在本文中,我们将介绍如何使用Python编写一个简单的数据抓取器,用于爬取东方财富网上的各类财务报表数据。我们将利用requests和lxml库进行数据请求和解析,并将抓取到的数据保存到CSV文件中。
1. 准备工作
首先,确保你已经安装了以下Python库:
pip install requests
pip install lxml
2. 创建数据抓取器
我们将创建一个名为DataScraper的类,用于封装所有数据抓取相关的方法。数据抓取器的主要功能包括:
- 获取报表数据
- 解析并提取表头信息
- 将数据写入CSV文件
2.1 初始化
在DataScraper类的__init__方法中,我们将初始化一些必要的属性,如报表类型、报表名称等。此外,我们还需要设置请求URL和请求头,以便稍后进行数据请求。
class DataScraper:
def __init__(self):
self.pagename_type = {
# ...
}
self.pagename_en = {
# ...
}
self.en_list = []
self.url = 'https://datacenter-web.eastmoney.com/api/data/v1/get'
self.headers = {
# ...
}
2.2 获取报表数据
我们定义一个名为get_table的方法,用于向东方财富网发送请求并获取报表数据。传入页数作为参数,返回当前页的报表数据。
def get_table(self, page):
# ...
2.3 解析表头
在抓取数据之前,我们需要解析表头信息。我们创建一个名为get_header的方法,传入一个包含所有英文表头的列表。该方法将请求报表页面,使用lxml库解析HTML,并提取中文表头信息。
def get_header(self, all_en_list):
# ...
2.4 写入表头
接下来,我们创建一个名为write_header的方法,用于将解析到的表头信息写入CSV文件。在该方法中,我们首先调用get_header方法获取表头信息,然后使用csv.writer将其写入CSV文件。
def write_header(self, table_data):
# ...
2.5 写入报表数据
定义一个名为write_table的方法,用于将抓取到的报表数据逐行写入CSV文件。在该方法中,我们遍历抓取到的数据,并将每一行数据写入CSV文件。
def write_table(self, table_data):
# ...
2.6 获取时间列表
为了让用户选择爬取的报表时间,我们定义一个名为get_timeList的方法。该方法将发送请求到东方财富网,解析并提取可选的时间列表。
def get_timeList(self):
# ...
3 使用数据抓取器
在创建好DataScraper类之后,我们可以使用以下代码来实例化它并爬取所需的报表数据:
if __name__ == '__main__':
scraper = DataScraper()
timeList = scraper.get_timeList()
for index, value in enumerate(timeList):
if (index + 1) % 5 == 0:
print(value)
else:
print(value, end=' ; ')
timePoint = str(input('\n请选择时间(可选项如上):'))
pagename = str(input('请输入报表类型(业绩报表;业绩快报;业绩预告;预约披露时间;资产负债表;利润表;现金流量表):'))
# 校验输入
assert timePoint in timeList, '时间输入错误'
assert pagename in list(scraper.pagename_type.keys()), '报表类型输入错误'
table_type = scraper.pagename_type[pagename]
filename = f'{pagename}_{timePoint}.csv'
# 写入表头
scraper.write_header(scraper.get_table(1))
# 循环遍历所有页数
page = 1
while True:
table = scraper.get_table(page)
if table:
scraper.write_table(table)
else:
break
page += 1
4 完整代码及结果截图
import csv
import json
import requests
from lxml import etree
class DataScraper:
def __init__(self):
self.pagename_type = {
"业绩报表": "RPT_LICO_FN_CPD",
"业绩快报": "RPT_FCI_PERFORMANCEE",
"业绩预告": "RPT_PUBLIC_OP_NEWPREDICT",
"预约披露时间": "RPT_PUBLIC_BS_APPOIN",
"资产负债表": "RPT_DMSK_FN_BALANCE",
"利润表": "RPT_DMSK_FN_INCOME",
"现金流量表": "RPT_DMSK_FN_CASHFLOW"
}
self.pagename_en = {
"业绩报表": "yjbb",
"业绩快报": "yjkb",
"业绩预告": "yjyg",
"预约披露时间": "yysj",
"资产负债表": "zcfz",
"利润表": "lrb",
"现金流量表": "xjll"
}
self.en_list = []
self.url = 'https://datacenter-web.eastmoney.com/api/data/v1/get'
self.headers = {
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'closed',
'Referer': 'https://data.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="111", "Not(A:Brand";v="8", "Chromium";v="111"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"'
}
def get_table(self, page):
params = {
'sortTypes': '-1,-1',
'reportName': self.table_type,
'columns': 'ALL',
'filter': f'(REPORT_DATE=\'{self.timePoint}\')'
}
if self.table_type in ['RPT_LICO_FN_CPD']:
params['filter'] = f'(REPORTDATE=\'{self.timePoint}\')'
params['pageNumber'] = str(page)
response = requests.get(url=self.url, params=params, headers=self.headers)
data = json.loads(response.text)
if data['result']:
return data['result']['data']
else:
return
def get_header(self, all_en_list):
ch_list = []
url = f'https://data.eastmoney.com/bbsj/{self.pagename_en[self.pagename]}.html'
response = requests.get(url)
res = etree.HTML(response.text)
for en in all_en_list:
ch = ''.join(
[i.strip() for i in res.xpath(f'//div[@class="dataview"]//table[1]//th[@data-field="{en}"]//text()')])
if ch:
ch_list.append(ch)
self.en_list.append(en)
return ch_list
def write_header(self, table_data):
with open(self.filename, 'w', encoding='utf-8', newline='') as f:
writer = csv.writer(f)
headers = self.get_header(list(table_data[0].keys()))
writer.writerow(headers)
def write_table(self, table_data):
with open(self.filename, 'a', encoding='utf-8', newline='') as csvfile:
writer = csv.writer(csvfile)
for item in table_data:
row = []
for key in item.keys():
if key in self.en_list:
row.append(str(item[key]))
print(row)
writer.writerow(row)
def get_timeList(self):
headers = {
'Referer': 'https://data.eastmoney.com/bbsj/202206.html',
}
response = requests.get('https://data.eastmoney.com/bbsj/202206.html', headers=headers)
res = etree.HTML(response.text)
return res.xpath('//*[@id="filter_date"]//option/text()')
def run(self):
self.timeList = self.get_timeList()
for index, value in enumerate(self.timeList):
if (index + 1) % 5 == 0:
print(value)
else:
print(value, end=' ; ')
self.timePoint = str(input('\n请选择时间(可选项如上):'))
self.pagename = str(
input('请输入报表类型(业绩报表;业绩快报;业绩预告;预约披露时间;资产负债表;利润表;现金流量表):'))
assert self.timePoint in self.timeList, '时间输入错误'
assert self.pagename in list(self.pagename_type.keys()), '报表类型输入错误'
self.table_type = self.pagename_type[self.pagename]
self.filename = f'{self.pagename}_{self.timePoint}.csv'
self.write_header(self.get_table(1))
page = 1
while True:
table = self.get_table(page)
if table:
self.write_table(table)
else:
break
page += 1
if __name__ == '__main__':
scraper = DataScraper()
scraper.run()
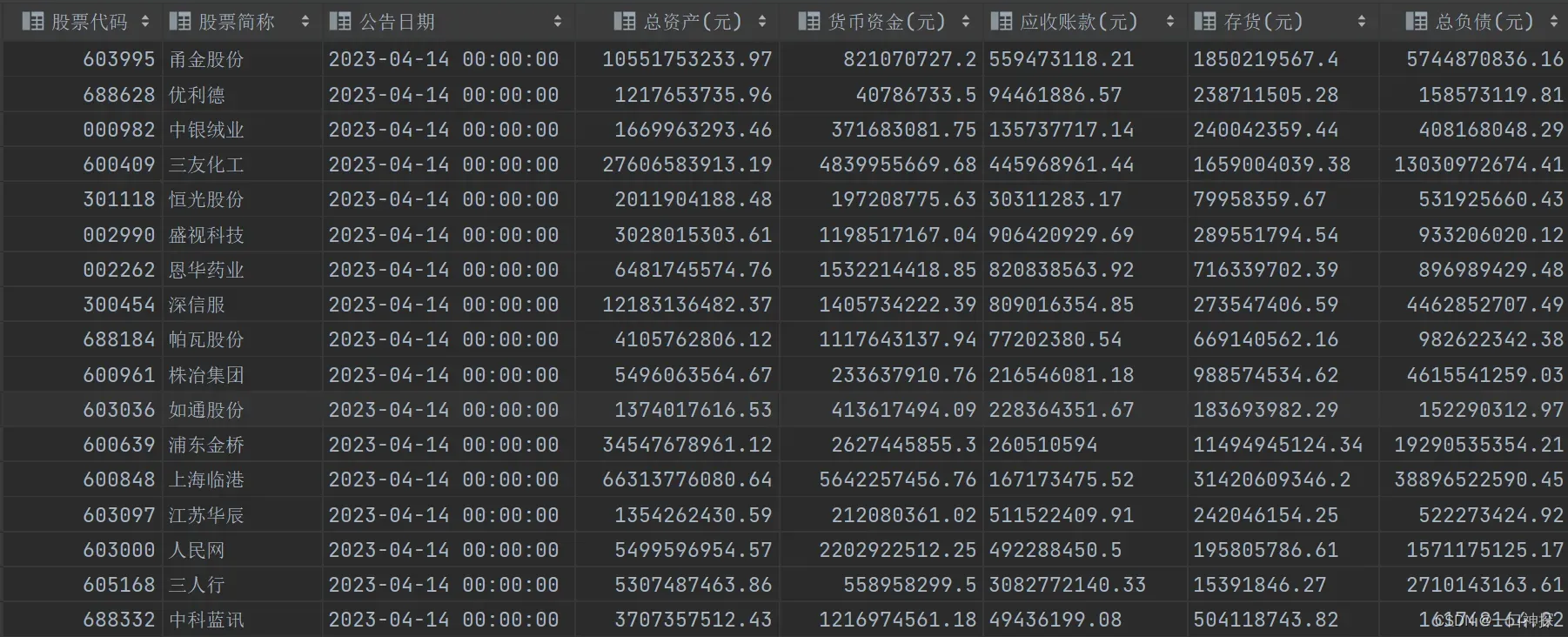
关于更多东方财富网、巨潮网、中国知网的爬虫,欢迎来参观我的github仓库
文章出处登录后可见!
已经登录?立即刷新