ResNet简单介绍
ResNet是15年提出的经典网络了。在ResNet提出之前,人们发现当模型层数提升到一定程度后,再增加层数就不再能提升模型效果了——这就导致深度学习网络看似出现了瓶颈,通过增加层数来提升效果的方式似乎已经到头了。ResNet解决了这一问题。
ResNet的核心思想就是引入了残差边。即一条直接从输入添加到输出的边。
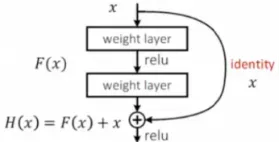
这样做有什么用处呢?可以这样理解:假如新加的这些层的学习效果非常差,那我们就可以通过一条残差边将这一部分直接“跳过”。实现这一目的很简单,将这些层的权重参数设置为0就行了。这样一来,不管网络中有多少层,效果好的层我们保留,效果不好的我们可以跳过。总之,添加的新网络层至少不会使效果比原来差,就可以较为稳定地通过加深层数来提高模型的效果了。
此外,使用残差边缘的另一个好处是可以避免梯度消失的问题。因为这个特性,它可以训练成百上千层的网络。
也很容易理解为什么残差网络可以避免梯度消失:
在没有残边的情况下,如果网络层数很深,为了更新底层(靠近输入数据部分)的网络权重,首先计算梯度。根据链式法则,需要向前相乘,只要 的任何一个因子太小,得到的梯度就会很小,而这个小梯度即使乘以很大的学习率也没用;
当我们有剩余边缘时,梯度可以直接通过“高速公路”传递到我们要请求梯度的对象。此时,无论通过链式法则取正态路径得到的梯度有多小,两条路径相加的结果如果不小,都可以非常高效地进行梯度更新。
由于残差网络的各种优势,残差边缘已经成为现在许多主流网络的标准,可见其影响深远。
ResNet一些具体要点
ResNet根据层数的不同分为很多种,比如下图中的每一列,也就分别对应着ResNet18,ResNet34,ResNet50等网络结构。其中ResNet152层数最多,也被普遍认为是效果最不错的(代价也是需要更多的计算量)。一般来说ResNet可以作为首选的网络去做分类任务,如果追求最高的精度就用ResNet152。
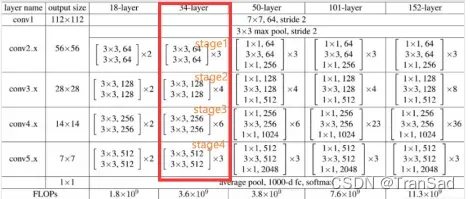
以ResNet34(上图中框起来的)来举例子解释一下它的结构,34其实就代表它有34层,它最上面首先有7*7的卷积层(算1层),再经过(3+4+6+3)=16个残差块,每个残差快有两层卷积(这里就有16*2=32层),在最后连上一个全连接层(最后1层),所以共34层。
残差块是长什么样子的呢?用残差边“包”起来的一部分就可以看作是个残差快。我在图中写了stage1到stage4(补充一下:一般图像的尺寸减半、通道数翻倍时我们就认为算一个stage,不过这些维度在上图中看不出来,上图中显示的都是卷积核的尺寸和通道数,不要搞混了),每个stage其实都用了不同的残差快,ResNet的重点也就在于残差块中的结构。
我们把ResNet34中间结构部分截取出来,从stage1开始往下,其具体结构如下图:
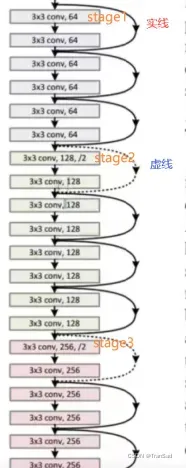
通过各个stage的标记位置可以对比两张图,我们对ResNet残差块具体是怎么连接的就清楚多了。可以发现除了正常的卷积之外,最显著的特点就在于每个残差块旁边都带了要么实线要么虚线的残差边。
就通过这些重复的残差块结构,我们通过控制层数以及残差块中卷积核尺寸和通道数,就得到了各个不同的ResNet了。到此,不管是ResNet几,其网络结构都可以按同样逻辑理解了。
等等,图中的实线和虚线残差边缘有什么区别?先说结论:
实线的残差边,就是直接相连到结果,也就是最简单最简单的一条线,对应identity_block;
虚线的残差边,其实中间要经过一个1*1的卷积来改变通道数,对应convolution_block。
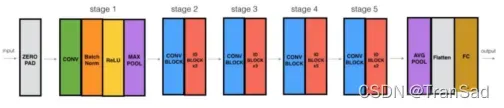
从stage2开始,每个stage都是先来一个convolution_block,再接若干个identity_block。(如下图是ResNet网络样式图。其中蓝色的是convolution_block,红色的是identity_block)
具体来看,为什么在stage的一开始需要一个convolution_block呢?上面说了一个convolution_block的残差边是一个1*1的卷积(如下图)。
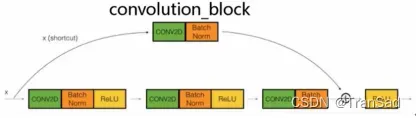
上篇文章整理过1*1卷积的作用,其中一个作用也是在这里的作用就是扩大通道数。为什么要扩大通道数呢?假如说这个convolution_block对应着下图这里的虚线位置:
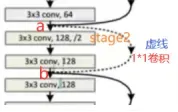
可以发现在a处本来是64个特征图的,经过了2次3*3、通道数为128的卷积核,到b通道数就变成了128;那么如果从a直接到b的这条残差边什么也不做的话,让64通道直接与128通道相加是不成立的。而如果64通道的特征图经过了一次1*1卷积,只要卷积核个数为128,就可以实现通道数翻倍从而合理相加了。这就是1*1卷积的作用,在这种通道数翻倍的地方也可以进行残差边的应用,而这整体就成为了convolution_block。
而identity_block就很简单啦(如下图)就是一条边,对应着所有实线部分。当输入输出的尺寸、通道数前后都没有变化时,输入就可以直接加到输出上。
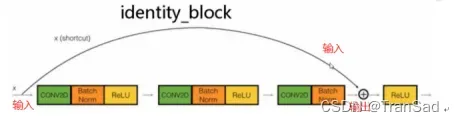
总之,在整个ResNet网络结构中,从输入到输出,就不断进行着特征图尺寸缩小以及特征图数量增加的过程。当特征图数量增加时,残差边就不得不进行1*1的卷积来同样扩大通道数,从而可以与正常卷积而得到的操作结果的尺寸保持一致。
和NiN网络类似,ResNet最后也使用了全局平均池化,但此时我们不再限制通道数直接等于结果数从而直接经过一个全局平均池化就可以得到结果维数——而是再加上一个全连接层来得到结果。(最后卷积层结果有几个通道数,比如512,输入神经元个数就是512;结果有几维,比如10,输出层神经元个数就是10)
简要总结:
这篇文章整理了一下ResNet网络的基本思想和大致结构,提到了一些优势作用,也区分了一下convolution_block和identity_block的不同之处等。
最后,在ResNet中很多地方都使用了Batch Normal来进行标准化,这个在上面各个过程中一直有意的忽略掉了,Batch Normal主要是用来解决梯度消失和梯度爆炸问题的,可以暂时就当成是一个不会改变尺寸和通道数的处理方式。关于BN展开有点多,以后再作补充。
版权声明:本文为博主TranSad原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_44492824/article/details/123189456