GPT-4原论文详细解读(GPT-4 Technical Report)
1.导读
相比之前的GPT-3.5等大型语言模型(这里可以看我的InstructGPT解读,也方便理解本文内容),GPT-4最大的不同在于变成了多模态,即输出不变的情况下,输入可以为图片或文本。其展现了优于ChatGPT模型并且非常强大的性能。读者可在OpenAI官网体验体验,不过网页端只提供了文本输入,图片输入的方式目前只支持API。
2.摘要和引言
GPT-4是一个多模态的大模型。它的基础结构仍然是Transformer+预测下一个词的目标函数。
GPT-4在摘要中的说法是给出了一个预测模型性能的方法,使得只需要0.1%的训练计算资源,就可以预测模型的性能了。不需要训练到最后才得到模型性能,这有助于早期就调整好模型,减少不必要的训练成本。
GPT-4这篇工作目的是增强理解生成文本的能力,尤其在复杂且存在细微差异的场景。
GPT-4使用了很多人类的考试(例如,律师资格考试)和传统的NLP任务作为测试案例。
GPT-4仍然存在之前工作中的一些问题:1.会瞎编,缺乏可靠性。2.限制25000字。3.无法从经验中学习。
3.论文结构
- 第3节:本文的内容涉及范围
- 第4节:预测技术(预测模型性能相关技术,使得用少数的训练就能预测模型的性能),这部分本篇博客跳过
- 第5节:详细介绍GPT-4的能力,实验
- 第6节:详细介绍GPT-4的局限性
- 第7节:风险和因对方法
- 第8节:结论
- 参考文献
- 附录23-98页
4.本文的内容涉及范围
- 不会给出具体的技术细节,包括模型结构,模型大小,硬件,训练成本,数据集,训练方法。
- 会给出一些初始的步骤和想法。
5.GPT-4的能力,实验
对于这部分实验,OpenAI在github上开源了评估框架。
模拟人类的考试
值得注意的是,这些考试的问题在模型训练的时候只会看到一部分相关的资料(例如律师考试不会有真题,但可能在训练集中有些相关法律书籍),这部分的实验展开的细节放在了附录C。这些测试的真题都来源于公开的available的材料。题目包括选择题和论述题,OpenAI对于这两种题目分别设计了prompt,这些prompt包括图片。最后这个实验考试的打分方式和人类的考试一样。这部分的实验的细节放在了附录A。
下表是实验结果,第一列是考试名称,包括律师考试、研究生入学考试、生物、化学、计算机。第2列是GPT-4(带vision输入的)、GPT-4(不带vision输入的)、GPT-3.5(应该不是ChatGPT,而是基础GPT-3.5)。分别给出了分数(例如298/400,分别是得分/总分)和排名(例如~90th,100个人超过了90%的人)。
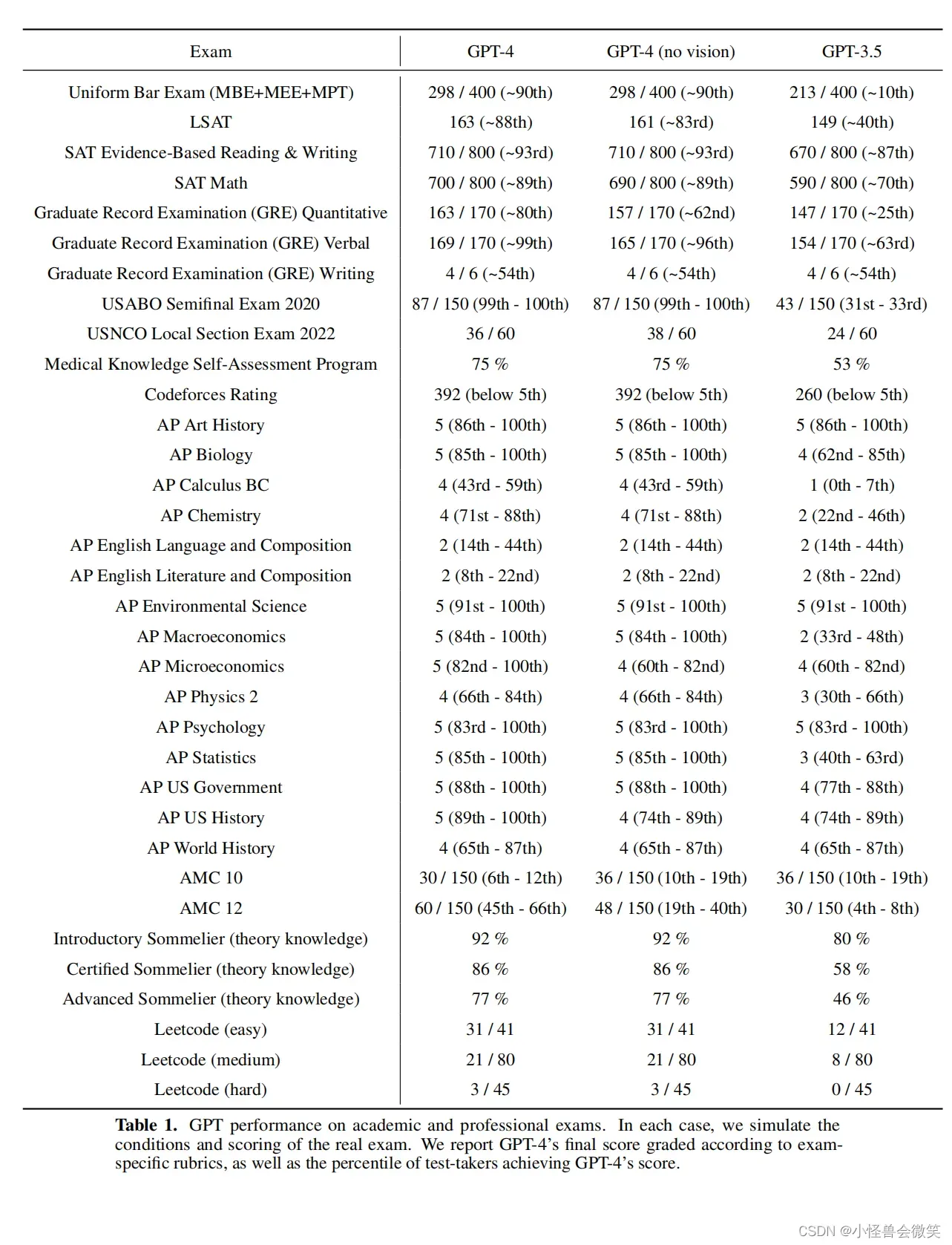
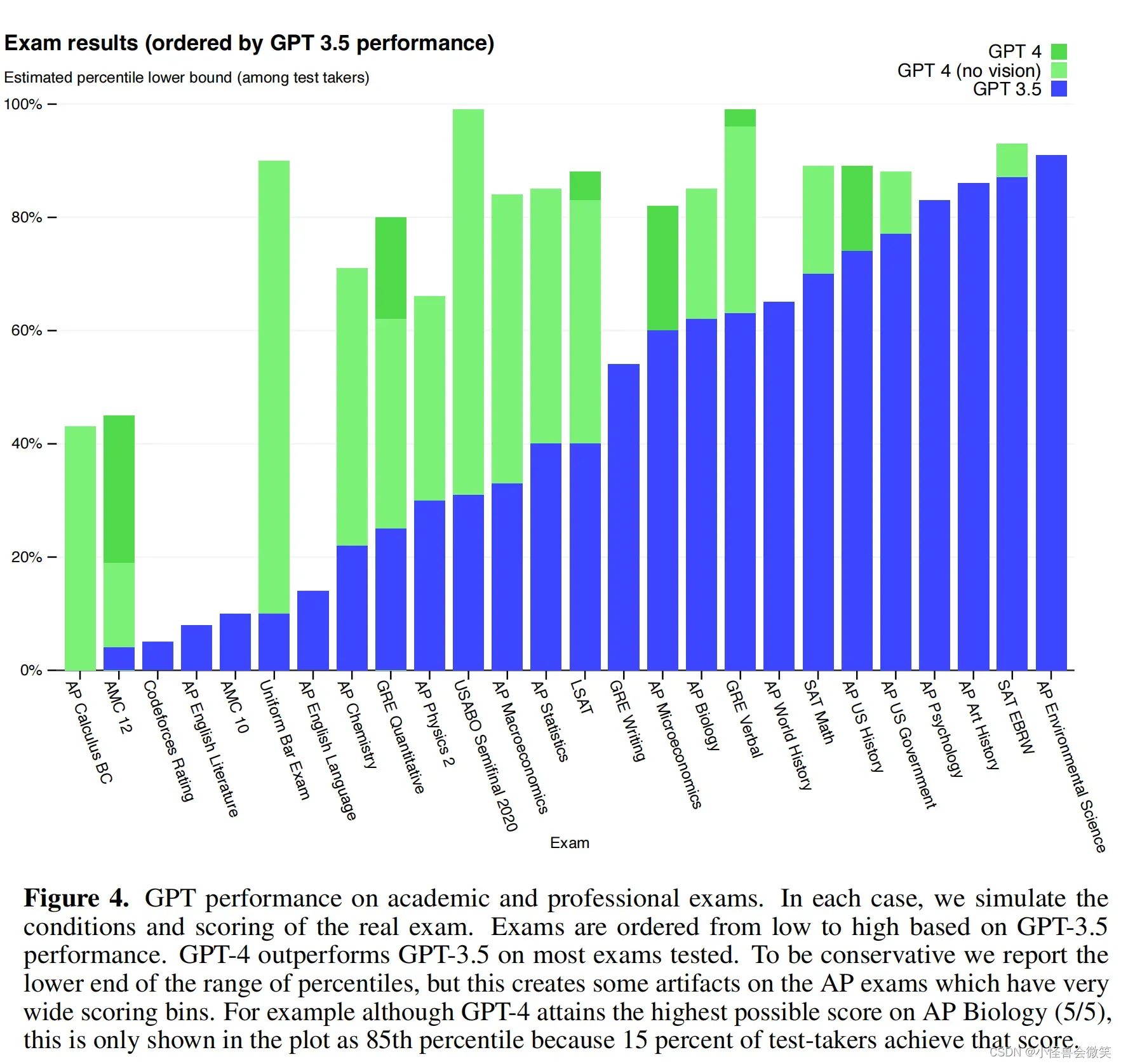
下图给出了图示化展示,可以清晰看出GPT-4较不带vision和baseline的GPT3.5的差距。其中横坐标是考试名称,纵坐标是得分占总分的比。蓝色上方的绿色表示GPT-4(不带vision模块)超过GPT3.5的性能部分。如果绿色上方有深绿色,则表示GPT-4(带vision模块)超过GPT-4(不带vision模块)的性能部分。如果蓝色上方无其他(例如最后一列),则表示3者无差异。
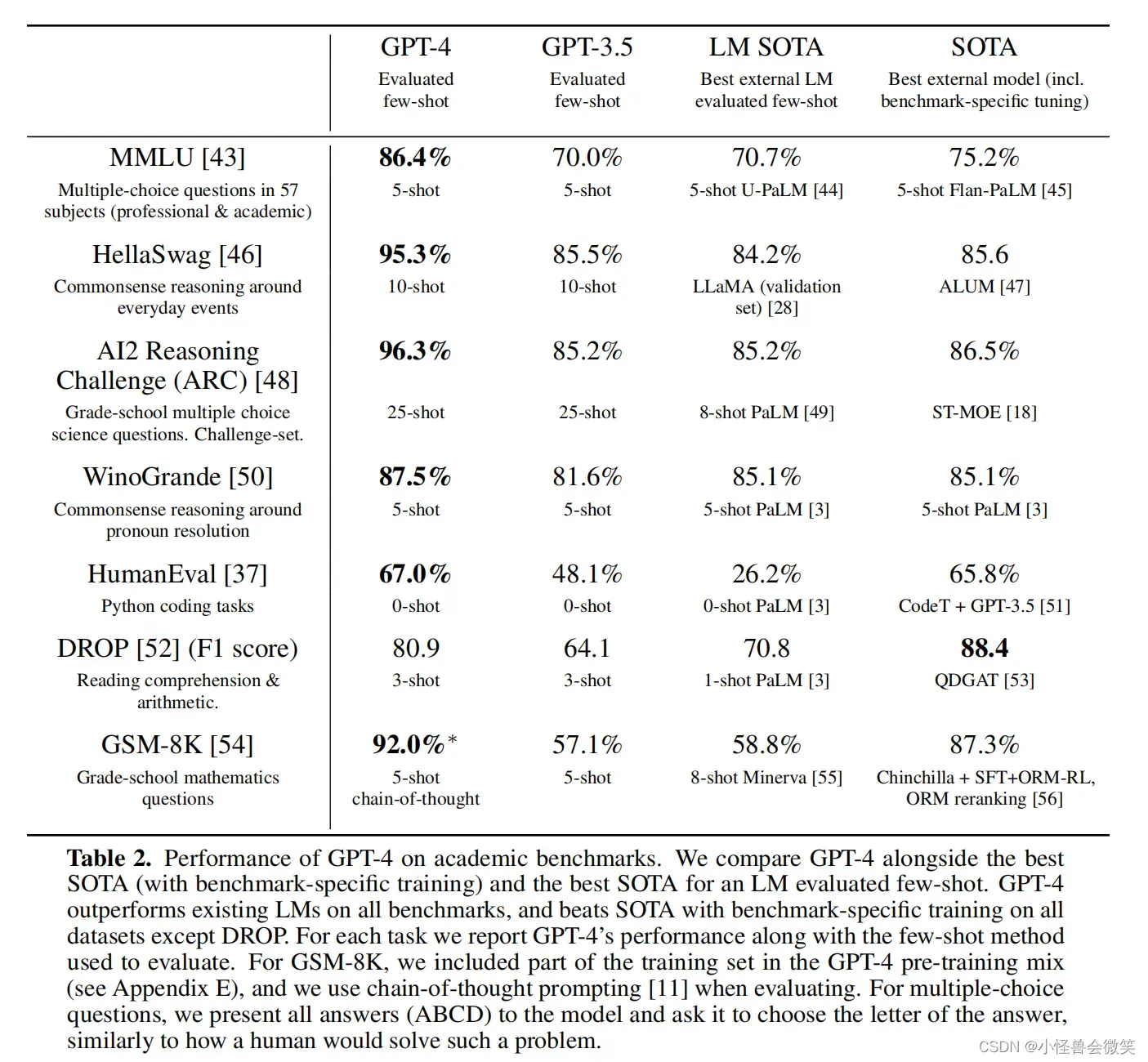
传统的NLP任务
为了让GPT-4能理解实验问题什么的,OpenAI进行了适当的预处理,包括“问题翻译”和给出few-shot(细节见附录F)。
实验结果如下,第一列是案例(例如MMLU是在57个学术和专业性学科的多项选择题)。最后两列是最先进的模型(有特定任务上的微调)。
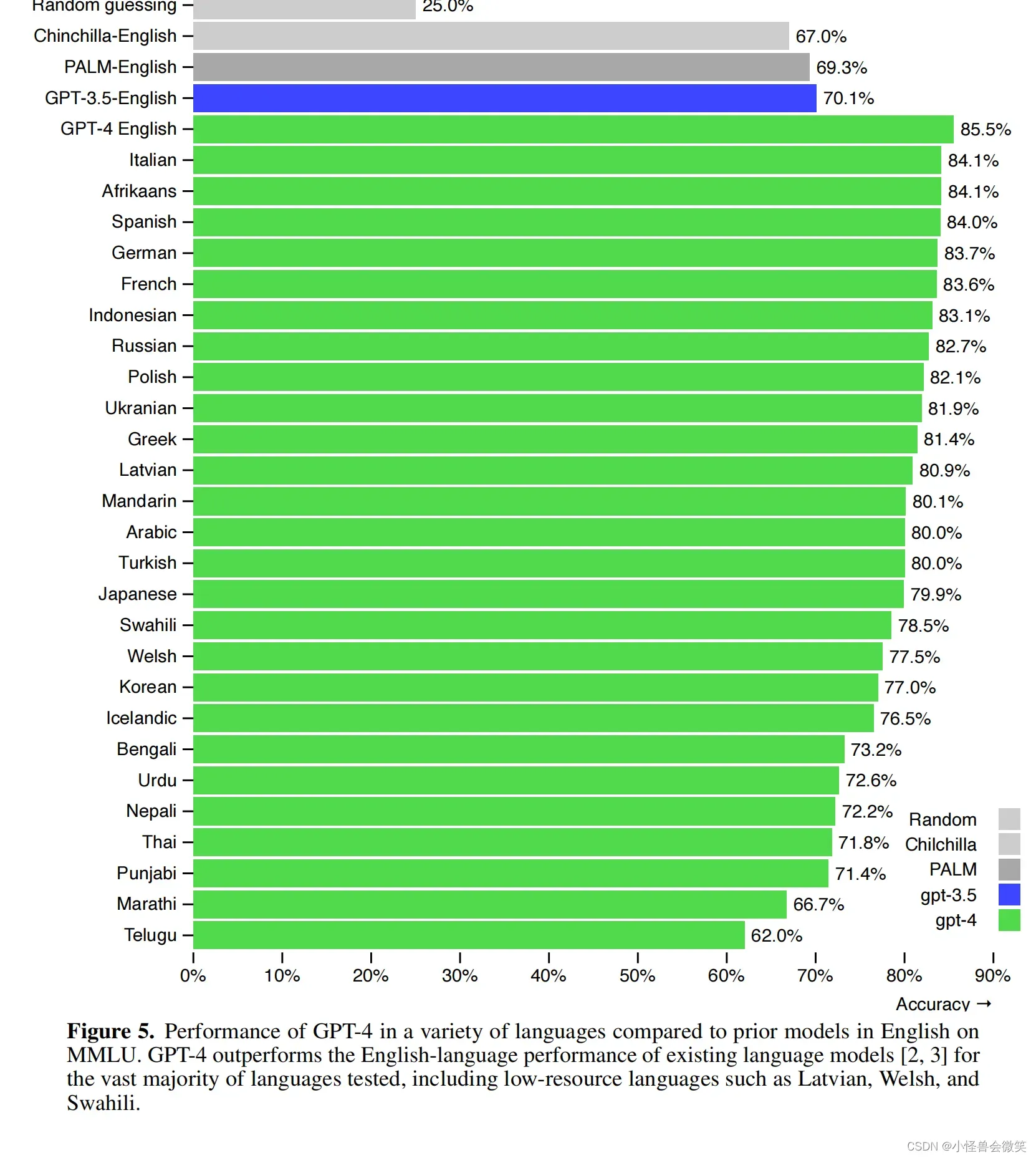
下图给出了不同语音对GPT-4性能的影响。
下图给出了GPT-4图片输入时的例子。
看了下回答,没什么问题,感觉理解了图片内容,并结合了LM中的常识,具备了一定的认知水平,很强!

5.GPT-4的局限性
未完待续。
文章出处登录后可见!