一、机器学习
1.1 机器学习定义
计算机程序从经验E中学习,解决某一任务T,进行某一性能P,通过P测定在T上的表现因经验E而提高
eg:跳棋程序
E: 程序自身下的上万盘棋局
T: 下跳棋
P: 与新对手下跳棋时赢的概率
1.2 监督学习
1.2.1 监督学习定义
给算法一个数据集,其中包含了正确答案,算法的目的是给出更多的正确答案
1.2.2 例1:预测房价(回归问题)
回归问题目的: 预测连续的数值输出
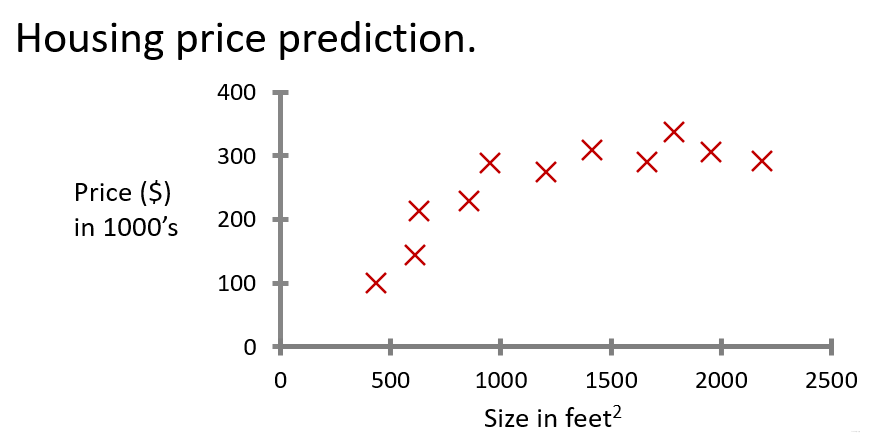
1. 用直线拟合
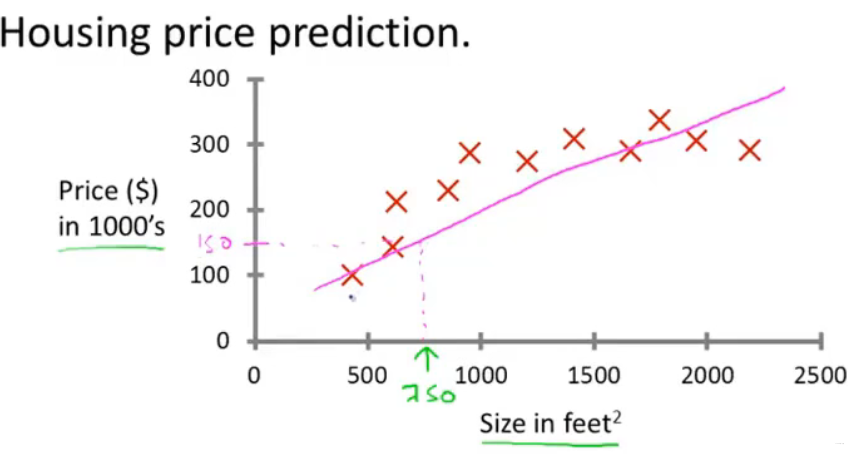
2. 用二次函数或二阶多项式拟合(效果更佳)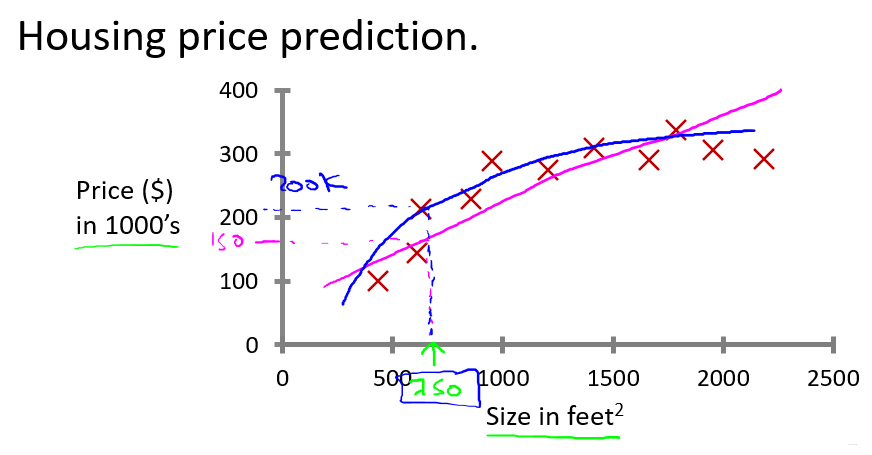
1.2.3 例2:预测肿瘤是良性或恶性(分类问题)
分类问题目的: 预测离散值输出。
就本问题而言,结果只有0和1的输出。
1. 只有一个特征时
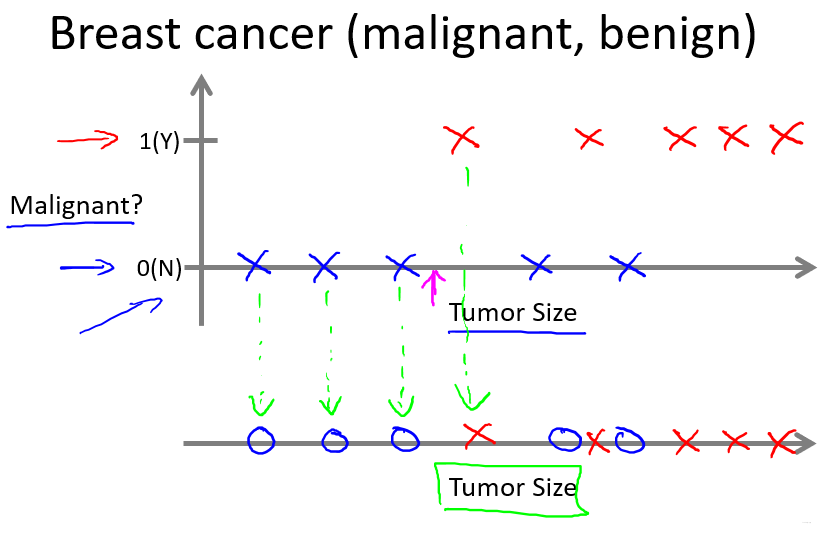
2. 有两个特征时
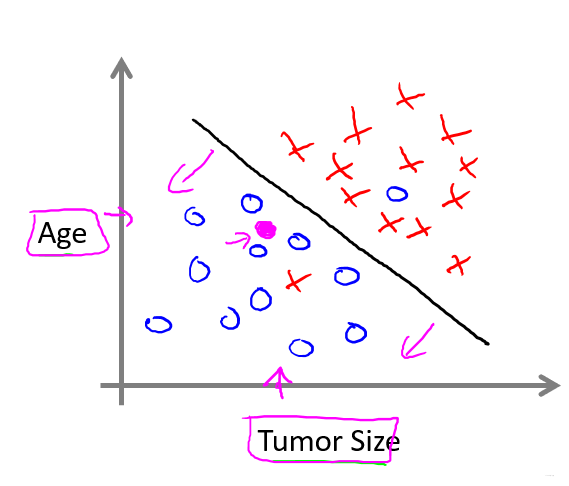
3. 算法最终的目的是解决无穷多个特征的数据集
1.3 无监督学习
1.3.1 无监督学习定义
只给算法一个数据集,但是不给数据集的正确答案,由算法自行分类。
1.3.2 聚类算法
- 谷歌新闻每天收集几十万条新闻,并按主题分好类
- 市场通过对用户进行分类,确定目标用户
- 鸡尾酒算法:两个麦克风分别离两个人不同距离,录制两段录音,将两个人的声音分离开来(只需一行代码就可实现,但实现的过程要花大量的时间)
二、单变量线性回归
2.1 线性函数
假设函数 hθ(x) = θ0 + θ1x
代价函数
J(θ0, θ1) = ( h(x(i)) − y(i))2(m表示训练样本的数量)
重新复习补充:h(x(i))是预测值,y(i)是实际值,两者取差。公式中的这个平方,似乎是最小二乘法和最佳平方/函数逼近,涉及到数值分析这一块知识,前置知识太多没去细理解,先按方差这么去理解。至于前面的中的2是为了后续求偏导更好计算。
目标: 最小化代价函数,即minimize J(θ0, θ1)
代价函数也被称为平方误差函数或者平方误差代价函数,在线性回归问题中,平方误差函数是最常用的手段
2.1.1 只考虑一个参数 θ1
为方便分析,先取θ0为0并改变θ1的值,得到多组J(θ0) = ( h(x(i)) − y(i))2,并作出下右图
得到的minimize J(θ0) 就是线性回归的目标函数

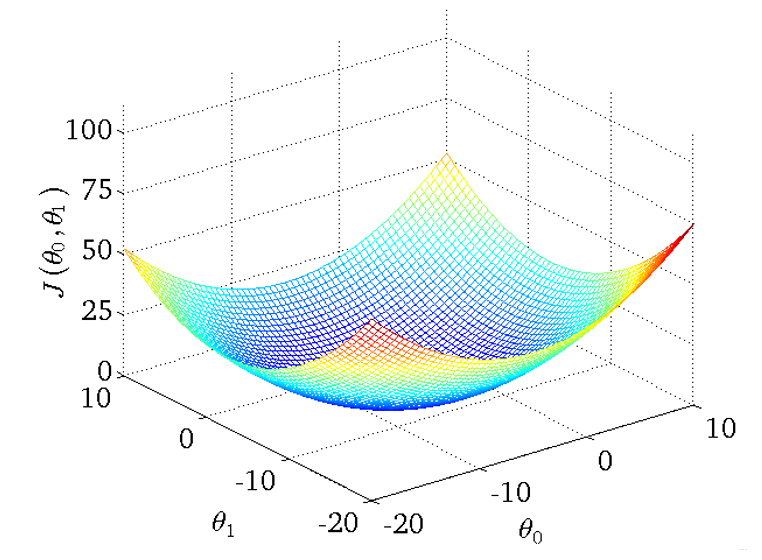
2.1.2 θ0和θ1都考虑
- 得到的三维图如下
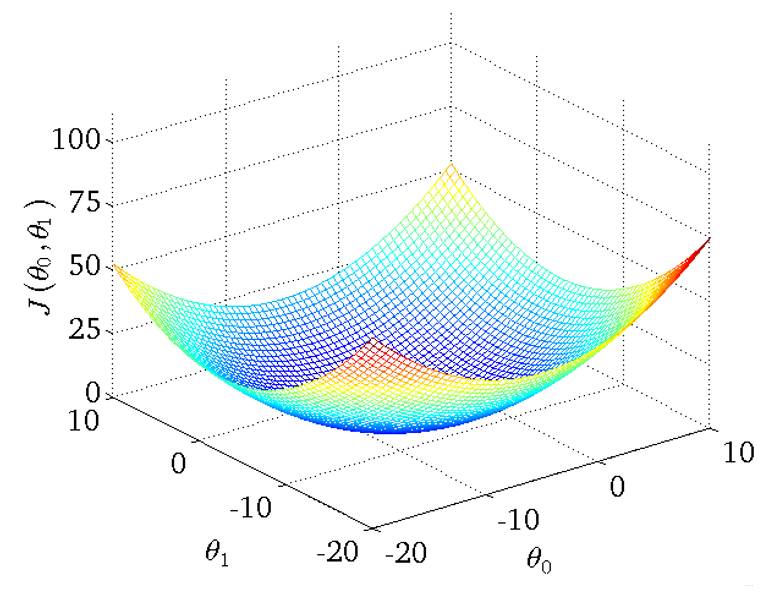
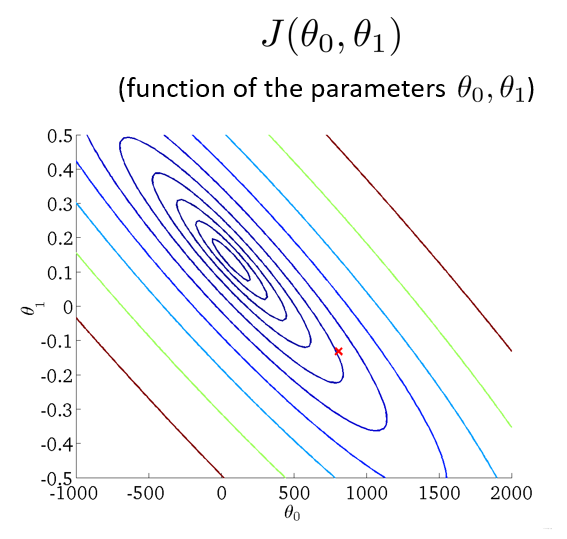
- 将三维图平面化
等高线的中心对应最小代价函数
2.2 梯度下降
算法思路
- 指定θ0 和 θ1的初始值
- 不断改变θ0和θ1的值,使J(θ0,θ1)不断减小
- 得到一个最小值或局部最小值时停止
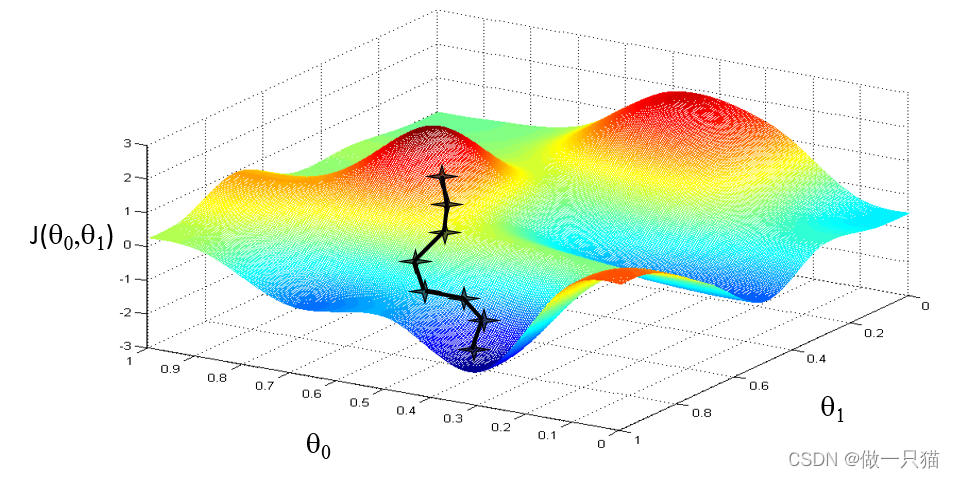
梯度: 函数中某一点(x, y)的梯度代表函数在该点变化最快的方向
(选用不同的点开始可能达到另一个局部最小值)
- θj = θj − α
J(θ0, θ1)
其中 α 为学习速率( learning rate ) - θ0和θ1应同步更新,否则如果先更新θ0,会使得θ1是根据更新后的θ0去更新的,与正确结果不相符
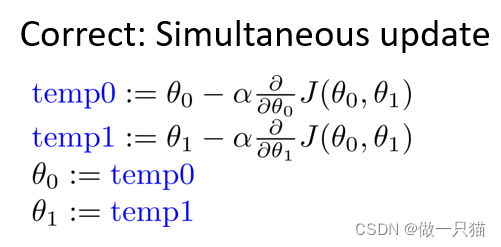
关于α
如果α选择太小,会导致每次移动的步幅都很小,最终需要很多步才能最终收敛
如果α选择太大,会导致每次移动的步幅过大,可能会越过最小值,无法收敛甚至会发散
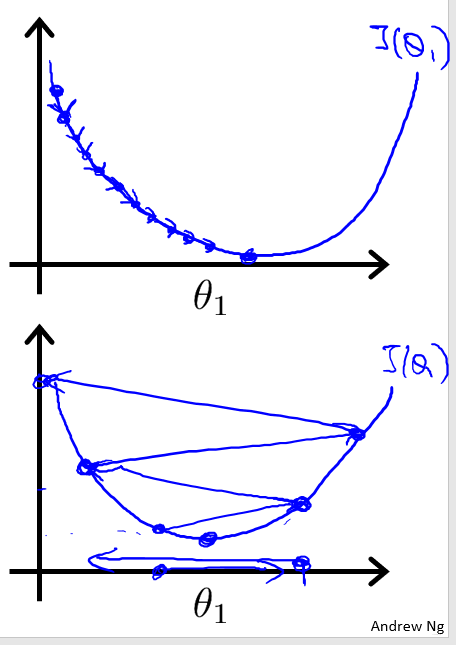
- 偏导表示的是斜率,斜率在最低点左边为负,最低点右边为正。 θj减去一个负数则向右移动,减去一个正数则向左移动
- 在移动过程中,偏导值会不断变小,进而移动的步幅也不断变小,最后不断收敛直到到达最低点
- 在最低点处偏导值为0,不再移动
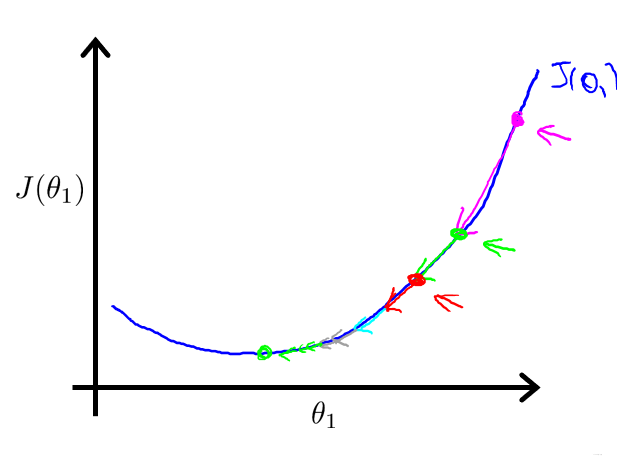
2.3 线性回归的梯度下降 / Batch梯度下降
- 公式推导:
J(θ0, θ1) = ( h(x(i)) − y(i))2 =
( (θ0 + θ1x(i)) − y(i))2
j = 0时表示对θ0求偏导
j = 1时表示对θ1求偏导
=
( (θ0 + θ1x(i)) − y(i))
=
( (θ0 + θ1x(i)) − y(i)) x(i)
x(i)的 i 表示第 i 个样本
进而更新得到:
θ0 := θ0 – α ( (θ0 + θ1x(i)) − y(i))
θ1 := θ0 – α ( (θ0 + θ1x(i)) − y(i)) x(i)
梯度回归的局限性: 可能得到的是局部最优解
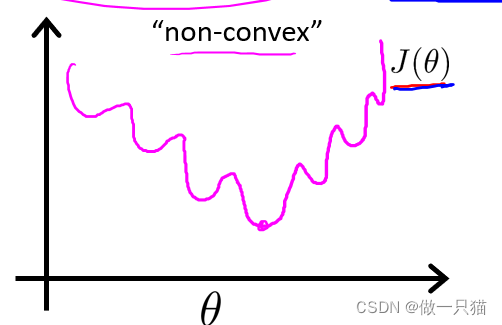
线性回归的梯度下降的函数是凸函数,因此没有局部最优解,只有全局最优解
凸函数
三、矩阵
3.1 矩阵加法和标量乘法
同维矩阵对应位置相加。
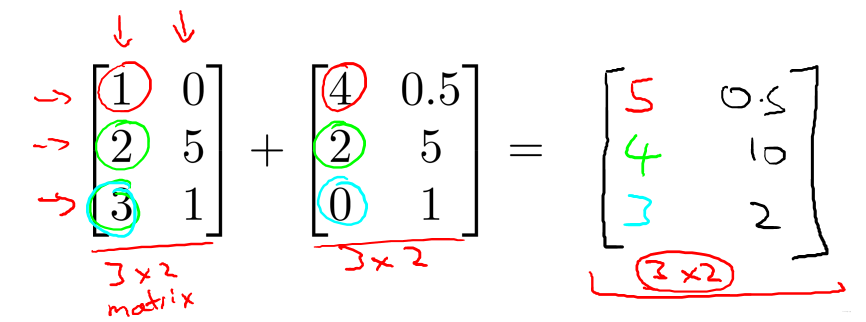
矩阵对应位置乘标量。
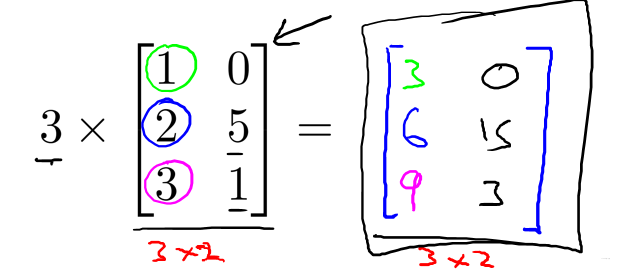
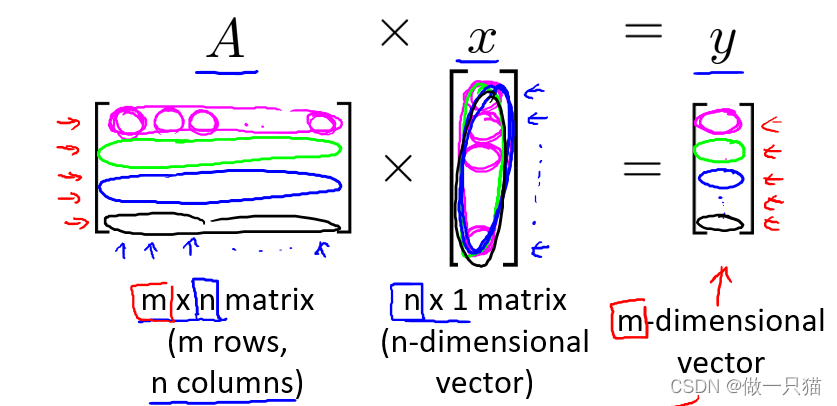
3.2 矩阵乘向量
A12表第一行第二列
A11 * x1 + A12 * x2 + A13 * x3 + …… + A1n * xn = y1
A21 * x1 + A22 * x2 + A23 * x3 + …… + A2n * xn = y2
3.2 矩阵乘法
An1 * B1b + An2 * B2b + …… + Anm * Bab = Cnb
eg:
A11 * B11 + A12 * B21 + A13 * B31 + …… + A1n * Bn1 = C11
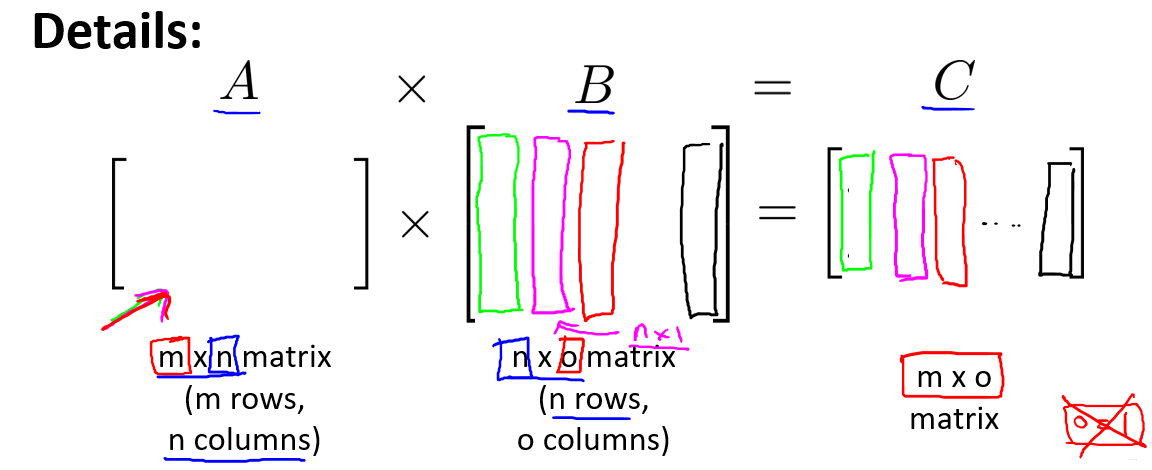
- 不满足交换律
- 满足结合律
3.3 矩阵逆和矩阵转置
单位矩阵
- 用 I 表示
- 主对角线上都是1,其余位置都是0
逆矩阵
-
用A-1 表示
-
A * A-1 = I
矩阵转置
-
用AT表示
-
Anm变为Amn
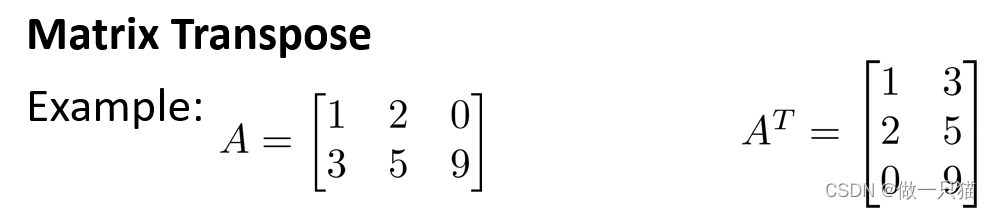
四、多变量线性回归
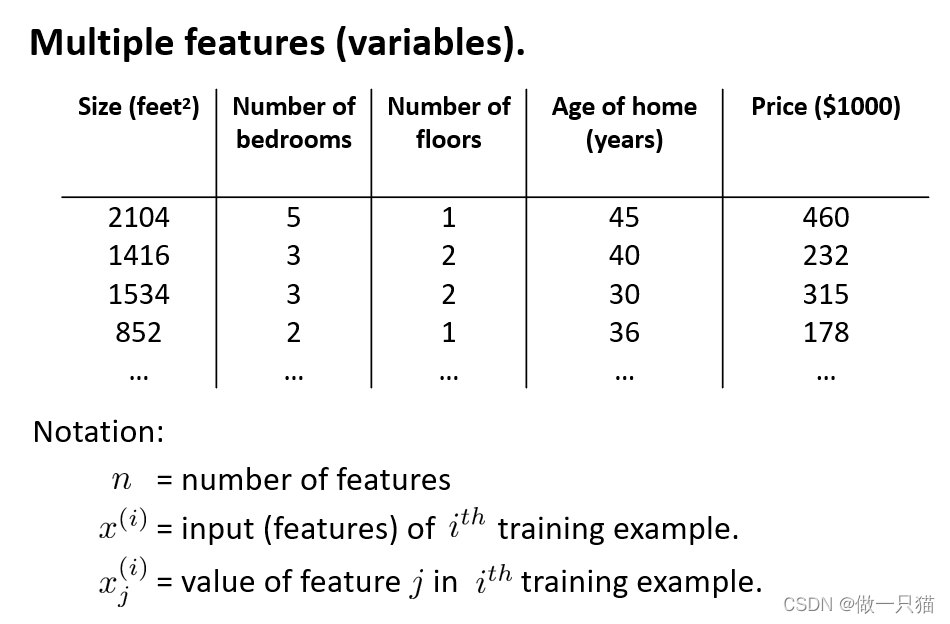
4.1 多变量线性回归假设函数
x(i) 表示第 i 组样本
xj(i) 表示第 i 组样本中的第 j 个数据
eg:
x4(2)表示第4组样本中的第2个数据,值为40
定义x0 = 1 (即θ0的系数,也即x0(i) = 1 )
则

x = [x0, x1, x2, ……, xn]T
θ = [θ0, θ1, θ2,…, θn]T, θ∈Rn+1

进而
假设函数可记作:hθ(x) = θTx
4.2 多元梯度下降法
=
( hθ(x) (i)) − y(i))x0(i)
=
( hθ(x) (i) − y(i)) x1(i)
=
( hθ(x) (i)− y(i)) x2(i)
进而更新得到:
θ0 := θ0 – α ( hθ(x) (i) − y(i))x0(i)
θ1 := θ0 – α ( hθ(x) (i)− y(i)) x1(i)
θ2 := θ0 – α (hθ(x) (i) − y(i)) x2(i)
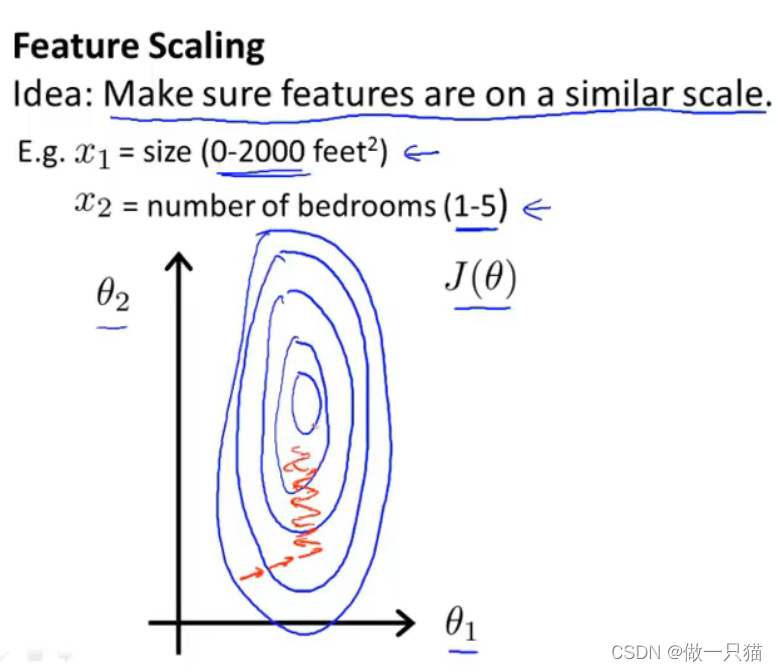
4.3 特征缩放
当特征范围相差太大时,会一直来回振荡,梯度下降效率低
(本例子中θ0不考虑)
如下例中,x1范围为0~2000, x2范围为 1~5
xi =
μ 为平均值,σ 为range(即max – min)
如下述例子
x1 =
x2 =
其中1000 和 2 是事先知道的平均值
通常计算出来的 x 最好在-3 ~ +3之间
4.4 学习率
绘制代价函数J(θ)的变化来反映下降的过程
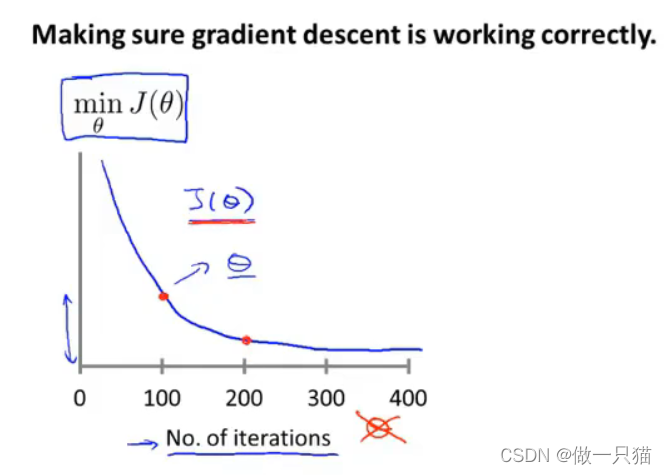
’梯度下降更新公式: θj = θj – α J(θ)
形如下左两种情况都是α选取太大导致的。
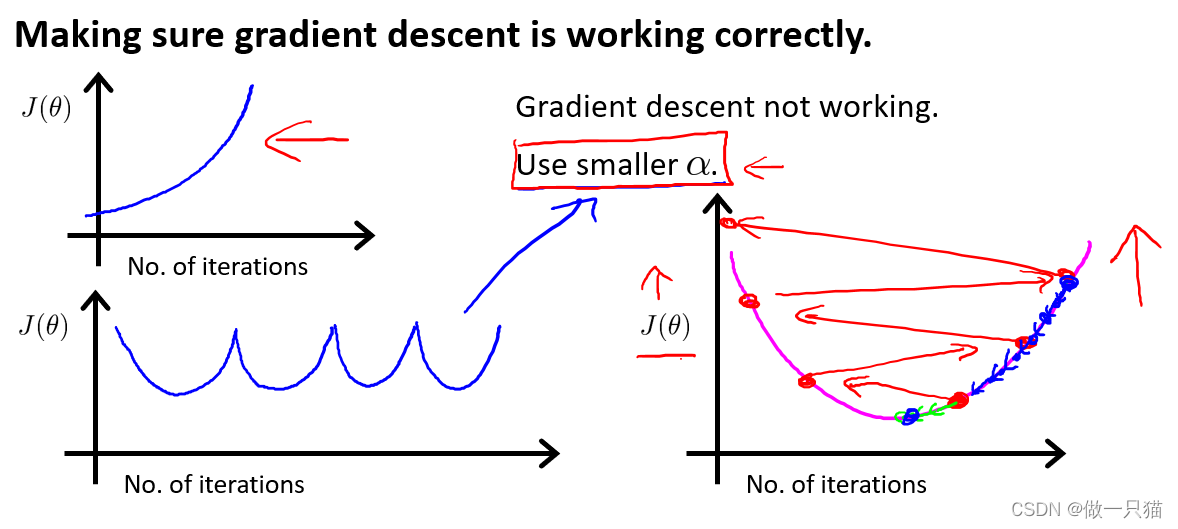
选取合适的α:, 0.001,0.003,0.01,0.03,0.1,0.3,1,
以3为倍数找到一个最大值,以该最大值或比该最大值略小的值作为α
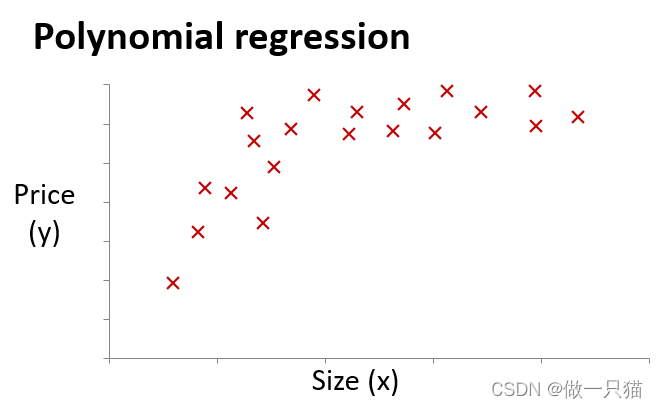
4.5 特征和多项式回归
房价预测问题
4.5.1 特征
假设有两个特征:x1 是土地宽度,x2 是土地纵向深度,则有hθ(x) = θ0 + θ1x1 + θ2x2
由于房价实际与面积挂钩,所以可假设x = x1 * x2,则有hθ(x) = θ0 + θ1x
数据集样本分布如图所示
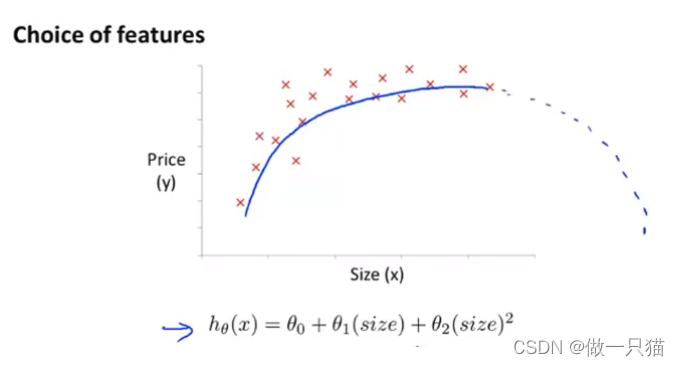
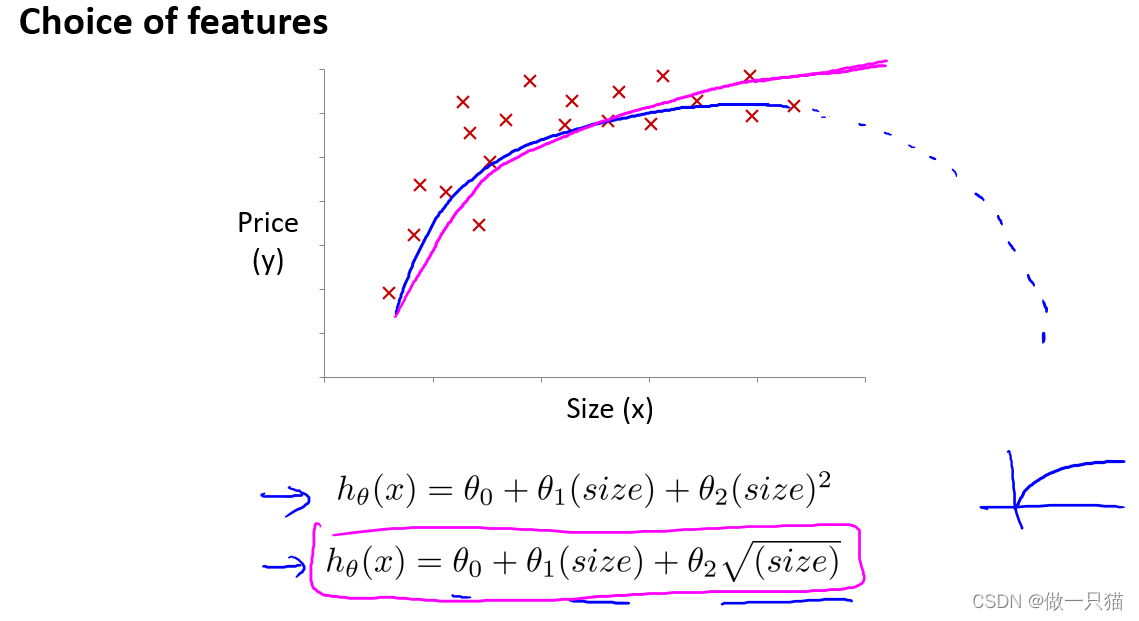
4.5.2 多项式回归
选用二次模型拟合
曲线后半明显下降,不符合实际
曲线符合实际,但由于次方的出现,要十分注意自变量范围的选取
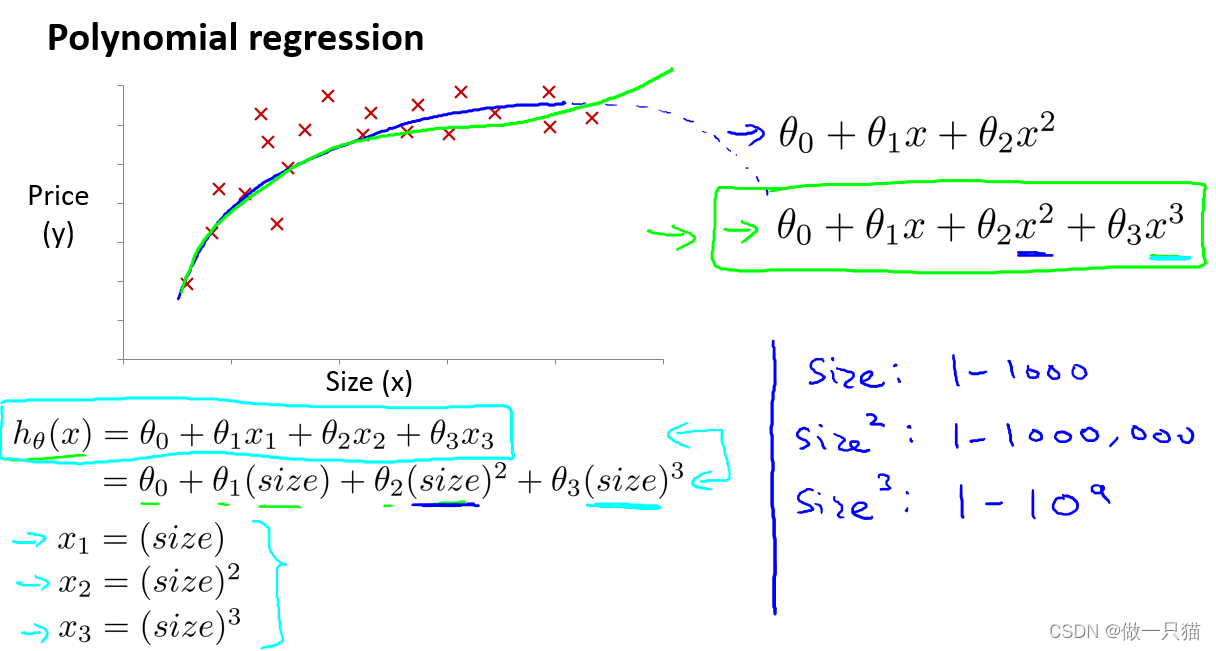
能充分拟合,且自变量范围可变曲度大
4.6 正规方程
作用: 求解某些线性回归的参数θ
4.6.1推导过程
代价函数:
J(θ) =
(hθ(x(i)) – y(i))2
对J (θ) 求偏导并令导数为零可解得: θ = (XTX)-1XTy
推导过程如下:
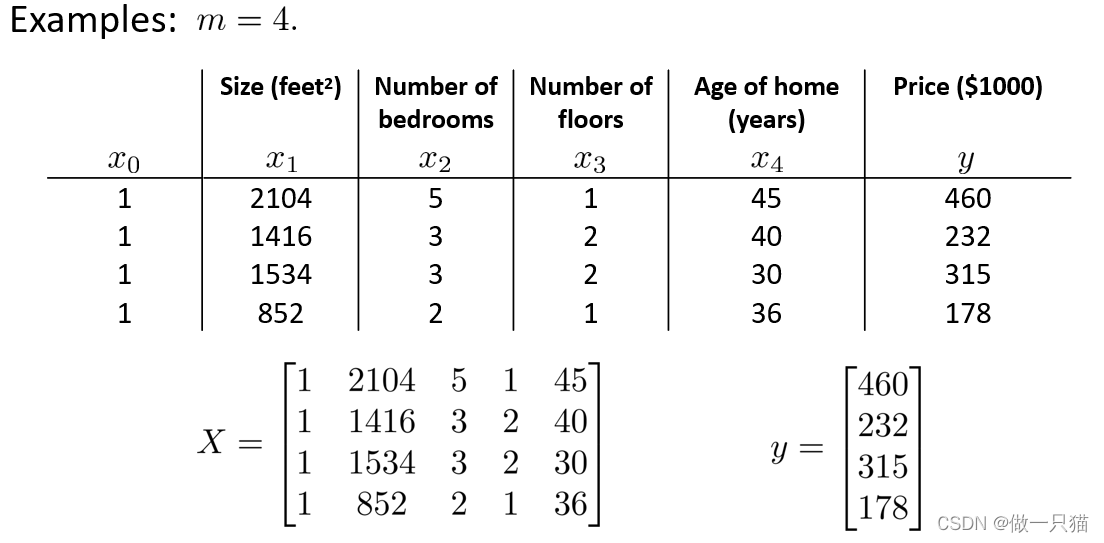
- 实例中,假设有m个样本,n个特征
- x(i)表第i个样本,可写成下左形式的向量。
- 设计矩阵X,取第1个到第m个样本的逆作为X的行,得到m*(n+1)矩阵X

复习补充: 这段推导没看明白,视频里是直接推出最终式子。看弹幕提到是涉及矩阵微分式,之后再做学习
又
J(θ) =
(hθ(x(i)) – y(i))x(i) = 0
可得
θ = (XTX)-1XTy
其中X为特征矩阵,y为目标矩阵(看视频有提到说特征值过于复杂时,该种方法计算速度较慢)
4.6.2 正规方程同梯度下降比较
- 是同级算法
- 梯度下降缺点是需确定α,需要许多次迭代;优点是适用于样本量大(m > 10000)的数据
- 正规方程缺点是不适用于样本量大(m > 10000)的数据,但无需确定α,无需许多次迭代
4.6.3 正规方程与不可逆矩阵
矩阵不可逆的情况很少,导致不可逆可能有以下两个原因:
- 两个及两个以上的特征量呈线性关系,如x1 = 3x2
- 特征量过多。当样本量较小时,无法计算出那么多个偏导来求出结果
实际操作过程中,要删除多余特征,且呈线性关系的多个特征保留一个即可
Octave中的pinv即使面对不可逆矩阵,也能计算出结果,得出来的是伪矩阵
五、Octave
5.1 基本操作
5.1.1 加减乘除与逻辑判断
5 + 6
ans = 11
3 - 2
ans = 1
5 * 8
ans = 40
1 / 2
ans = 0.50000
2 ^ 6
ans = 64
1 == 2 //判断 1 是否等于 2
ans = 0
1 ~= 2
ans = 1
1 && 0 //and
ans = 0
1 || 0 //or
ans = 1
xor(1, 0) //异或
ans = 1
//消除注释
PS1('>> ')
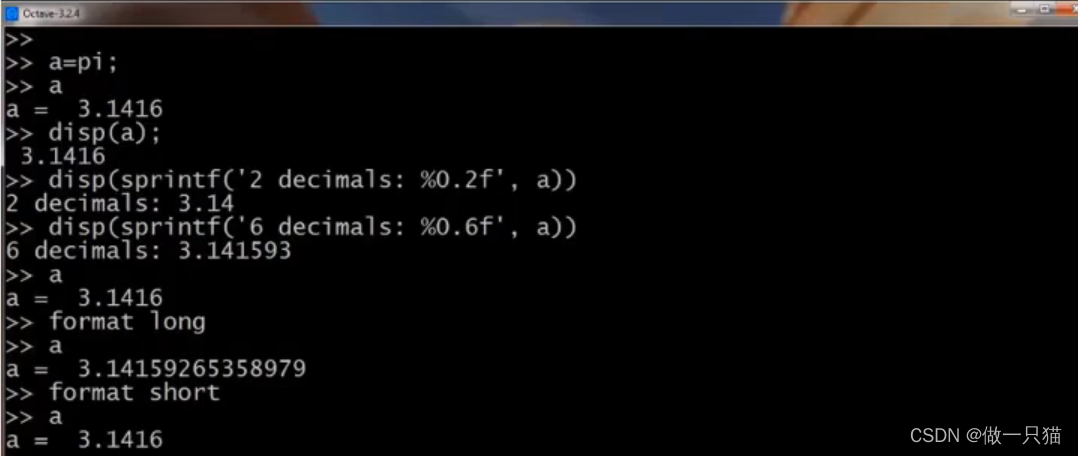
5.1.2 dips()与format
dips(a);
disp(spintf('2 decimals: %0.2f', a))
format long
format short
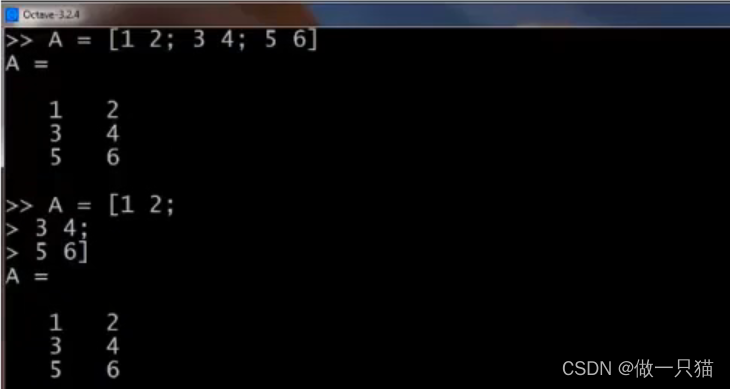
5.1.3 矩阵与向量
A = [1 2; 3 4; 5 6]
v = 1:0.1:2
v = 1:6
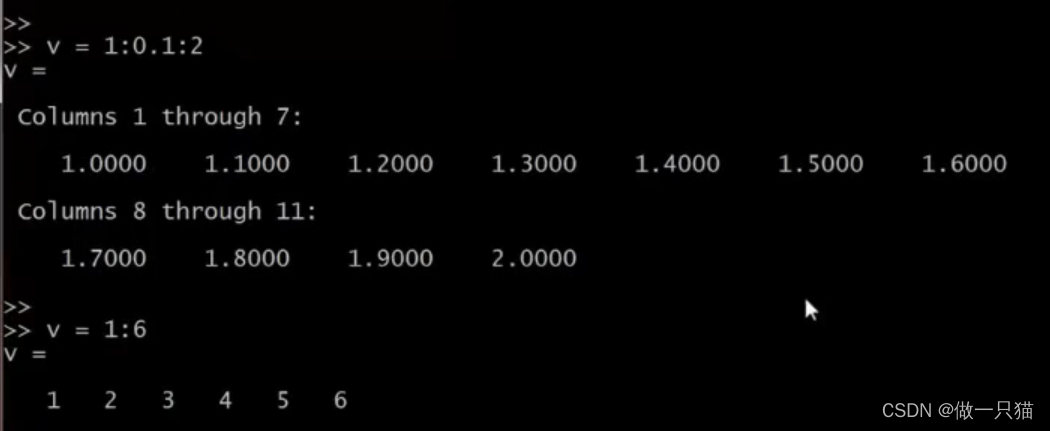
5.1.4 ones() 、 zeros() 与rands()
ones(2, 3)
2*ones(2, 3)
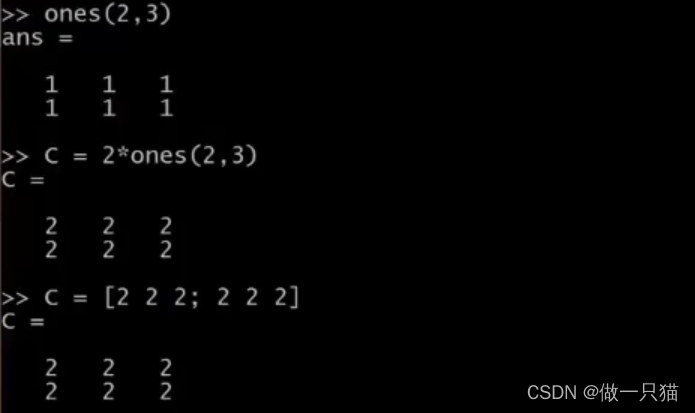
zeros(1, 3)
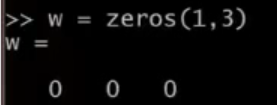
rand(1, 3)
5.1.5 hist()
w = -6 + sqrt(10)*(randn(1, 10000))
hist(w)
后续第五节有关Octave,先跳过,后续再补上
六、逻辑回归
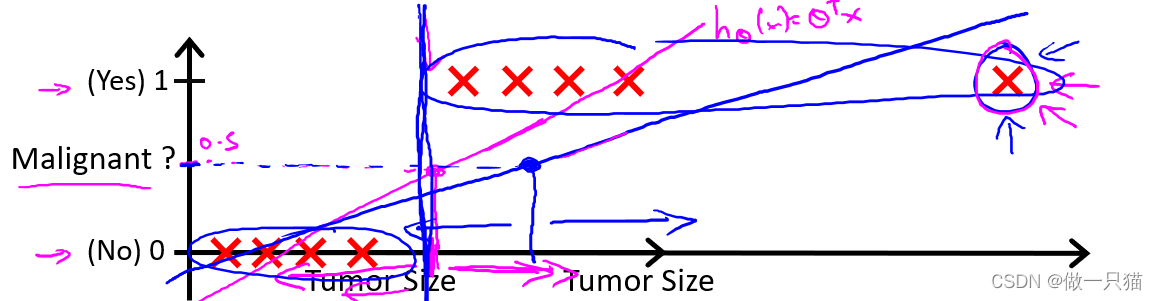
6.1 线性回归对于分类问题的局限性
由于离群点的存在,线性回归不适用于分类问题。
如下图(阈值为0.5),由于最右离群点,再用线性回归与实际情况不拟合。
6.2 logistic regression假设陈述
logistic regression的假设函数值总是在0到1之间

logistic regression模型
线性回归中 hθ(x) = θTx
作一下修改,变成下图形式
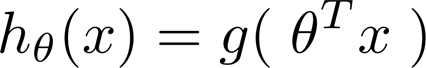
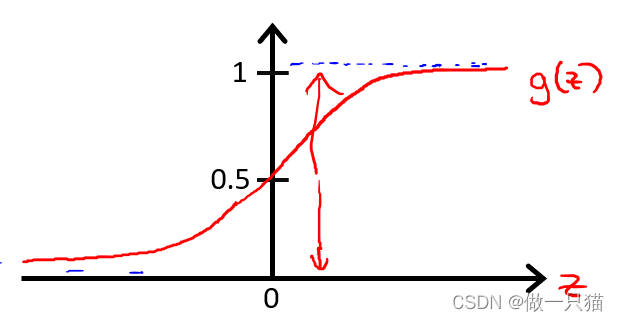
logistic函数 / sigmoid函数
定义logistic函数g如下
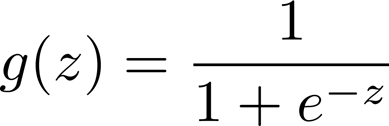
6.2 决策边界
决策边界不是训练集的属性,而是假设本身及其参数的属性
简单来说就是一个分类问题划分依据,可以是一条直线,在这条直线的上方就是y=1,下方就是y=0
用例子进一步说明
6.2.1 例1
假设有一个训练集:
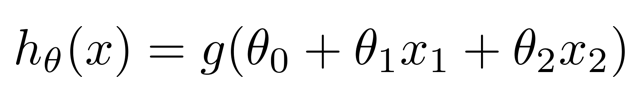
6.2.1 例2

其他参数更多更复杂的也同理
6.3 代价函数(cost function)
6.3.1 cost function的导出
将线性回归的代价函数改写为如下形式(即把1/2提到后面去)
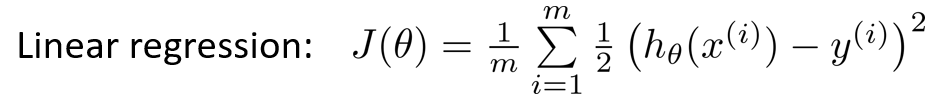
如果在逻辑回归中用线性回归的代价函数,由于 hθ 实际为 g(θTx) ,会导致图像为非凸函数,很难得到最小代价函数
6.3.2 cost function 运用到逻辑回归中
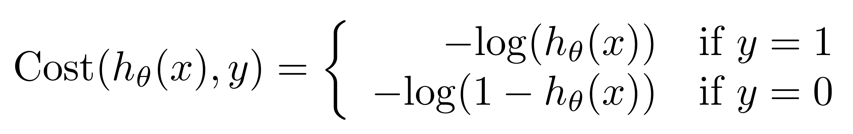
2. 当y = 0时
if hθ(x) = 0, cost = 0
if hθ(x) = 1, cost = ∞ (预测与实际完全不一致,要花费很大的代价惩罚算法)
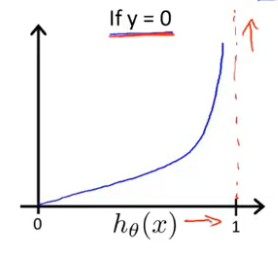
即cost函数值越小,代价函数越好
6.4 简化代价函数与梯度下降
将上述式子合并为一个式子
Cost(hθ(x), y) = -ylog(hθ(x)) – (1 – y)log(1 – hθ(x))
当y = 1时,后一个式子整体为0
当y = 0时,前一个式子整体为0
进而我们得到
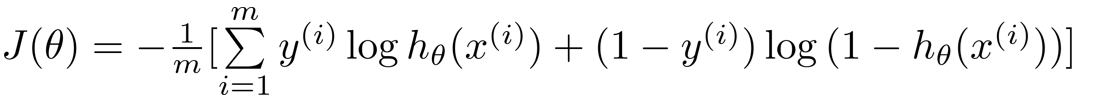
求最小代价函数
由
得
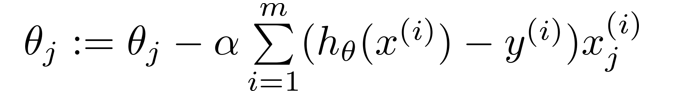
注意:
- 逻辑回归的代价函数看似与线性回归的代价函数相同,但本质不同。
- 逻辑回归中的hθ(x) = 1 / e-θT^x(T是θ的上标)
- 线性回归中的hθ(x) = θTx
6.5 高级优化
本质: 利用一些高级算法,来更快计算出结果。
通常这些算法:
- 能够自主选择α
- 速度大大快于梯度下降
- 比梯度下降更为复杂
Octave中的标号是从1开始的
故theta[1] = θ0,theta[n + 1] = θn
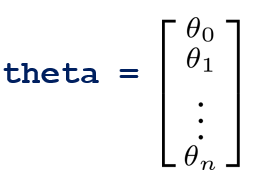
写一个costFunction()函数
该函数需返回
- jVal。因此需要一些代码来计算出J(θ)的值
- gradient。gradient(1)对应关计算出关于θ0的代码

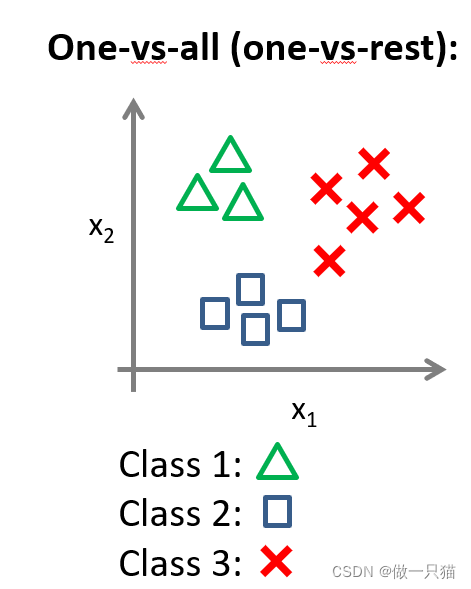
6.7 多元分类:一对多
多元分类: 结果有多种可能。
如下例,有三种可能结果。
将它们两两作为一组,得到
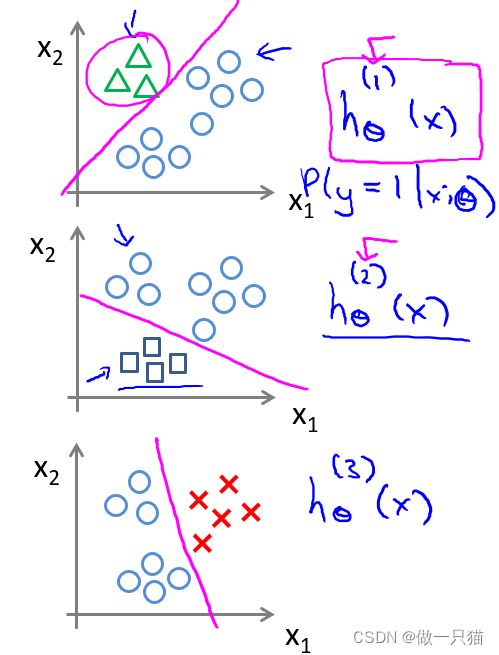
即
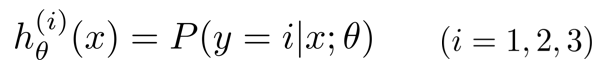
最后需要输入一个x,选择h最大的类别,也即在三个分类器中选择可信度最高,效果最好的
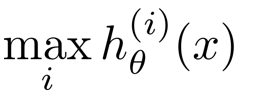
七、过拟合问题
7.1 过拟合定义
过拟合
当变量过多时,训练出来的假设能很好地拟合训练集,所以代价函数实际上可能非常接近于0,但得到的曲线为了千方百计的拟合数据集,导致它无法泛化到新的样本中,无法预测新样本数据
泛化
指一个假设模型应用到新样本的能力
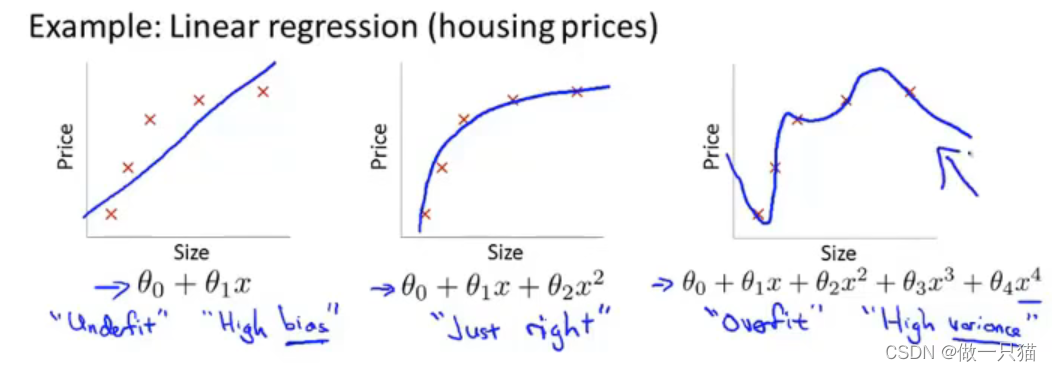
例
下左欠拟合,存在高偏差
下中拟合适中
下右过拟合,存在高方差
解决方法
-
减少特征数量
人工选择
模型选择算法(后续讲到)缺点:舍弃一部分特征变量也舍弃了关于问题的一些信息
-
正则化
减少特征量级或参数θj的大小
7.2 过拟合代价函数
7.2.1 房价例子引入
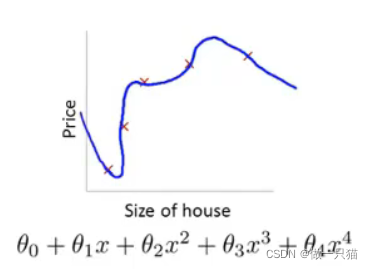
以这个例子为例,其代价函数为
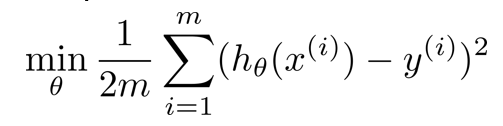
在之后再加上两项(1000为任意一个较大的数)
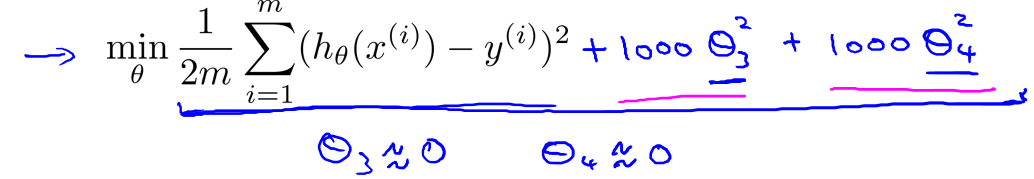
为了minisize代价函数,自然而然地θ3,θ4要等于0,从而去除了这两项,相当于惩罚这两项使得原来的式子变为二次函数
在一般的回归函数中,使参数的值更小一般会使得曲线更为平滑而减少过拟合情况的发生
7.2.2 代价函数(正则化)
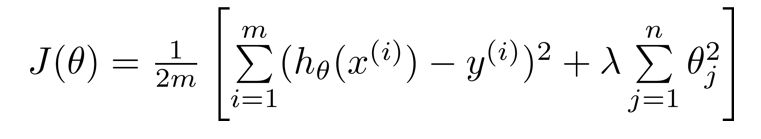
- 如果有很多参数,我们不清楚哪个参数是高阶项,即不知道惩罚哪个能获得更好拟合的结果,因此引入正则化项统一惩罚参数以得到较为简单的函数
- 统一惩罚能得到简单结果是因为,高阶项受到惩罚的效果会更强,反映在图像上就是使其影响变弱
- 其中
+后的一项为正则化项,
λ为正则化参数,作用是控制两个不同目标之间的取舍
(1)第一个目标与第一项有关,即我们想要更加拟合数据集
(2)第二个目标与第二项有关,即我们想要参数θj尽量小 - 惩罚从θ1到θn,不包括θ0(之所以不惩罚theta0是为了让拟合的函数尽量简单,极端情况就是hθ(x) = θ0,代表的一条水平线,不过实操中有无θ0影响不大)
- 若 λ 设置的过大,即对θ1θ2θ3θ4的惩罚程度过大,导致θ1θ2θ3θ4都接近于0,最后假设模型只剩一个θ0,出现欠拟合情况
7.3 线性回归的正则化
7.3.1 梯度下降的正则化
由于正则化是从1到n项,故先将θ0提出来
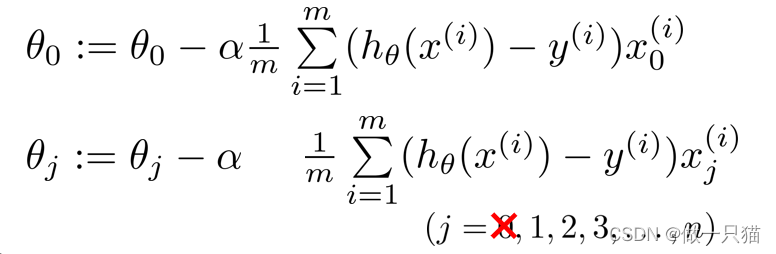
将第二个式子写成下面这样的形式
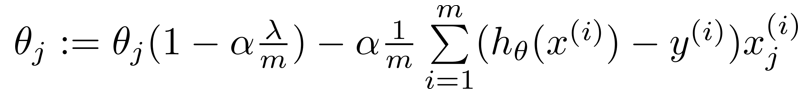
其中m是样本量,所以一般都是一个很大的值,λ 正则化参数,一般都不大。故 1 – α一项的值比1略小
每次迭代时,θj都乘这么一个比1略小的数,效果相当于梯度下降
7.3.2 正规方程的正则化

7.4 逻辑回归的正则化
首先有这么个例子
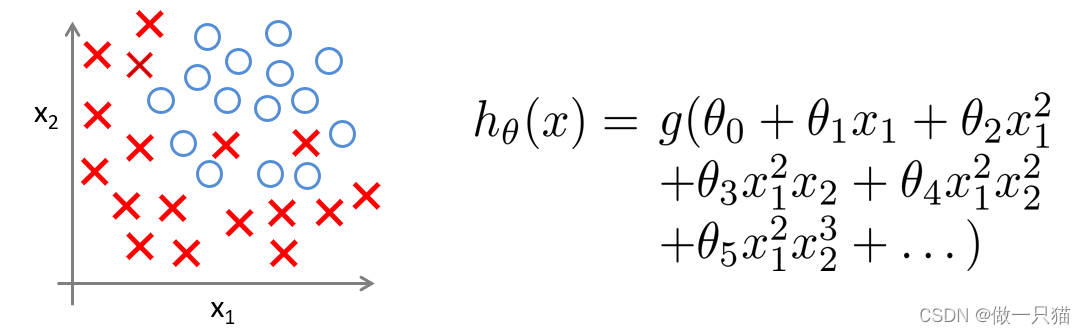
其cost函数为
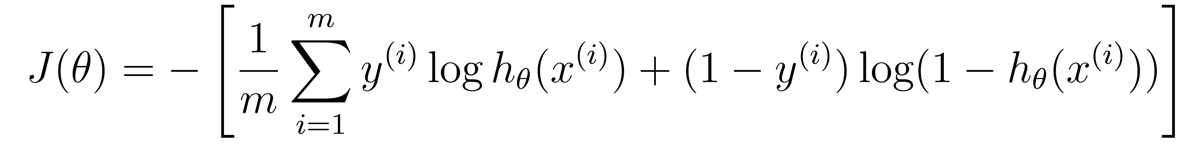
进而得到其偏导
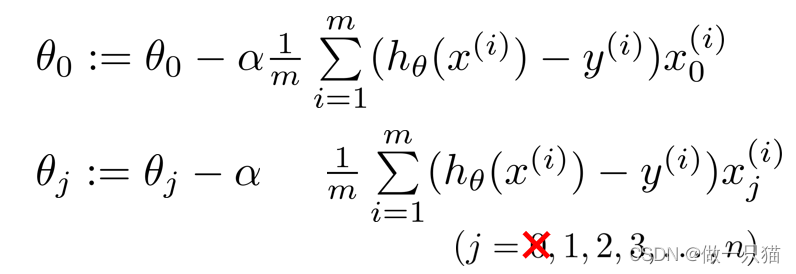
与之前操作类似的,得到 能计算加上正则项的cost函数的偏导 jVal代码,和计算每一个偏导值的gradient(i)代码

八、神经网络
8.1 神经网络的必要性
当特征值只有两个时,我们仍可以用之前学过的算法去解决

但当特征值很多,且含有很多个多次多项式时,用之前的算法就很难解决了
例 汽车识别
计算机识别汽车是靠像素点的亮度值

给定数据集汽车和非汽车的数据,按照之前的方法划分
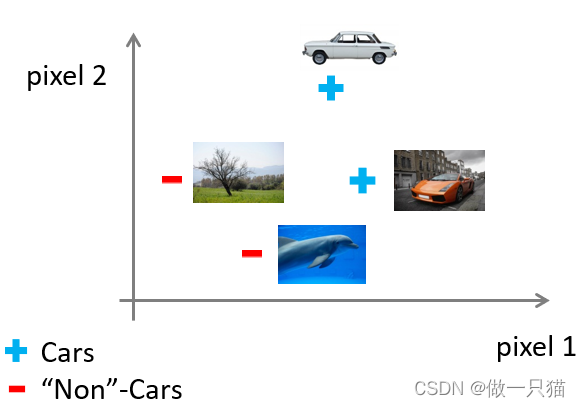
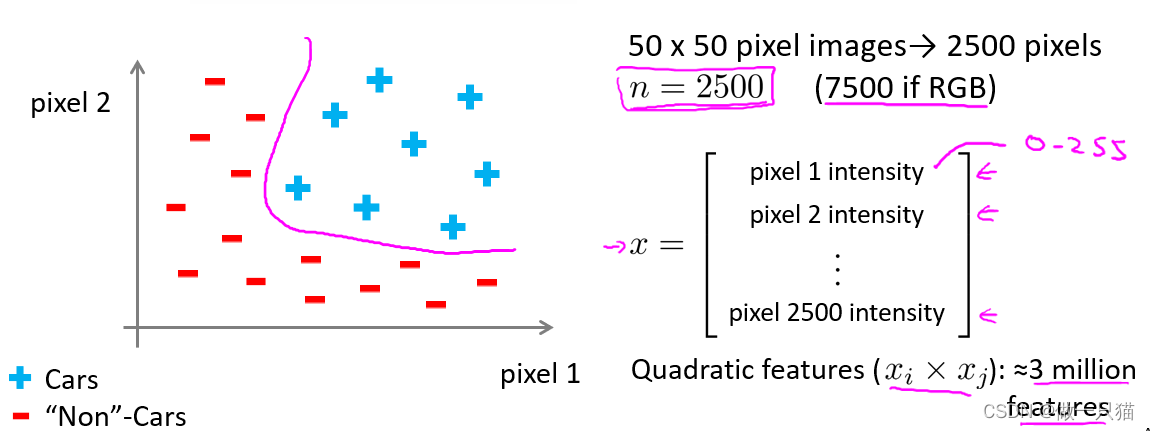
可以看到仅针对50*50像素的灰白图片,就有2500个特征值。当引入rgb时,特征值达到了7500个,如果算上多次多项式,特征值达到了三百万个,显然再继续用之前的算法难以处理这么庞大的数据
8.2 模型展示
8.2.1 神经元的工作方式
神经元由树突接收外界信息,经神经元计算,再由轴突发出信息
神经元之间可互相传递信息
类似地,我们定义一个神经网络如下:
- x0,a0为偏置单元,默认值为1
- Layer1是输入层,Layer3是输出层,Layer2的工作过程看不到故为隐藏层
- ai(j)是第 j 层第 i 个神经元的激活值(即由一个具体神经元计算并输出的值)
- θ(j)是权重矩阵,控制从第 j 层到第 j + 1层的映射

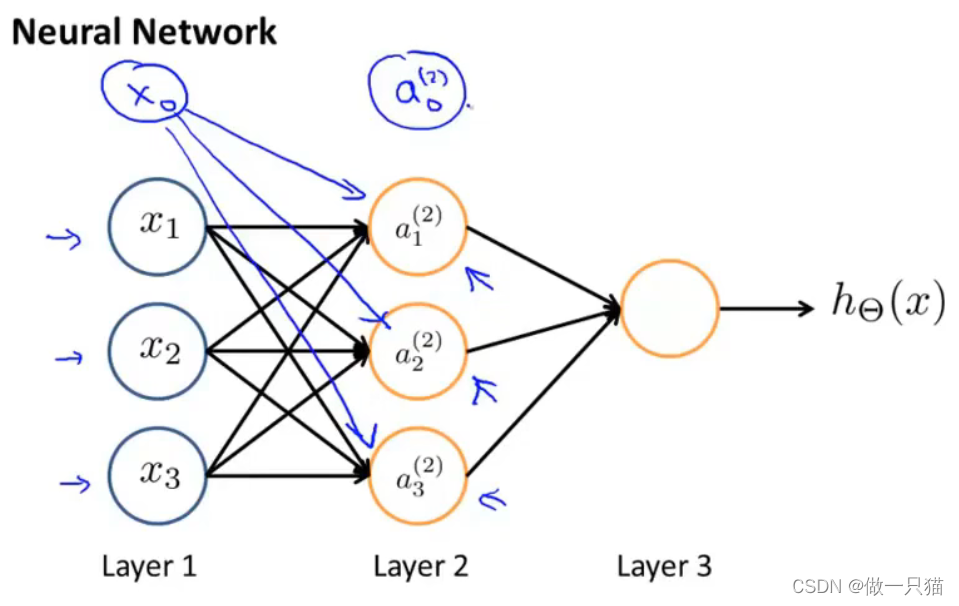
进而得到 a(2) 和 hθ(x) 的计算公式
θ是映射,可理解为是中间的连线。
因为是矩阵相乘,x是4行1列向量(记得算上x0),所以θ是4列,又因为a有三个,所以θ是3行,最后得θ是3行4列向量,则θ × x结果为3行1列向量
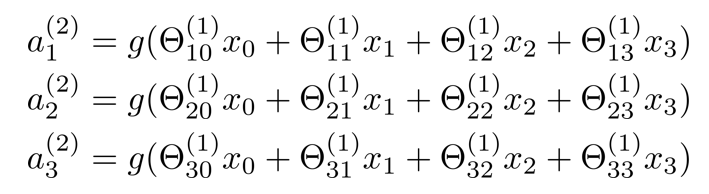
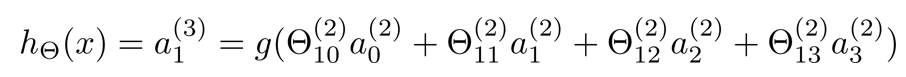
如果一个网络在第 j 层有 sj 个单元,在第 j + 1 层有 sj +1 个单元,则矩阵θj的维度为 sj+1 * (sj +1 )。如θ(2)是3×4矩阵
8.2.2 前向传播
从输入单元的激活项开始,进行前向传播给隐藏层,计算隐藏层的激活项,继续前向传播,并计算输出层的激活项
- 由之前我们有如下式子
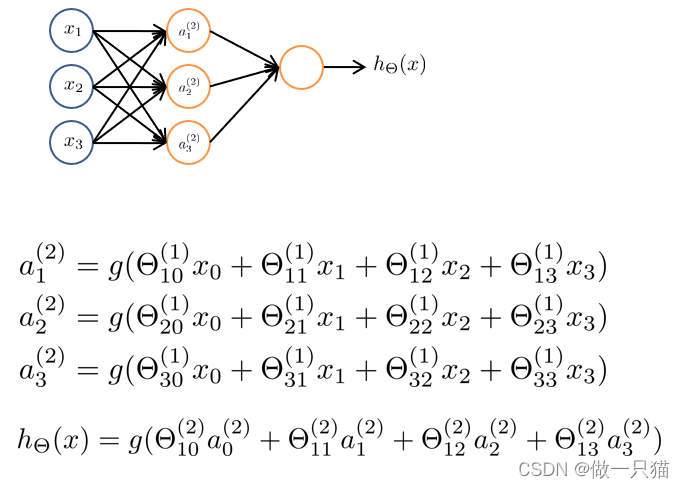
- 其中 x 为 4维向量
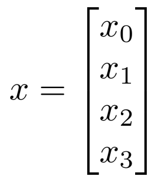
- 令 z(2) = θ(1)x,从而z是一个 3维向量
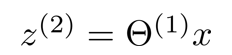

-
进而
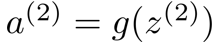
-
进而 a(2) = g(z(2))
-
类似的,加上a0(2) = 1,a(2)为 4维向量,进而得到
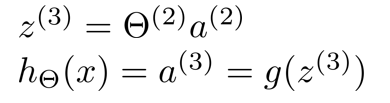
合在一起比较好理解
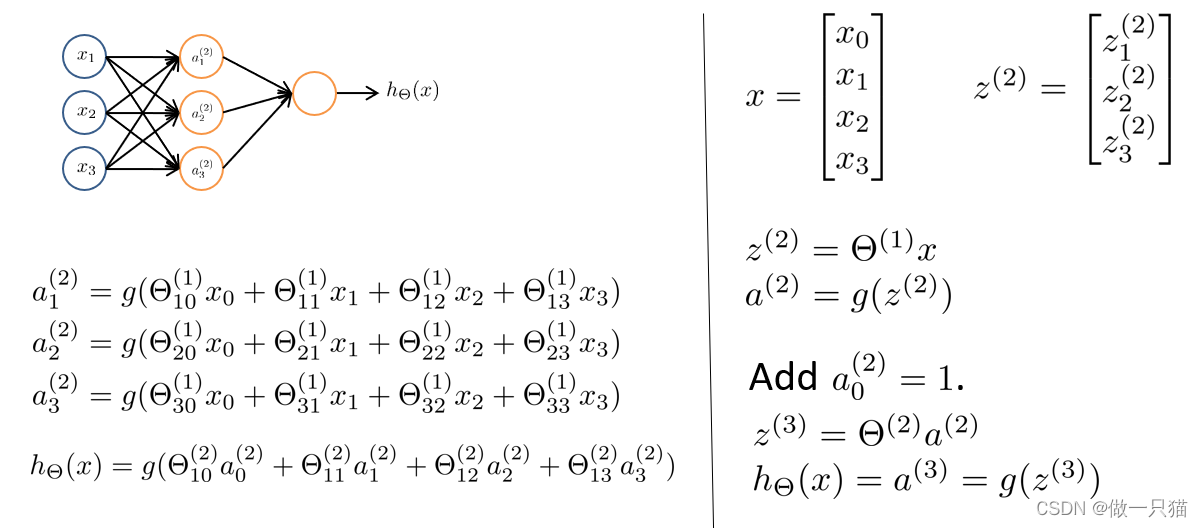
更复杂的神经网络
中间的均为隐藏层
一层层往后越来越复杂
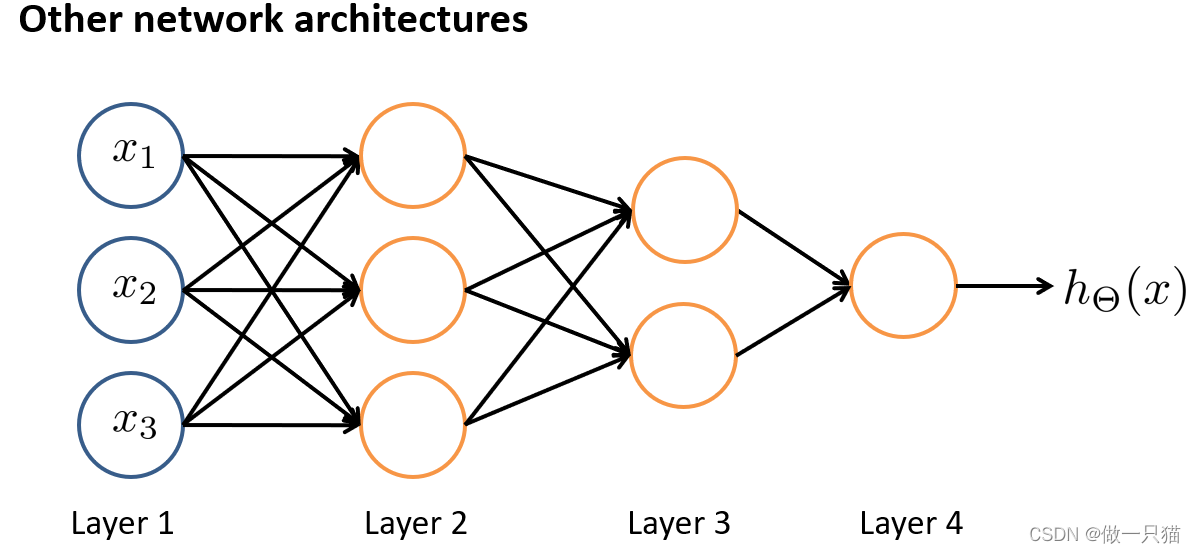
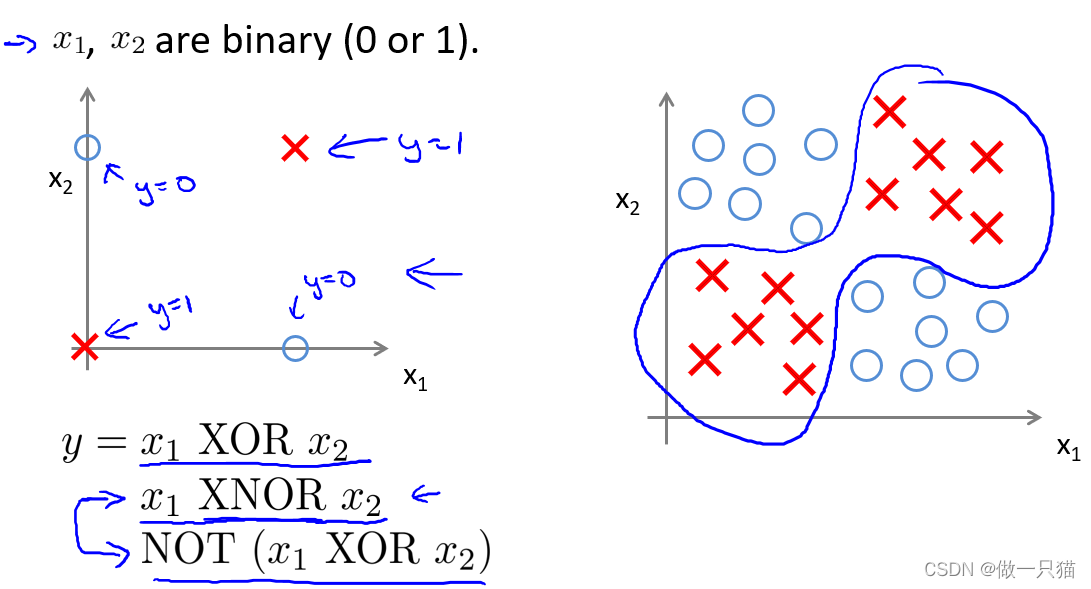
8.3 例:神经网络用于计算XOR,XNOR
-
定义两个特征x1,x2,它们的值只能为0或1
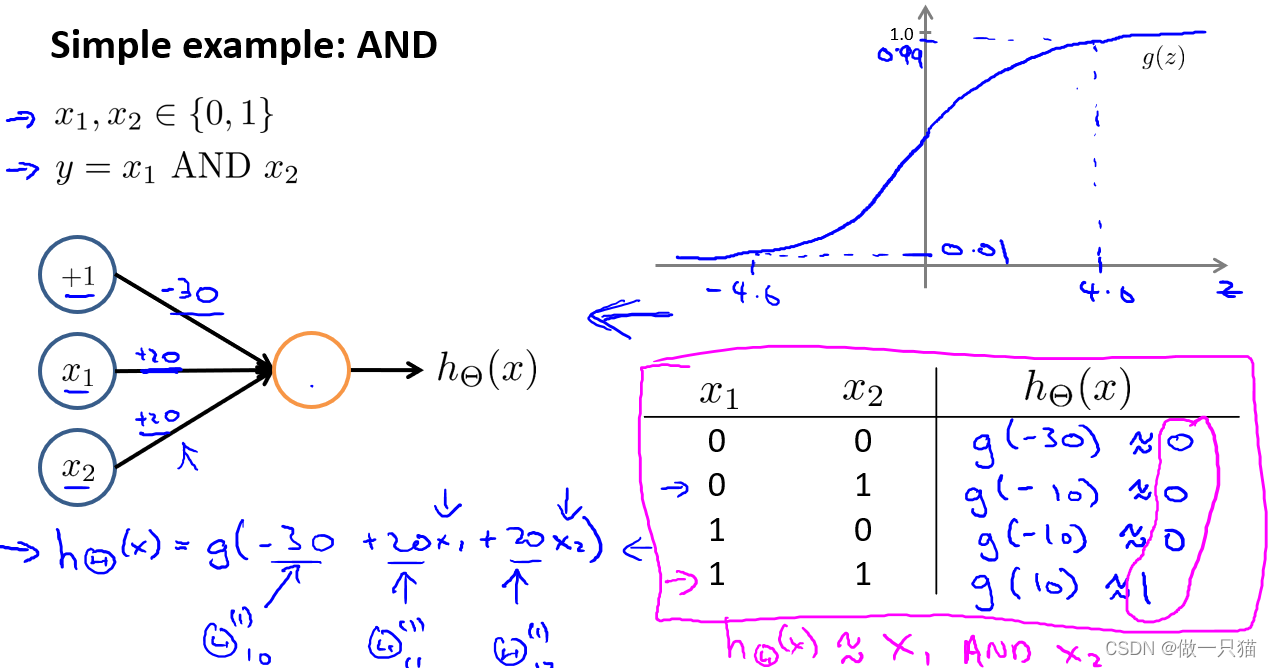
-
AND
引入x0,值为1。对权重 / 参数进行赋值,-30、+20、+20
x1 = 0,x2 = 0,hθ(x)结果为0
同理得到另外三组结果
总结果与 x1 AND x2 一致
-
OR
与AND同理

-
(NOT x1)AND(NOT x2)
NOT即结果取反。如果x1输入为1,则输出为0
x1输入0,hθ(x1)输出1;x2输入0,hθ(x2)输出1,再进行AND运算可得最终结果
其他三种情况同理
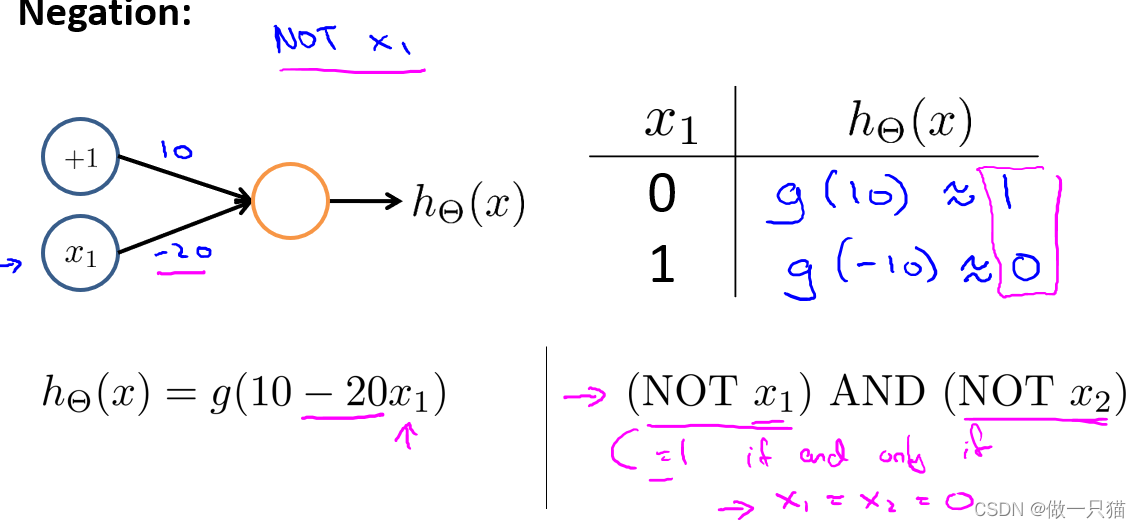
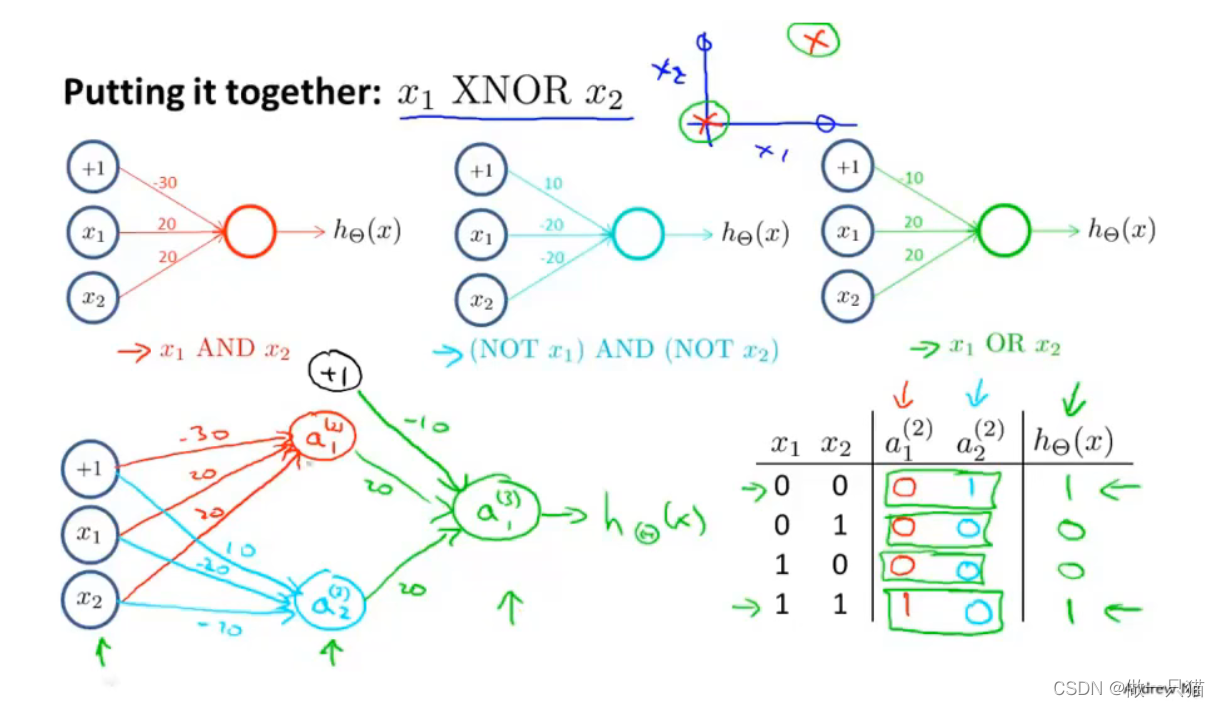
– XNOR
有AND,(NOT x1)AND (NOT x2), OR三个前提
同样在输入层定义x0,x1,x2
在隐藏层中
进行AND运算得到a1(2),进行(NOT x1)AND (NOT x2)运算得到a2(2)
在输出层中
进行OR运算得到a1(3),即为最终结果
每层都是通过计算不断复杂
九、神经网络的运用
9.1 代价函数
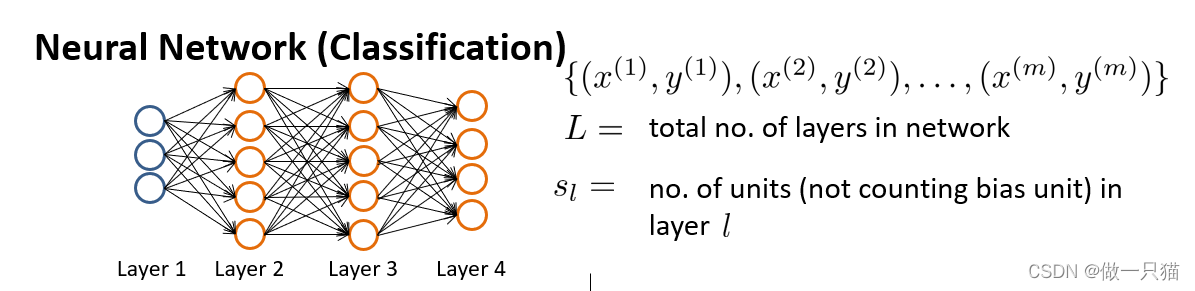
定义 L,指网络中共有多少层
定义sL,指每层中有多少个偏差单元
如,s1 = 3,s4 = sL = 4
针对01输出问题
-
二元分类

只有一个输出,则sL = 1
K = 1(K表示输出层的单元数目)
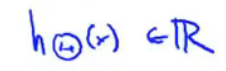
输出结果h(x)是一个实数 -
多类别分类
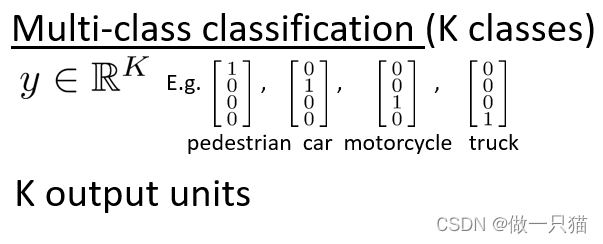
K个输出单元(K ≥ 3,不然没有必要用多类别分类)
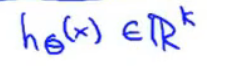
输出结果h(x)是一个K维向量
(eg:有不同的交通工具,定义一个结果集yk每个车对应向量第j行的值是1,其他位置都为0,将结果h(x)与yk比较,对应得上则说明是该交通工具)
代价函数
在逻辑回归中,我们有如下代价函数
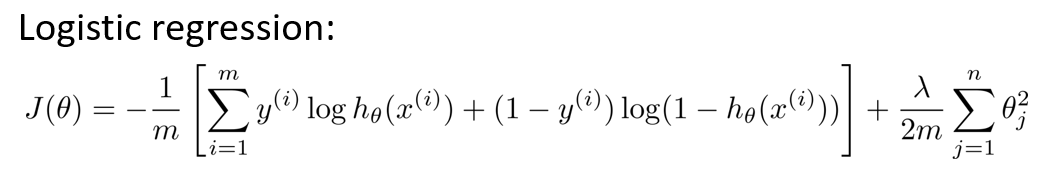
演化到神经网络中,得到如下代价函数
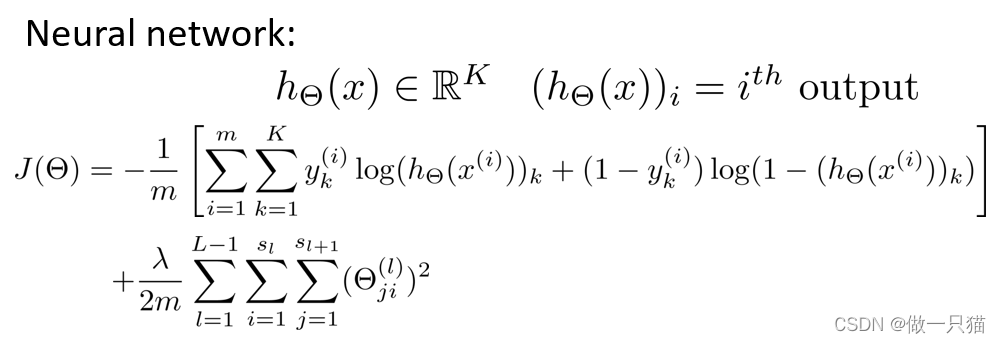
-
其中
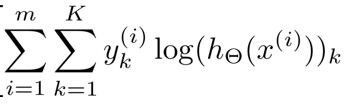
两个连加类似for循环。
这里相当于求k等于从1到4的每一个逻辑回归算法的代价函数,然后按四次输出的顺序,依次把这些代价函数加起来 -
其次
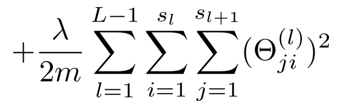
这一项表对所有θji(l)求和
1 到 L – 1是因为映射是两两之间的 -
注意 j 和 i 没有标错,按照之前的定义,i 就是θ向量的列(i可理解为前一层输入的单元数也即样本数),进而 j 就代表行
-
在计算中,不将θi0这一项也进行计算,乘出来的结果有些类似于偏差单元的值,但实际运用中,影响不大
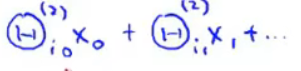
9.2 反向传播算法
为了最小化 J(Θ),需要求偏导

这需要用到反向传播算法,即先计算最后一层的误差,然后再一层一层反向求出各层的误差,直到倒数第二层(第一层是输入变量,不存在误差)
举例说明:
假设我们的训练集只有一个实例(𝑥(1), 𝑦(1)),我们的神经网络是一个四层的神经网络,
其中𝐾 = 4,𝑆𝐿 = 4,𝐿 = 4
前向传播算法:

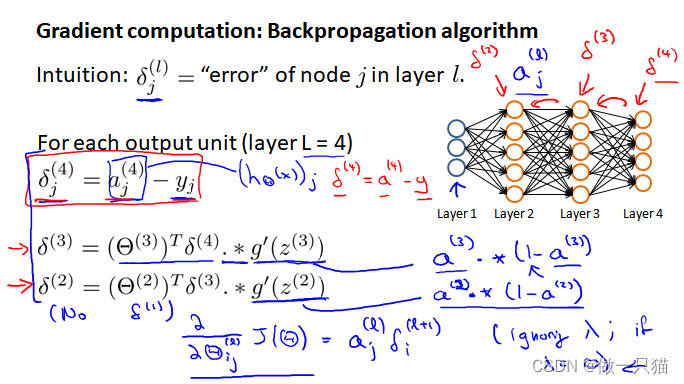
我们从最后一层的误差开始计算,误差是激活单元的预测(ak(4))与实际值(𝑦𝑘)之间的误差,(𝑘 = 1: 𝑘)。
用𝛿来表示误差,计算前一层的误差得下左式子,其中𝑔′(𝑧(3)) = 𝑎(3) ∗ (1 − 𝑎(3)),(𝜃(3))𝑇𝛿(4)是权重导致的误差的和
继续计算第二层的误差: 𝛿(2) = (𝛩(2))𝑇𝛿(3)∗ 𝑔′(𝑧(2))
为第一层是输入变量,不存在误差
有了所有的误差的表达式后,便可以计算代价函数的偏导数,假设𝜆 = 0,即不做任何正则化处理时有: 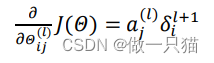
𝑙 代表目前所计算的是第几层。
𝑗 代表目前计算层中的激活单元的下标,也将是下一层的第𝑗个输入变量的下标。
𝑖 代表下一层中误差单元的下标,是受到权重矩阵中第𝑖行影响的下一层中的误差单元
的下标
上面得到了error变量δ的计算,下面来看backpropagation算法的伪代码 :

然后计算代价函数的偏导数,公式如下:
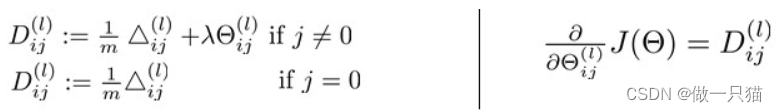
9.3 理解反向传播算法
前向传播算法 从前往后计算z(j),a(j) 的过程如下:

将原cost function 进行简化,去掉正则化项,得到 cost(i):

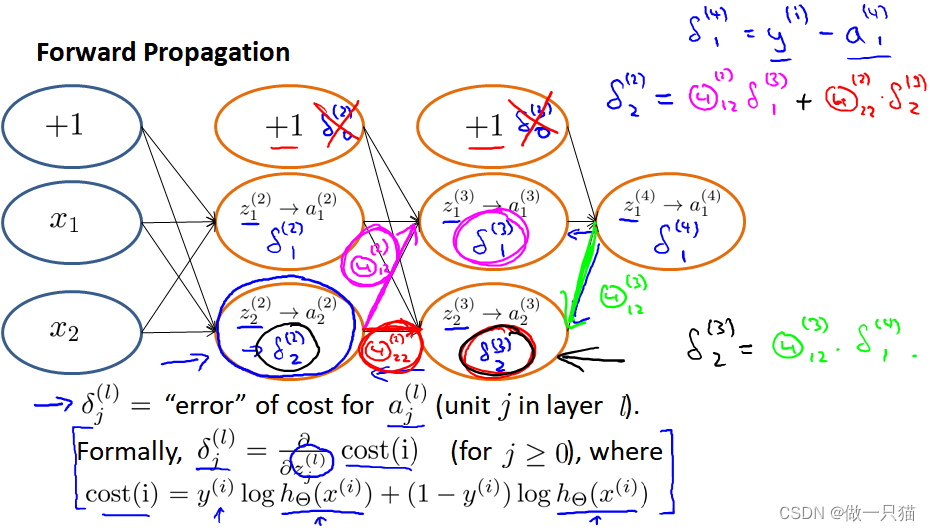
即对于每一层来说,δ分量都等于后面一层所有的δ的加权和,其中权值就是参数θ:
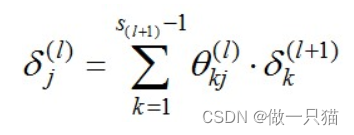
9.4 使用注意:展开参数
在Octave中,如果要使用fminc这样的优化算法来求解权重矩阵,需要将矩阵展开成为向量,再利用算法求出最优解后再重新转回矩阵

假设有三个权重矩阵:Theta1,Theta2,Theta3 。下面是将其向量化 unroll into vector,再变回矩阵的方法:

9.5 梯度检测
为了验证复杂模型内部是否呀运行正常,我们是用一种叫做 Numerical gradient checking的方法来验证梯度是否在下降对于下面这个J(θ)图,取θ点左右各一点(θ+ε),(θ-ε),则点θ的导数(梯度)近似等于(J(Θ+ε)-J(θ-ε))/(2ε)
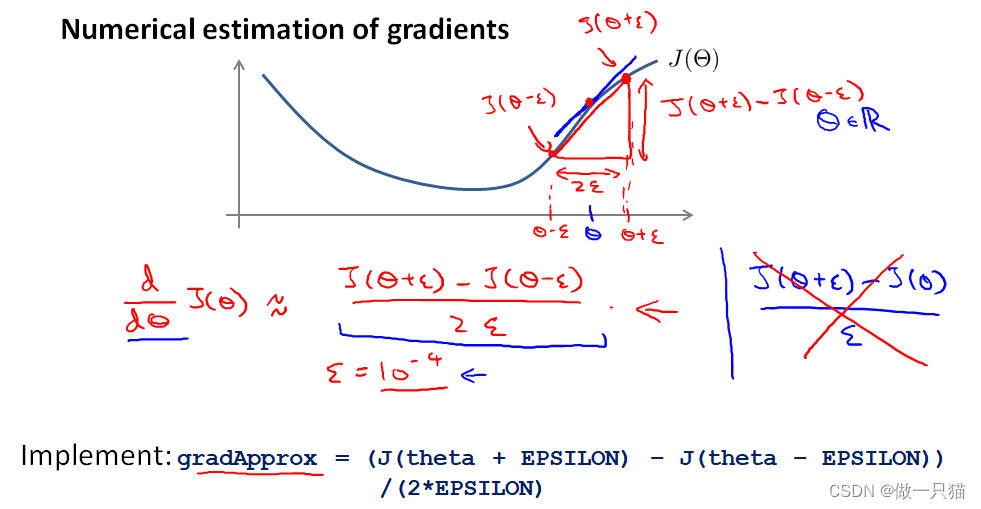
因此,针对每个θ,其导数都可以近似为:

将这个近似值,与back-propagation算法中每一步得到的J(θ)的导数D(derivative)进行比较。如果这两个结果相近,则code正确,否则错误。上面描述的算法如下:

步骤:
- 在 back propagation 中计算出J(θ)对θ的导数D,并向量化成Dvec(unroll D(1),D(2),D(3))
- 用 numerical gradient check 方法计算梯度近似值 gradApprox
- 确保这两个值很接近
-(这一点非常重要)只在测试的时候进行校验。真正使用 back propagation 进行神经网络学习的时候,要停止校验,否则会非常慢
9.6 随机初始化
之前对于逻辑回归,我们将参数θ全部初始化为0。 然而对于神经网络,此方法不可行: 如果第一层参数θ都相同(不管是不是0),意味着第二层的所有激活单元的值会完全相同
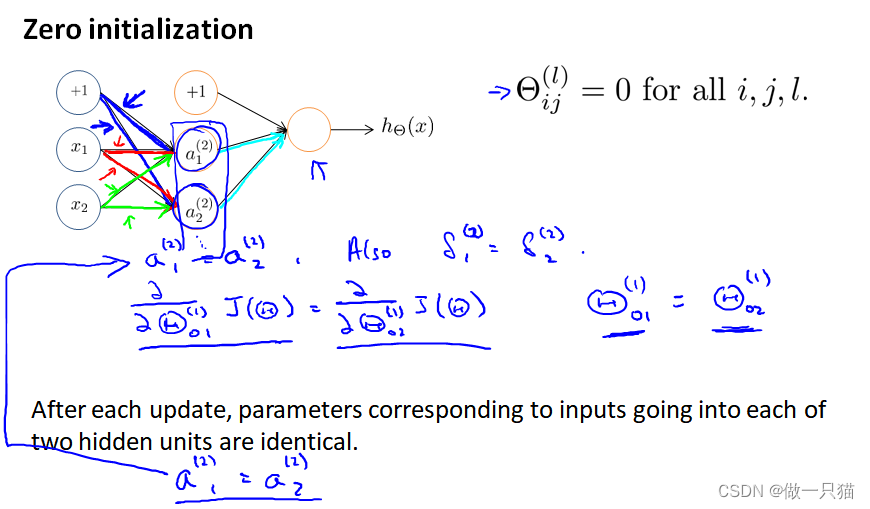
通常初始参数为正负 ε 之间的随机值,代码如下:

9.7 综合使用
选择神经网络
通常情况下隐藏层神经单元的个数越多越好
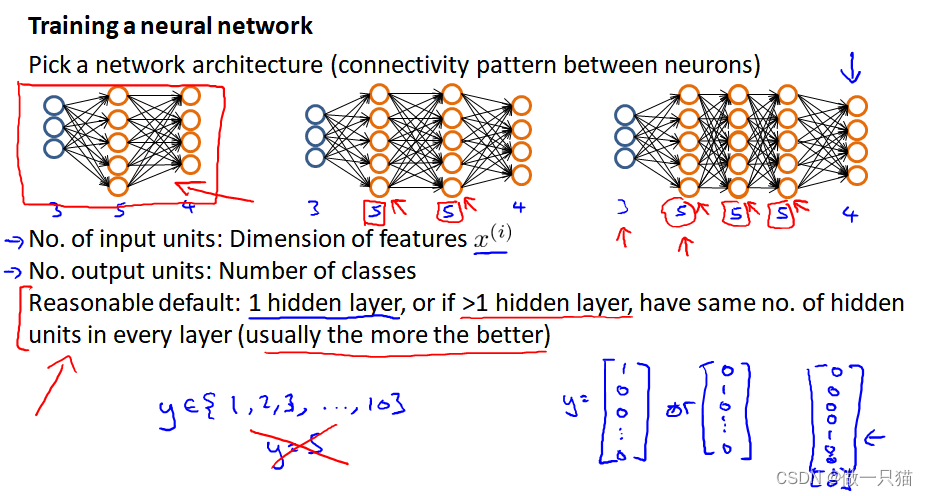
训练神经网络:
-
参数的随机初始化
-
利用正向传播方法计算所有的 ℎ𝜃(𝑥)
-
编写计算代价函数 𝐽 的代码
-
利用反向传播方法计算所有偏导数
-
利用数值检验方法这些偏导
-
使用优化算法来最小代价函数


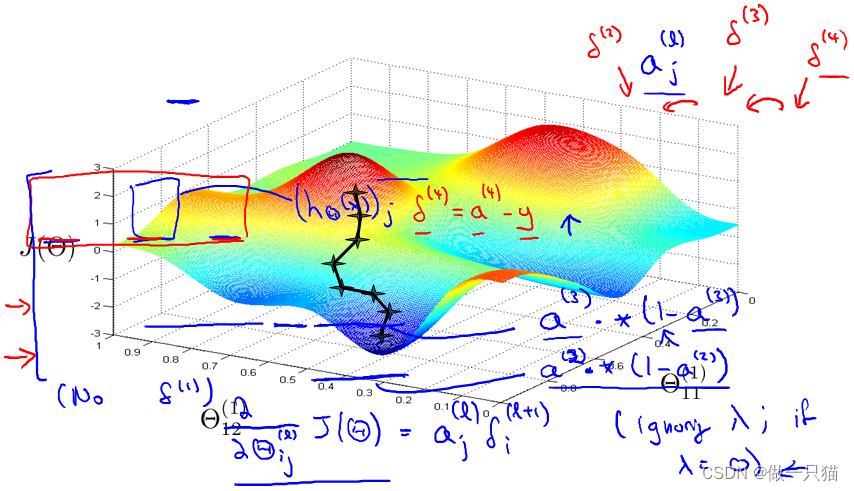
神经网络的直观表示如下,因为J(𝜃)不是一个凸函数,因此我们可以到达一个局部最小点
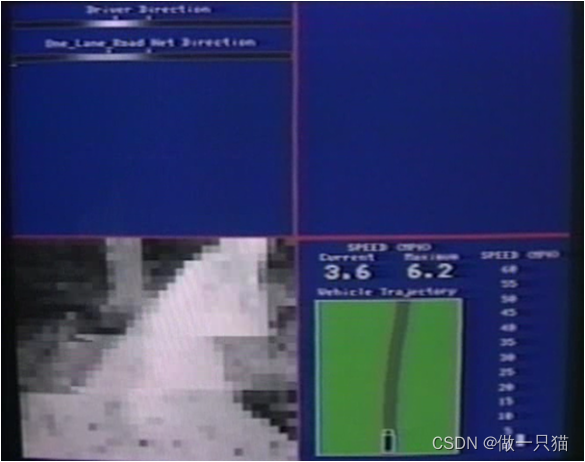
9.8 无人驾驶
ALVINN (Autonomous Land Vehicle In a Neural Network) 是一个基于神经网络的智能系统
神经网络过拟合有两种情况,可以通过两种方式解决:
(1)引入Validate 数据集
(2)规则化
加入规则化因子之后,整个模型其实是奔着选取较小的 w 而进化的,因为如果需要损失函数值小的话,一旦选取了比较大的 w,那么只有等式右边第一项式子的值比较小的情况下才行,因此规则化的目的其实是减轻比较大的 w 值对损失函数的影响,为什么需要这么做,我们假设对于线性回归而言,有一个数据特别偏离主模型,这样的话,往往会导致模型受这个影响比较大,从而偏离主模型,这时候就需要抵消这个数据对结果的影响,这就用到了规范化,目的是消除其某些损失函数值过大的点影响,对于神经网络,正则化的目的是为了消除太大的 w 对结果的影响,其结果就是局部的变化因素(个别 w 的变化)不会影响整个模型的数据,只有对全部模型起变化的因素才能影响到模型的建立,这样就消除了局部噪声的影响
十、应用机器学习的建议
10.1 应用机器学习的建议
到目前为止,我们已经学习了许多不同的学习算法,但可能没有完全理解怎样运用它们,因此总是把时间浪费在毫无意义的尝试上。所以我们接下来将学习一些方法去选择一条最正确的道路。
我们将重点关注的是如果我们在开发一个机器学习系统,或者想试着改进一个机器学习系统的性能,我们要如何决定接下来应该选择哪条道路?

为了解释这一问题,我们仍然使用预测房价的学习例子。假设已经完成了正则化线性回归,也就是最小化代价函数的值,但如果假设函数放到一组新的房屋样本上进行测试,发现在预测房价时产生了巨大的误差,我们要如何改进这个算法?

第一种办法是使用更多的训练样本。但有时候获得更多的训练数据实际上并没有作用。
第二种方法是尝试选用更少的特征集。如果你有很多特征,我们可以从这些特征中仔细挑选一小部分来防止过拟合。
第三种方式是尝试选用更多的特征,也许目前的特征集,对我们来讲并不是很有帮助。所以我们也许可以从获取更多特征的角度来收集更多的数据,也可以把这个问题扩展为一个很大的项目。
第四种方式是可以尝试增加多项式特征,比如X1的平方,X2的平方,X1和下的乘积等等。
第五种方式是可以考虑其他方法去减小或增大正则化参数的值。
以上这些方法都需要很长的时间,但有一系列简单的方法能让我们事半功倍,排除掉这些方法中的至少一半,从而节省大量不必要花费的时间。这些方法被叫做 “机器学习诊断法” 。
“诊断法” 的意思是:这是一种测试法,你通过执行这种测试,能够深入了解某种算法到底是否有用。这也能告诉我们,要想改进一种算法的效果,去做什么样的尝试才是有意义的。
但同时这些诊断法的执行和实现,也需要花费时间,有时候确实需要花很多时间来理解和实现,不过这样做是把时间用在了刀刃上,可以为我们在开发学习算法时节省几个月的时间。
10.2 评估一个假设
在之前的学习中我们尝试选择参量来使训练误差最小化,但得到一个非常小的训练误差并不一定是一件好事,它推广到新的训练集上并不一定适用。那么我们该如何判断一个假设函数是否过拟合呢?

对于简单的例子,我们可以对假设函数进行画图,然后观察图形的趋势,但对于像右边这样特征变量不止一个的情况,就很难画图去观察了。所以需要另一种方法来评估(假设函数是否过拟合)。

这里展示十组训练样本,我们将数据分成两部分,第一部分(通常为70%)作为我们的训练集,第二部分(通常为30%)作为我们的测试集。
用Mtest表示测试样本的总数,(x(1)test, y(1)test)就表示第一组测试样本。
要注意的是,在分成两组数据集之前,应该先将数据随机排列再进行分组。

对于线性回归,假设函数J(θ)由70%的训练集得到。
之后要计算出测试误差,用Jtest来表示。把从训练集中学习得到的参数 θ 放在Jtest中来计算测试误差,这个是测试集平方误差的平均值(样本量为Mtest)。

对于逻辑回归,同样我们也要从训练集中学习得到参数θ,再放到Jtest中去。这个目标函数和之前的一样,唯一的区别是这里使用的是Mtest个样本。
还有另一种测试度量可能更便于理解,叫做错误分类,也叫作0/1分类错误。
可以定义一次预测的误差,是关于假设函数和标签y的误差:
(1)误差等于1的情况是,当假设函数h(x)的值大于等于0.5且y的值等于0时;假设函数的值小于0.5,且y的值等于1时;这两种情况都表示假设对样本进行了误判。
(2)其他情况则误差等于0,表示假设能对样本进行正确分类。
然后我们就能用应用错误分类误差(Test error),来定义测试误差,也就是错误分类误差求平均值。
10.3 模型选择和交叉验证集
如果我们想要确定对于一个数据集最合适的多项式次数,怎样选用正确的特征来构造学习算法;或者如果我们要选择学习算法中的正则化参数LAMBDA,要怎么做?这类问题叫做模型选择问题。

我们之前提到过拟合问题,用左边这些参数来拟合训练集,就算假设函数在训练集上表现得很好,也不意味着该假设对新样本也有好的泛化能力。所以训练集误差不能用来表示假设对新样本的拟合好坏。而如果参数对某个数据集拟合的很好,那么用同一数据集计算得到的误差,比如训练误差并不能很好地估计出实际的泛化误差(即对该数据集的泛化能力)。

假设我们要在10个不同次数的二项式模型之间进行选择,用参数d来表示多项式的次数。d=1……d=10。
(1)选择各个模型,分别得到各个参数,为做区别,在参数上加上上标。
(2)用这些参数分别计算得到各个测试集误差。
(3)为从这些模型找到最好一个,应该看哪个模型的测试集误差最小。
(4)假设这里最终选择了五次多项式模型,现在要知道这个模型的泛化能力,可以观察这个模型对测试集的拟合程度,但由于我们拟合了一个参数d,并且选择了一个最好地拟合测试集的参数d的值,因此我们的参数向量θ(5)在测试集上的性能很可能是对泛化误差过于乐观的估计。意思就是说是用测试集拟合得到的参数d,再在测试集上评估假设,所以假设可能对测试集的表现要好过那些其他那些新的测试集中没有的样本。
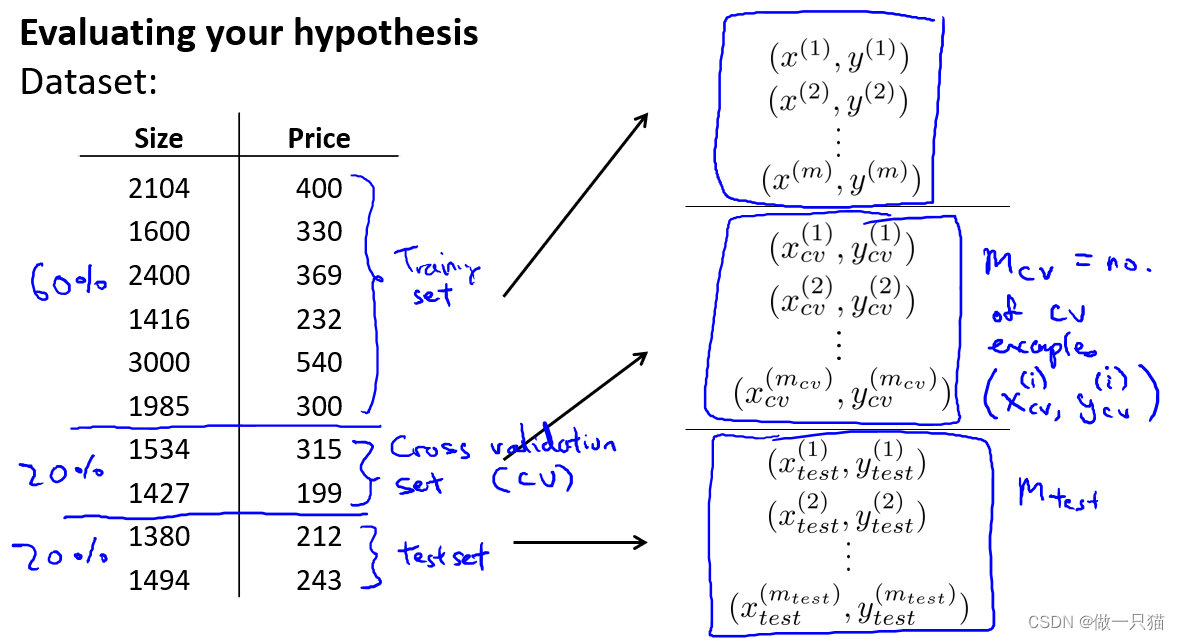
为解决模型选择出现的问题,通常会使用以下的方法来评估一个假设:
给定一个数据集,分为三部分,用60%的数据作为训练集,用 20%的数据作为交叉验证集(CV,也叫验证集),用20%的数据作为测试集。
用Mcv来表示验证集的样本总数,同样用(x(i) ,y(i) )来表示第i个验证样本

用三个样本分别计算测试误差

(1)同样我们用训练集来计算最小代价函数得到各个参数,但这次用验证集来测试。
(2)用计算出的Jcv来观察这些假设模型在交叉验证集上的效果如何。
(3)选择Jcv最小的假设,这里假设选择四次多项式对应的交叉验证误差最小,进而得到d=4
(4)之后就可以用测试集来衡量模型的泛化误差了。
10.4 诊断偏差和方差
当我们运行一个学习算法时,如果这个算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。高偏差和高方差的问题基本上来说是欠拟合和过拟合的问题。能判断出现的情况是这两种情况中的哪一种,是一个很有效的指示器,指引着可以改进算法的最有效的方法和途径。
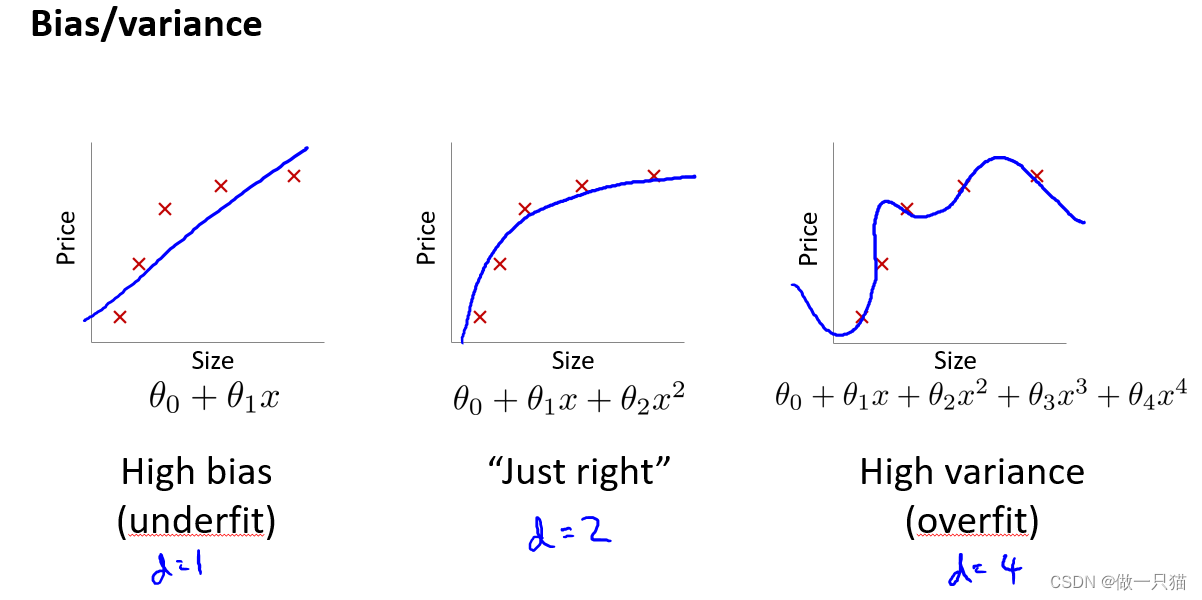
通过之前的学习我们知道,上图左边是欠拟合,右边是过拟合,而中间是刚好拟合,其泛化误差也是最小的。
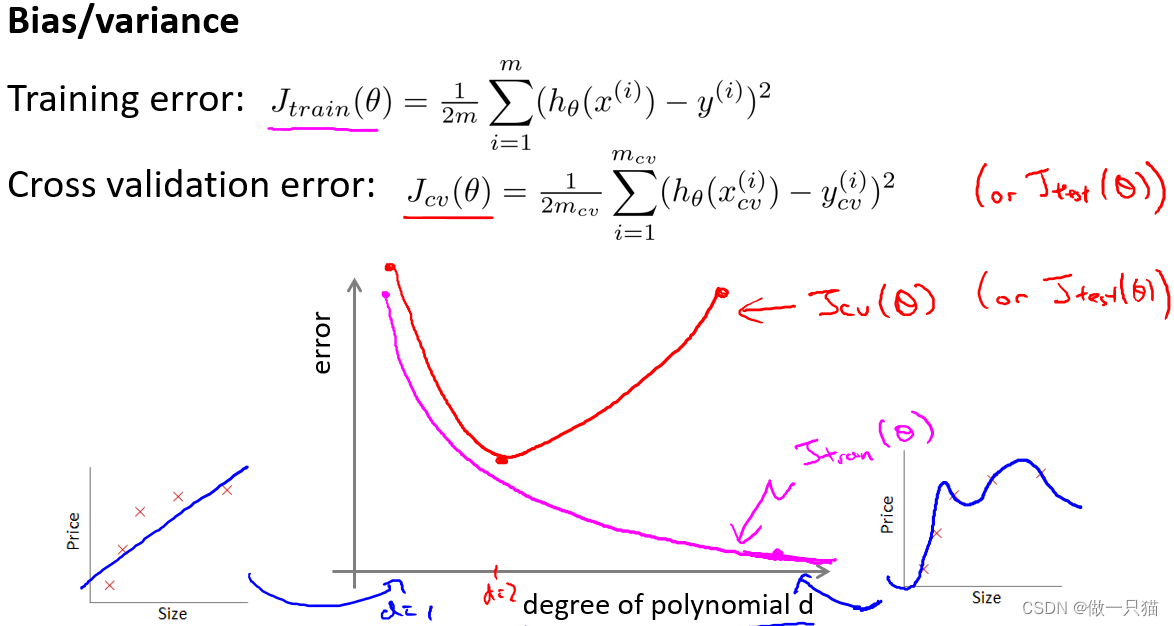
上图的图像,横坐标d代表多项式的次数,左边值为1的时候对应一次函数,右边值为4的时候对应更高的多项式次数。
粉色线Jtrain(θ)代表训练误差,由于次数越高越拟合,所以训练误差是趋于下降的。
红色线Jcv(θ)代表测试误差,d=1时欠拟合,测试误差较高,d=4时过拟合,测试误差较高,而d=2时刚好拟合,测试误差较低。
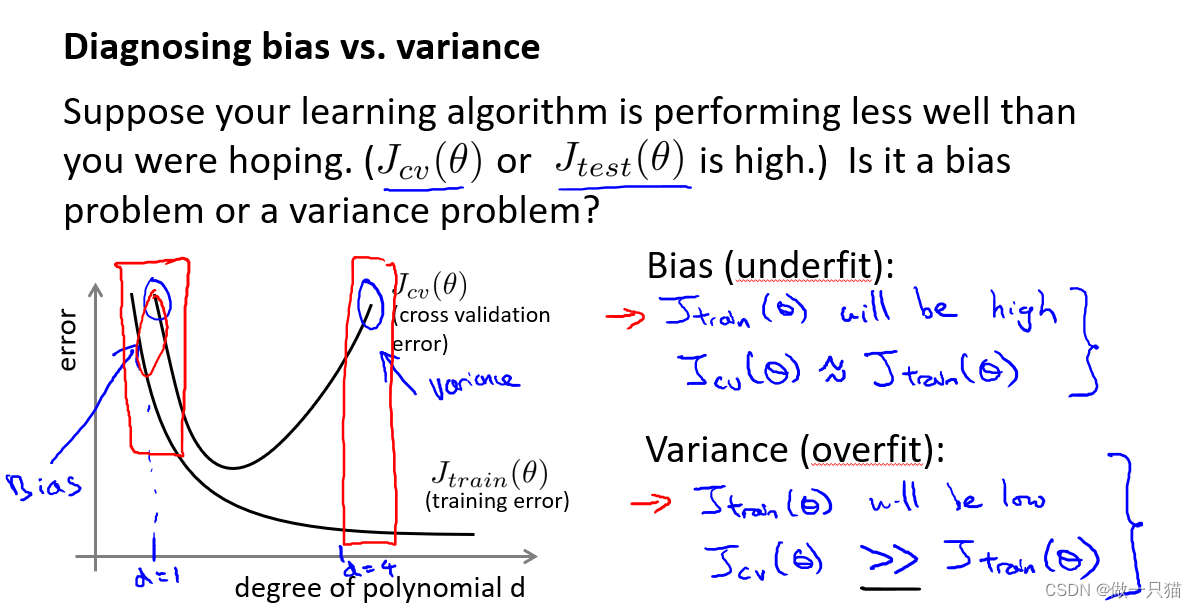
由上面的分析我们可以知道,
d=1时欠拟合,呈现高偏差,此时训练误差和测试误差都很大,且两者接近;
d=4时过拟合,呈现高方差,此时训练误差很大,测试误差很小,测试误差远大于训练误差。
文章出处登录后可见!