0. 引言
0.1 COCO 数据集评价指标

目标检测模型通过 pycocotools 在验证集上会得到 COCO 的评价列表,具体参数的含义是什么呢?
0.2 目标检测领域常用的公开数据集
在 MS COCO 数据集出来之前,目标检测基本上用的是 PASCAL VOC 数据集,现在 MS COCO 非常流行。这两个数据集均有自己的评判标准。
0.3 COCO(Common Objects in Context,上下文中的常见对象)数据集简介
0.3.1 介绍
COCO 数据集是一个可用于图像检测(Image Detection),语义分割(Semantic Segmentation)和图像标题生成(Image Captioning)的大规模数据集。它有超过 330K 张图像(其中 220K 张是有标注的图像),包含
- 150 万个目标
- 80 个目标类别(object categories:行人、汽车、大象等)
- 91 种材料类别(stuff categoris:草、墙、天空等)
- 每张图像包含五句图像的语句描述
- 且有 250, 000 个带关键点标注的行人
MS COCO官网:https://cocodataset.org/#home
0.3.2 MS COCO 可以应用的任务
-
目标检测(object detection):使用 bounding box 或者 object segmentation (也称为instance segmentation)将不同的目标进行标定。
-
Densepose(密集姿势估计):DensePose 任务涉及同时检测人、分割他们的身体并将属于人体的所有图像像素映射到身体的3D表面。用于不可控条件下的密集人体姿态 估计。

Key-points detection(关键点检测):在任意姿态下对人物的关键点进行定位,该任务包含检测行人及定位到行人的关键点。

Stuff Segmentation(材料细分):语义分割中针对 stuff class 类的分割(草,墙壁,天空等)

Panoptic Segmentation(全景分割):其目的是生成丰富且完整的连贯场景分割,这是实现自主驾驶或增强现实等真实世界视觉系统的重要一步。

image captioning(图像标题生成):根据图像生成一段文字。

0.3.3 COCO 的 80 个类别
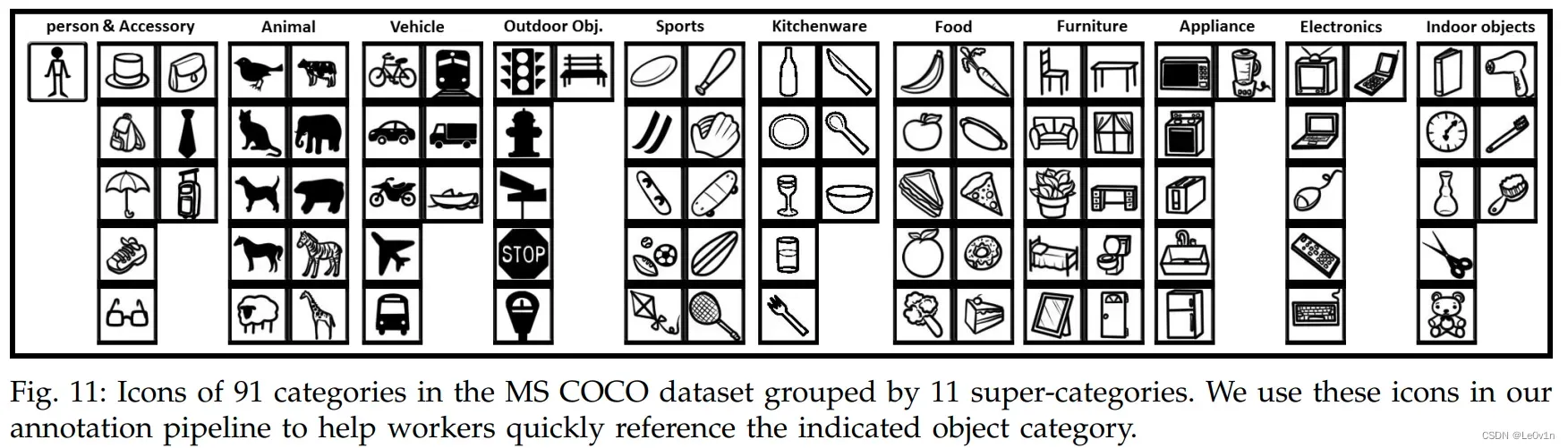

| 编号 | 英文名称 | 中文名称 | 编号 | 英文名称 | 中文名称 | 编号 | 英文名称 | 中文名称 |
|---|---|---|---|---|---|---|---|---|
| 1 | person | 人 | 28 | boat | 船 | 55 | cup | 杯子 |
| 2 | bicycle | 自行车 | 29 | traffic light | 交通灯 | 56 | fork | 叉子 |
| 3 | car | 汽车 | 30 | fire hydrant | 消防栓 | 57 | knife | 刀 |
| 4 | motorcycle | 摩托车 | 31 | stop sign | 停车标志 | 58 | spoon | 勺子 |
| 5 | airplane | 飞机 | 32 | parking meter | 停车计时器 | 59 | bowl | 碗 |
| 6 | bus | 公共汽车 | 33 | bench | 长凳 | 60 | banana | 香蕉 |
| 7 | train | 火车 | 34 | bird | 鸟 | 61 | apple | 苹果 |
| 8 | truck | 卡车 | 35 | cat | 猫 | 62 | sandwich | 三明治 |
| 9 | boat | 船 | 36 | dog | 狗 | 63 | orange | 橙子 |
| 10 | traffic light | 交通灯 | 37 | horse | 马 | 64 | broccoli | 西兰花 |
| 11 | fire hydrant | 消防栓 | 38 | sheep | 羊 | 65 | carrot | 胡萝卜 |
| 12 | stop sign | 停车标志 | 39 | cow | 牛 | 66 | hot dog | 热狗 |
| 13 | parking meter | 停车计时器 | 40 | elephant | 大象 | 67 | pizza | 披萨 |
| 14 | bench | 长凳 | 41 | bear | 熊 | 68 | donut | 甜甜圈 |
| 15 | bird | 鸟 | 42 | zebra | 斑马 | 69 | cake | 蛋糕 |
| 16 | cat | 猫 | 43 | giraffe | 长颈鹿 | 70 | chair | 椅子 |
| 17 | dog | 狗 | 44 | backpack | 背包 | 71 | couch | 沙发 |
| 18 | horse | 马 | 45 | umbrella | 雨伞 | 72 | potted plant | 盆栽 |
| 19 | sheep | 羊 | 46 | handbag | 手提包 | 73 | bed | 床 |
| 20 | cow | 牛 | 47 | tie | 领带 | 74 | dining table | 餐桌 |
| 21 | elephant | 大象 | 48 | suitcase | 行李箱 | 75 | toilet | 厕所 |
| 22 | bear | 熊 | 49 | frisbee | 飞盘 | 76 | tv monitor | 电视监视器 |
| 23 | zebra | 斑马 | 50 | skis | 滑雪板 | 77 | laptop | 笔记本电脑 |
| 24 | giraffe | 长颈鹿 | 51 | snowboard | 单板滑雪 | 78 | mouse | 鼠标 |
| 25 | backpack | 背包 | 52 | sports ball | 运动球 | 79 | remote | 遥控器 |
| 26 | umbrella | 雨伞 | 53 | kite | 风筝 | 80 | keyboard | 键盘 |
| 27 | tie | 领带 | 54 | baseball bat | 棒球棍 |
1. 目标检测中常见的指标
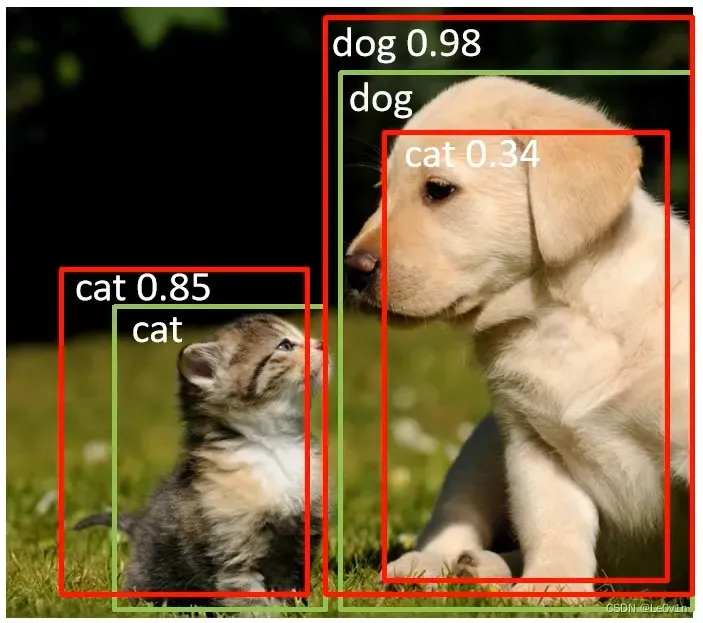
对于这样一张图片,怎样才能算检测正确呢?其中,绿色为 GT,红色为预测框。
- IoU 大于指定阈值?
- 类别是否正确?
- confidence 大于指定阈值?
以上三点都是我们需要考虑的。
1.1 TP、FP、FN
1.1.1 定义
- TP(True Positive):预测正确的预测框数量 [IoU > 阈值](同一个 GT 只计算一次)
- FP(False Positive):检测到是同一个 GT 的多余预测框的数量 [IoU < 阈值](或者是检测到同一个 GT 的多余预测框的数量)
- FN(False Negative):没有检测到 GT 的预测框数量 [漏检的数量]
- 阈值根据任务进行调整,一般选择 0.5
- FP 就是“假阳性”,就是模型误认为是 TP
1.1.2 例子说明 TP、FP、FN
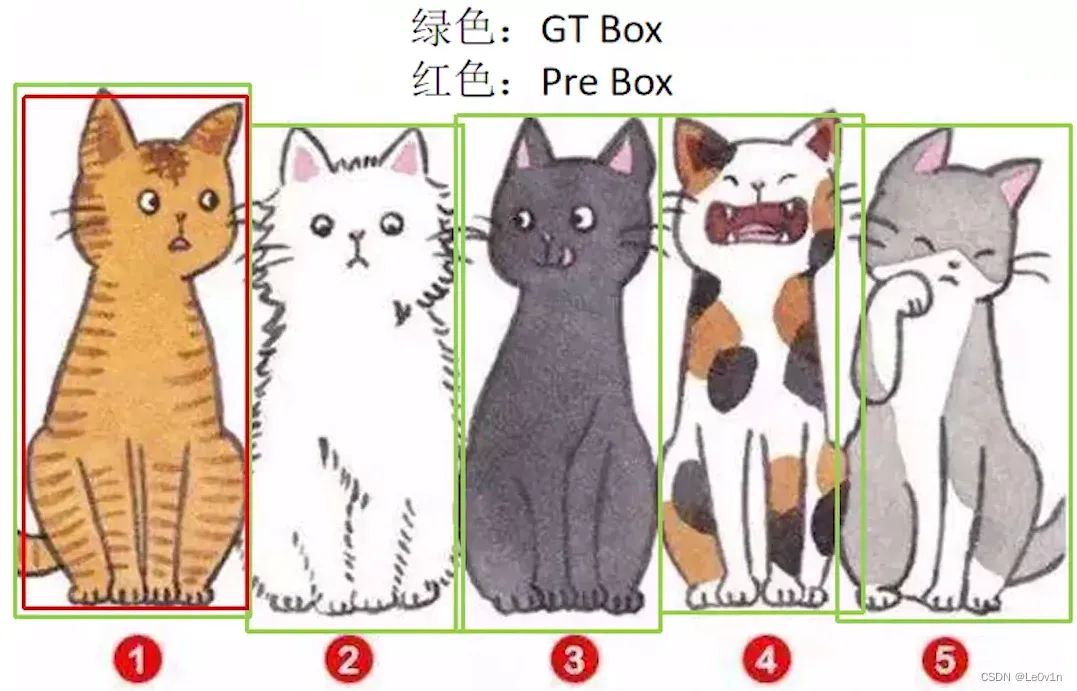
举个例子理解 TP、FP、FN:

对于张图片来说,绿色 为 GT,红色 为模型预测框,IoU 阈值设置为 0.5。
- 对于中间这只猫来说,在 绿色框(GT) 中的 预测框(红色) 和 绿色框 的 IoU 肯定是 >0.5 的,所以它应该是一个 TP(预测对了目标且 IoU > 阈值);而对于 偏左的预测框 来说,它和 GT 的 IoU 肯定是不足 0.5 的,加之因为有 TP 的存在,所以它是 FP。
- 对于右下角的那只猫,GT 是有的,但模型并没有给出对应的预测框,因此模型对于这只猫来说,漏检了,故 FN 的数量为 1。
1.2 AP(Average Precision,平均精度)
1.2.1 Precision
解释:模型预测的所有目标(Object)中,预测正确的比例 -> 查准率
模型认为正确的目标 中 确实预测对了多少
那么仅仅通过 Precision 这个指标能不能全面衡量模型的检测能力呢?举个例子进行说明:
版权声明:本文为博主作者:Le0v1n原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_44878336/article/details/134030021