这里说一下常规的在kaggle上创建jupyter notebook
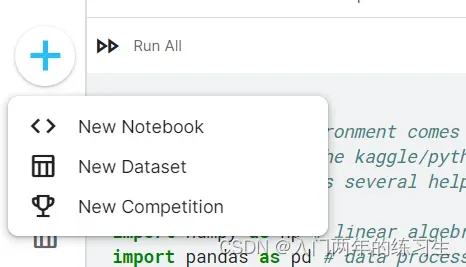
点击New Notebook后,进入一个空的Notebook,可以在Data处创建上传要进行处理的数据。
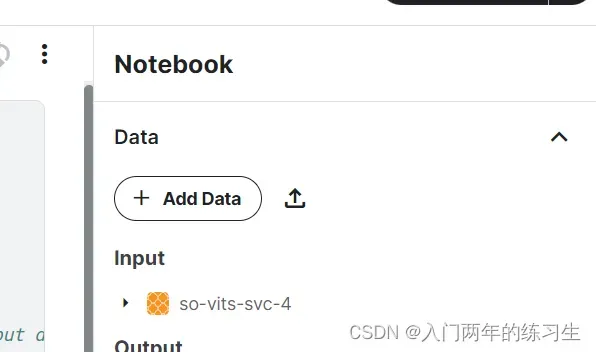
其中可以选择本地上传,也可以直接点击Add Data进行查找开源的数据。
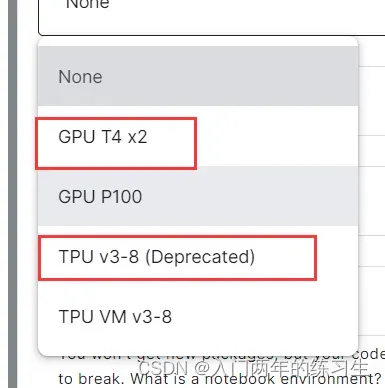
点击ACCELERATOR可以选择要使用的GPU或TPU。如果不选择默认是使用自己笔记本的cpu
保存:
torch.save(date,path)
其中date为保存数据,path为路径加文件名,如:torch.save(date, ‘/kaggle/working’+”.pt”)
加载
torch.load('/kaggle/working/07pt')直接选择路径下的文件名进行load
在output上删除已经存在的pt文件
import shutil
import os
if __name__ == '__main__':
path = '/kaggle/working'
if os.path.exists(path):
shutil.rmtree(path)
print('删除完成')
else:
print('原本为空')直接在code上进行运行,即可删除所有working下的文件,选择删除其他路径的文件只需要进行改变path
这里在来介绍一下GPU和CPU
GPU
GPU这个概念是由Nvidia公司于1999年提出的。GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片。那么1999年之前显卡上就没有GPU吗?当然有,只不过那时候没有人给它命名,也没有引起人们足够的重视,发展比较慢。
自Nvidia提出GPU这个概念后,GPU就进入了快速发展时期。简单来说,其经过了以下几个阶段的发展:
1)仅用于图形渲染,此功能是GPU的初衷,这一点从它的名字就可以看出:Graphic Processing Unit,图形处理单元;
2)后来人们发现,GPU这么一个强大的器件只用于图形处理太浪费了,它应该用来做更多的工作,例如浮点运算。怎么做呢?直接把浮点运算交给GPU是做不到的,因为它只能用于图形处理(那个时候)。最容易想到的,是把浮点运算做一些处理,包装成图形渲染任务,然后交给GPU来做。这就是GPGPU(General Purpose GPU)的概念。不过这样做有一个缺点,就是你必须有一定的图形学知识,否则你不知道如何包装。
3)于是,为了让不懂图形学知识的人也能体验到GPU运算的强大,Nvidia公司又提出了CUDA的概念。
什么是CUDA?
CUDA(Compute Unified Device Architecture),通用并行计算架构,是一种运算平台。它包含CUDA指令集架构以及GPU内部的并行计算引擎。你只要使用一种类似于C语言的CUDA C语言,就可以开发CUDA程序,从而可以更加方便的利用GPU强大的计算能力,而不是像以前那样先将计算任务包装成图形渲染任务,再交由GPU处理。
TPU(Tensor Processing Unit)即张量处理单元,是一款为机器学习而定制的芯片,经过了专门深度机器学习方面的训练,它有更高效能(每瓦计算能力)。
因为它能加速其第二代人工智能系统TensorFlow的运行,而且效率也大大超过GPU――Google的深层神经网络就是由TensorFlow引擎驱动的。TPU是专为机器学习量身定做的,执行每个操作所需的晶体管数量更少,自然效率更高。
TPU与同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。
TPU每瓦能为机器学习提供比所有商用GPU和FPGA更高的量级指令,这基本相当于7年后的科技水平。TPU是为机器学习应用特别开发,以使芯片在计算精度降低的情况下更耐用,这意味每一个操作只需要更少的晶体管,用更多精密且大功率的机器学习模型,并快速应用这些模型,因此用户便能得到更正确的结果。
二者的应用的优势不同,可根据不同的需求来进行选择
文章出处登录后可见!