声音克隆项目地址 https://github.com/babysor/MockingBird
介绍
Python 深度学习AI – 声音克隆、声音模仿,是一个三阶段的深度学习框架,允许从几秒钟的音频中创建语音的数字表示,并用它来调节文本到语音模型,该模型经过培训,可以概括到新的声音。
环境准备与安装
原始英文版地址:
https://github.com/CorentinJ/Real-Time-Voice-Cloning
中文二次开发版(本文使用该版本):
https://github.com/babysor/MockingBird
pycharm环境下载:
https://www.jetbrains.com/pycharm/download/#section=windows
conda虚拟环境:
https://www.anaconda.com/products/individual
FFmpeg :
https://github.com/BtbN/FFmpeg-Builds/releases
模型文件:
https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ 提取码 2021
在电脑系统上安装 FFmpeg 工具
下载完成后将其解压到一个目录后在系统的环境变量中添加该目录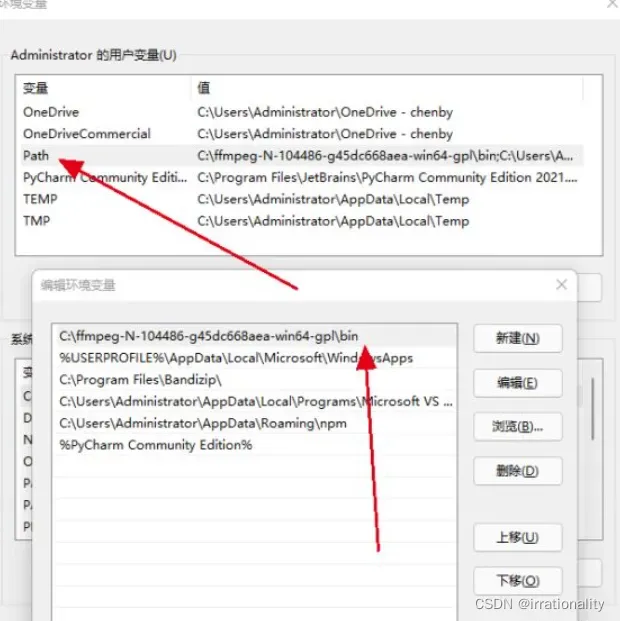
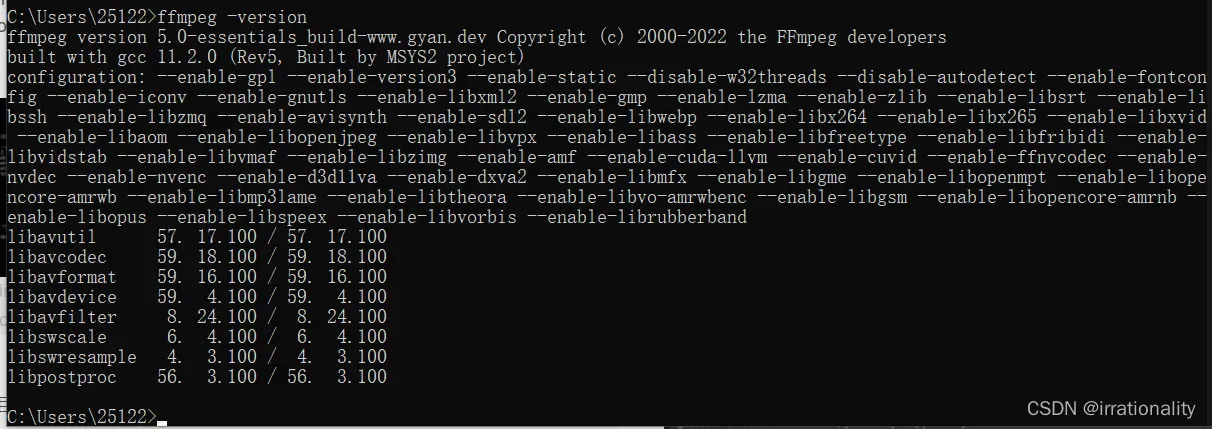
打开新的cmd中查看是否安装成功
ffmpeg -version
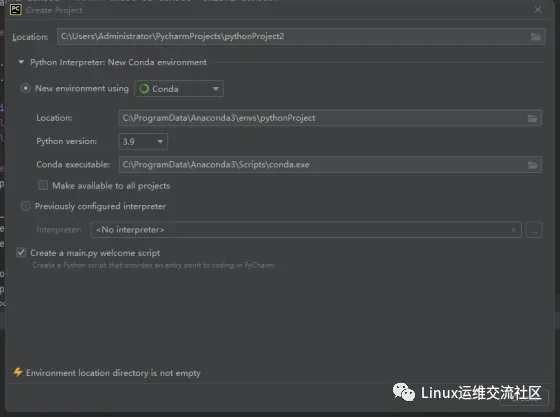
使用打开项目目录后,创建时使用conda的Python 3.9虚拟环境
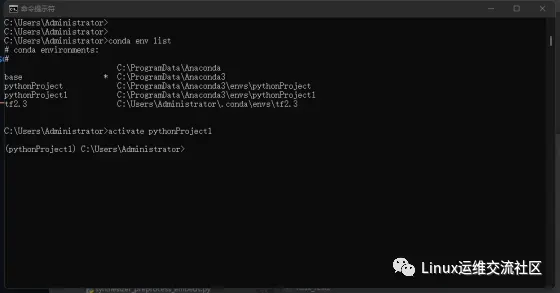
创建完成后,在cmd中查看现有的虚拟环境,并进入刚刚创建的虚拟环境
conda env list
activate pythonProject1
进入环境后在进行安装pip所需依赖,并使用国内源进行安装实现下载加速
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

在虚拟环境下安装pytorch
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
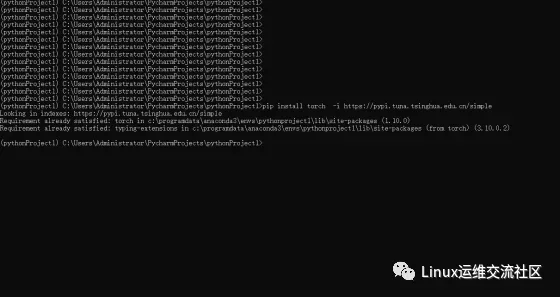
回到pycharm中,将模型导入到项目目录下,把目录复制黏贴到项目中
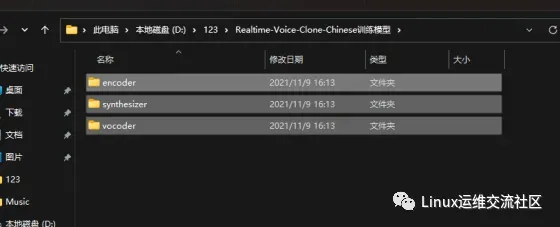
修改一行代码,在 synthesizer/utils/symbols.py 文件中
修改为:
_characters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz12340!'(),-.:;? '
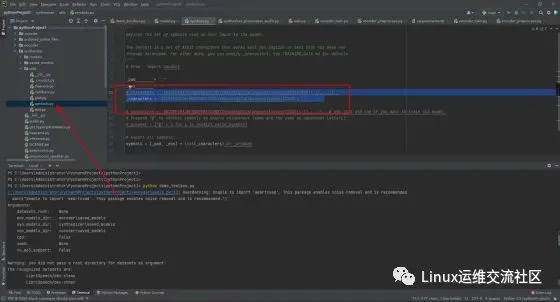
之后在terminal中启动工具箱
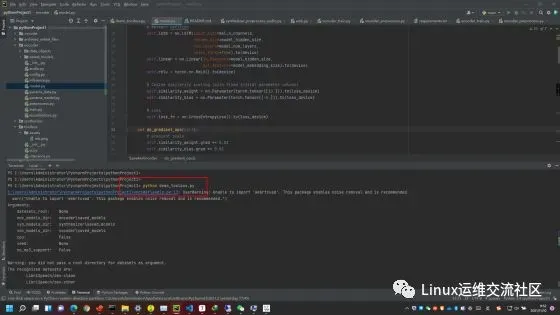
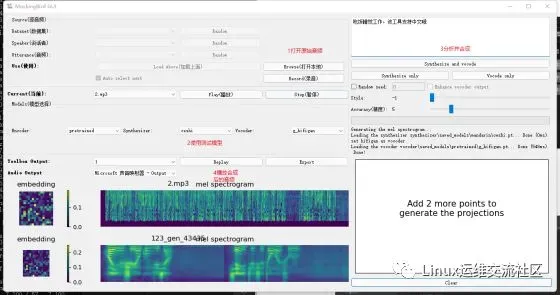
使用音频合成工具箱
https://blog.csdn.net/qq_33921750
https://my.oschina.net/u/3981543
https://www.zhihu.com/people/chen-bu-yun-2
https://segmentfault.com/u/hppyvyv6/articles
https://juejin.cn/user/3315782802482007
https://space.bilibili.com/352476552/article
https://cloud.tencent.com/developer/column/93230
知乎、CSDN、开源中国、思否、掘金、哔哩哔哩、腾讯云
本文使用 文章同步助手 同步
附录:
文本分类数据集https://github.com/fate233/toutiao-text-classfication-dataset
版权声明:本文为博主irrationality原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_54227557/article/details/122657161