目录
AAAI 2021最佳论文:比Transformer更有效的长时间序列预测
Background
通用文段:
Sequence prediction is a problem that involves using historical sequence information to predict the next value or values in the sequence.It is a basic but important research problem.
问题背景:
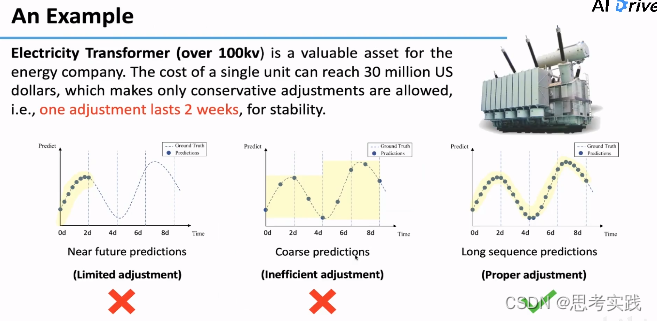
国家电网中存在很多的大型电力变压器,这些变压器用于对各个地区电压的调配,均超过100kV,单台的机组造价可达几个亿,是我们国家非常宝贵的资产,在进行电力调配的过程中,运行一些保守的调整,通常一次调整能够运行两周甚至数周,然后通过这种较长时间的间隙调整可以保持电网的稳定,然而这带来一个问题,需要对未来较长一段时间的变压器负载有一个大体的估计,在此基础之上才能设定一个调整的范围。对于未来值预测这个问题,目前有一些解决方案,组要分为两种,如下三张图所示:(凸显工作的优势)
第一种是对未来较近的一些值的预测,这种方法无法提供一种较长期的预测, 这对变压器的调整有时间上的限制,我们不能根据这样的模型给出的结果做一个足够鲁棒的调整,然后进而很难用这个调整保证在接下两周的时间内变压器能够稳定运行。
第二种方法被称为粗粒度预测,这种方法可以对未来一长段时间进行大体趋势上的预测,然而精度不足以支撑实际的应用。只能用来判断未来大体的趋势如何,不足以满足变压器的精细化调整。
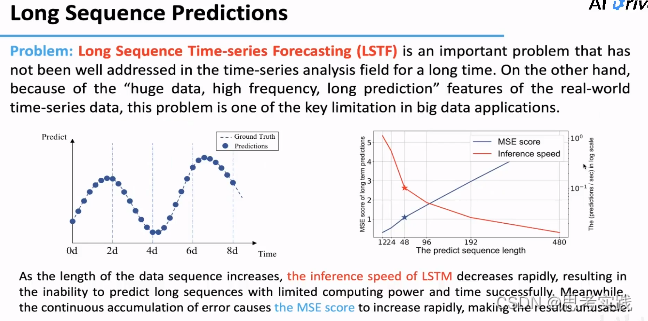
所以我们需要研究一种较为精细化的且能长时间输出的预测方法,也就是长序列预测问题。这是一个长时间未解决但很重要的问题。

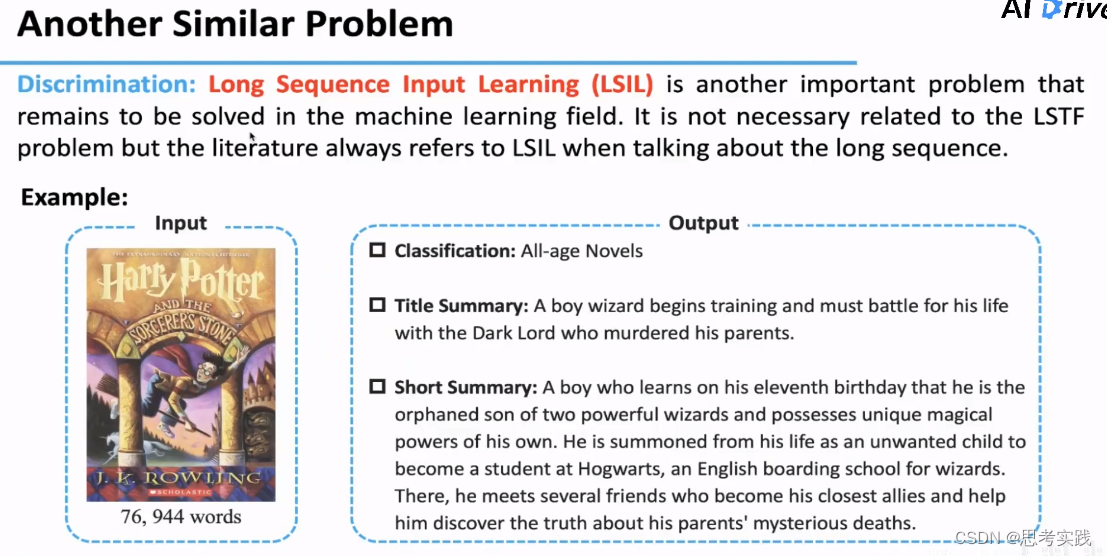
Informer的目标是解决长序列持续预测问题,这个问题与之前LSIL(长序列输入表征)问题很相似, Informer一切的工作都是围绕着长序列的Output来做的,在此基础之上不仅要完成对Long Sequence Input的表征,更重要的是我们要建立一个连接between Long sequence-output and Long sequence-input(映射关系,或者说注意力之类的),
Why attention
我们为什么要用Attention这种机制来解决长序列预测问题呢?

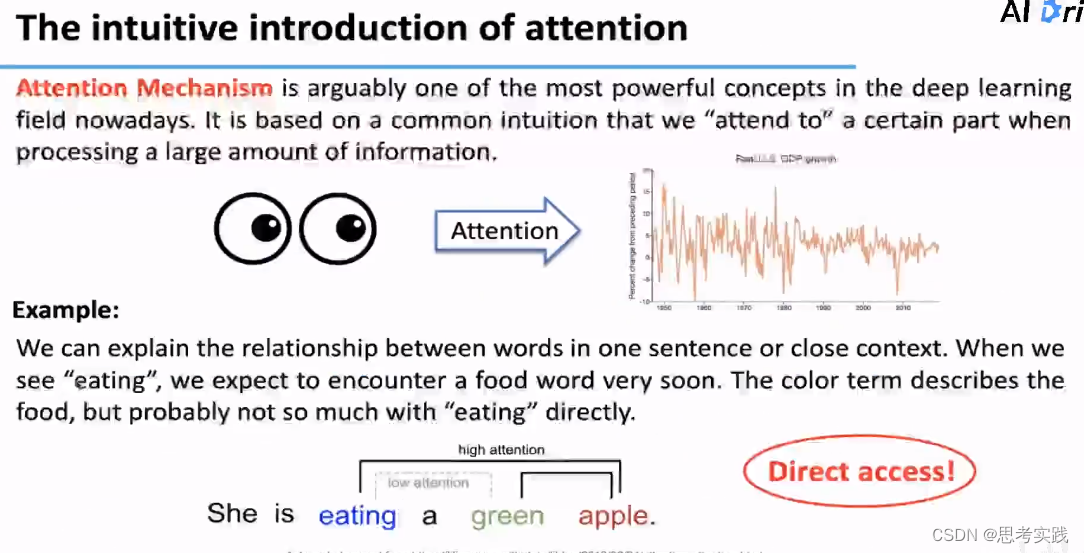
我们在处理大量的信息时,不会去关注全局的每一个信息,而会更加关注其中的某一部分。
比如Eating可以直接到达apple,这个Direct access特性就是Informer想用Attention机制来做长序列预测的一个最主要的原因。
Self-attention mechanism已经在NLP/CV领域取得了很好的成果,Transformer正是使用了大量的Self-attention 来捕获序列文本里面的依赖信息,然后在机器翻译、文本摘要、生成等任务上都取得了非常好的效果。
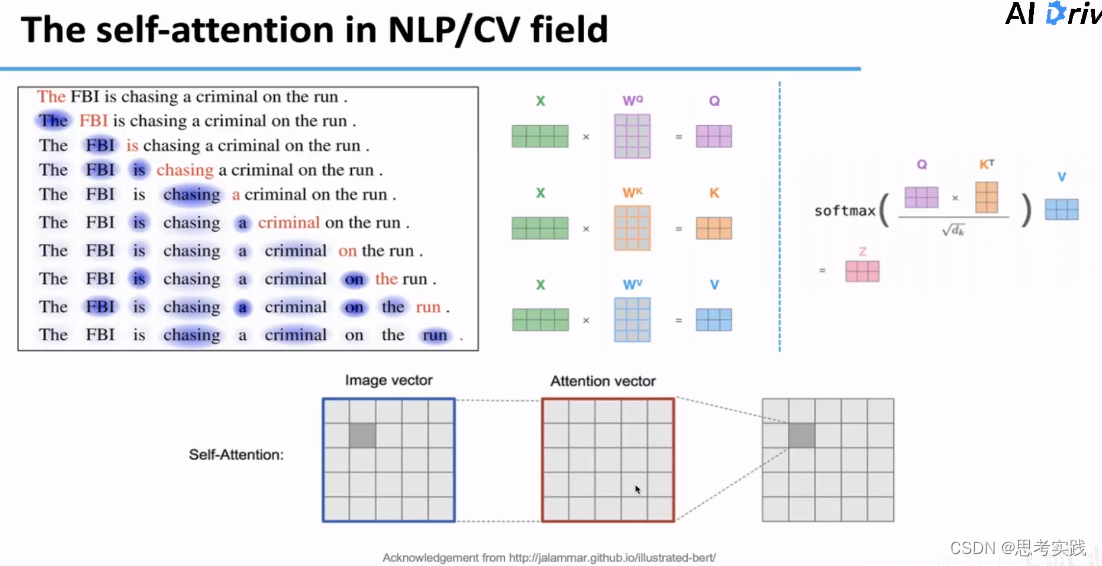
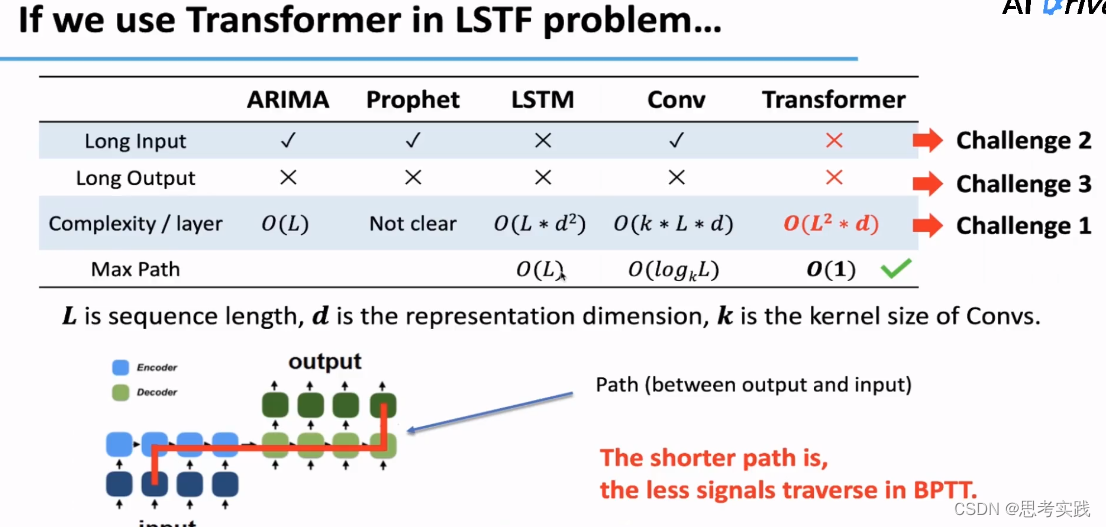
既然Transformer对于文本这种特别特殊的序列都有不错的效果,考虑把它用到长序列预测可不可以呢,与其他模型横向对比可以看到Transformer最大的优势就是序列中点与点最大路径的长度是O(1)的, 这个路径可以理解为输入输出需要经历多少个求导单元,我们一般认为通过的路径越短,有效的梯度信息才会保留的越多,才会传递的越准确,那是不是Transformer就可以直接用于解决长时序预测问题了呢?答案是不能的,原生Trans依然存在问题的,如下:
- 首先不能支持长序列的Input
- 也不能支持长序列的Output
因为其计算attention的时候,会计算decoder输出的每一个点和与Encoder的hidden state其他所有点的注意力,所以每一层的计算复杂度都是,时序数据的dimension暂且认为是1
对Transformer不熟悉的同学可以看看这篇博客的PPT,很清晰:
Transformer论文粗读[Neurips 2017]最佳论文_思考实践的博客-CSDN博客_transformer 论文
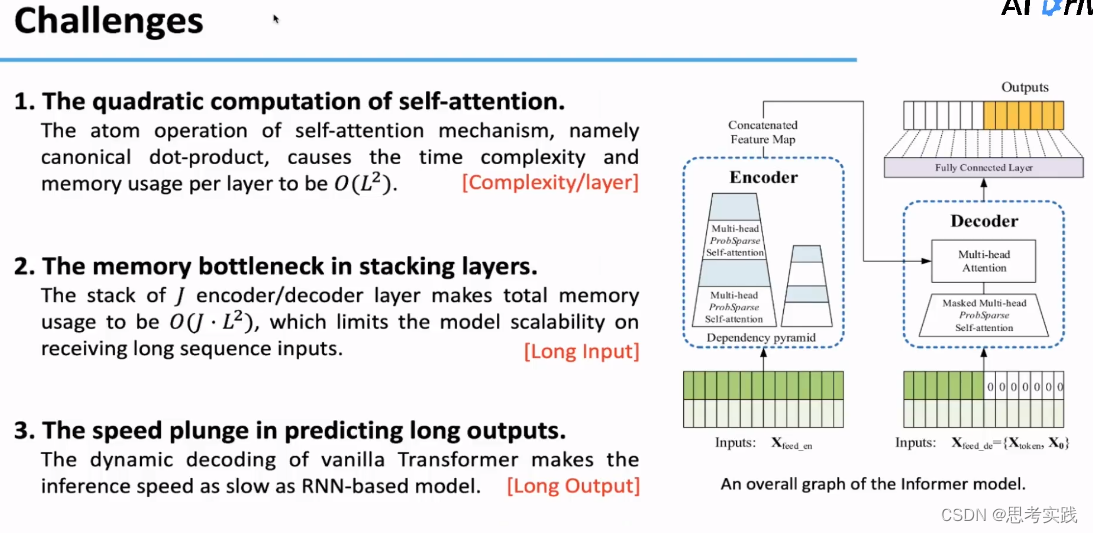
Methods:the details of Informer

首先分析一下这三个问题形成的原因(论文要解决)
- self-attention这个原子操作(就是Transformer的核心基本操作的意思),它这个传统点积操作使得每一层的时间复杂度和内存使用率都达到了
- 对于长序列Input的问题来说,最主要的原因就是encoder/decoder layer的堆叠导致内存的开销出现瓶颈,如果堆叠J-layer,我们就会得到
的内存占用量,这个特性很大程度上限制了模型长序列的接收和处理,(比如我一批长序列可以打成几份丢进不同层的encoder/decoder,最后输出拼接起来)
- 对于长序列Output的问题来说,预测长序列Output的速度会迅速下降,因为原生Trans的Decoder在Inference的过程中是动态输出的(也就是上一次的输出作为下一次的输入再预测),这不能满足于实际生产环境中对长序列的Output速度需求
Solve_Challenge_1:最基本的一个思路就是降低Attention的计算量,仅计算一些非常重要的或者说有代表性的Attention即可,一些相近的思路在近期不断的提出,比如Sparse-Attention,这个方法涉及了稀疏化Attention的操作,来减少Attention计算量,然后涉及的呈log分部的稀疏化方法, LogSparse-Attention 更大程度上减小Attention计算量,再比如说Restart+LogSparse(在LogSparse基础上在一个位置重新Restart一下,这个相比LogSparse可能增加一些计算量)
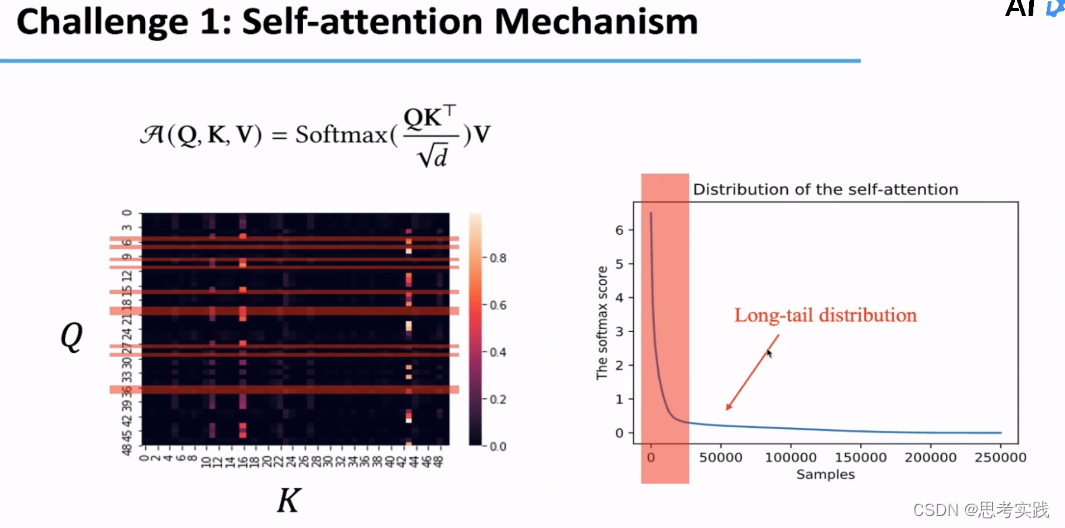
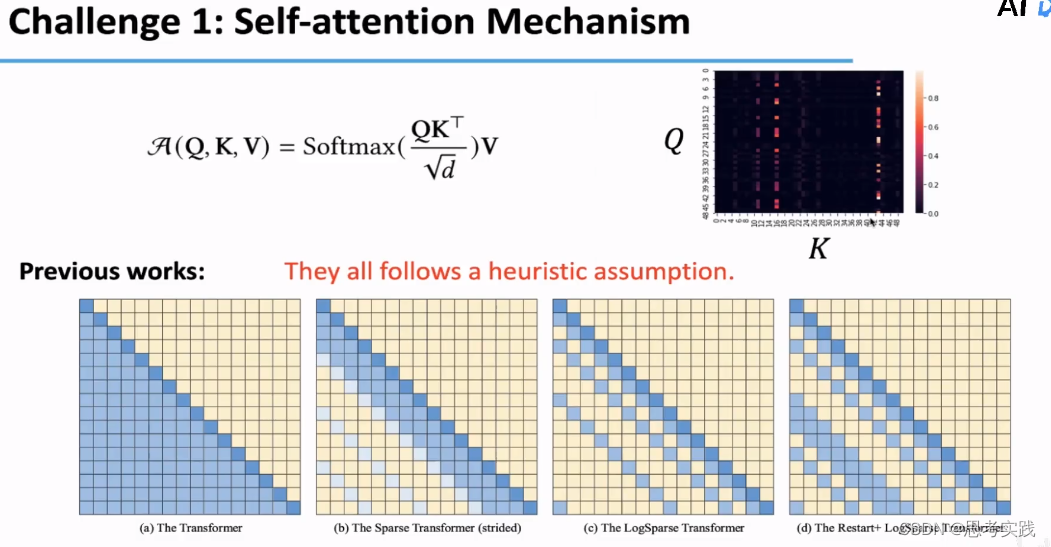 启发式假设也就是说我计算那些attention是用规则决定的,这种方法的缺点就是不能自适应的,根据具体的情况去计算那些attention,经过研究发现attention_map的高激活值,在很多情况下都是较为稀疏的,如果我们把query,key,score,这些pairs排一个序,然后画出一个统计图来(右图所示),然后我们会发现它是服从一个Long-Tail分布的,也就是说大部分的attention仅仅起了一个很微弱的作用。
启发式假设也就是说我计算那些attention是用规则决定的,这种方法的缺点就是不能自适应的,根据具体的情况去计算那些attention,经过研究发现attention_map的高激活值,在很多情况下都是较为稀疏的,如果我们把query,key,score,这些pairs排一个序,然后画出一个统计图来(右图所示),然后我们会发现它是服从一个Long-Tail分布的,也就是说大部分的attention仅仅起了一个很微弱的作用。
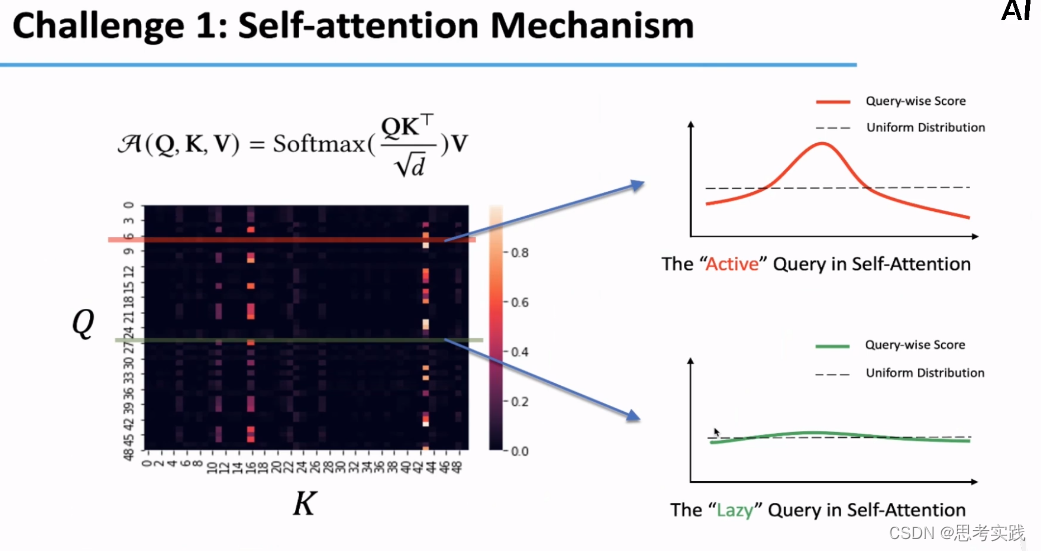
同时通过对attention_map随机抽取一些Query-wise Score(按行抽取),我们抽象出比较典型的attention score的两种代表,一个是"Active",一个是"Lazy",Active Query 特征是有一个或者多个较大的峰值,而其他的atten_score较小,然后另一种是Lazy Query整个统计曲线没有过大的起伏与均匀分布相差不大,我们称之为Lazy Query,然后希望根据这种发现重新定义一种计算和选取attention的方法,目的是尽量保证不遗漏重要的attention,又能尽量的较小计算量,降低开销
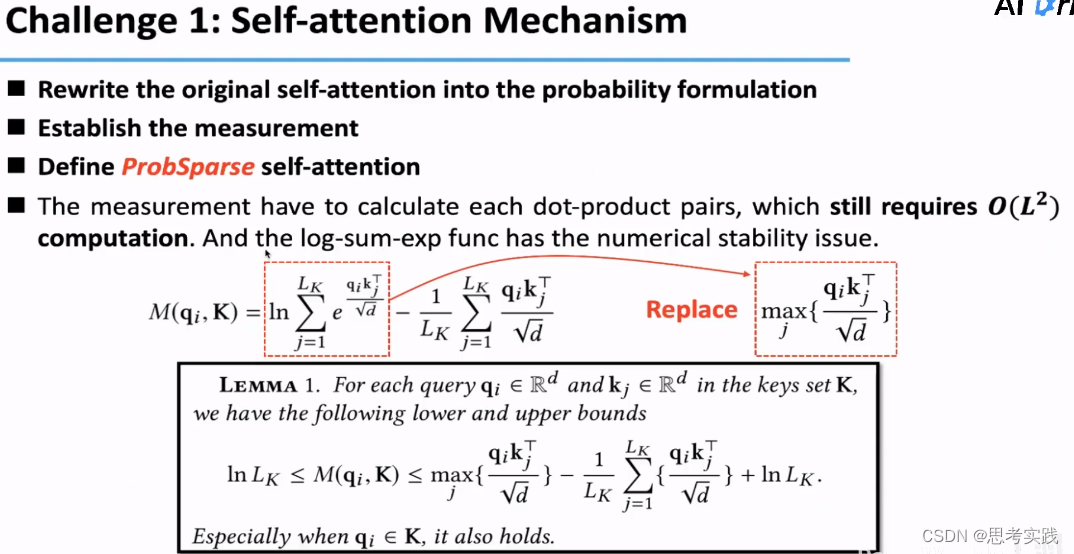
我们从Q里面把qi拿出来,把Self-Attention写成一个概率形式,原生Self-attention呈现Long-Tail分布的,具有稀疏性,也就是说连接对主要的注意力有贡献,其他的连接可能可以忽略,用来评估第i个query稀疏性的方法是利用了KL散度,q是一个均匀分布的概率,p是我们的Attention probability,经过这个KL散度就可以计算它们俩之间的一个相对熵,丢弃常数项,得到我们的i-th query's sparsity measurement formula.

散度用于衡量分布之间的距离,与uniform分布距离越大说明越可能有单峰,基于这个稀疏衡量方式定义了这个ProbSparse self-attention的形式,如下图所示,其中Q-bar是与q有相同尺寸的稀疏矩阵,Q-bar里面只包含了top-u个query(根据M(qi,K)计算出来的),这top-u个query定义为"Active query" ,

这里u的选取是通过一个采样参数c来确定的,代码的默认参数中U使25,论文这里也没解释清楚啦其实,作者解释到用LogL个也能表征,就不计算L个了,又和论文描述的不搭(这可是AAAI-best paper⊙o⊙ ),这个解释确实牵强,作者说后面会上线一个具体证明过程(填个坑先O(∩_∩)O)

其实当时看论文的时候给的逻辑就是用这个公式你去计算得到top-u前提是需要计算全部情况的attention去与这个uniform distribution做KL散度才能拿到一个基于散度结果的排序去做top-u,但这样一来时间复杂度还是,然后这里还有LSE(log-sum-exp)潜在的数值稳定性问题,


至此chanllenge2
Solve_Challenge_2:长序列的input表征//Self-attention Distilling Operation,feature map的尺寸可以在时间维度上面得到一个缩减(L*L到L/2*L/2),这里减半的处理方法就是直接用96个时间点的后48个得到一半,distilling的公式如图所示,从第j层套一个con1D,激活完后套一个MaxPooling层,就得到了th_j+1层的feature map,同时为了增强distilling 操作的鲁棒性,构建了几个并列的副本(replicas),最上边那个输入是主序列长度为L,第一个replica是主序列长度减半得到L/2,第二个replica是第一个replica再减半的到长度为L/4,通过这种方式得到了若干个长度为L/4的feature map,然后最后将其拼接起来作为Encoder的最终的Output,因为第二个challenge就是long sequence input解决不了会造成很大的内存开销,通过这种方法逐级减小feature map大小使得feature map在空间上并不会构成一个特别占内存的这样一个局限,这里再配合链接2的Encoder讲解解释一下
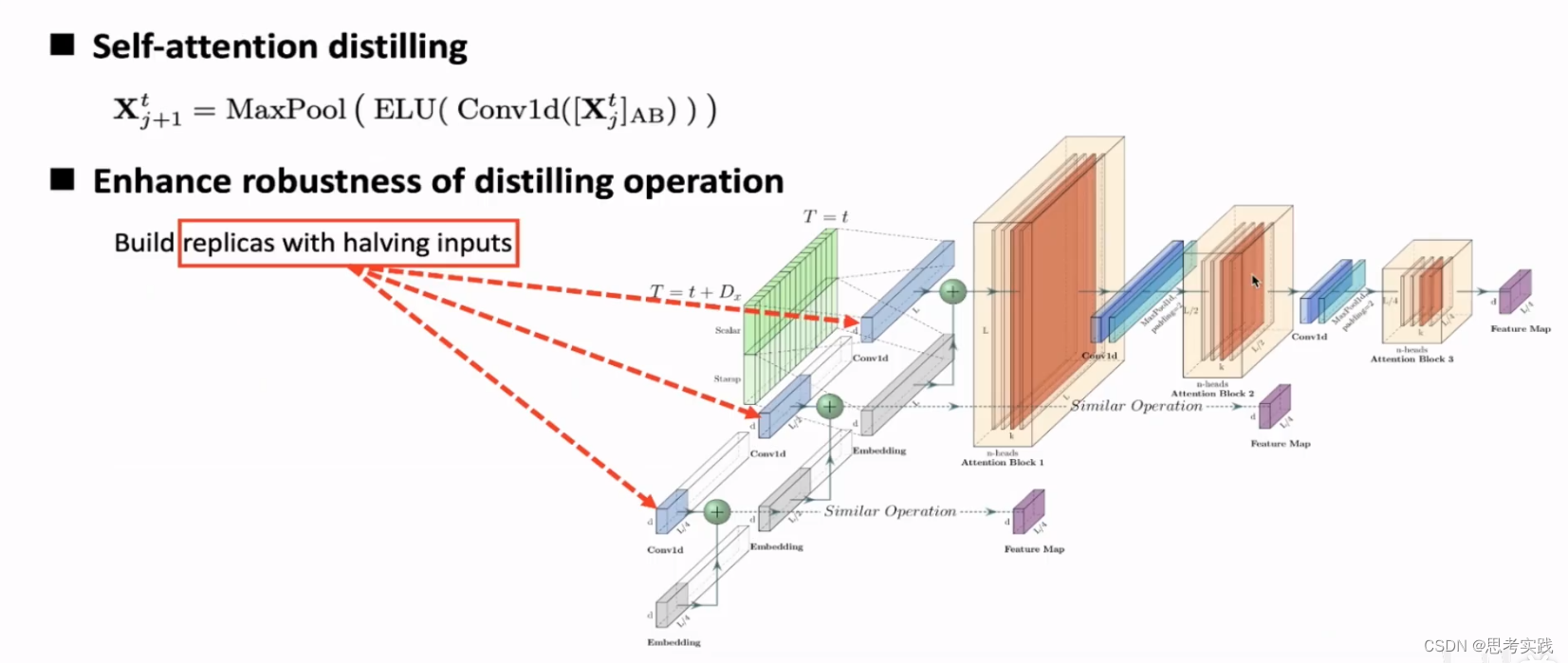
有无Distilling 的对比
有distill operation(右图)部分的操作,attention map特征重新进行了梳理,亮的部分可能更加明显,但是这个attention map依然维持了之前的一些patten(就是看起来差不多),这符合我们对distillation的直觉,也就是说distilling 操作会对一些主导性的特征进行attention,并在下一层构建出来一个focused feature map(就是通过注意力的特征图)
上左与上右都是原生的Self-Attention,进行对比可以看到通过distilling操作的不同,白话就是特征更清晰。
下左与下右都是ProbSparse Self-Attention,上下一对比能发现确实特征这样计算量和特征更少了也更明显了,可以看到ProbSparse Self-Attention相比于Fully-Attention能够更加有效的捕捉到周期性的信息,这个特性也符合一开始的直觉,这个可视化验证了ProbSparse Self-Attention与distilling这两个操作真实有效
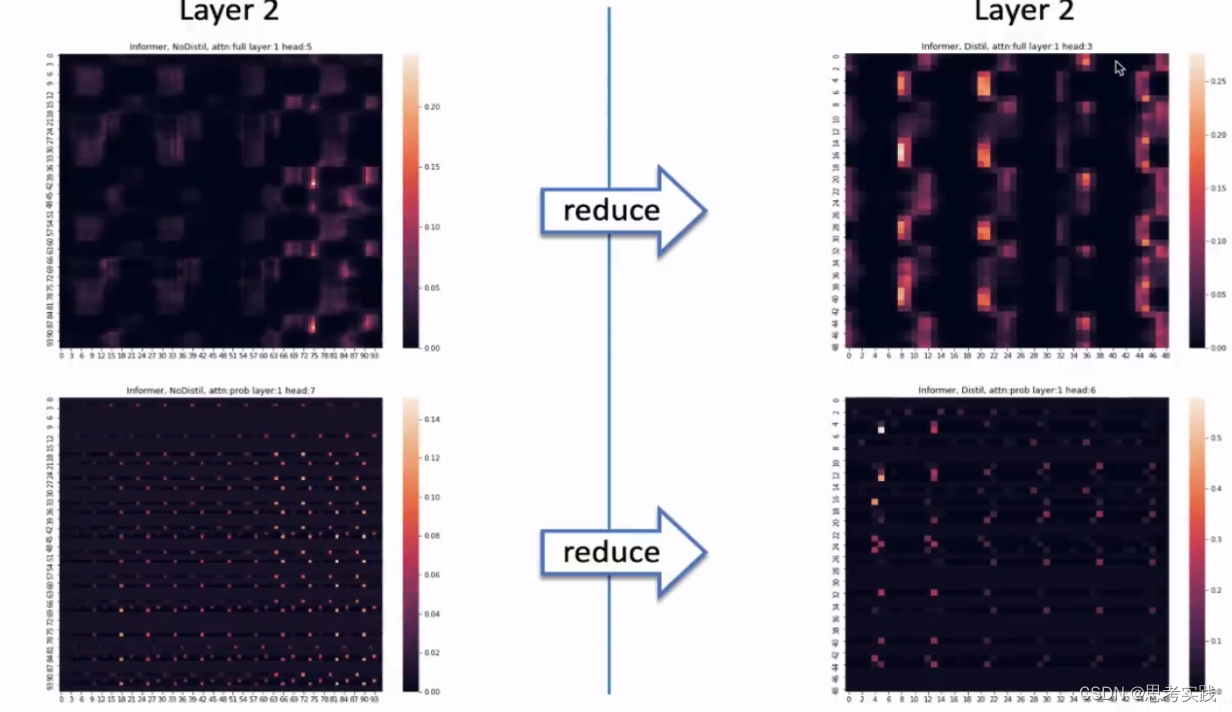
这样可以看到第二个challenge Long Sequence Input的问题也解决了,并且通过attention map可以看出一些不错的解释性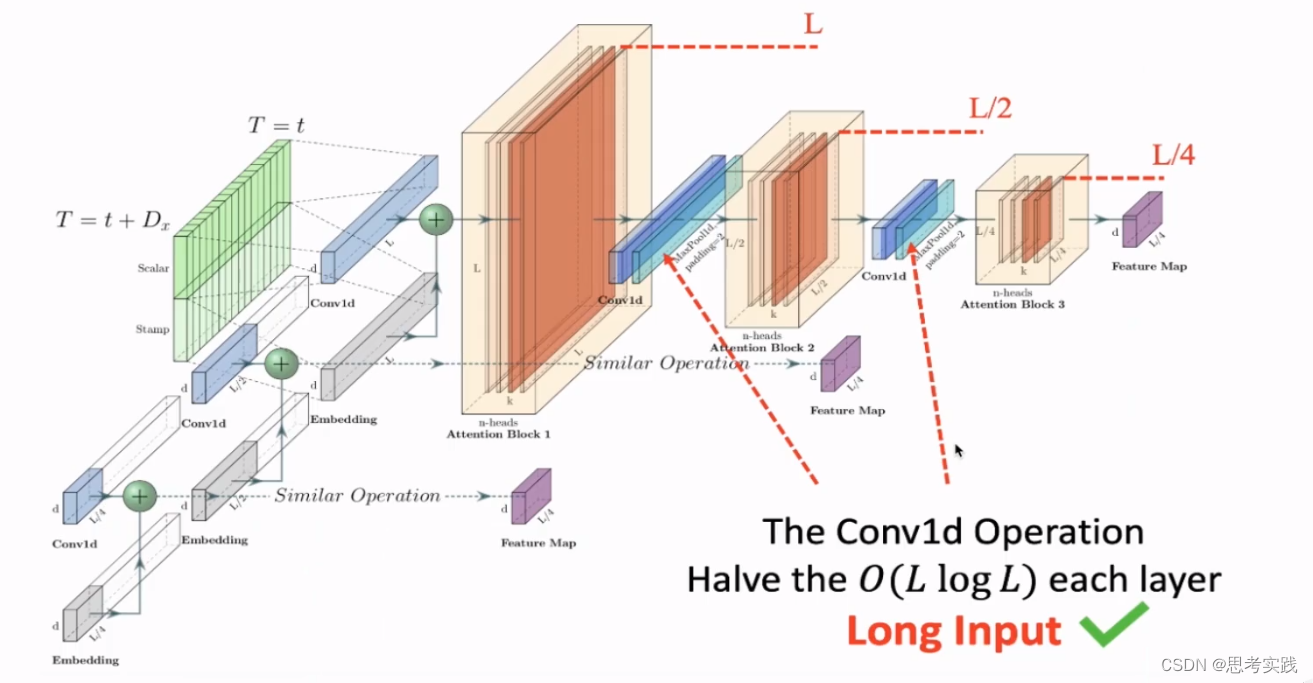
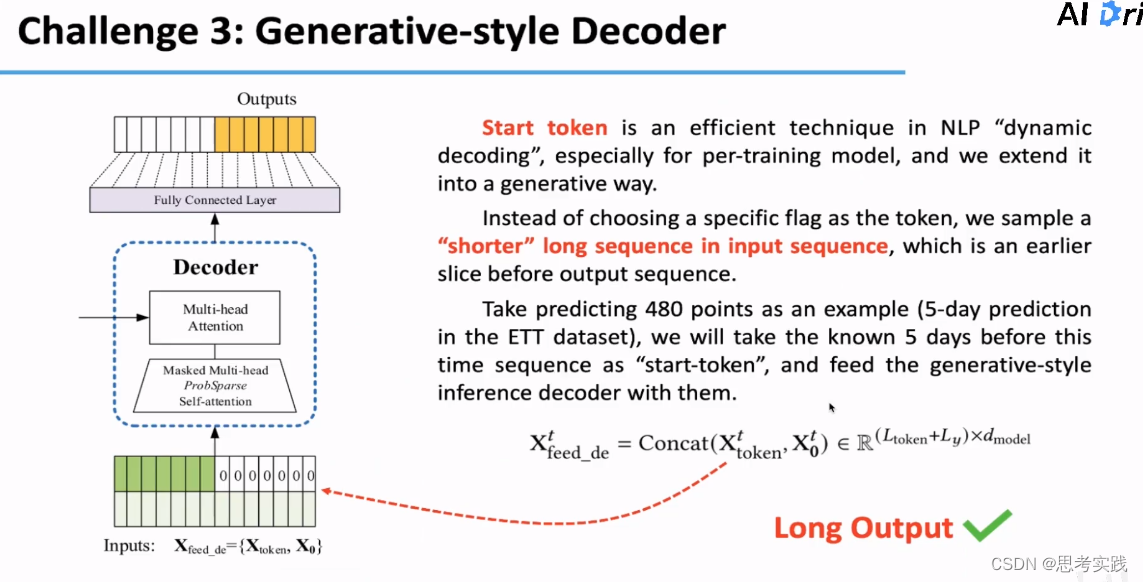
Challenge 3:长序列的Output,原生transformer没办法去解决,都是动态输出的跟rnn-based model一样的级联输出,无法handle 长序列的inference,Start token是个很不错的技巧在Nlp的动态解码过程中,尤其对于预训练模型,在informer中针对长序列预测问题扩展了这个概念,对于长序列的output问题提出了一个单阶段生成式的Decoder,也就是一次性生成所有的预测数据,不需要想rnn一样一步一步的进行迭代,同时与nlp不同之处是我们的start token并不是一个标志符,而是从Input Sequence里面去sample一个较短的序列,这个序列是我们需要预测的序列之前的一个片段,举个例子
比如我们要预测10号到15号的值,那我们需要选取的token就是从input sequence里面抽取5号到10号值作为一个Start Token,然后告诉模型你接着我这部分往后预测就可以了,我们通过多个Output一起生成的这个方法就解决了第三个challenge,long sequence output的问题(没讲清楚)
回顾一下整个Informer模型:
使用Encoder-Decoder架构基于Transformer的,提出了基于ProbSparse self-attention还有Self-attention distilling Operation,Generative-style的Decoder解决了将transformer直接应用到长时间序列预测遇到的三个挑战问题
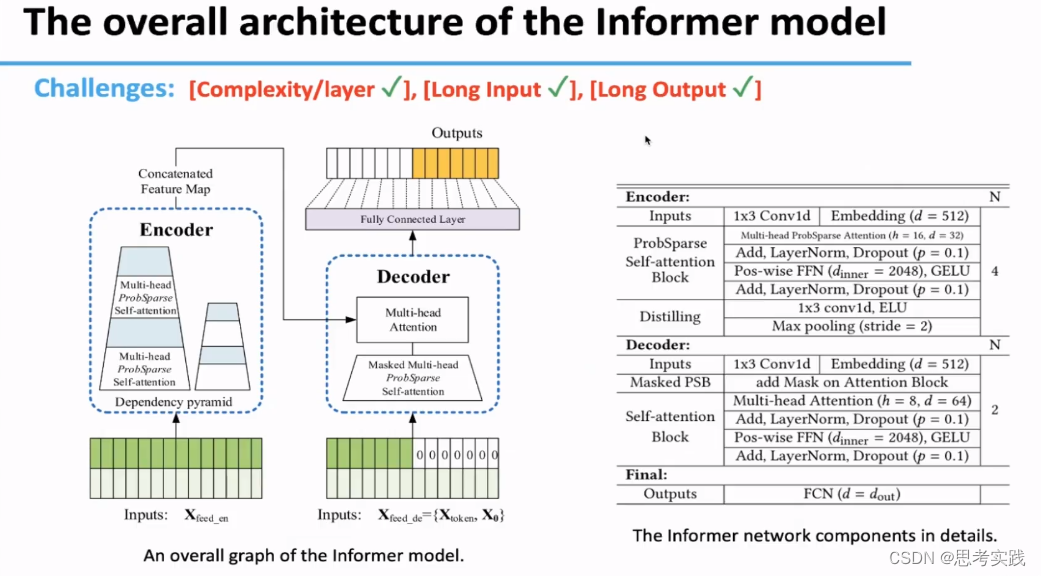
Experiments Settings
数据集
ETT-北航自己收集的电力变压器运行数据,包含两个站点,连续两年的运行数据,传感器在这两年之中每隔15min会采集一个样本点,基于这份数据分别按照一个小时的力度和原始的15min的力度构建了两个数据集(Public)
ECL-用电负荷数据(Public),包含了我国两年的用电负荷数据,每1h一个采样点
Weather-天气数据(Public),天气数据包含美国1600个地点数据,每隔1h采集一个点,共计4年
Baselines
如图所示
Metrics
MAE,MSE,采用两个指标综合评价模型性能

Univariate TSF ,Count代表实验里面结果为sota的总计,Informer随着输出的长度Increase,预测的误差能够平稳缓慢的上升而不是突增,第二行是去掉了ProbSparse Self-Attention
的情况,说明PSS这个假设在很多数据集上都是成立的,所以Informer比
的效果更好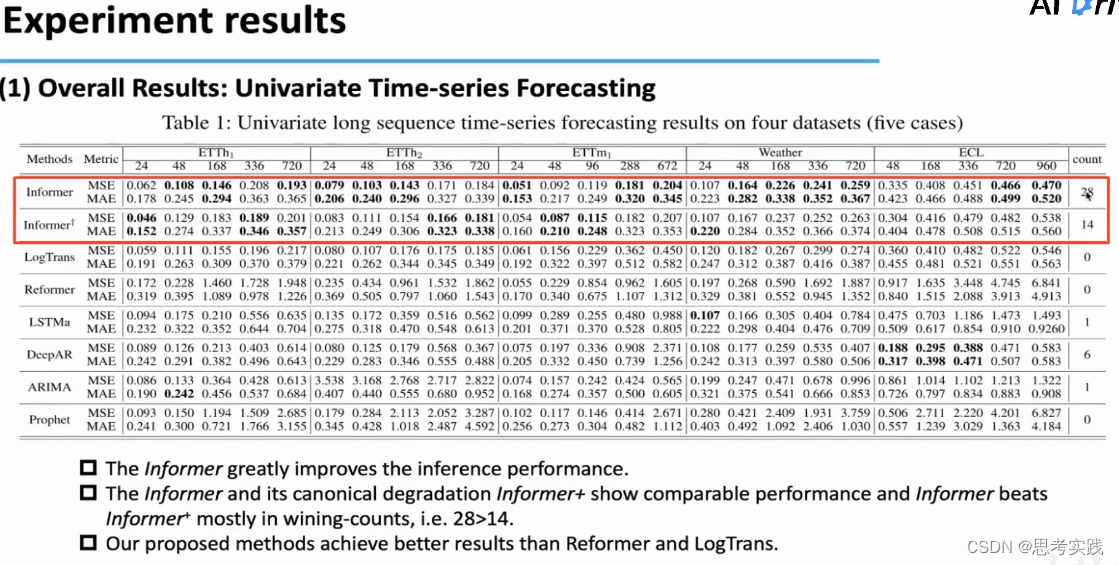
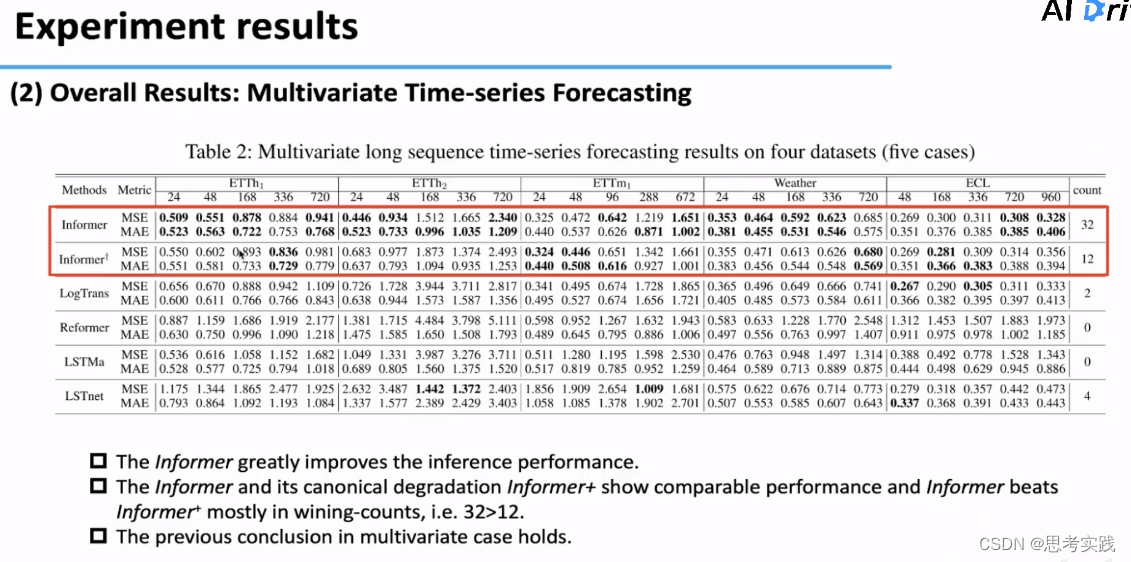
Multivariate TSF,
Granularity :不同粒度上的数据上进行对比,Informer表现的比其他Baseline好 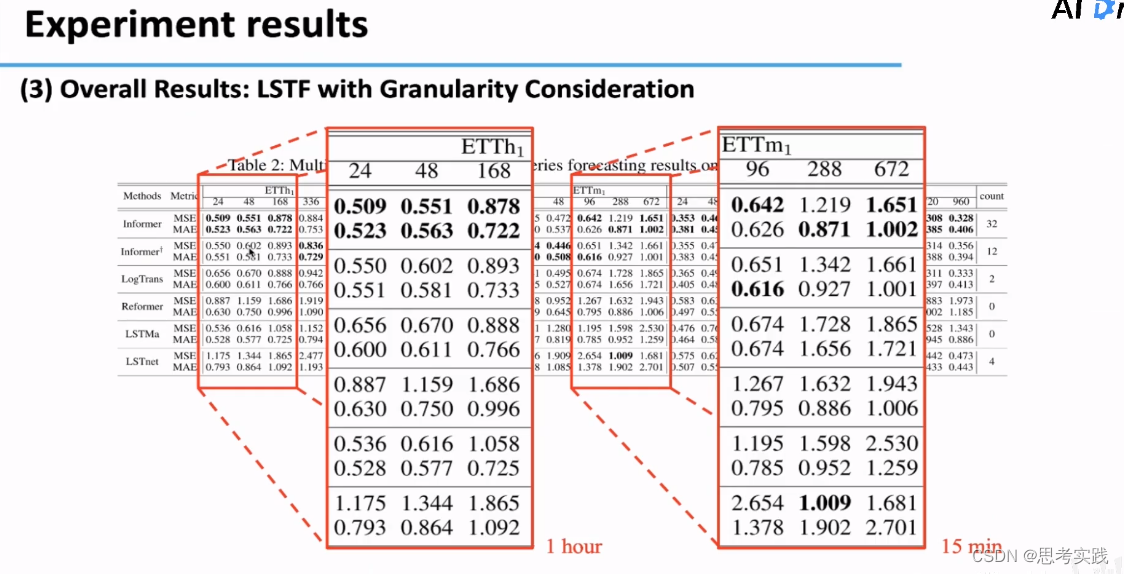
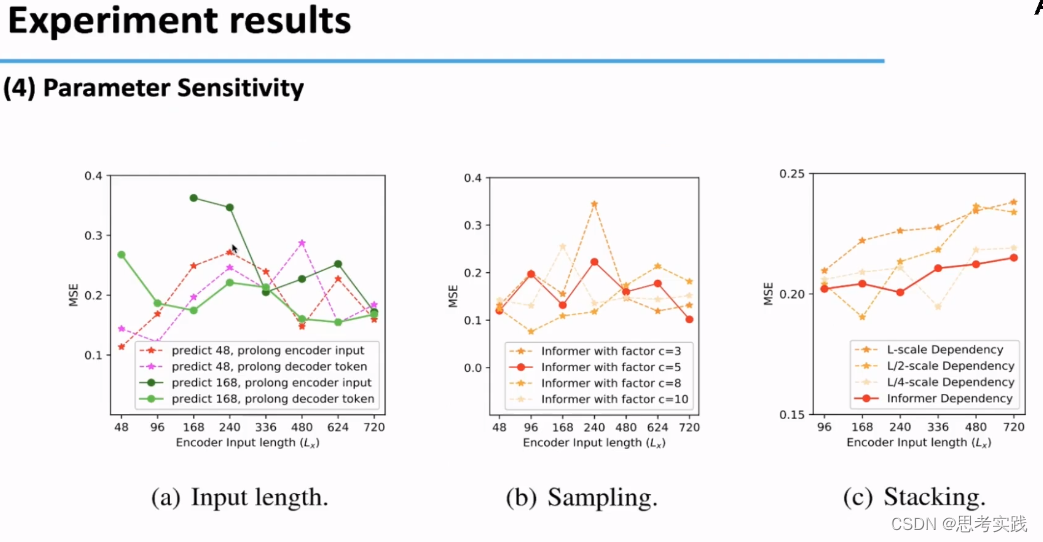
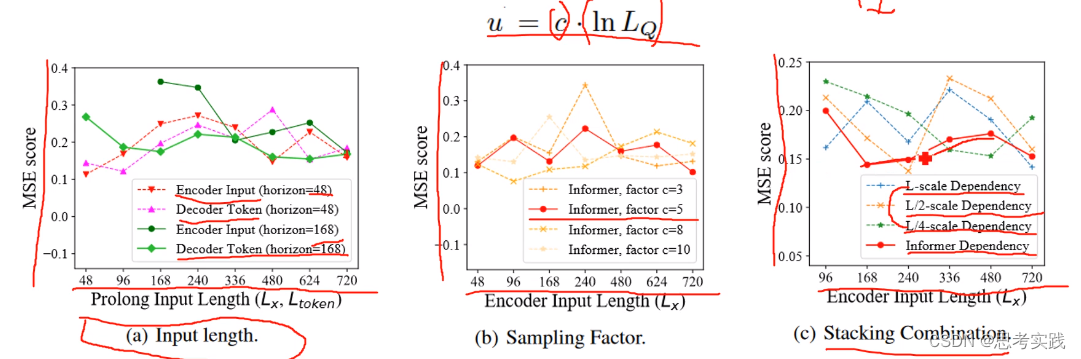
Parameter Sensitivity:通过一下三个实验发现
(a)Input length改变预测不同的predict长度(Autoformer论文工作没有很好的解释这个问题):Orange line举例,当预测短序列48的时候,最初延长输入,会降低性能(MSE提高),但是进一步增加输入长度结果其实会变得更好,原因可能是增加Input的长度会引入更多的短期周期模式,有利于模型进行capture(捕获),同时在预测长序列的时候输入的时间越差,平均误差越低可以看1h与15min对比(上图,但这个没有很严谨的解释,只是描述了一下实验现象),较长的encoder输入可能包含更多的依赖项,较长的decoder token可能包含更加丰富的局部信息
(b)Sampling factor,之前说c与 是有关系的,最终选择的是红色的"Informer with factor c=5"
(c)Stacking对应之前Encoder里面的Stacking,可以看到stack对输入会更加的敏感,比如L/2-stack表现比L-stack好,L/4-stack表现比L/2-stack好,Informer最终的 Setting是红线所示的这一条,这个红色的setting整合了全部情况可以达到最好的效果
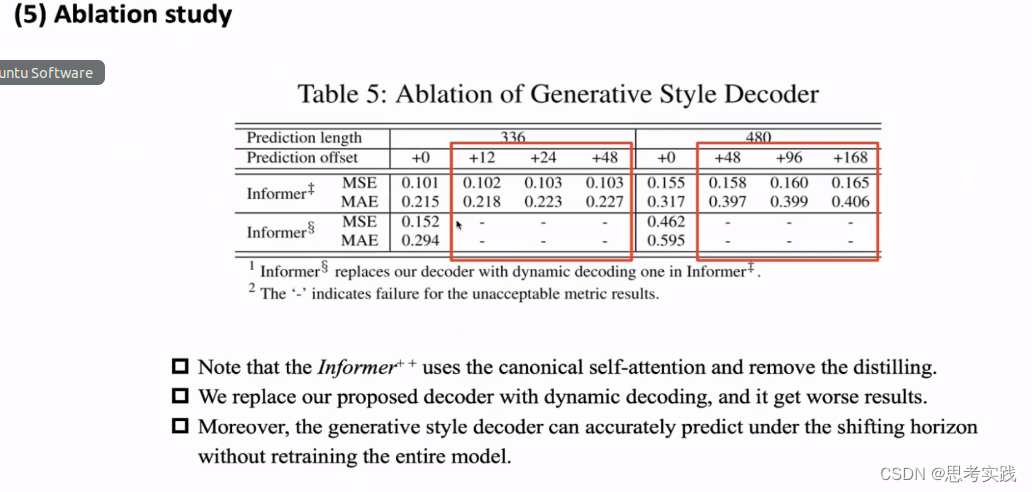
Ablation study
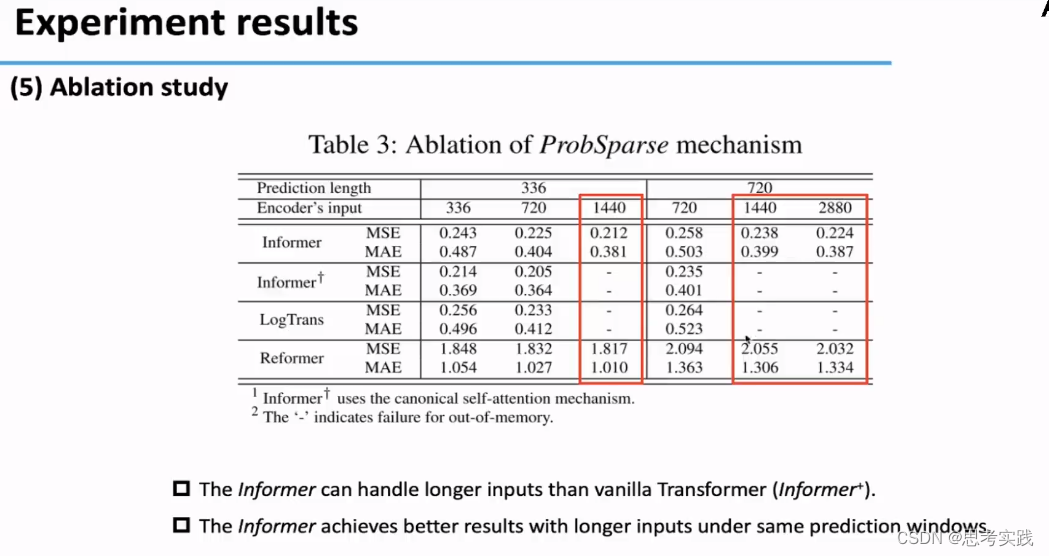
去掉distilling operation的注意力的可以在长度<720的时候达到更好的效果,它不能对较长的序列进行预测,要预测更长的数据,也需要输入更长 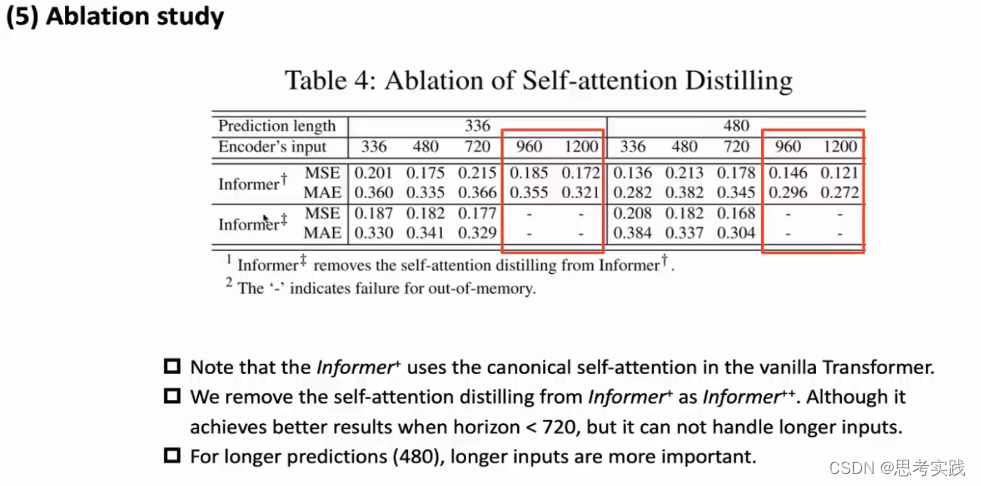
抛开LSTnet与LSTM而言,在Transformer体系中,Informer获得了最佳的效益,在测试阶段Informer大幅度领先其他模型

Your creativity starts with curiosity.
未解释:c参数怎么选取的理论没弄清楚
自己不太了解的是:蒸馏学习用在attention上面这个参考链接2这位同学讲到了
Generative-style的Decoder怎么解决的lso问题没弄清楚
数据整体预测和训练的直觉没弄清楚,反向过程没弄清楚
Transformer Decoder详解
Transformer中的Decoder详解_CuddleSabe的博客-CSDN博客_transformer的decoder
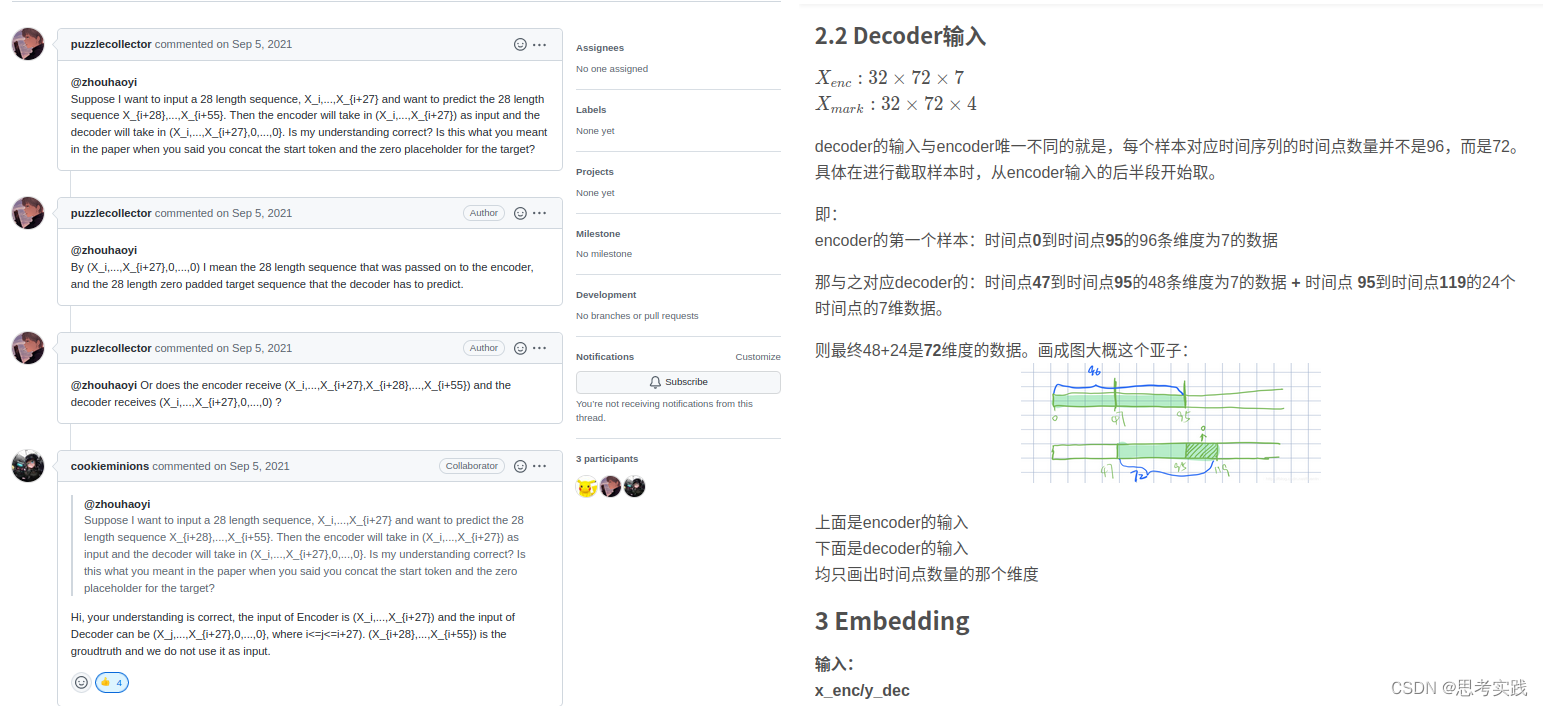
代码Decoder细节讨论
About inputs to the decoder · Issue #223 · zhouhaoyi/Informer2020 · GitHub
Transformer Decoder详解 – 知乎

Reference
我这篇博客从challenge讲故事出发角度引入解释,链接2从模型角度解释
【AI Drive】AAAI 2021最佳论文:比Transformer更有效的长时间序列预测_哔哩哔哩_bilibili
时序模型论文分享:informer_哔哩哔哩_bilibili //这个同学讲解的细节部分有些比原作者团队讲解的还清楚
AAAI最佳论文Informer 解读_fluentn的博客-CSDN博客_informer算法 //最详细的解释解释得比我好多了
文章出处登录后可见!