🤵 Author :Horizon Max[0]
✨ 编程技巧:各种操作总结[0]
🎇 机器视觉篇:会变魔术 OpenCV[0]
💥 深度学习篇:简单入门 PyTorch[0]
🏆 神经网络:经典网络模型[0]
💻 算法篇:再忙也别忘了 LeetCode[0]
🚀 MobileNet
MobileNet 使用 深度可分离卷积 来构建轻量级的深度神经网络,是一种用于 移动和嵌入式视觉 应用的高效模型 ;
通过引入两个简单的全局超参数有效地权衡延迟和准确性;

🔗 论文地址:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications[0]
🚀 MobileNet 详解
🎨 MobileNet 网络结构
🚩 背景介绍
自AlexNet于2012年获得 ImageNet Challenge(ILSVRC) 冠军以来,深度卷积神经网络在计算机视觉中得到了广泛的应用 ;
为了获得更高的模型精度,大趋势是对网络模型进行深化和复杂化;
但模型精度的提高并不一定会使网络在规模和速度方面更加高效;
与机器人、自动驾驶汽车和增强现实等许多现实世界的应用一样,识别任务需要在计算能力有限的平台上及时完成;
在此之前,人们构建小模型主要有两种方式:压缩训练网络和直接训练小模型;
但是许多关于小型网络的论文只关注规模,而不是速度;
MobileNet 主要专注于 优化延迟 ,但也产生小型网络 ;
因此,作者提出了一种高效的网络架构和一组超参数;
构建非常小的、低延迟的模型,可以轻松满足移动和嵌入式视觉应用的设计需求;
🚩 Depthwise Separable Convolution
Depthwise Separable Convolution :深度可分离卷积
深度可分离卷积 分为两层:第一层 深度卷积(Depthwise Convolution)用于滤波,第二层 逐点卷积(Pointwise Convolution)用于合并,这样可以极大地减少 计算量 和 模型大小 ;
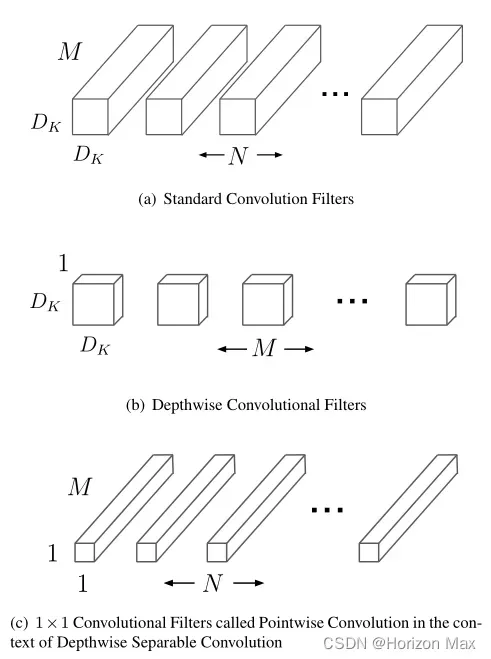
假设输入特征图为(DF × DF × M),卷积核大小为(Dk × Dk × N),M 和 N 分别为输入和输出通道数量 ;
那么对应的计算量为:
- 标准卷积 :DF × DF × M × DK × DK × N
- 深度卷积 :DF × DF × M × DK × DK
- 1×1点卷积 :DF × DF × M × N
- 深度可分离卷积 :( DF × DF × M × DK × DK ) + ( DF × DF × M × N )
减少的计算量是:
=
+
当使用 3×3 深度可分离卷积时,计算量可以减少 8-9 倍 ;
🚩 MobileNet 结构框图
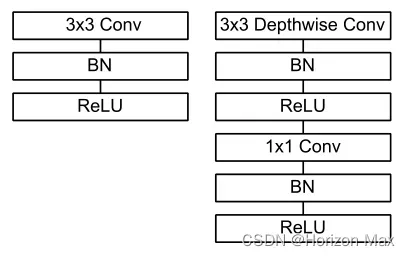
MobileNet 结构建立在深度可分离卷积基础之上,在 深度卷积 和 逐点卷积 之后加入归一化和激活层(BN and ReLU);
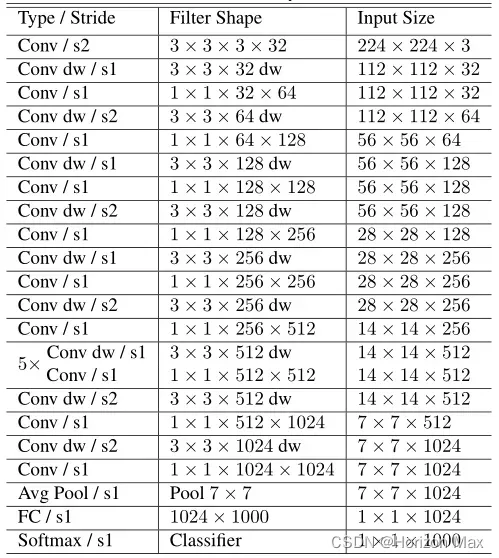
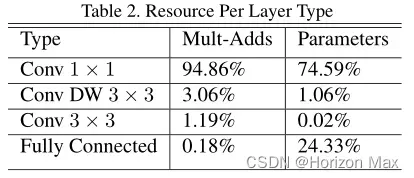
从下表可以看出:
模型将几乎所有的 计算 都放在密集的 1×1卷积 ;
(近95%的计算时间 和 近75%的模型参数)
在模型训练期间,与训练大型模型策略相反:
使用较少的正则化和数据增强技术,因为小型模型过拟合的可能性较低;
🚩 宽度倍增器
为构造更小且计算成本更低的模型,引入了一个非常简单的参数 α(宽度倍增器 ( Width Multiplier ) );
它可以在每一层均匀地细化网络,输入通道数 M 变为 αM,输出通道数 N 变为 αN ;
基于此得到的模型参数量为( α ∈ (0,1) ):
- 深度可分离卷积 :( DF × DF × αM × DK × DK ) + ( DF × DF × αM × αN )
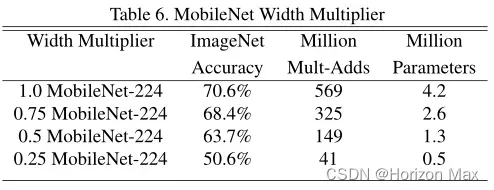
当 α = 0.25 时,结构变得太小,精度会平稳下降 ;
🚩 分辨率倍增器
降低神经网络计算代价的第二个超参数为 ρ (分辨率倍增器 ( Resolution Multiplier ) )
它可以减小输入特征图的尺寸,由 DF 变为 ρDF ;
基于以上两个超参数得到的模型参数量为( α ∈ (0,1) ,ρ ∈ (0,1] ):
- 深度可分离卷积 :( ρDF × ρDF × αM × DK × DK ) + ( ρDF × ρDF × αM × αN )
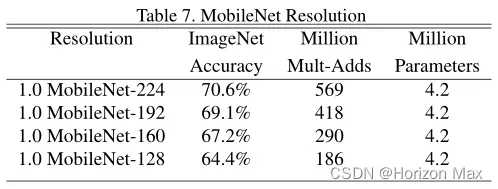
上图为 ρ = 1,6/7,5/7,4/7 时分别对应的结果 ;
🚀 MobileNet 复现
# Here is the code :
import torch
import torch.nn as nn
from torchinfo import summary
def Depthwise_Separable(in_planes, out_planes, stride, padding):
model = nn.Sequential(
# 3 × 3 深度卷积
nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=padding, groups=in_planes, bias=False),
nn.BatchNorm2d(in_planes),
nn.ReLU6(inplace=True),
# 1 × 1 点卷积
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU6(inplace=True),
)
return model
class MobileNet(nn.Module):
def __init__( self, num_classes=1000, width=1):
super(MobileNet, self).__init__()
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(32),
nn.ReLU6(inplace=True),
)
self.layers = nn.Sequential(
Depthwise_Separable(width*32, width*64, 1, 1),
Depthwise_Separable(width*64, width*128, 2, 1),
Depthwise_Separable(width*128, width*128, 1, 1),
Depthwise_Separable(width*128, width*256, 2, 1),
Depthwise_Separable(width*256, width*256, 1, 1),
Depthwise_Separable(width*256, width*512, 2, 1),
Depthwise_Separable(width*512, width*512, 1, 1),
Depthwise_Separable(width*512, width*512, 1, 1),
Depthwise_Separable(width*512, width*512, 1, 1),
Depthwise_Separable(width*512, width*512, 1, 1),
Depthwise_Separable(width*512, width*512, 1, 1),
Depthwise_Separable(width*512, width*1024, 2, 1),
Depthwise_Separable(width*1024, width*1024, 2, 4),
)
self.pool = nn.AvgPool2d(kernel_size=7, stride=1)
self.classifier = nn.Linear(width*1024, num_classes)
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.first_conv(x)
x = self.layers(x)
x = self.pool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
out = self.softmax(x)
return out
def test():
net = MobileNet()
y = net(torch.randn(1, 3, 224, 224))
print(y.size())
summary(net, (1, 3, 224, 224))
test()
输出结果:
torch.Size([1, 1000])
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
MobileNet -- --
├─Sequential: 1-1 [1, 32, 112, 112] --
│ └─Conv2d: 2-1 [1, 32, 112, 112] 864
│ └─BatchNorm2d: 2-2 [1, 32, 112, 112] 64
│ └─ReLU6: 2-3 [1, 32, 112, 112] --
├─Sequential: 1-2 [1, 1024, 7, 7] --
│ └─Sequential: 2-4 [1, 64, 112, 112] --
│ │ └─Conv2d: 3-1 [1, 32, 112, 112] 288
│ │ └─BatchNorm2d: 3-2 [1, 32, 112, 112] 64
│ │ └─ReLU6: 3-3 [1, 32, 112, 112] --
│ │ └─Conv2d: 3-4 [1, 64, 112, 112] 2,048
│ │ └─BatchNorm2d: 3-5 [1, 64, 112, 112] 128
│ │ └─ReLU6: 3-6 [1, 64, 112, 112] --
│ └─Sequential: 2-5 [1, 128, 56, 56] --
│ │ └─Conv2d: 3-7 [1, 64, 56, 56] 576
│ │ └─BatchNorm2d: 3-8 [1, 64, 56, 56] 128
│ │ └─ReLU6: 3-9 [1, 64, 56, 56] --
│ │ └─Conv2d: 3-10 [1, 128, 56, 56] 8,192
│ │ └─BatchNorm2d: 3-11 [1, 128, 56, 56] 256
│ │ └─ReLU6: 3-12 [1, 128, 56, 56] --
│ └─Sequential: 2-6 [1, 128, 56, 56] --
│ │ └─Conv2d: 3-13 [1, 128, 56, 56] 1,152
│ │ └─BatchNorm2d: 3-14 [1, 128, 56, 56] 256
│ │ └─ReLU6: 3-15 [1, 128, 56, 56] --
│ │ └─Conv2d: 3-16 [1, 128, 56, 56] 16,384
│ │ └─BatchNorm2d: 3-17 [1, 128, 56, 56] 256
│ │ └─ReLU6: 3-18 [1, 128, 56, 56] --
│ └─Sequential: 2-7 [1, 256, 28, 28] --
│ │ └─Conv2d: 3-19 [1, 128, 28, 28] 1,152
│ │ └─BatchNorm2d: 3-20 [1, 128, 28, 28] 256
│ │ └─ReLU6: 3-21 [1, 128, 28, 28] --
│ │ └─Conv2d: 3-22 [1, 256, 28, 28] 32,768
│ │ └─BatchNorm2d: 3-23 [1, 256, 28, 28] 512
│ │ └─ReLU6: 3-24 [1, 256, 28, 28] --
│ └─Sequential: 2-8 [1, 256, 28, 28] --
│ │ └─Conv2d: 3-25 [1, 256, 28, 28] 2,304
│ │ └─BatchNorm2d: 3-26 [1, 256, 28, 28] 512
│ │ └─ReLU6: 3-27 [1, 256, 28, 28] --
│ │ └─Conv2d: 3-28 [1, 256, 28, 28] 65,536
│ │ └─BatchNorm2d: 3-29 [1, 256, 28, 28] 512
│ │ └─ReLU6: 3-30 [1, 256, 28, 28] --
│ └─Sequential: 2-9 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-31 [1, 256, 14, 14] 2,304
│ │ └─BatchNorm2d: 3-32 [1, 256, 14, 14] 512
│ │ └─ReLU6: 3-33 [1, 256, 14, 14] --
│ │ └─Conv2d: 3-34 [1, 512, 14, 14] 131,072
│ │ └─BatchNorm2d: 3-35 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-36 [1, 512, 14, 14] --
│ └─Sequential: 2-10 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-37 [1, 512, 14, 14] 4,608
│ │ └─BatchNorm2d: 3-38 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-39 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-40 [1, 512, 14, 14] 262,144
│ │ └─BatchNorm2d: 3-41 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-42 [1, 512, 14, 14] --
│ └─Sequential: 2-11 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-43 [1, 512, 14, 14] 4,608
│ │ └─BatchNorm2d: 3-44 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-45 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-46 [1, 512, 14, 14] 262,144
│ │ └─BatchNorm2d: 3-47 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-48 [1, 512, 14, 14] --
│ └─Sequential: 2-12 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-49 [1, 512, 14, 14] 4,608
│ │ └─BatchNorm2d: 3-50 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-51 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-52 [1, 512, 14, 14] 262,144
│ │ └─BatchNorm2d: 3-53 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-54 [1, 512, 14, 14] --
│ └─Sequential: 2-13 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-55 [1, 512, 14, 14] 4,608
│ │ └─BatchNorm2d: 3-56 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-57 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-58 [1, 512, 14, 14] 262,144
│ │ └─BatchNorm2d: 3-59 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-60 [1, 512, 14, 14] --
│ └─Sequential: 2-14 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-61 [1, 512, 14, 14] 4,608
│ │ └─BatchNorm2d: 3-62 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-63 [1, 512, 14, 14] --
│ │ └─Conv2d: 3-64 [1, 512, 14, 14] 262,144
│ │ └─BatchNorm2d: 3-65 [1, 512, 14, 14] 1,024
│ │ └─ReLU6: 3-66 [1, 512, 14, 14] --
│ └─Sequential: 2-15 [1, 1024, 7, 7] --
│ │ └─Conv2d: 3-67 [1, 512, 7, 7] 4,608
│ │ └─BatchNorm2d: 3-68 [1, 512, 7, 7] 1,024
│ │ └─ReLU6: 3-69 [1, 512, 7, 7] --
│ │ └─Conv2d: 3-70 [1, 1024, 7, 7] 524,288
│ │ └─BatchNorm2d: 3-71 [1, 1024, 7, 7] 2,048
│ │ └─ReLU6: 3-72 [1, 1024, 7, 7] --
│ └─Sequential: 2-16 [1, 1024, 7, 7] --
│ │ └─Conv2d: 3-73 [1, 1024, 7, 7] 9,216
│ │ └─BatchNorm2d: 3-74 [1, 1024, 7, 7] 2,048
│ │ └─ReLU6: 3-75 [1, 1024, 7, 7] --
│ │ └─Conv2d: 3-76 [1, 1024, 7, 7] 1,048,576
│ │ └─BatchNorm2d: 3-77 [1, 1024, 7, 7] 2,048
│ │ └─ReLU6: 3-78 [1, 1024, 7, 7] --
├─AvgPool2d: 1-3 [1, 1024, 1, 1] --
├─Linear: 1-4 [1, 1000] 1,025,000
├─Softmax: 1-5 [1, 1000] --
==========================================================================================
Total params: 4,231,976
Trainable params: 4,231,976
Non-trainable params: 0
Total mult-adds (M): 568.76
==========================================================================================
Input size (MB): 0.60
Forward/backward pass size (MB): 80.69
Params size (MB): 16.93
Estimated Total Size (MB): 98.22
==========================================================================================
文章出处登录后可见!