始于NLP
简单来讲,Prompt就是对原来的输入文本进行一定的处理,使得在不改变预训练模型参数的情况下,相应任务的性能变高。例如,原输入文本为:I received the offer from ETH. ,对于文本分类,我们将其修改为I received the offer form ETH, I’m so [MASK];[MASK]可以为一些表示情绪的词,比如happy,那么相对于原文,修改后的句子更容易被分为happy类。如果将其改为I received the offer from ETH. Chinese:[MASK],则对于翻译任务来讲,更容易取得正确的翻译效果。所谓的修改方式在大佬论文中提到的有(如下图):

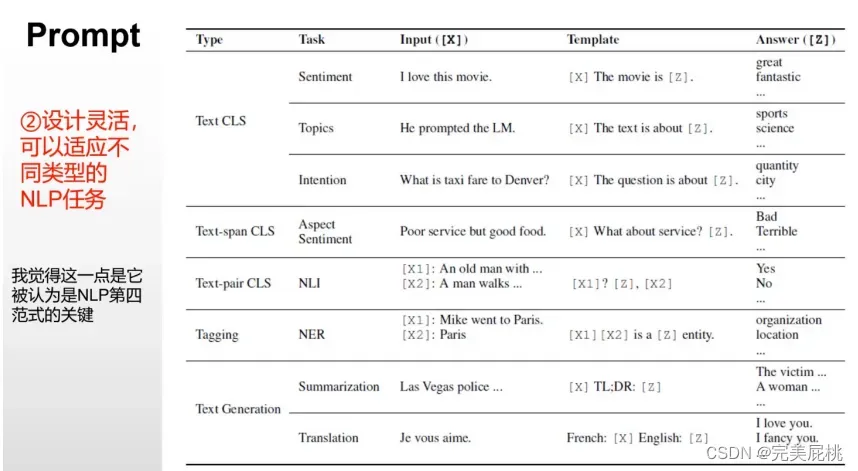
NLP中的Prompt算法步骤:
Prompt Addition: 这一步就是如何修改原文本。
Answer Search: 构建相应的answer空间,例如,文本分类,设置为(happy, good, terrible等)。
Answer Mapping: 在某些时候answer并不是我们最终想要的结果,比如我们最终想要的结果为positive和negative;那么则需要将happy,good映射为positive,将terrible映射为negative。
VPT(Visual prompt tuning)
一、论文信息
论文名称:Visual Prompt Tuning
作者团队:
 会议:ECCV2022
会议:ECCV2022
Github: https://github.com/kmnp/vpt
二、动机与创新
动机:
-
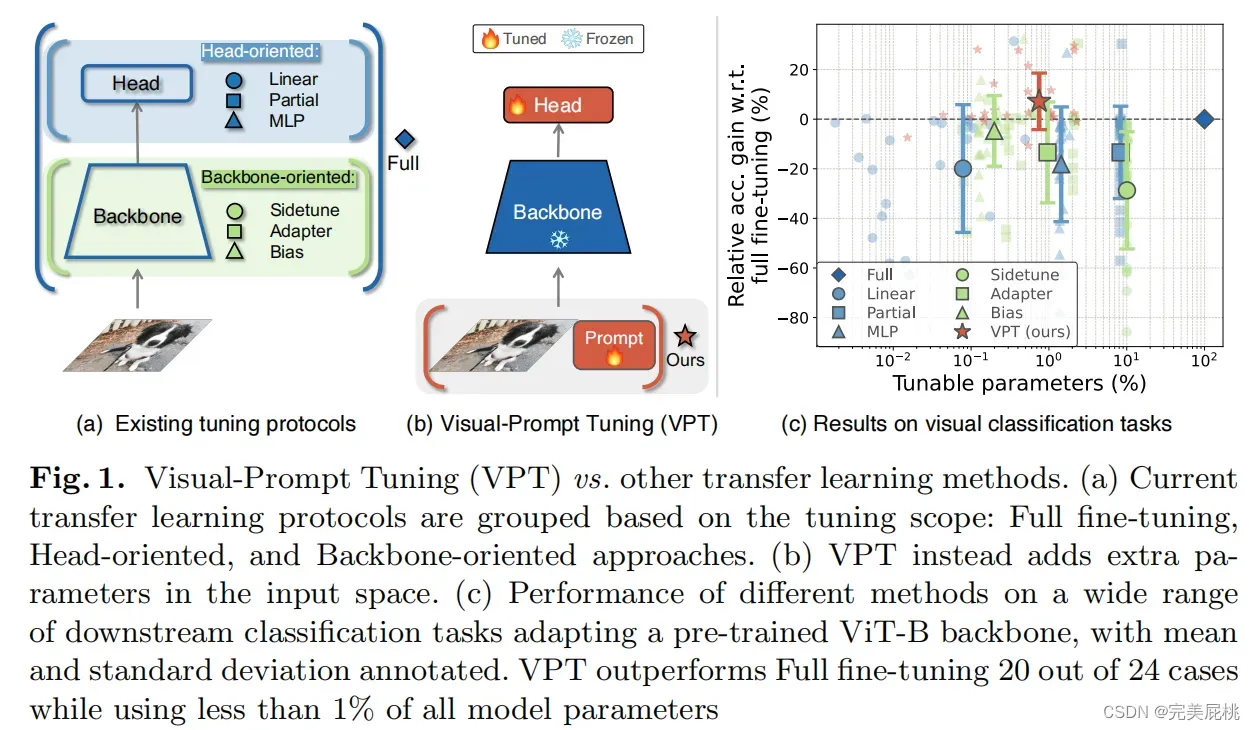
目前调整预训练模型的方法是full fine-tuning,即完全微调。预训练好的模型利用full fine-tuning的方式迁移到下游任务上时,需要存储整个模型,而且在会对模型的所有参数都进行训练,造成计算量大的问题;
-
随着计算机视觉领域的发展,基于Transformer的模型相较于基于CNN的模型更大,导致模型参数急剧上升,也致使训练难度的增大;
-
近年来,NLP已经进入大模型阶段,对于如何迁移NLP预训练好的大模型到下游任务,相关人员提出了不同于Fine-tuning的方法,即Prompt-tuning,在保持预训练模型冻结的情况下,只需要训练少量额外的参数即可将该大模型迁移到下游任务,而且效果不错。
-
如何更加有效地 adapt 预训练的Transformer用于下游任务?
创新:
-
这篇文章提出了一个简单、有效的方法调整预训练好的Transformer模型用于下游任务,即Visual-Prompt Tuning (VPT)。
 三、方法
三、方法
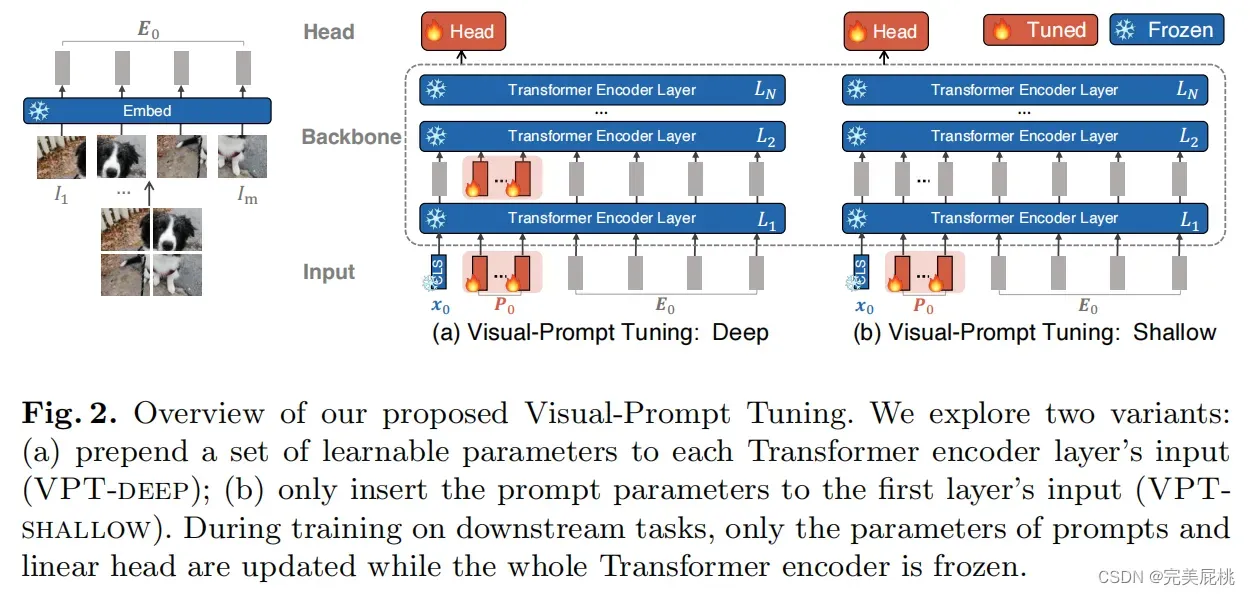
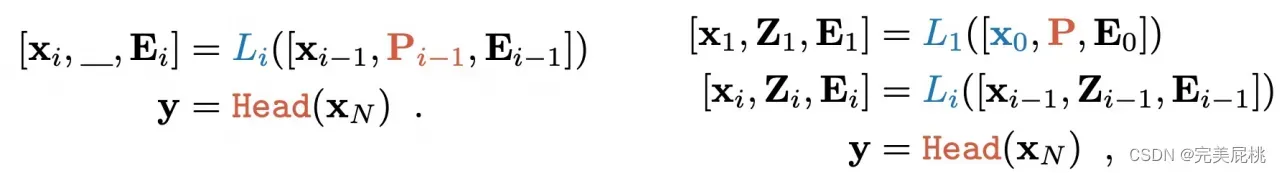
VPT-Deep变体为Transformer编码器每层的输入预先设置一组可学习的参数;
VPT-Shallow变体则仅将提示参数插入第一层的输入。
两者在下游任务的训练过程中,只有特定于任务的提示和线性头的参数会更新,而整个Transformer编码器被冻结。
四、实验结果 20/24
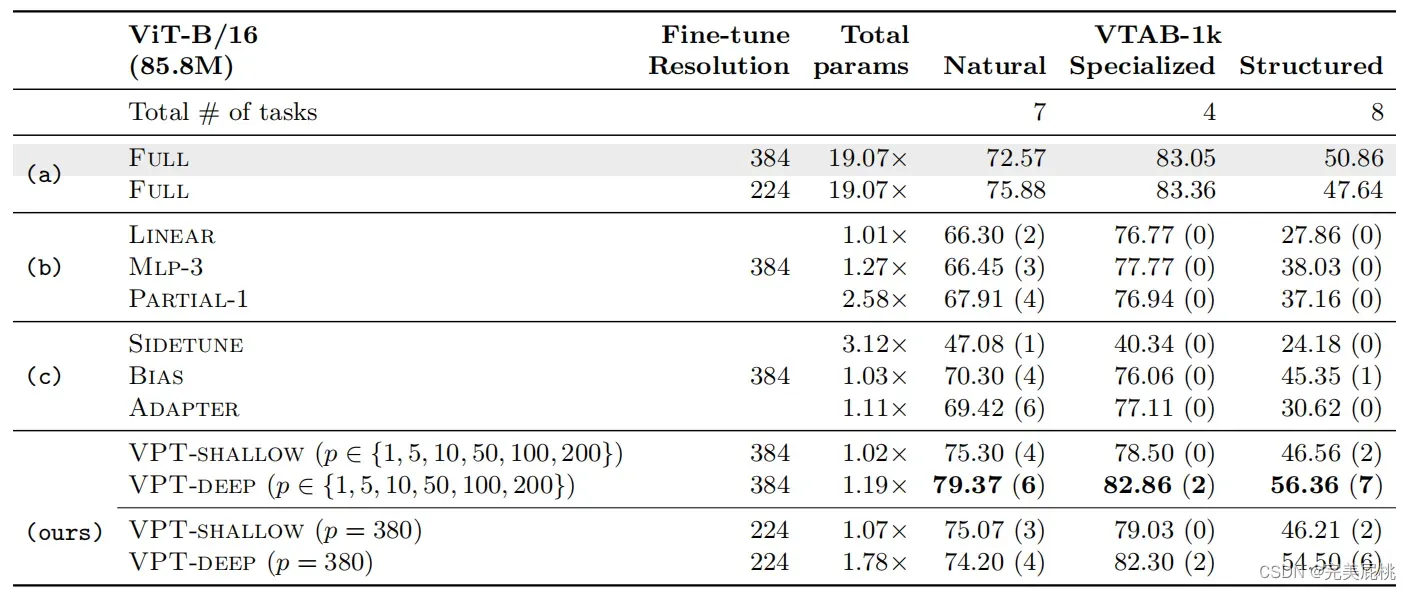
实验的数据集有两组,一共涉及24个跨不同领域的下游识别任务,包括:
(1)由5个基准细粒度视觉分类任务组成的FGVC;
(2)由19个不同视觉分类集合组成的VTAB-1k,细分为使用标准相机拍摄的自然图像任务(Natural)、用专用设备(如卫星图像)捕获的图像任务(Specialized)以及需要几何理解的任务(Structured),比如物体计数。测得每项任务上的平均准确度后,得出的主要结果如下:
VPT-Deep在24个任务中有20个的表现都优于全面微调,同时使用的总模型参数显著减少(1.18× vs. 24.02×);
在NLP领域中Prompt再厉害,性能也不会超过全面微调。这说明Prompt很适用于视觉Transformer模型。
Exploring Visual Prompts for Adapting Large-Scale Models
一、论文信息
论文名称:Exploring Visual Prompts for Adapting Large-Scale Models
作者团队:

Github: https://hjbahng.github.io/visual_prompting/
二、动机
正如随着attention机制和transformer在NLP成为主流,attention+CNN、Vit、Swin-transformer、ShiftVit等基于attention和transformer的CV模型不断涌出一样;在看到prompting在NLP变得越来越火时,作者自然问道:Why not visual prompting?为证明在CV领域,Prompt是可行的,并且在某些任务和数据集上效果不错。
三、方法
使用(迁移)预训练模型的方法:
在CV中,将一个预训练模型迁移到新任务上的方法主要包括Fine-tuning,Linear Probe,Visual Prompting ;三种方法的不同如下图所示:
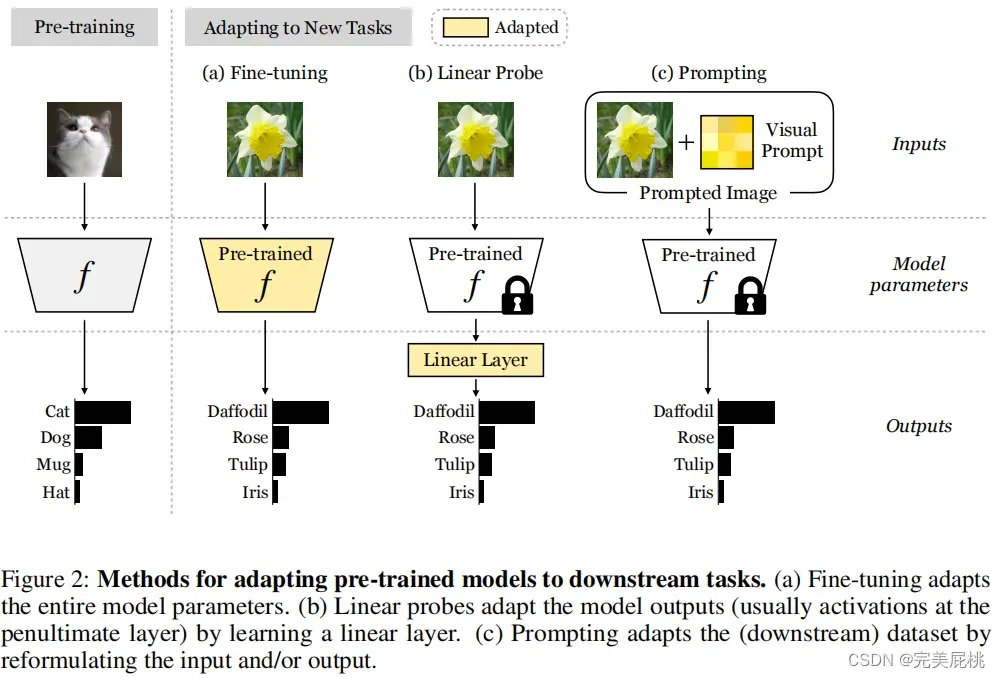 Fine-tuning会修改预训练模型参数,Linear Probe不会修改预训练模型参数,但是会在预训练模型后增加和任务相关的线性层,Visual Prompting则是不修改预训练模型参数,只修改原图像。
Fine-tuning会修改预训练模型参数,Linear Probe不会修改预训练模型参数,但是会在预训练模型后增加和任务相关的线性层,Visual Prompting则是不修改预训练模型参数,只修改原图像。
Prompt形式:
-
对于图片,给原图增加prompt,自然想到的是添加一些像素;其实以像素形式添加prompt的好处就是可以做到task-special和input-agnostic;也就是因为prompt中含有大量数据中学到的信息,所以是任务相关的;因为对于同一个任务,在测试时,直接使用得到的prompt就可以,不管你输入哪张图片,因此时输入无关的。
-
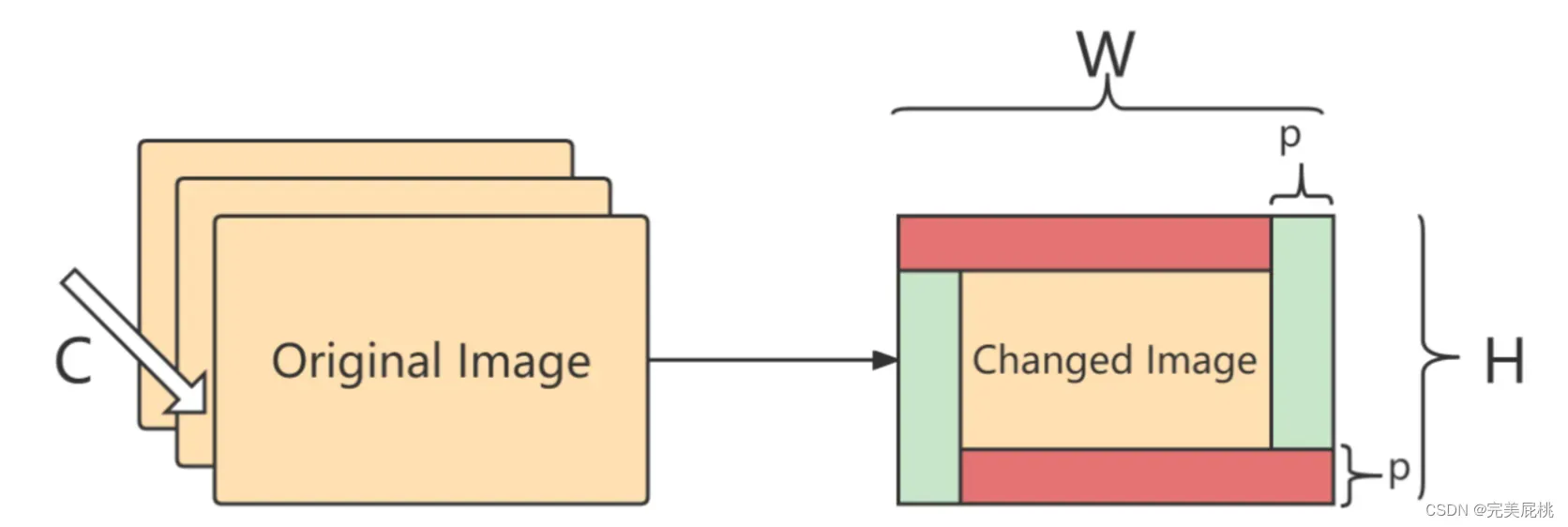
如何添加: 作者提到了三种方式:1)在随机位置添加像素块(pixel patch);2)在固定位置添加像素块(pixel patch);3)在图像内部边缘pad一些像素(类似卷积中的padding)第三种方式效果最好。
-
Padding: 使用pad方式添加,添加的宽度为p ;图像的尺寸为C,H,W;则一共需要添加 2*C*p*(H-p)+2*C*p*(W-p),如图:
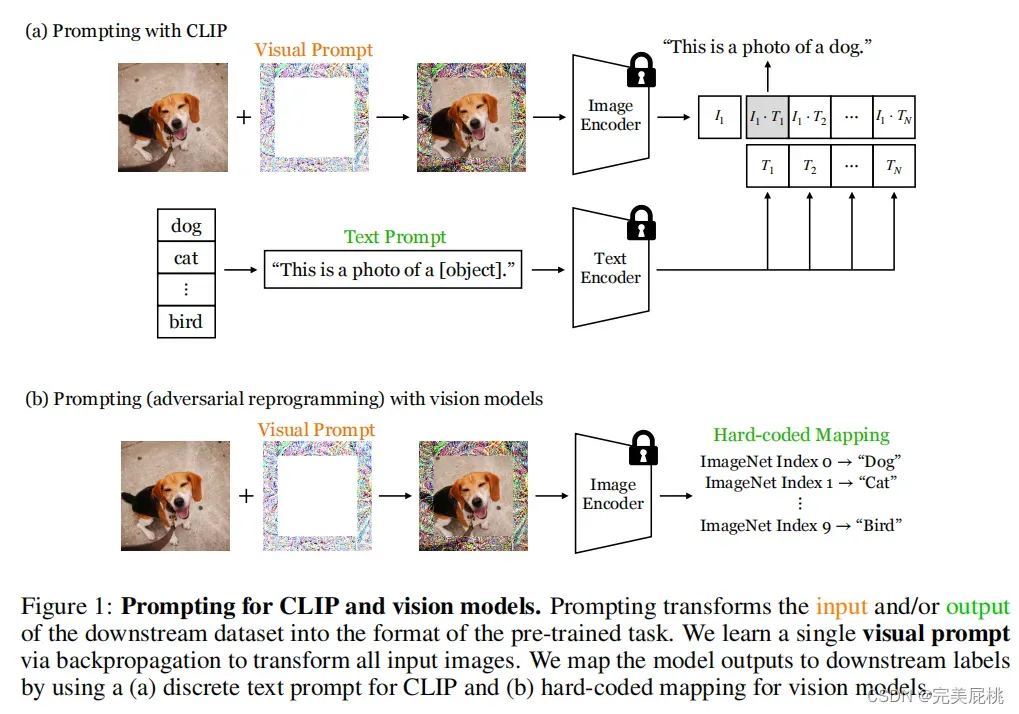
如何得来: 对于一个任务,需要通过训练得到于该任务相关的prompt,得到之后就可以直接应用了。
 四、实验结果
四、实验结果

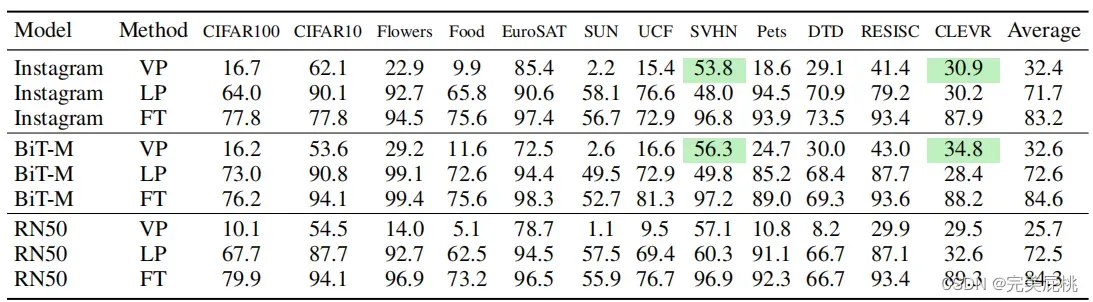
文章的目的不是达到state-of-the-art,只是为了证明visual prompting的有效性,实验效果不错。
文章出处登录后可见!