一、UNet代码链接
UNet代码:U-Net代码(多类别训练)-深度学习文档类资源-CSDN下载
二、开发环境
Windows、cuda :10.2 、cudnn:7.6.5 pytorch1.6.0 python 3.7
pytorch 以及对应的 torchvisiond 下载命令
# CUDA 10.2 conda安装
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.2 -c pytorch
# CUDA 10.2 pip 安装
pip install torch==1.6.0 torchvision==0.7.0
官网下载,较慢,可自己设置豆瓣源/清华源等下载
三、准备数据集
1、使用labelme软件标注数据,得到json文件
注意:图片格式为.jpg,位深为24位,否则无法标注。、
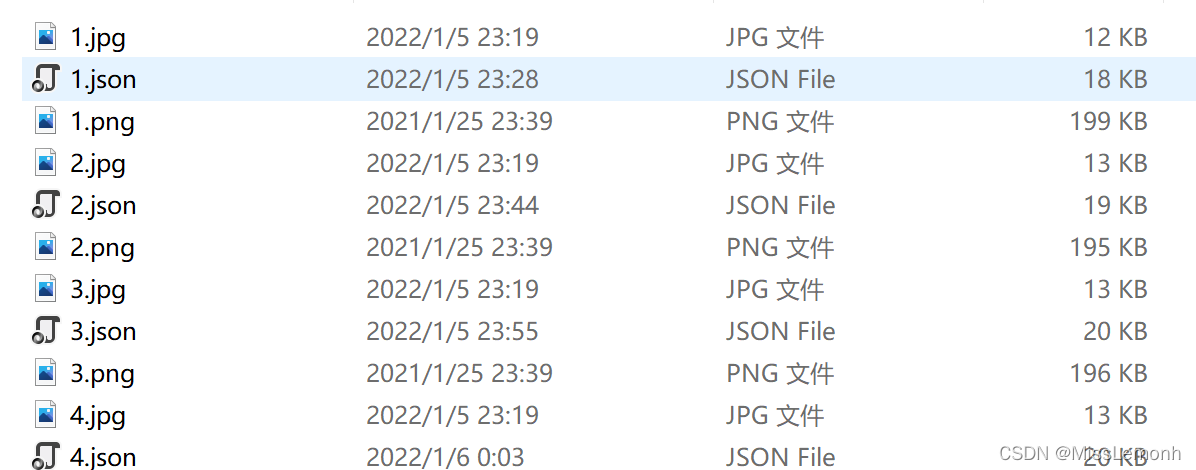
2、得到mask图以及png图(训练时只需要png图)
新建文件夹,命名为data_annotated,将上一步标注得到的json文件以及原始jpg图片放入文件夹,拷贝labeme2voc.py文件,文件内容如下,可复制直接用。
// labelme2voc.py
#!/usr/bin/env python
from __future__ import print_function
import argparse
import glob
import json
import os
import os.path as osp
import sys
import imgviz
import numpy as np
import PIL.Image
import labelme
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument('input_dir', help='input annotated directory')
parser.add_argument('output_dir', help='output dataset directory')
parser.add_argument('--labels', help='labels file', required=True)
parser.add_argument(
'--noviz', help='no visualization', action='store_true'
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print('Output directory already exists:', args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, 'JPEGImages'))
os.makedirs(osp.join(args.output_dir, 'SegmentationClass'))
os.makedirs(osp.join(args.output_dir, 'SegmentationClassPNG'))
if not args.noviz:
os.makedirs(
osp.join(args.output_dir, 'SegmentationClassVisualization')
)
print('Creating dataset:', args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == '__ignore__'
continue
elif class_id == 0:
assert class_name == '_background_'
class_names.append(class_name)
class_names = tuple(class_names)
print('class_names:', class_names)
out_class_names_file = osp.join(args.output_dir, 'class_names.txt')
with open(out_class_names_file, 'w') as f:
f.writelines('\n'.join(class_names))
print('Saved class_names:', out_class_names_file)
for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
print('Generating dataset from:', label_file)
with open(label_file) as f:
base = osp.splitext(osp.basename(label_file))[0]
out_img_file = osp.join(
args.output_dir, 'JPEGImages', base + '.jpg')
out_lbl_file = osp.join(
args.output_dir, 'SegmentationClass', base + '.npy')
out_png_file = osp.join(
args.output_dir, 'SegmentationClassPNG', base + '.png')
if not args.noviz:
out_viz_file = osp.join(
args.output_dir,
'SegmentationClassVisualization',
base + '.jpg',
)
data = json.load(f)
img_file = osp.join(osp.dirname(label_file), data['imagePath'])
img = np.asarray(PIL.Image.open(img_file))
PIL.Image.fromarray(img).save(out_img_file)
lbl = labelme.utils.shapes_to_label(
img_shape=img.shape,
shapes=data['shapes'],
label_name_to_value=class_name_to_id,
)
labelme.utils.lblsave(out_png_file, lbl)
np.save(out_lbl_file, lbl)
if not args.noviz:
viz = imgviz.label2rgb(
label=lbl,
img=imgviz.rgb2gray(img),
font_size=15,
label_names=class_names,
loc='rb',
)
imgviz.io.imsave(out_viz_file, viz)
if __name__ == '__main__':
main()
制作自己的标签数据集labels.txt,内容如下:
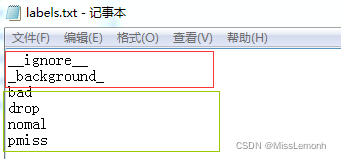
红色部分不用更改,绿色改为自己的标签名称。
将此三个文件放入一个文件夹中,最终结果如图。

在此文件夹中运行cmd,激活labelme环境。运行命令:python labelme2voc.py data_annotated data_dataset_voc –labels labels.txt,运行成功截图。
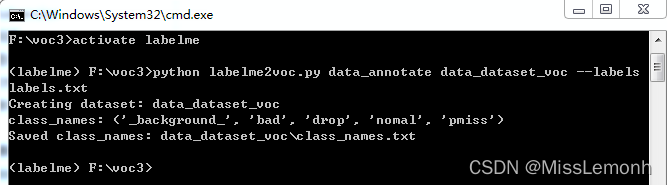
之后会生成一个data_dataset_voc的文件夹
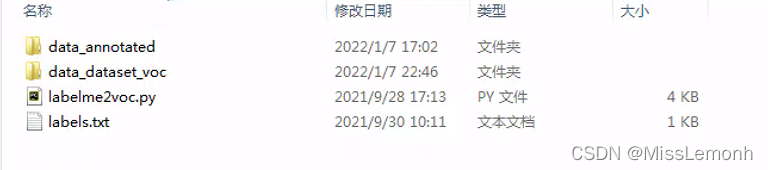
里面内容如下:
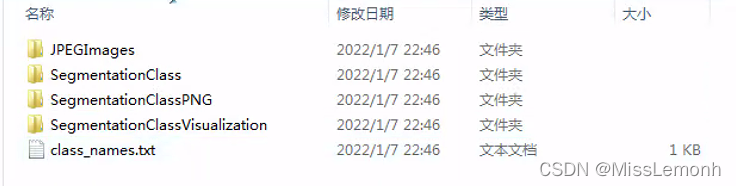
JPEGImages存放原图
SegmentationClass存放ground truth(mask)的二进制文件
SegmentationClassPNG存放原图对应的ground truth(mask)
SegmentationClassVisualization存放原图与ground truth融合后的图
3、创建数据集
新建三个文件夹并将三个文件夹置入一个文件夹内

其中ImageSets内容:

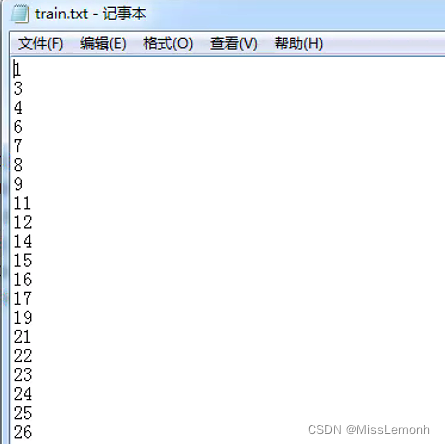
即,ImageSets中新建一个文件夹,命名为Segmentation,里面新建两个文件夹,分别为train.txt和val.txt,其中为训练集和验证集的图片名称(不带后缀)
JPEGImages:存放原题
SegmentationClass:存放第二部中生成的SegmentationClassPNG图
四、修改代码
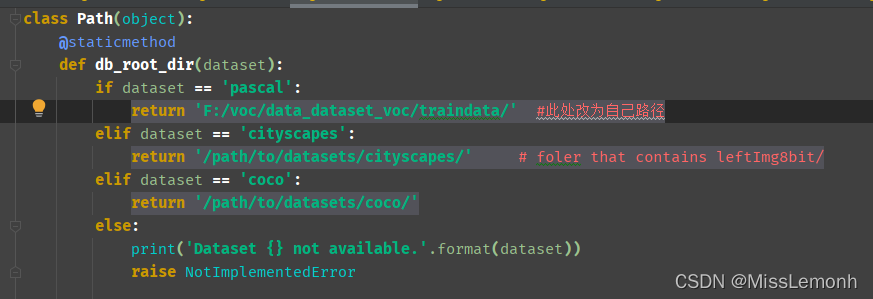
1、在mypath.py文件中修改数据集路径:
2. dataloaders/datasets/pascal.py修改
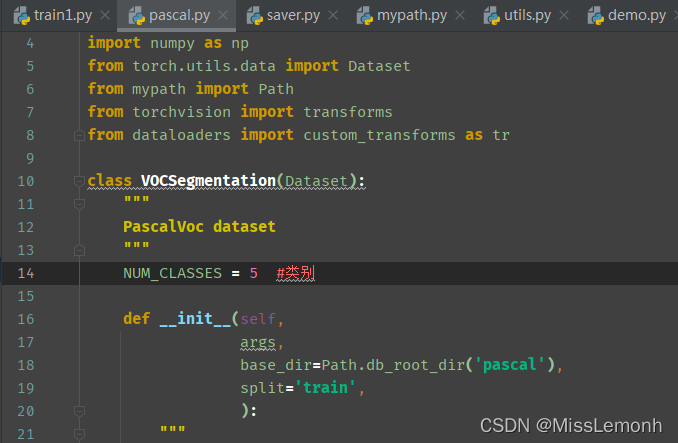 NUM_CLASSES修改为自己的类别数
NUM_CLASSES修改为自己的类别数
3、 dataloaders/utils.py修改

n_classes修改为自己类别数
4. train.py修改
// train.py
# Define network
model = Unet(n_channels=3, n_classes=5) # n_classes修改为自己的类别数
train_params = [{'params': model.parameters(), 'lr': args.lr}]
如果自己是单显卡
parser.add_argument('--gpu-ids', type=str, default='0',
help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')default设置为0就可以
--gpu-ids, default='0',表示指定显卡为默认显卡,若为多显卡可设置为default='0,1,2.......'
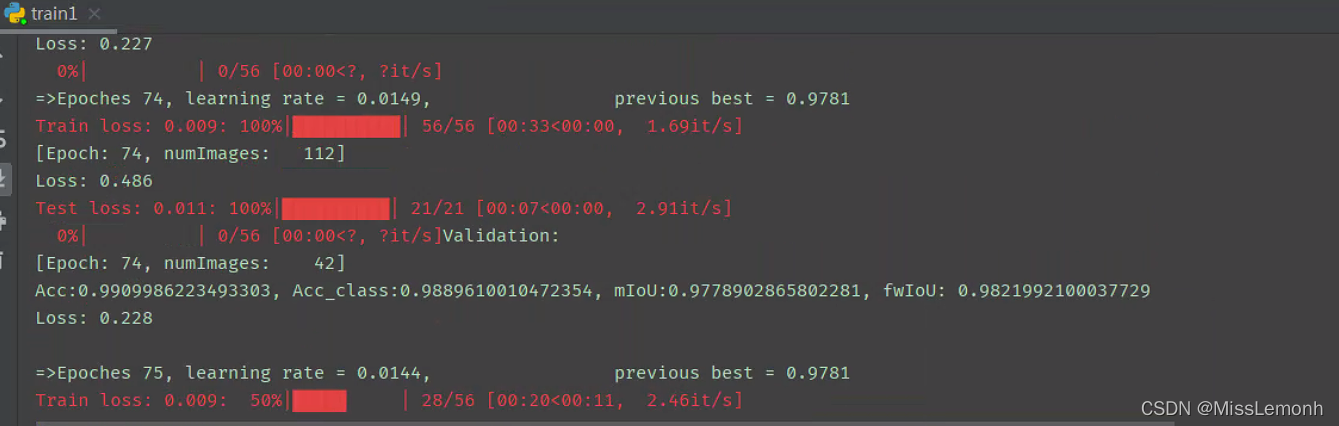
5、正常训练图
五、测试
1、修改测试代码
demo.py
// demo.py
import argparse
import os
import numpy as np
import time
import cv2
from modeling.unet import *
from dataloaders import custom_transforms as tr
from PIL import Image
from torchvision import transforms
from dataloaders.utils import *
from torchvision.utils import make_grid, save_image
def main():
parser = argparse.ArgumentParser(description="PyTorch Unet Test")
parser.add_argument('--in-path', type=str, required=True, help='image to test')
parser.add_argument('--ckpt', type=str, default='model_best.pth.tar', # 得到的最好的训练模型
help='saved model')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--gpu-ids', type=str, default='0', # 默认单GPU测试
help='use which gpu to train, must be a \
comma-separated list of integers only (default=0)')
parser.add_argument('--dataset', type=str, default='pascal',
choices=['pascal', 'coco', 'cityscapes','invoice'],
help='dataset name (default: pascal)')
parser.add_argument('--crop-size', type=int, default=512,
help='crop image size')
parser.add_argument('--num_classes', type=int, default=21, # 修改为自己的类别数
help='crop image size')
parser.add_argument('--sync-bn', type=bool, default=None,
help='whether to use sync bn (default: auto)')
parser.add_argument('--freeze-bn', type=bool, default=False,
help='whether to freeze bn parameters (default: False)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
if args.sync_bn is None:
if args.cuda and len(args.gpu_ids) > 1:
args.sync_bn = True
else:
args.sync_bn = False
model_s_time = time.time()
model = Unet(n_channels=3, n_classes=21)
ckpt = torch.load(args.ckpt, map_location='cpu')
model.load_state_dict(ckpt['state_dict'])
model = model.cuda()
model_u_time = time.time()
model_load_time = model_u_time-model_s_time
print("model load time is {}".format(model_load_time))
composed_transforms = transforms.Compose([
tr.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
tr.ToTensor()])
for name in os.listdir(args.in_path):
s_time = time.time()
image = Image.open(args.in_path+"/"+name).convert('RGB')
target = Image.open(args.in_path+"/"+name).convert('L')
sample = {'image': image, 'label': target}
tensor_in = composed_transforms(sample)['image'].unsqueeze(0)
model.eval()
if args.cuda:
tensor_in = tensor_in.cuda()
with torch.no_grad():
output = model(tensor_in)
grid_image = make_grid(decode_seg_map_sequence(torch.max(output[:3], 1)[1].detach().cpu().numpy()),
3, normalize=False, range=(0, 9))
save_image(grid_image,'E:/demo(测试图片保存的路径)'+"/"+"{}.png".format(name[0:-4])) #测试图片测试后结果保存在pred文件中
u_time = time.time()
img_time = u_time-s_time
print("image:{} time: {} ".format(name,img_time))
print("image save in in_path.")
if __name__ == "__main__":
main()
# python demo.py --in-path your_file --out-path your_dst_file
2、demo.py修改完成后,在pycharm中的Terminal下运行:
// Terminal
python demo.py --in-path E:/demo1(E:/demo1为测试结果图想要保存的位置)
3、测试成功的结果图
4、最终分割结果


参考链接:Pytorch下实现Unet对自己多类别数据集的语义分割_brf_UCAS的博客-CSDN博客_pytorch unet多类分割
文章出处登录后可见!