文章目录
1. 参数的更新方法
1.1 SGD函数更新
class SGD:
def __init__(self, lr = 0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
1.2 SGD 的缺点
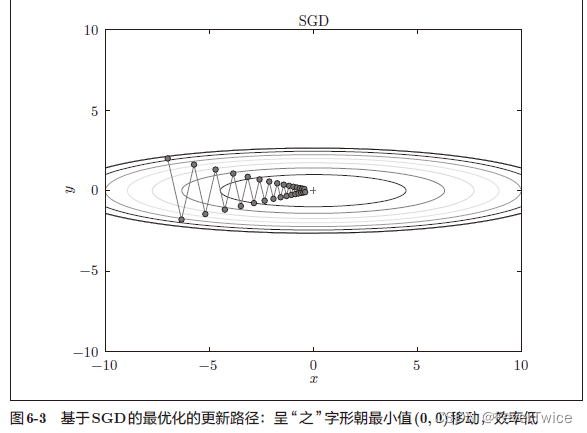
SGD向下搜索,呈现z字形状,但是这种搜索效率是十分低下的
- 梯度每个指向最小值的反向
- 呈延伸状的搜索路径低效
1.3 Momentum更新方法
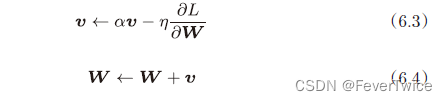
关于python中的 .item
Python 字典(Dictionary) items() 函数以列表返回可遍历的(键, 值) 元组数组。
遍历字典列表
for key,values in tinydict.items():
print key,values
字典值 : [(‘Google’, ‘www.google.com’), (‘taobao’, ‘www.taobao.com’), (‘Runoob’, ‘www.runoob.com’)]
Google www.google.com
taobao www.taobao.com
Runoob www.runoob.com
class Momentum:
def __init__(self, lr = 0.01, momentum = 0.9):
self.lr = lr
self.momentum = momentum
self.v = None # 初始化
def update(self, params, grads):
if self.v is None:
self.v = {}
# 初始化与传入参数结构一样的数据
# v 与params的结构相同(W)
for key, val in params.items():
self.v[key] = np.zero_like(val)
for key in params.keys():
self.v[key] = self.momentum * self.v[key] - self.lr * grads[key]
params[key] += self.v[key]
1.4 AdaGrad
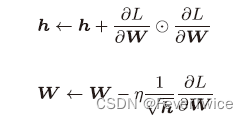
class AdaGrad:
def __init__(self, lr = 0.01):
self.lr = lr
self.h = None
def update(self, params, grads):
if self.h == None:
self.h = {}
for key, val in params.items():
self.h[key] = np.zeros_like(val)
for key in params.keys():
self.h[key]0 += grads[key] * grads[key]
# 加上微小值防止0溢出
params[key] -= self.lr * grads / (np.sqrt(self.h[key]) + 1e-7)
2. 权重的初始值
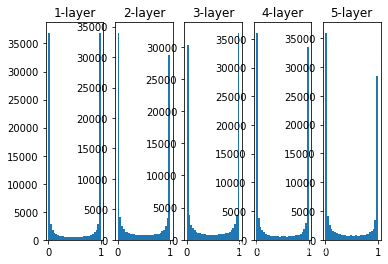
2.1 隐藏层的激活值实验
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(1000, 100) # 100 个数据
node_num = 100
hidden_layer_size = 5
activations = {}
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
z = np.dot(x, w)
a = sigmoid(z)
activations[i] = a
# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i + 1)
plt.title(str(i+1) + "-layer")
plt.hist(a.flatten(), 30, range=(0, 1))
plt.show()
# 权重标准差0.01
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(1000, 100) # 100 个数据
node_num = 100
hidden_layer_size = 5
activations = {}
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 0.01
z = np.dot(x, w)
a = sigmoid(z)
activations[i] = a
# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i + 1)
plt.title(str(i+1) + "-layer")
plt.hist(a.flatten(), 30, range=(0, 1))
plt.show()
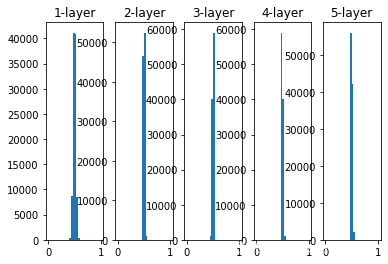
# 权重标准差0.01
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(1000, 100) # 100 个数据
node_num = 100
hidden_layer_size = 5
activations = {}
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) / np.sqrt(node_num)
z = np.dot(x, w)
a = sigmoid(z)
activations[i] = a
# 绘制直方图
for i, a in activations.items():
plt.subplot(1, len(activations), i + 1)
plt.title(str(i+1) + "-layer")
plt.hist(a.flatten(), 30, range=(0, 1))
plt.show()
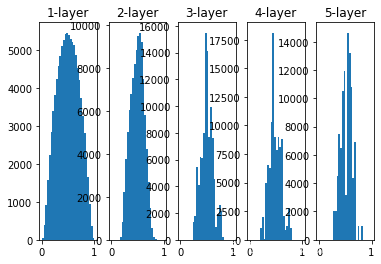
3. 模拟过拟合的实验
模型发生过拟合,主要有两个原因:
- 模型有着大量参数
- 训练数据较少
下面我们来故意满足这两个条件,以制造过拟合的现象
老样子,还是从dataset里面导入加载函数(用于加载Mnist数据集)
# coding: utf-8
import os
import sys
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from common.multi_layer_net import MultiLayerNet
from common.optimizer import SGD
# 读入数据
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label = True)
# 但是我们只取 300 个
x_train = x_train[:300]
t_train = t_train[:300]
network = MultiLayerNet(input_size = 784, hidden_size_list = [100, 100, 100,
100, 100, 100], output_size = 10)
optimizer = SGD(lr = 0.01) # 学习率为0.01的SGD更新参数
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(1000000000):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
grads = network.gradient(x_batch, t_batch)
optimizer.update(network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
# 3.绘制图形==========
markers = {'train': 'o', 'test': 's'}
x = np.arange(max_epochs)
plt.plot(x, train_acc_list, marker='o', label='train', markevery=10)
plt.plot(x, test_acc_list, marker='s', label='test', markevery=10)
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
4. 实现dropout层
class Dropout:
def __init__(self, dropout_ratio = 0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg = True):
if train_flg:
# *train_x.shape 与 train_x.shape[0] 的结果是一致的
self.mask = np.random.randn(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x *(1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask
训练的结果
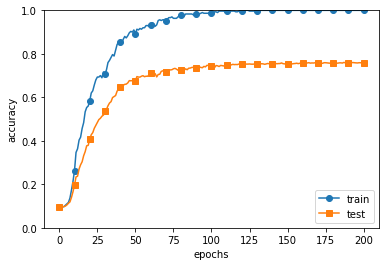
5. 超参数的验证
(x_train, t_train), (x_test, t_test) = load_mnist()
# 不能运行,运行的版本参考原书
# 打乱训练数据
x_train, t_train = shuffle_dataset(x_train, t_train)
# 分割验证数据
validation_rate = 0.20
validation_num = int(x_train.shape[0] * validation_rate)
x_val = x_train[:validation_num]
t_val = t_train[:validation_num]
x_train = x_train[validation_num:]
t_train = t_train[validation_num:]
写在最后
各位看官,都看到这里了,麻烦动动手指头给博主来个点赞8,您的支持作者最大的创作动力哟!
才疏学浅,若有纰漏,恳请斧正
本文章仅用于各位作为学习交流之用,不作任何商业用途,若涉及版权问题请速与作者联系,望悉知
文章出处登录后可见!
已经登录?立即刷新