GPT模型介绍
GPT与BERT一样也是一种预训练模型,与BERT不同的是,GPT使用的是Transformer的Decoder结构。在大量没有标号的数据上训练出一个预训练模型,然后少量有标号的数据上微调训练一个中下游任务的模型。在微调的时候构造与任务相关的输入,就可以很少地改变模型的架构。
无监督训练方式
使用一个标准的语言模型训练方式来进行无监督训练,就是给定一个句子,使用前k-1个词来预测第k个词,假设一个句子,来最大化似然函数:
每一次拿k-1个词,来预测后面的那一个词。
模型结构
模型使用的是Transformer的Decoder解码器,解码器与编码器不同的是,解码器在计算注意力机制的时候会加入一个掩码mask,使得模型在对某个词计算自注意力机制的时候无法看到其后面的词,只能抽取前面词的信息,编码器Encoder没有掩码,对某个词计算自注意力时,它能看到整个序列的所有信息,BERT使用的是Encoder,所以BERT可以做完形填空的任务,抽取前后词的信息来预测中间词,而GPT只能预测后面的词。由于预测未来要比预测中间要难得多,所以导致GPT的效果不如BERT。模型计算公式如下:
transformerblock是Transfomer模型的解码器,如果不了解Transformer,建议先了解一下Transformer结构。是词的Embedding表示,
是位置编码,Transformer使用固定的位置编码,而BERT和GPT均使用可训练的位置编码,其中u是当前要预测的词,U是当前词的前k个词。
微调
在训练好预训练模型后,就要用于下游任务,基于有标号的数据X,一个数据 其标签是y,将其输入到训练好的模型中,得到最后一步的结果
,然后经过一个全连接层以及softmax激活函数,来预测它的类别,公式表示如下:
来最大化如下似然函数:
对于分类任务,我们只关注这个似然函数L2就可以,但是如果把之前语言模型的似然函数L1也用上效果也不错,
是一个超参数。我们最大化这个L3似然函数效果是最佳的,当前只考虑L2也是可以的。
下游任务输入形式
分类任务

蕴含任务

给一段话,然后给一个假设,判断这段话有没有蕴含假设提出的内容。
比如假设是a喜欢b,给出的这段话是a喜欢b,那么这段话是支持这个假设的,如果给出这段话是a讨厌b,那么这段话不支持这个假设,如果给出的这段话是a和b是邻居,那么既不支持也不反对,其实本质也是一个三分类任务。将两句话拼接起来,最开始加上开始符,中间加上分隔符,最后加上抽取符。
相似任务

选择题

GPT-2
使用了更大的数据集进行训练,增大模型,模型参数达到了15亿。并且提出了zero-shot的观点。一般的预训练模型都是训练好以后,需要根据不同的任务去进行微调,还需要有标号的数据,在拓展到一个新的任务上时有一定的成本,GPT2还是做语言模型,但在运用到下游任务的时候,使用一个zero-shot的设定,拓展到其他任务时,不需要下游任务的任何标号信息,也不需要去微调模型,预训练结束后,在很多任务都可以使用。那么在训练数据就需要多做研究,比如想要把英语翻译成法语,那么训练数据需要是这样的(translate to french,english text,french text),比如想要模型回答问题,训练数据就是这样的(answer the question,document,question,answer),将各种任务对应的数据合并起来一起训练进行多任务学习,那么模型在处理下游任务时就不需要微调,直接完成任务。在使用模型时,加入你想让它将英文翻译成法语,则输入(translate to french,english text,),后面的内容就让模型自动生成就可以了。将数据输入模型,让其生成下一个字符,然后将该字符拼接到原数据再次输入模型,再生成下一个字符,直到生成结束标识符,预测结束。
GPT-3
又继续增大了模型,达到了1750亿个参数,提出了few-shot的设定。由于模型已经非常大了,所以在作用到下游任务时也不需要进行微调。few-shot在运用到下游任务时需要给出少量有标号的数据,但是也不对模型进行更新,将问题描述与少量有标号的数据拼接起来输入模型进行预测。
pytorch实现一个小型GPT中文闲聊系统
使用大小50万的数据集,由于算力有限,我只用了其中的24万条,数据集地址:50w中文闲聊数据集地址
(需要科学上网!)或者百度网盘百度网盘,提取码jk8d
数据集长这个样子,由空行隔开每一次对话,需要将数据进行处理,每次对话内容放在一行中,每句话使用\t分隔开,把数据放在一行这样才能使模型每次预测下一个词,处理后的数据dataset.txt是这个样子。

一般的seq2seq模型的对话系统,只能根据一句话来生成一句话,而GPT模型更优,可以把前边的对话信息考虑进来,因为训练数据是把好几轮对话放在一行中,在生成新的回答时,会考虑到之前的信息。
下边是代码实现:
generate_data.py
with open('train.txt','r',encoding='utf-8') as f:
lines = f.readlines()
train_datas = []
temp_data = ''
for line in lines:
if line!='\n':
line = line.strip()
temp_data+=(line+'\t')
else:
train_datas.append(temp_data)
temp_data=''
train_datas = sorted(train_datas,key =lambda x:len(x))
new_train_datas=[]
for train_data in train_datas:
if len(train_data)<300:
new_train_datas.append(train_data)
new_train_datas=new_train_datas[::2]
with open('dataset.txt','w',encoding='utf-8') as f:
for train_data in new_train_datas:
f.write(train_data+'\n')
这个文件是处理原始数据集的,生成dataset.txt文件,算力有限,只取了一部分数据,长度大于300的数据也舍弃了。
get_vocab.py
import json
def get_dict(datas):
word_count ={}
for data in datas:
data = data.strip().replace('\t','')
for word in data:
word_count.setdefault(word,0)
word_count[word]+=1
word2id = {"<pad>":0,"<unk>":1,"<sep>":2}
temp = {word: i + len(word2id) for i, word in enumerate(word_count.keys())}
word2id.update(temp)
id2word=list(word2id.keys())
return word2id,id2word
if __name__ == '__main__':
with open('dataset.txt','r',encoding='utf-8') as f:
datas = f.readlines()
word2id, id2word = get_dict(datas)
dict_datas = {"word2id":word2id,"id2word":id2word}
json.dump(dict_datas, open('dict_datas.json', 'w', encoding='utf-8'))
该文件是来生成字典信息的
gpt_model.py
import json
import torch
import torch.utils.data as Data
from torch import nn, optim
import numpy as np
import time
from tqdm import tqdm
device = torch.device("cuda")
dict_datas = json.load(open('dict_datas.json', 'r'))
word2id, id2word = dict_datas['word2id'], dict_datas['id2word']
vocab_size = len(word2id)
max_pos = 300
d_model = 768 # Embedding Size
d_ff = 2048 # FeedForward dimension
d_k = d_v = 64 # dimension of K(=Q), V
n_layers = 6 # number of Encoder of Decoder Layer
n_heads = 8 # number of heads in Multi-Head Attention
CLIP = 1
def make_data(datas):
train_datas =[]
for data in datas:
data=data.strip()
train_data = [i if i!='\t' else "<sep>" for i in data]+['<sep>']
train_datas.append(train_data)
return train_datas
class MyDataSet(Data.Dataset):
def __init__(self,datas):
self.datas = datas
def __getitem__(self, item):
data = self.datas[item]
decoder_input = data[:-1]
decoder_output = data[1:]
decoder_input_len = len(decoder_input)
decoder_output_len = len(decoder_output)
return {"decoder_input":decoder_input,"decoder_input_len":decoder_input_len,
"decoder_output":decoder_output,"decoder_output_len":decoder_output_len}
def __len__(self):
return len(self.datas)
def padding_batch(self,batch):
decoder_input_lens = [d["decoder_input_len"] for d in batch]
decoder_output_lens = [d["decoder_output_len"] for d in batch]
decoder_input_maxlen = max(decoder_input_lens)
decoder_output_maxlen = max(decoder_output_lens)
for d in batch:
d["decoder_input"].extend([word2id["<pad>"]]*(decoder_input_maxlen-d["decoder_input_len"]))
d["decoder_output"].extend([word2id["<pad>"]]*(decoder_output_maxlen-d["decoder_output_len"]))
decoder_inputs = torch.tensor([d["decoder_input"] for d in batch],dtype=torch.long)
decoder_outputs = torch.tensor([d["decoder_output"] for d in batch],dtype=torch.long)
return decoder_inputs,decoder_outputs
def get_attn_pad_mask(seq_q, seq_k):
'''
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
'''
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], True is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
def get_attn_subsequence_mask(seq):
'''
seq: [batch_size, tgt_len]
'''
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
subsequence_mask=subsequence_mask.to(device)
return subsequence_mask # [batch_size, tgt_len, tgt_len]
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
'''
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(
d_k) # scores : [batch_size, n_heads, len_q, len_k]
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
return context, attn
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
self.layernorm = nn.LayerNorm(d_model)
def forward(self, input_Q, input_K, input_V, attn_mask):
'''
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
'''
residual, batch_size = input_Q, input_Q.size(0)
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k]
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,
2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1,
1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
context = context.transpose(1, 2).reshape(batch_size, -1,
n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
output = self.fc(context) # [batch_size, len_q, d_model]
return self.layernorm(output + residual), attn
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
self.layernorm=nn.LayerNorm(d_model)
def forward(self, inputs):
'''
inputs: [batch_size, seq_len, d_model]
'''
residual = inputs
output = self.fc(inputs)
return self.layernorm(output + residual) # [batch_size, seq_len, d_model]
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, dec_self_attn_mask):
'''
dec_inputs: [batch_size, tgt_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
'''
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(vocab_size, d_model)
self.pos_emb = nn.Embedding(max_pos,d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs):
'''
dec_inputs: [batch_size, tgt_len]
'''
seq_len = dec_inputs.size(1)
pos = torch.arange(seq_len, dtype=torch.long,device=device)
pos = pos.unsqueeze(0).expand_as(dec_inputs) # [seq_len] -> [batch_size, seq_len]
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos) # [batch_size, tgt_len, d_model]
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs)# [batch_size, tgt_len, tgt_len]
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask), 0) # [batch_size, tgt_len, tgt_len]
dec_self_attns = []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_self_attn = layer(dec_outputs, dec_self_attn_mask)
dec_self_attns.append(dec_self_attn)
return dec_outputs, dec_self_attns
class GPT(nn.Module):
def __init__(self):
super(GPT, self).__init__()
self.decoder = Decoder()
self.projection = nn.Linear(d_model,vocab_size)
def forward(self,dec_inputs):
"""
dec_inputs: [batch_size, tgt_len]
"""
# dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attns = self.decoder(dec_inputs)
# dec_logits: [batch_size, tgt_len, tgt_vocab_size]
dec_logits = self.projection(dec_outputs)
return dec_logits.view(-1, dec_logits.size(-1)), dec_self_attns
def greedy_decoder(self,dec_input):
terminal = False
start_dec_len=len(dec_input[0])
#一直预测下一个单词,直到预测到"<sep>"结束,如果一直不到"<sep>",则根据长度退出循环,并在最后加上”<sep>“字符
while not terminal :
if len(dec_input[0])-start_dec_len>100:
next_symbol=word2id['<sep>']
dec_input = torch.cat(
[dec_input.detach(), torch.tensor([[next_symbol]], dtype=dec_input.dtype, device=device)], -1)
break
dec_outputs, _ = self.decoder(dec_input)
projected = self.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
next_word = prob.data[-1]
next_symbol = next_word
if next_symbol == word2id["<sep>"]:
terminal = True
dec_input = torch.cat(
[dec_input.detach(), torch.tensor([[next_symbol]], dtype=dec_input.dtype, device=device)], -1)
return dec_input
def answer(self,sentence):
#把原始句子的\t替换成”<sep>“
dec_input = [word2id.get(word,1) if word!='\t' else word2id['<sep>'] for word in sentence]
dec_input = torch.tensor(dec_input, dtype=torch.long, device=device).unsqueeze(0)
output = self.greedy_decoder(dec_input).squeeze(0)
out = [id2word[int(id)] for id in output]
#统计"<sep>"字符在结果中的索引
sep_indexs =[]
for i in range(len(out)):
if out[i] =="<sep>":
sep_indexs.append(i)
#取最后两个sep中间的内容作为回答
answer = out[sep_indexs[-2]+1:-1]
answer = "".join(answer)
return answer
该文件是GPT模型的实现,如果看不懂建议先去了解一下Transformer代码。
train.py
import json
import torch
import torch.utils.data as Data
from torch import nn, optim
import numpy as np
import time
from tqdm import tqdm
from gpt_model import *
def make_data(datas):
train_datas =[]
for data in datas:
data=data.strip()
train_data = [i if i!='\t' else "<sep>" for i in data]+['<sep>']
train_datas.append(train_data)
return train_datas
class MyDataSet(Data.Dataset):
def __init__(self,datas):
self.datas = datas
def __getitem__(self, item):
data = self.datas[item]
decoder_input = data[:-1]
decoder_output = data[1:]
decoder_input_len = len(decoder_input)
decoder_output_len = len(decoder_output)
return {"decoder_input":decoder_input,"decoder_input_len":decoder_input_len,
"decoder_output":decoder_output,"decoder_output_len":decoder_output_len}
def __len__(self):
return len(self.datas)
def padding_batch(self,batch):
decoder_input_lens = [d["decoder_input_len"] for d in batch]
decoder_output_lens = [d["decoder_output_len"] for d in batch]
decoder_input_maxlen = max(decoder_input_lens)
decoder_output_maxlen = max(decoder_output_lens)
for d in batch:
d["decoder_input"].extend([word2id["<pad>"]]*(decoder_input_maxlen-d["decoder_input_len"]))
d["decoder_output"].extend([word2id["<pad>"]]*(decoder_output_maxlen-d["decoder_output_len"]))
decoder_inputs = torch.tensor([d["decoder_input"] for d in batch],dtype=torch.long)
decoder_outputs = torch.tensor([d["decoder_output"] for d in batch],dtype=torch.long)
return decoder_inputs,decoder_outputs
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
def train_step(model,data_loader,optimizer,criterion,clip=1,print_every=None):
model.train()
if print_every == 0:
print_every = 1
print_loss_total = 0 # 每次打印都重置
epoch_loss = 0
for i, (dec_inputs, dec_outputs) in enumerate(tqdm(data_loader)):
'''
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
'''
optimizer.zero_grad()
dec_inputs, dec_outputs =dec_inputs.to(device), dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, dec_self_attns = model(dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1))
print_loss_total += loss.item()
epoch_loss += loss.item()
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
optimizer.step()
if print_every and (i + 1) % print_every == 0:
print_loss_avg = print_loss_total / print_every
print_loss_total = 0
print('\tCurrent Loss: %.4f' % print_loss_avg)
return epoch_loss / len(data_loader)
def train(model,data_loader):
criterion = nn.CrossEntropyLoss(ignore_index=0).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(epochs):
start_time = time.time()
train_loss = train_step(model, data_loader, optimizer, criterion, CLIP, print_every=10)
end_time = time.time()
torch.save(model.state_dict(), 'GPT2.pt')
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch + 1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f}')
def print_num_parameters(model):
# Find total parameters and trainable parameters
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(
p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
if __name__ == '__main__':
with open('dataset.txt', 'r', encoding='utf-8') as f:
datas = f.readlines()
train_data = make_data(datas[:200])
train_num_data = [[word2id[word] for word in line] for line in train_data]
batch_size = 2
epochs = 30
dataset = MyDataSet(train_num_data)
data_loader = Data.DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.padding_batch)
model = GPT().to(device)
# model.load_state_dict(torch.load('GPT2.pt'))
train(model,data_loader)
该文件用于训练模型
demo.py
import torch
from gpt_model import GPT
if __name__ == '__main__':
device = torch.device('cuda')
model = GPT().to(device)
model.load_state_dict(torch.load('GPT2.pt'))
model.eval()
#初始输入是空,每次加上后面的对话信息
sentence = ''
while True:
temp_sentence = input("我:")
sentence += (temp_sentence + '\t')
if len(sentence) > 200:
#由于该模型输入最大长度为300,避免长度超出限制长度过长需要进行裁剪
t_index = sentence.find('\t')
sentence = sentence[t_index + 1:]
print("机器人:", model.answer(sentence))
该文件测试模型
由于本人算力有限,数据量只使用了24万多,并且模型训练epoch过少,模型效果不佳,想提高效果可以增大数据集以及训练轮次epoch
模型部分测试效果如下:

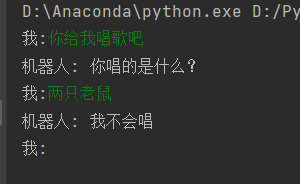
文章出处登录后可见!