.exists("./weights") is False:
os.makedirs("./weights")
2 ) 数据预处理和实例化数据集
train_info, val_info, num_classes = read_split_data(args.data_path)
train_images_path, train_images_label = train_info
val_images_path, val_images_label = val_info
# check num_classes
assert args.num_classes == num_classes, "dataset num_classes: {}, input {}".format(args.num_classes,
num_classes)
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_data_set = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_data_set = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
这些代码是一样的,是单GPU不一样的,这里使用了DistributedSampler,这个函数通过鼠标左键找不到它的定义。我们可以复制DistributedSampler这个关键词去pytorch官网中Docs文档中去搜索一下:
然后点击torch.utils.data.distributed.DistributedSampler就能看到对应参数的介绍,点击SOURCE也可以查看到源码
DistributedSampler说明
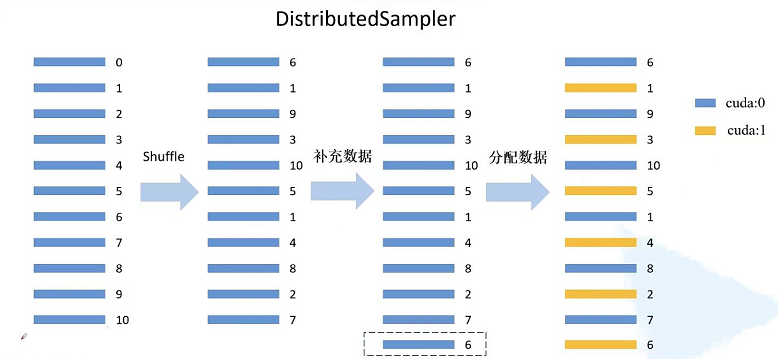
假设我们当前数据集一共有11个样本,序号为0-10. 通过查看DistributedSampler的源码给的信息知道:第一步会通过shuffle处理打扰数据,假设有2块GPU进行并行计算,首先会通过11/2并进行向上取整,在乘以GPU的个数就等于12.由于只有11个数据,差一个数据,我们就从头开始补数据,将第一个数据补充到最后面,这样就有12个数据,这样就能够均衡的分配到每个GPU设备中。将数据间隔的分配到不同的设备中,标蓝色的表示分配给第一块GPU,标橙色的表示分配给第二块GPU。这样就将整个数据集的数据均分到每块GPU上了。
然后对train_sampler做进一步处理,打包为一个个batch,如果batch_size=2的话,就将数据2个2个一组打包为batch。如果最后的数据不够一个batch,通过设置drop_last=True就将最后不足一个batch的数据给丢掉了。
# 将样本索引每batch_size个元素组成一个list
train_batch_sampler = torch.utils.data.BatchSampler(
train_sampler, batch_size, drop_last=True)
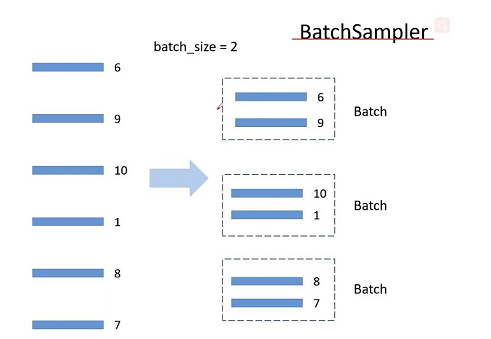
dataloader
dataloader中传入了刚刚定义好的train_batch_sampler,对于验证集的dataloader由于没有使用batch_sampler打包为一个个batch,因此直接传入val_sampler
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
if rank == 0:
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_data_set,
batch_sampler=train_batch_sampler,
pin_memory=True,
num_workers=nw,
collate_fn=train_data_set.collate_fn)
val_loader = torch.utils.data.DataLoader(val_data_set,
batch_size=batch_size,
sampler=val_sampler,
pin_memory=True,
num_workers=nw,
collate_fn=val_data_set.collate_fn)
3 ) 模型载入预训练权重
# 实例化模型
model = resnet34(num_classes=num_classes).to(device)
# 如果存在预训练权重则载入
if os.path.exists(weights_path):
weights_dict = torch.load(weights_path, map_location=device)
load_weights_dict = {k: v for k, v in weights_dict.items()
if model.state_dict()[k].numel() == v.numel()}
model.load_state_dict(load_weights_dict, strict=False)
else:
checkpoint_path = os.path.join(tempfile.gettempdir(), "initial_weights.pt")
# 如果不存在预训练权重,需要将第一个进程中的权重保存,然后其他进程载入,保持初始化权重一致
if rank == 0:
torch.save(model.state_dict(), checkpoint_path)
dist.barrier()
# 这里注意,一定要指定map_location参数,否则会导致第一块GPU占用更多资源
model.load_state_dict(torch.load(checkpoint_path, map_location=device))
判断是否有权重文件,有权重就载入。如果没有权重的话,由于使用多GPU训练我们必须保证每个设备上它初始的权重是一模一样的。如果初始化权重不一样的话,那么各个GPU上所取得的梯度,就不是针对同一组参数。如果我们没有载入预训练权重,我们要保证每块GPU上的初始变量是一模一样的。这里我们会在主进程保存我们模型初始化的权重,然后在不同设备上载入我们在主进程中保留下来的权重文件。这样我们就能够保证,在开始训练时,各个GPU对应的模型权重都是一模一样的。
4 ) 冻结权重,同步BN
和单GPU的脚本是一样的,对除fc以外的权重进行冻结。如果不冻结权重的话,需要判断是否使用具有同步功能的BN,如果args.syncBN为True的话,就使用下面的命令同步模型。
# 使用SyncBatchNorm后训练会更耗时
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
就会将模型中所有的BN替换为具有同步功能的BN了,然后再指认到我们的设备中。如果我们冻结权重,只有全连接层可训练,但全连接层没有BN,这里使用同步的BN是没有意义的。所以这里只有训练所有权重,并且权重中有BN层的时候,才会去考虑使用具有同步功能的BN层。
5 ) 训练
使用torch.nn.parallel.DistributedDataParallel去包装我们的模型,通过这个方法包装后,模型就可以在各个设备间进行通信了。
然后通过遍历获得需要学习更新的参数,指定SGD优化器,初始学习率args,lr,动量和正则项weight_decay,同样设置cosine学习率变化曲线。
# 转为DDP模型
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
# optimizer
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(pg, lr=args.lr, momentum=0.9, weight_decay=0.005)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
lf = lambda x: ((1 + math.cos(x * math.pi / args.epochs)) / 2) * (1 - args.lrf) + args.lrf # cosine
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
通过train_sampler.set_epoch(epoch)通过BatchSampler组合的一个个Batch的数据是不一样的。这样的话不同设备在每一轮获得的数据就不一样。因为打扰数据的随机种子中传入了self.epoch,从而利用epoch实现每个epoch获得的数据是不一样的.
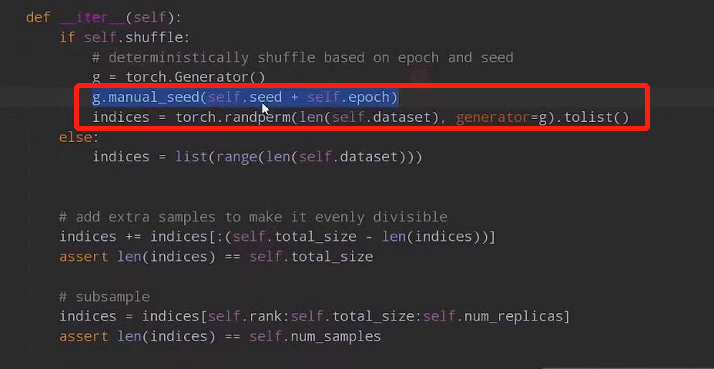
接下来介绍train_one_epoch与单GPU的train_one_epoch之间的差异。
loss = reduce_value(loss,average = True)
在单GPU中这一行代码是不起作用的,针对多GPU的平均损失应该是所有设备的损失的均值,跟单GPU中单设备的损失不同。通过reduce_value求得所有设备损失的均值。
def reduce_value(value, average=True):
world_size = get_world_size()
if world_size < 2: # 单GPU的情况
return value
with torch.no_grad():
dist.all_reduce(value)
if average:
value /= world_size
return value
- 首先在
reduce_value这个函数中,我们会求得world_size这个参数,也就是GPU数量,如果world_size<2,说明是单GPU的情况,就直接返回它的参数。所以在单GPU情况下reduce_value是不起任何作用的。 - 对于多GPU情况下,我们会通过
all_reduce这个方法,去对不同设备之间的value(loss)求和,所以通过all_reduce就求得所有device的value(loss)总和,如果average为True的话,就将value/world_size,我们得到的value(loss)值就是多个GPU设备之间的均值
5 ) 验证 evalute
def evaluate(model, data_loader, device):
model.eval()
# 用于存储预测正确的样本个数
sum_num = torch.zeros(1).to(device)
# 在进程0中打印验证进度
if is_main_process():
data_loader = tqdm(data_loader, file=sys.stdout)
for step, data in enumerate(data_loader):
images, labels = data
pred = model(images.to(device))
pred = torch.max(pred, dim=1)[1]
sum_num += torch.eq(pred, labels.to(device)).sum()
# 等待所有进程计算完毕
if device != torch.device("cpu"):
torch.cuda.synchronize(device)
sum_num = reduce_value(sum_num, average=False)
return sum_num.item()
evalue方法中和单GPU不同的地方,就是在预测正确样本个数存在不同。使用多GPU的时候,每个GPU都会计算它自己对应那一部分训练集预测正确的样本个数,最后是需要对所有GPU预测正确个数进行求和的,这样才能求得在验证集上预测正确的样本总和。所以通过reduce_value这个方法来对它求和,这里average就设置为False,为False的话返回来的就是多个设备之间预测的正确数之和,而不是平均了。
sum_num = reduce_value(sum_num, average=False)
求的预测正确数之和,然后除以val_sampler.total就得到准确率了。最后在主进程中通过tensorboard保存平均损失mean_loss,精度acc,学习率lr, 同时在主进程中保存每个epoch的权重参数
sum_num = evaluate(model=model,
data_loader=val_loader,
device=device)
acc = sum_num / val_sampler.total_size
if rank == 0:
print("[epoch {}] accuracy: {}".format(epoch, round(acc, 3)))
tags = ["loss", "accuracy", "learning_rate"]
tb_writer.add_scalar(tags[0], mean_loss, epoch)
tb_writer.add_scalar(tags[1], acc, epoch)
tb_writer.add_scalar(tags[2], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.module.state_dict(), "./weights/model-{}.pth".format(epoch))
最后还需要注意一点,当我们从头开始训练我们在我们主进程中生成了一个初始化权重保存为临时文件,训练完成好需要将该临时文件移除。最后会调用cleanup去destory进程组,训练完之后将资源释放。
# 删除临时缓存文件
if rank == 0:
if os.path.exists(checkpoint_path) is True:
os.remove(checkpoint_path)
cleanup()
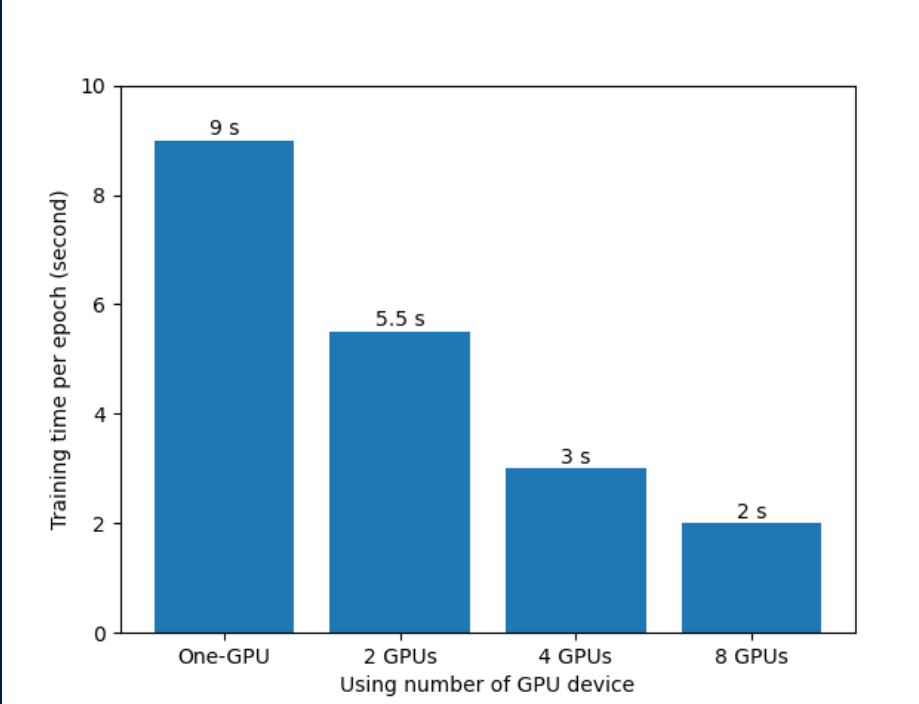
3. 训练时间对比
使用python -m torch.distributed.launch --nproc_per_node=8 --use_env train_multi_gpu_using_launch.py启动多GPU训练,对于单机多卡的情况nproc_per_nod对应的就是GPU的数量。use_env将GPU信息写入环境变量中
不同GPU数,推理时间对比
4 .源码
下载地址:https://download.csdn.net/download/weixin_38346042/86768878?spm=1001.2014.3001.5501
文章出处登录后可见!