代码:https://github.com/zanshuxun/User-Difference-Attention
1. What does literature study?
- 提出了一个user-difference用户差异注意模型(UDA),利用关系注意力显式模拟群体成员之间的comparisons(用户之间的明确关系),
2. What’s the innovation?
- Past shortcomings
a. 大多数的方法只考虑了单个用户和目标项目来计算它们的权值,这不足以确定用户在群组中的重要性。
b.一个用户面对不同的items或在不同的组会有不同的影响influences,因此预定义聚合策略不能很好work。
c.AGREE忽略了不同用户之间的比较,因为,仅当用户与其他用户相比更重要它的权值才会更高。因此,不同用户之间的比较能够提供更多了解他们内部结构的信息 - innovation:
a.提出对比信息的重要性,comparison是组成员之间的明确关系,有助于确定哪个用户更熟悉目标项,从而得出成员之间的准确权值。
b.提出了一个user-difference用户差异注意模型(UDA),利用关系注意力显式模拟群体成员之间的关系,使用用户关系核(URK)得出用户之间的comparison向量。
c.提出了四个用户关系内核(URKs)模拟组决策过程中的几种类型的关系。
3. What was the methodology?
利用关系注意力显式模拟群体成员之间明确关系,将每个用户与其他用户进行比较,利用MLP添加非线性变换。提出用几个用户关系核(URK)模拟小组决策过程中不同类型的关系。
研究的目的是:利用关系注意力来整合比较信息的群组推荐模型。
- 构建多个关系核来显式比较组成员
- 利用多层感知机得出其权值的分布
- 将最佳核集成到UDA模型中研究其有效性
User-difference attention:
通过实现不同用户之间的差异算子来获取比较的信息。(与基于单用户的模型不同:AGREE)
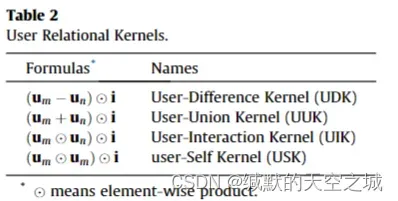
提出了四种关系核,UDK计算在给定item下一个用户与其他用户的差异以提高与项目相关的用户的影响。UUK在不同用户之间应用一个联合操作找到他们偏好的联合集。UIK使用元素乘法获得相互偏好。USK增强自己的信息而不是与他人互动。
给定一个group g和一个目标item i,组内两个用户之间的比较向量为
,
表示上述四种操作,最有效的是UDK:给定目标项目,更熟悉此项目的用户有更高的权值。获取比较信息的重要性在于它可以减少学习和捕获群体与目标项目之间关系的难度。
因此得到:,然后计算比较向量
,它等于其在组内与其他成员之间的比较总和:
。(不懂)
模型流程:
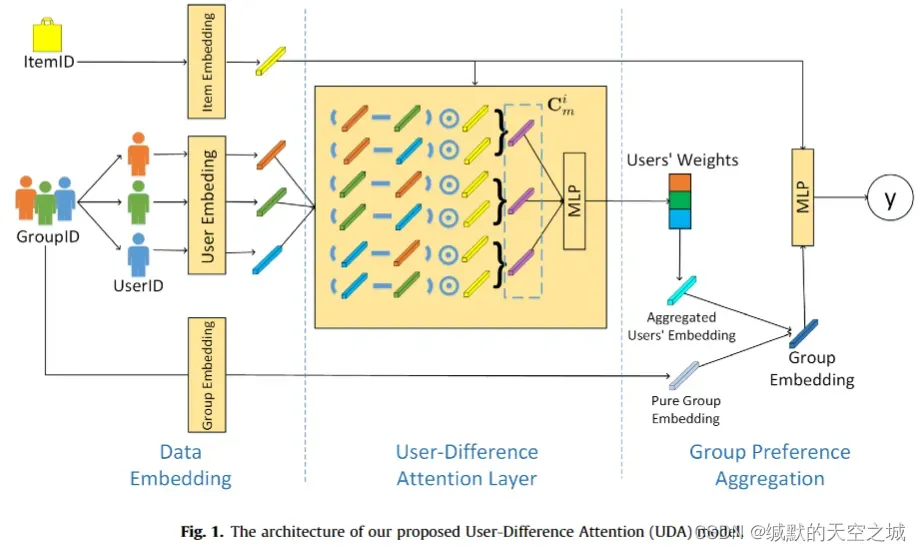
4. What are the conclusions?
- 实验
ML-100K没有组信息,根据用户与用户相似度生成一些合成组,然后提取group-item交互数据来评价组推荐。采样一定数量负样本,将模型训练为二元分类器。
评价指标:对每个组,我们使用排名分数对候选项目排序获得top-K推荐列表,利用user-item交互数据和group-item交互数据交替训练模型,使用户推荐任务和组推荐任务相互优化。评价指标采用HR(命中率)和NDCG(归一化折损累积增益):
,
表示top K推荐列表,
表示测试集项目集合;
,
,其中
是二进制表示推荐列表
位置的项目是否出现在测试集中,
是长度为K的所有可能的推荐列表中最大的
值(不懂)。这两个指标值越大,推荐性能越好。记录每个组的指标,并将平均值作为最终评价指标。
- 结论:
关系核user-difference kernel(UDK)可以学习到更有效的用户权重分布,提高组推荐性能。
5. others
- 组推荐
- 基于内存的方法:(1)偏好聚合。首先更具各种策略聚合组成员的特征,将组group视为虚拟用户,从而使用一系列个性化的推荐算法;(2)分数聚合。首先预测每个群体成员在候选items上的得分,然后根据预定义的策略聚合分数。
- 基于模型的方法:通过学习群体决策的生成过程来提出群体推荐。
- 正如 TransE 中提出的,两个对象之间的语义关系可以理解为两个对象之间差异的转换。
- 通过比较给定项目下用户与其他用户之间的差异可以增强项目相关用户的影响力(用户权值)。确定哪个用户对目标项目更熟悉,从而在小组中更有影响力。
文章出处登录后可见!
已经登录?立即刷新