Datawhale干货
作者:皮钱超,厦门大学,Datawhale成员
深圳租房数据分析完整篇
从2020年11月发表第一篇深圳租房数据分析的文章,到这篇基于深度学习框架Keras的建模分析和预测,在此谈谈3篇文章的特点:
1、第一篇:
写于2020年11月,笔者作为一名数据分析师,学习了Python、SQL、爬虫、可视化以及部分机器学习的常见算法和模型,所以在第一篇文章中的重点是:统计与可视化分析。看过文章的小伙伴应该都知道,里面出现了许多还算漂亮的可视化图表(下面是部分图)。
一图胜千言,从统计和可视化图表的角度能够很快速且直观地看到数据分布和变化趋势。文章中使用可视化库是Plotly,一个非常棒的动态可视化库,强烈推荐学习~
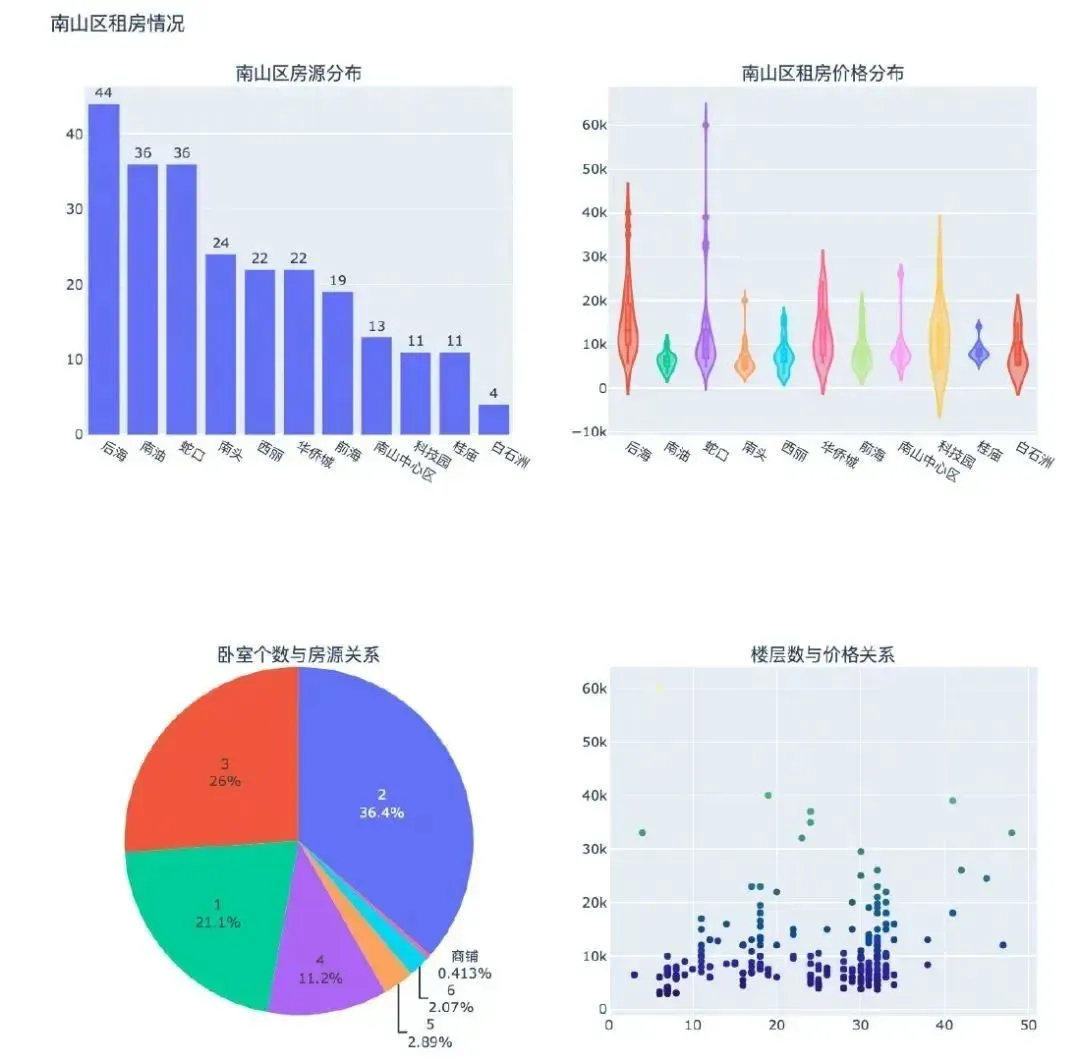
文章地址:
https://mp.weixin.qq.com/s/DEsclUfdnmVqICiK5rM57Q
2、第二篇:
写于2022年3月,笔者仍然是一名数据分析师。从2020年末到2022年初,一年左右的时间,笔者接触和学习了更多的是机器学习的算法、特征工程以及模型的可解释性等知识点。
在这篇文章中,笔者花费了大量的工作来做10个字段的预处理和特征工程工作,重点是如何做编码处理,便于后续输入到不同的回归模型中,以及各种模型的对比。
最后,笔者对模型的可解释性进行了探索,主要基于目前一个流行的可解释库:SHAP。
SHAP将所有的特征都视为“贡献者”。 对于每个预测样本,模型都产生一个对应的预测值,SHAP value就是该样本中每个特征所分配到的数值
关于特征工程的学习,笔者推荐一本书:《特征工程入门与实践》。
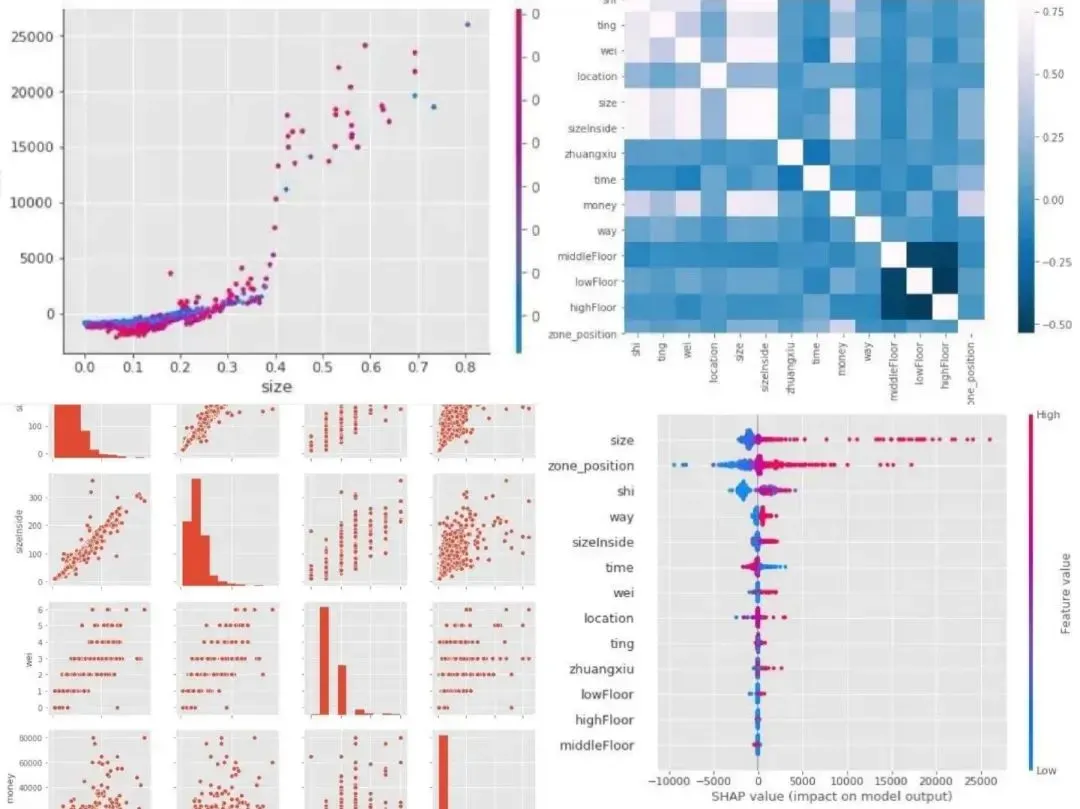
文章地址:
https://mp.weixin.qq.com/s/iO47yo6IgYgw6xZ8W-8lbQ
3、第三篇(本篇)
写第3篇(也就是看到的这篇)的时候,笔者依旧是一名数据分析师。今年的学习重点转移到了深度学习和kaggle比赛,最近一段时间学习一些DL的基础和Keras框架对于分类和回归问题的建模,从网络模型搭建、编译、训练网络等步骤完成整个建模的基本过程。
DL的建模过程后面深入学习了之后,会对现有的模型进行下一步的优化!
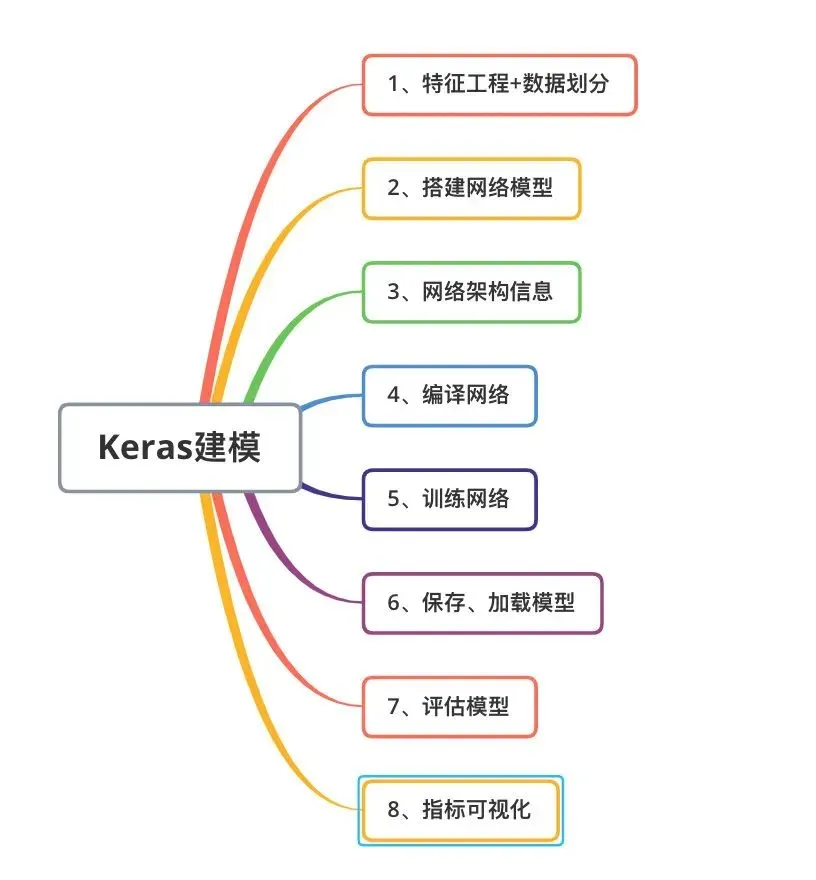
写在最后:3篇文章仅代表了笔者的一些学习经历和知识总结,关于文章的具体细节部分,如果大家有认为有更好的处理方式或者不恰当的地方,欢迎指出来一起学习讨论~
Datawhale后台回复 深圳 可下载租房数据
本文是针对深圳租房数据的第3次分析,主要包含数据预处理、采样处理、基于Keras的建模等:
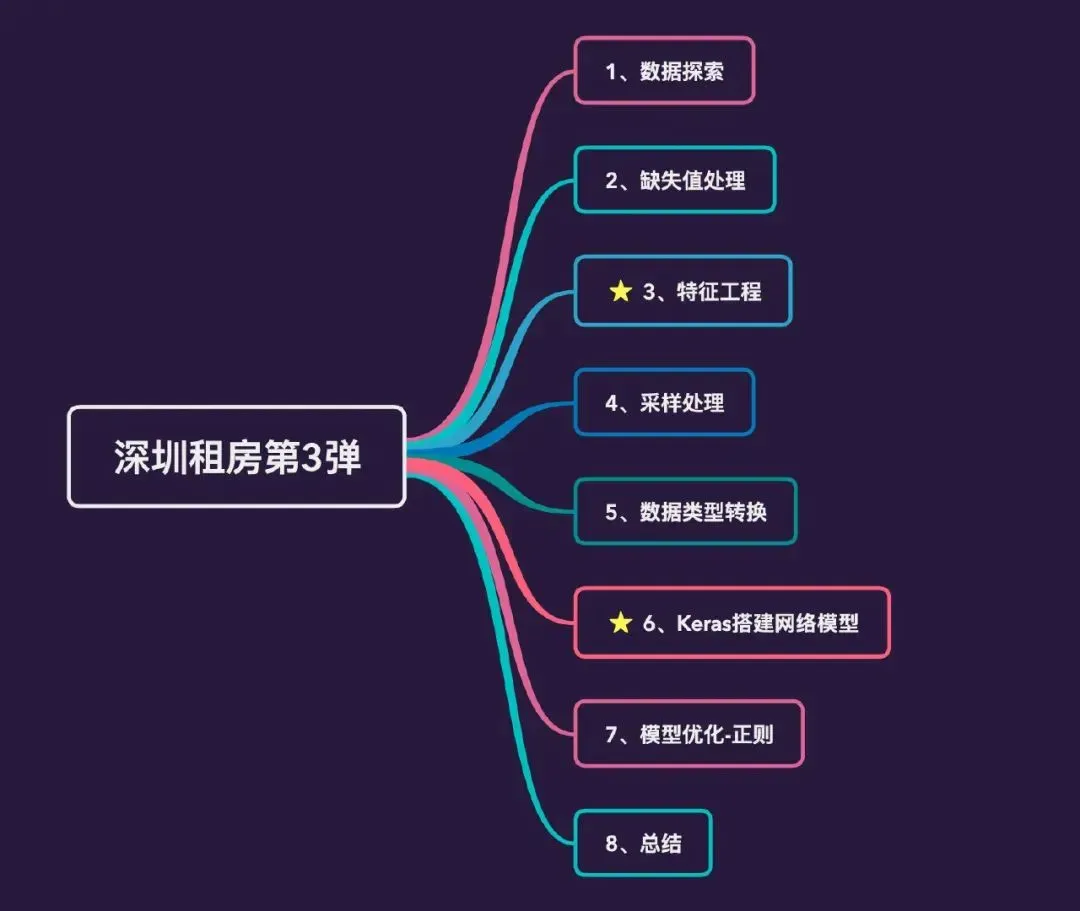
导入库
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.graph_objects as go
import matplotlib.pyplot as plt
import seaborn as sns
# plt.style.use("fivethirtyeight")
plt.style.use('ggplot')
import sklearn.preprocessing as pre_processing
from imblearn.over_sampling import SMOTE
from sklearn.preprocessing import StandardScaler,MinMaxScaler
import tensorflow as tf
from keras import models
from keras import layers
np.random.seed(123)
pd.options.mode.chained_assignment = None数据基本信息
读取数据
df = pd.read_excel("leyoujia.xls")
df.head()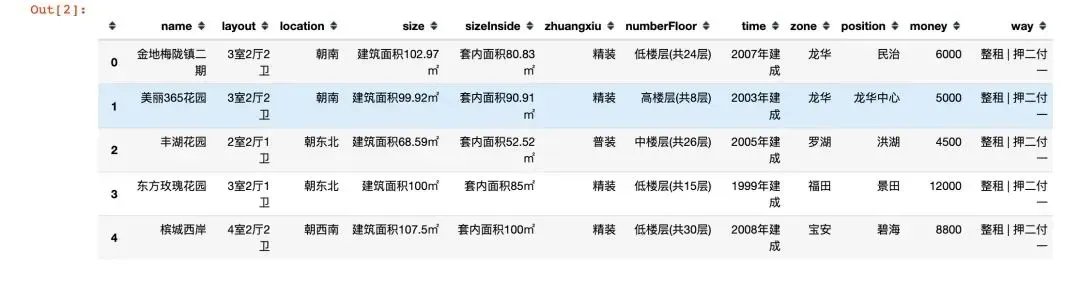
数据shape
In [3]:
# 数据形状
df.shapeOut[3]:
(2020, 12)数据shape返回的是一个列表,第一个取值表示数据的行数,第二个是属性个数,即字段的多少
字段类型
In [4]:
# 数据的字段类型
df.dtypesOut[4]:
大部分都是字符串类型,只有money,就是最终的预测值是数值型
name object
layout object
location object
size object
sizeInside object
zhuangxiu object
numberFloor object
time object
zone object
position object
money int64
way object
dtype: objectIn [5]:
# 数据中的缺失值
df.isnull().sum()Out[5]:
name 0
layout 0
location 0
size 0
sizeInside 0
zhuangxiu 0
numberFloor 0
time 6 # 缺失值
zone 0
position 0
money 0
way 0
dtype: int64缺失值处理
找出缺失值
在time字段中存在缺失值,找出缺失值所在的行数据信息:

文章出处登录后可见!