前言
GAN对抗生成网络可以在数据集量少不足的情况下,根据这部分少量的数据集的特征来生成更多的新的数据集达到数据集扩充的目的,这篇文章前面部分先做个大概介绍后面有实例,都比较简单好理解,不想看理论的小伙伴可以直接跳到代码。
一、GAN基本原理
1.结构图
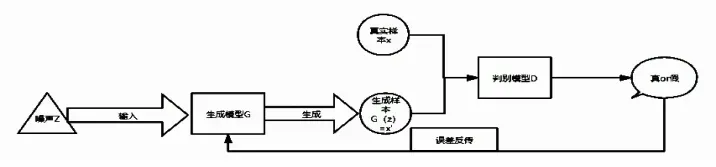
GAN由两个模型构成, 判别模型和生成模型, 判别模型可用于训练, 也可用于测试, 但生成模型只能用于测试。生成模型捕捉真实样本的分布, 并根据分布生成新的fake样本;判别器是判别输入是真实样本还是fake样本的二分类器。模型G和D通过不断的对抗训练,使D正确判别训练样本来源,同时使G生成的fake样本与真实样本更相像。
2.目标函数
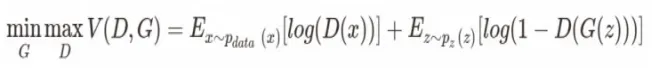
GAN是生成网络和判别网络的博弈问题,判别网络D希望真实样本x的概率值越大越好,同时希望判断fake样本G(z)为真实样本的概率值越小越好,而生成网络G希望fake样本G(z)与x越相似越好,让判别网络判断其为真实样本的概率D(G(z))越高越好。
二、实现
1.实现流程图
(这个流程图是识别模型在扩充数据集前后准确率的对比流程图,如果只是想通过gan生成一部分样本就只参考这个流程图的上半部分)
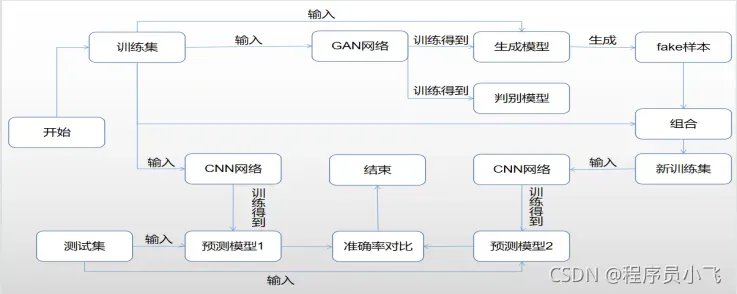
流程图说明:1.先把原始训练集中的图片送入GAN网络训练得到GAN的生成模型和判别模型,同时将原始训练集中的图片送入CNN网络中训练得到第一个预测模型 2.将原始训练集中的图片再送入步骤1中训练GAN后得到的生成模型中,得到若干输出的fake样本 3.将步骤2得到的fake样本和原始训练集组合得到一个在原始数据集上加入了fake样本进行扩充后的新训练集 4.将新的训练集送入与步骤1相同的CNN网络中训练得到第二个预测模型 5.将测试集的图片送入步骤1和步骤4得到的两个预测模型中,对比预测准确率得到实验结论。
2.实例
2.1采集少量原始数据
采集实验者的手写数字0到9各30张作为原始训练集样本,以及0到9各20张作为测试集:

采集代码:(注意修改保存路径)
# coding=utf-8
##手写数字创建原始数据集
import cv2
import numpy as np
import os
# =========画布==================
img = np.zeros((512, 512), dtype=np.uint8)
# =========窗口事件相应函数==================
def draw_number(event, x, y, flags, param):
global is_drawing
if event == cv2.EVENT_LBUTTONDOWN:
is_drawing = True
cv2.circle(img, (x, y), 9, (255, 255, 255), -1)
elif event == cv2.EVENT_LBUTTONUP:
is_drawing = False
elif event == cv2.EVENT_MOUSEMOVE and flags == cv2.EVENT_FLAG_LBUTTON:
# if is_drawing == True:
cv2.circle(img, (x, y), 9, (255, 255, 255), -1)
# =========主函数==================
def main(save_path):
global img
number=0
cv2.namedWindow("main")
cv2.setMouseCallback("main", draw_number)
while True:
cv2.imshow("main", img)
key = cv2.waitKey(5)
if key == ord("q"):
break
elif key == ord("c"):
img = np.zeros((512, 512), dtype=np.uint8)
elif key == ord("s"): # 保存
if not os.path.exists(save_path):
os.mkdir(save_path)
cv2.imwrite(save_path+'\\'+str(number)+'.jpg', img)
number=number+1
if number==10:
break
cv2.destroyAllWindows()
if __name__ == "__main__":
test_train=input("需要保存在train还是test")
file_number=input("写入的是数字几")
print("写入数字后按S保存,保存十次后自动退出")
save_path='data\Experimenter handwritten digits\\'+test_train+'\\'+file_number
main(save_path)
2.2GAN模型训练(注意修改图片路径)
# coding=utf-8
import torch.autograd
import torch.nn as nn
from torch.autograd import Variable
from torchvision import transforms
from torchvision.utils import save_image
from PIL import Image
import os
num_epoch = 300
z_dimension = 100
# 图像预处理
img_transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # (x-mean) / std
])
route='data\After Gan expansion'
train_dir=os.path.join(route,'train')
#训练数据
training_set=[]
for dir_name in os.listdir(train_dir):
data = []
for file_name in os.listdir(os.path.join(train_dir,dir_name)):
img=Image.open(os.path.join(train_dir,dir_name,file_name))
x=img_transform(img)
data.append(x)
training_set.append(data)
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:
out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行
return out
# 定义判别器 #####Discriminator######使用多层网络来作为判别器
# 将图片28x28展开成784,然后通过多层感知器,中间经过斜率设置为0.2的LeakyReLU激活函数,
# 最后接sigmoid激活函数得到一个0到1之间的概率进行二分类。
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.dis = nn.Sequential(
nn.Linear(784, 256), # 输入特征数为784,输出为256
nn.LeakyReLU(0.2), # 进行非线性映射
nn.Linear(256, 512), # 进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(512, 256), # 进行一个线性映射
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 也是一个激活函数,二分类问题中,
# sigmoid可以班实数映射到【0,1】,作为概率值,
# 多分类用softmax函数
)
def forward(self, x):
x = self.dis(x)
return x
# ###### 定义生成器 Generator #####
# 输入一个100维的0~1之间的高斯分布,然后通过第一层线性变换将其映射到256维,
# 然后通过LeakyReLU激活函数,接着进行一个线性变换,再经过一个LeakyReLU激活函数,
# 然后经过线性变换将其变成784维,最后经过Tanh激活函数是希望生成的假的图片数据分布
# 能够在-1~1之间。
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 512), # 用线性变换将输入映射到512维
nn.ReLU(True), # relu激活
nn.Linear(512, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 784), # 线性变换
nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布
)
def forward(self, x):
x = self.gen(x)
return x
Number_table=0
for training_data in training_set:
# 创建对象
D = discriminator()
G = generator()
if torch.cuda.is_available():
D = D.cuda()
G = G.cuda()
# 首先需要定义loss的度量方式 (二分类的交叉熵)
# 其次定义 优化函数,优化函数的学习率为0.0003
criterion = nn.BCELoss() # 是单目标二分类交叉熵函数
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
# ##########################进入训练##判别器的判断过程#####################
for epoch in range(num_epoch): # 进行多个epoch的训练
for i, img in enumerate(training_data):
num_img = img.size(0)
# view()函数作用是将一个多行的Tensor,拼接成一行
# 第一个参数是要拼接的tensor,第二个参数是-1
# =============================训练判别器==================
img = img.view(num_img, -1) # 将图片展开为28*28=784
real_img = Variable(img).cuda() # 将tensor变成Variable放入计算图中
real_label = Variable(torch.ones(num_img)).cuda() # 定义真实的图片label为1
fake_label = Variable(torch.zeros(num_img)).cuda() # 定义假的图片的label为0
# ########判别器训练train#####################
# 分为两部分:1、真的图像判别为真;2、假的图像判别为假
# 计算真实图片的损失
real_out = D(real_img) # 将真实图片放入判别器中
real_label = real_label.reshape([-1, 1])
d_loss_real = criterion(real_out, real_label) # 得到真实图片的loss
real_scores = real_out # 得到真实图片的判别值,输出的值越接近1越好
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 随机生成一些噪声
fake_img = G(z).detach() # 随机噪声放入生成网络中,生成一张假的图片。 # 避免梯度传到G,因为G不用更新, detach分离
fake_out = D(fake_img) # 判别器判断假的图片,
fake_label = fake_label.reshape([-1, 1])
d_loss_fake = criterion(fake_out, fake_label) # 得到假的图片的loss
fake_scores = fake_out # 得到假图片的判别值,对于判别器来说,假图片的损失越接近0越好
# 损失函数和优化
d_loss = d_loss_real + d_loss_fake # 损失包括判真损失和判假损失
d_optimizer.zero_grad() # 在反向传播之前,先将梯度归0
d_loss.backward() # 将误差反向传播
d_optimizer.step() # 更新参数
# ==================训练生成器============================
# ###############################生成网络的训练###############################
# 原理:目的是希望生成的假的图片被判别器判断为真的图片,
# 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
# 反向传播更新的参数是生成网络里面的参数,
# 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的
# 这样就达到了对抗的目的
# 计算假的图片的损失
z = Variable(torch.randn(num_img, z_dimension)).cuda() # 得到随机噪声
fake_img = G(z) # 随机噪声输入到生成器中,得到一副假的图片
output = D(fake_img) # 经过判别器得到的结果
g_loss = criterion(output, real_label) # 得到的假的图片与真实的图片的label的loss
# bp and optimize
g_optimizer.zero_grad() # 梯度归0
g_loss.backward() # 进行反向传播
g_optimizer.step() # .step()一般用在反向传播后面,用于更新生成网络的参数
# 打印中间的损失
if (i + 1) % 100 == 0:
print('Epoch[{}/{}],d_loss:{:.6f},g_loss:{:.6f} '
'D real: {:.6f},D fake: {:.6f}'.format(
epoch, num_epoch, d_loss.data.item(), g_loss.data.item(),
real_scores.data.mean(), fake_scores.data.mean() # 打印的是真实图片的损失均值
))
fake_images = to_img(fake_img.cpu().data)
if not os.path.exists( 'data\Gan training process picture\\'+str(Number_table)):
os.mkdir( 'data\Gan training process picture\\'+str(Number_table))
save_image(fake_images, 'data\Gan training process picture\\'+str(Number_table)+'\\fake_images-{}.png'.format(epoch + 1))
# 保存模型
torch.save(G.state_dict(), 'Saved_model\GAN/generator'+str(Number_table)+'.pth')
torch.save(D.state_dict(), 'Saved_model\GAN/discriminator'+str(Number_table)+'.pth')
Number_table=Number_table+1
2.3用训练好的模型扩充数据集(生成fake样本,注意修改模型路径)
扩充代码:
import torch
import torch.nn as nn
import os
from torch.autograd import Variable
from torchvision.utils import save_image
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.gen = nn.Sequential(
nn.Linear(100, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 512), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(512, 256), # 用线性变换将输入映射到256维
nn.ReLU(True), # relu激活
nn.Linear(256, 784), # 线性变换
nn.Tanh() # Tanh激活使得生成数据分布在【-1,1】之间,因为输入的真实数据的经过transforms之后也是这个分布
)
def forward(self, x):
x = self.gen(x)
return x
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1) # Clamp函数可以将随机变化的数值限制在一个给定的区间[min, max]内:
out = out.view(-1, 1, 28, 28) # view()函数作用是将一个多行的Tensor,拼接成一行
return out
G=generator()
if torch.cuda.is_available():
G = G.cuda()
model_path='Saved_model\GAN'
save_image_path='data\After Gan expansion\\train'
model_path_list=[]
save_image_path_list=[]
for dir_name in os.listdir(model_path):
if 'generator' in dir_name:
model_path_list.append(model_path+'\\'+dir_name)
for dir_name in os.listdir(save_image_path):
save_image_path_list.append(save_image_path+'\\'+dir_name)
for model,image_path in zip(model_path_list,save_image_path_list):
G.load_state_dict(torch.load(str(model)))
for number in range(31,101):
z = Variable(torch.randn(1, 100)).cuda()
fake_img =G(z)
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, image_path+'\\'+str(number)+'.jpg')
#os.remove(image_path + '\\' + str(number) + '.jpg')
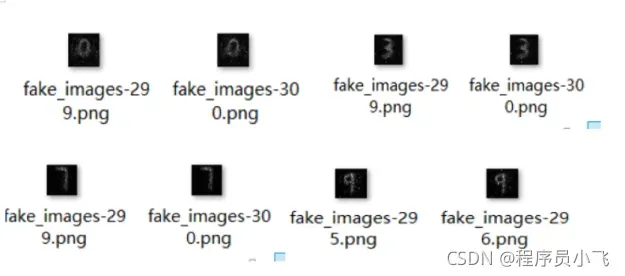
2.4fake样本长这样
三、数据目录结构展示
最上层目录结构:

data目录结构:


data/After Gan expansion和data\Experimenter handwritten digits都长这样:

data/After Gan expansion/train和data/After Gan expansion/test都是这样,同样data/Experimenter handwritten digits/train和data/Experimenter handwritten digits/test也是这样:

每一个编号存放对应的数字 如图:

data/Gan training process picture:
每个文件夹里存放的是训练GAN的时候生成模型产生的数据

Saved_model目录结构:


Saved_model/GAN
保存的每个数字的生成网络和对抗网络
总结
人懒此处省略,有问题欢迎评论区,阿巴阿巴。。。。。。。。。。。。。
文章出处登录后可见!