Adaboost
0.参考内容及思维导图链接
1.集成学习
1.1 思想
集成学习通过构建并结合多个学习器来完成学习任务
1.1.1 类比
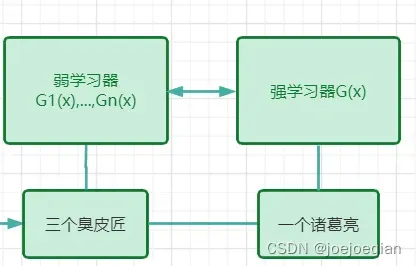
三个臭皮匠,顶个诸葛亮
如下图:
1.1.2 补充概念
在集成学习中,学习器相当于模型,又分为强学习器和弱学习器,弱分类器又叫基分类器。
强学习器:可以认为它是一种准确率很高但相对复杂的模型,比如一些神经网络构建出来的模型,它耗费时间精力多,对算力要求高,花费代价高;
弱学习器:可以认为它是一种比较简单的模型,预测效果不太好,如逻辑回归等简单的模型。
总结就是三个臭皮匠顶个诸葛亮
1.2 优点
集成学习通过将多个学习器进行结合,常常可以获得比单一学习器更加显著的优越性能。
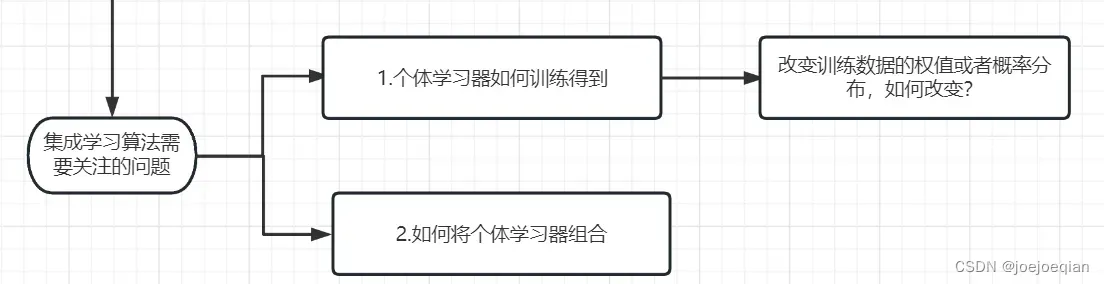
1.3 需要关注的问题
1.3.1 个体学习器如何训练得到?
改变训练数据的权值或者概率分布,如何改变?
个体学习器就是弱学习器,多个弱学习器学到的东西必须是有所差异的,它们各自的强项不一样。
举例:
一个班级里有
,其中
语文好,
英语好,
,
数学好,将他们各自好的学科组合起来,就可以抗衡学校里年级第一的学生了。
所以只需要让各学习器,学习不一样的数据就可以了,继续上面的例子
其中
这样相当于改变了训练数据的权值或者概率分布。
1.3.2 如何将个体学习器组合?
是通过线性相加,还是其他方法?
后面会详细说
1.4 分类
当训练和组合有不一样的办法时,就得到两种类别:
- boosting
- bagging
1.4.1 对于boosting

2.工作机制
也就是如何解决训练和组合问题:
- 1.提高那些在前一轮被弱分类器分错的样本的权值;减少那些在前一轮被弱分类器分对的样本的权值,使得误分的样本在后续受到更多的关注,体现了串行。
举例:
如你有
个分身
,期末考试需要考语数英三门。在平时学习时,你先让
去学习语文,然后通过平时的测验发现
去学习,减少对语文的学习的时间,增多数学和英语的时间,然后通过平时的测验发现
去学习,减少对数学和语文的学习的时间,增多英语的时间。
- 2.加法模型将弱分类器进行线性组合
3.四个问题
- 1.如何计算学习误差率
?
- 2.如何得到基学习器权重系数
?
- 3.如何更新样本权重
?
- 4.使用何种结合策略?
1.4.2 对于bagging
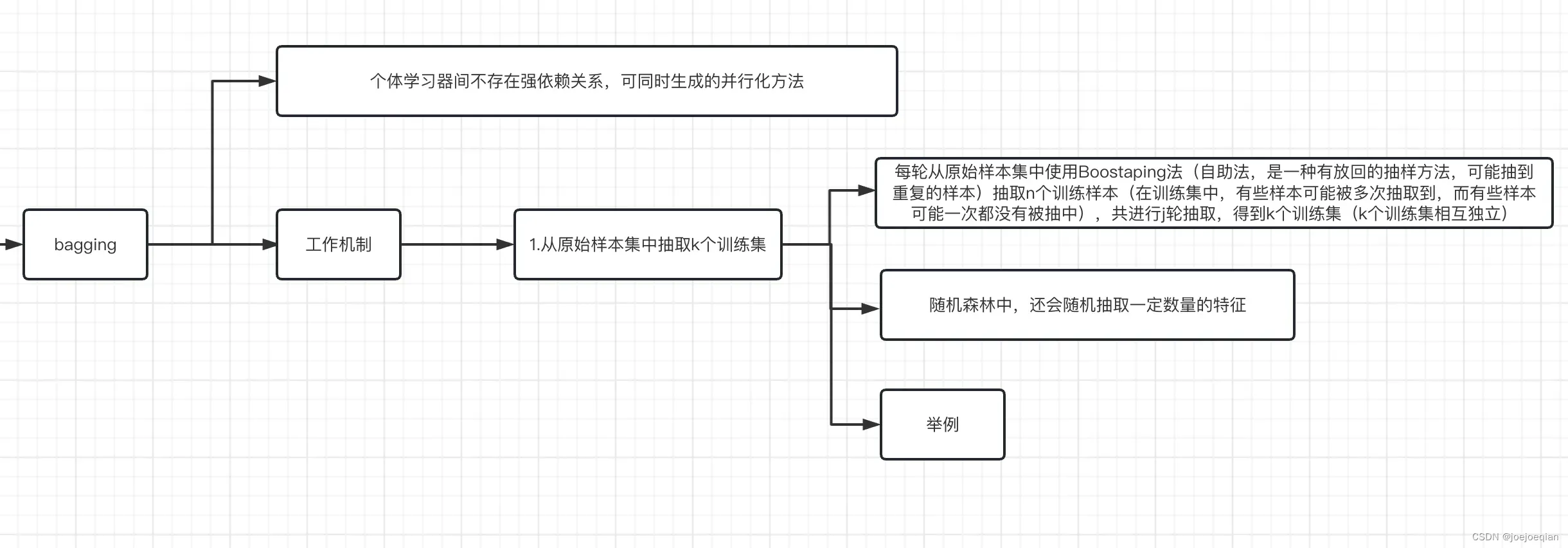
2.工作机制
- 1.从原始样本集中抽取k个训练集
- 每轮从原始样本集中使用Boostraping法(自助法,是一种有放回的抽样方法,可能抽到重复的样本)抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中),共进行j轮抽取,得到k个训练集(k个训练集相互独立)。
- 随机森林中,还会随机抽取一定数量的特征。
- 举例:待补充。
- 2.k个训练集分别训练,共得到k个模型,体现了并行。
- 3.将上步得到的k个模型,通过一定方式组合起来
- 分类问题:将上步得到的k个模型采用投票的方式得到分类结果。
- 回归问题:计算上述模型的均值作为最后的结果。
3.代表
随机森林
2.Adaboost
Adaboost解决的是二分类问题。
2.1 参考资料
《机器学习方法》作者:李航
2.2 思路
2.2.1 数学表达
表达式
其中由
的”分类误差率”决定,训练样本
:提高前一轮“错误分类”的样本的权值,降低前一轮“正确分类”的样本的权值。
注意到,不是之前说的权重值,之前说的权值是
。
2.2.2 基本思路
1.每一轮中,分别记录好那些被当前弱分类器正确分类和错误分类的样本,在下一轮训练时,提高错误分类样本的权值,同时降低正确分类样本的权重,用以训练新的弱分类器。这样一来,那些没有被正确分类的数据,由于其权值加大,会受到后一轮的更大关注。
如何理解改变样本的权值?
举例:
初始有3个样本,即其所占比例
:
| 样本 | |||
|---|---|---|---|
| 所占比例 |
经过一轮学习后,分类器成功将
分类成功,所以我们需要将这两个样本的权重降低,提高第一个样本的权值,即下面表格:
:
| 样本 | |||
|---|---|---|---|
| 所占比例 |
所以增大权值相当于将初始样本中的错误分类的数量变多了,变成了这样:
2.加权多数表决
- 1.加大分类误差率小的弱分类器的权值
,使其在表决中起较大作用;
- 2.减少分类误差率大的弱分类器的权值
2.3 算法流程
2.3.1 基本流程
1.二分类训练数据集
,其中,每个样本点由实例与标记组成。实例
,标记
,
是实例空间,
是标记集合。
2.定义基分类器(弱分类器)
大部分情况下,都是同一类型的分类器。
比如:,其中
为阈值
3.具体算法流程
1.初始化/更新当前训练数据的权值分布
-
如果是初始化:
,初始化权值(这个是训练数据的权值,不是基分类器的)使用数量的平均值
。
-
如果是更新(不是第一次):

2.训练当前基分类器
使用具有权值分布
的训练数据集学习,得到基分类器
。比如,你选择的是逻辑回归模型,就要交叉熵作为损失函数,用梯度下降作为优化方法来训练。
3.计算当前基分类器的权值
- 1.先要计算当前
,其中
为指示函数,
其中,下面是简单的解释:
基分类器的权重
,
,
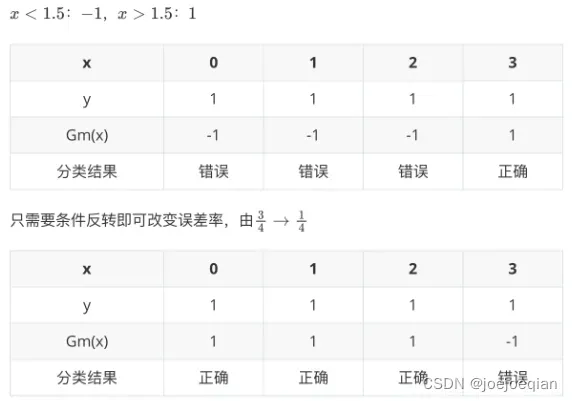
;当
,
,但是必有
该分类器的结果都取一个相反的结果,这样一来取反后的分类器误差率还是小于。
举例:
4.将更新到加法模型
中
5.判断是否满足循环退出条件,如定义的M次或者模型精度
- 分类器个数是否达到M
- 总分类器误差率是否低于设定的精度(
)
2.3.2 例题
1.二分类训练数据集

在x中划分出候选阈值(如图中红色箭头指向的所示),
从中选出使得误差率最小的,作为我们最终阈值构建好
:

3.循环M次
M=1时:
1.初始化/更新当前训练数据的权值分布
- 初始化:
2.训练当前基分类器
- 使用具有权值分布
- 训练方法:1.在
中划分出各候选阈值,构建好候选
在权值分布为的训练数据上,阈值
取2.5时分类误差最低,故基本分类器为
3.计算当前基分类器的权值
-
1.计算当前
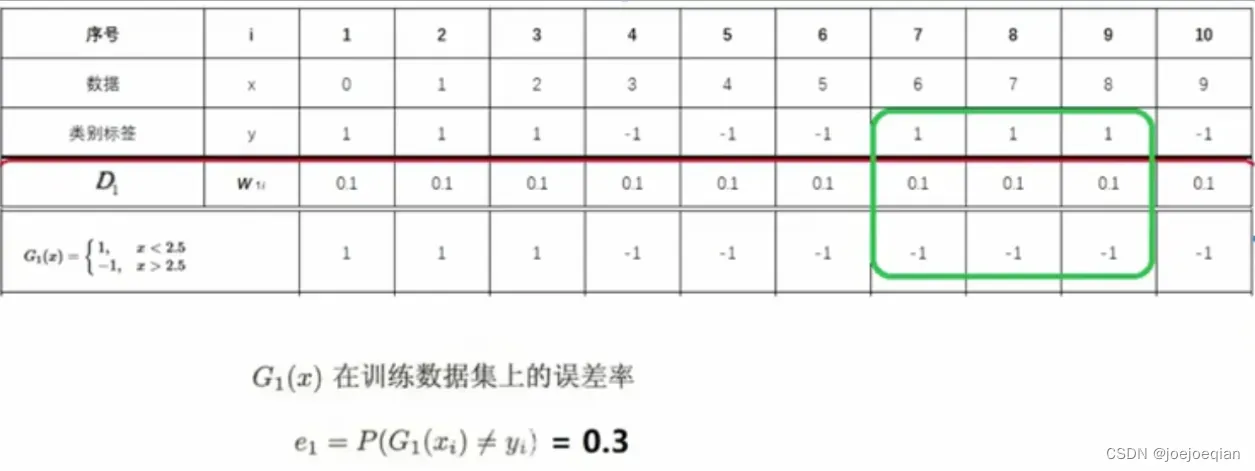
-
2.根据分类误差率
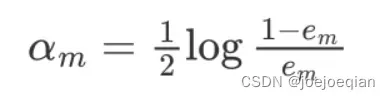
-
3.计算
4.将更新到加法模型
中
得
5.判断是否满足循环退出条件
- 分类器个数是否达到M
- 总分类器误差是否低于设定的精度
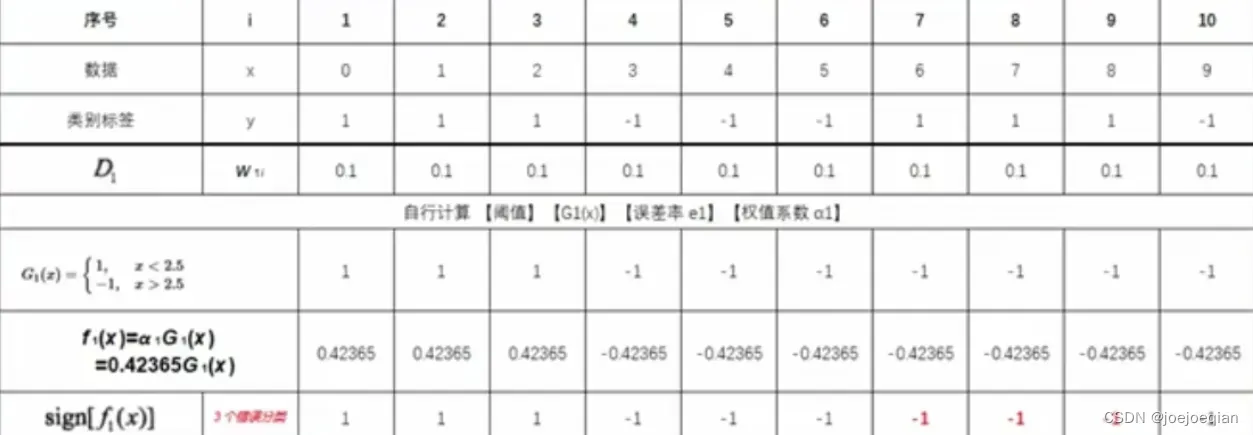
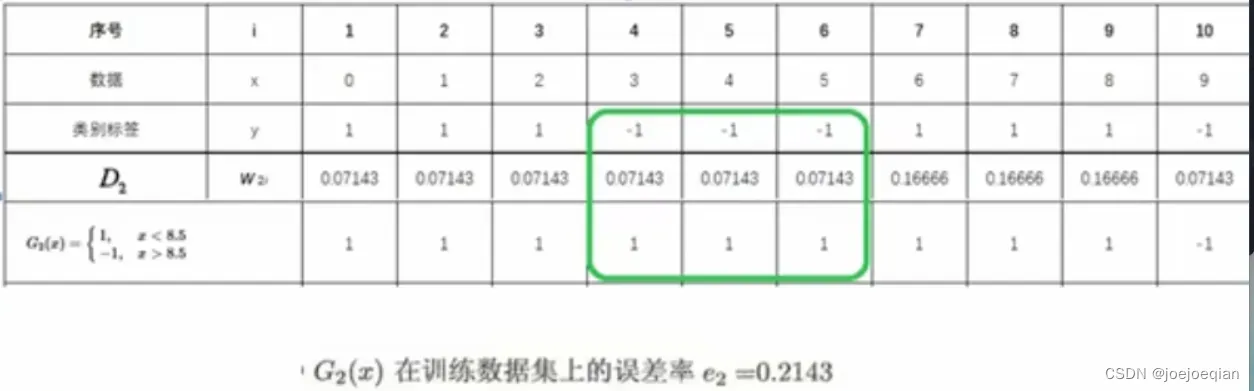
M=2时:
1.初始化/更新当前训练数据的权值分布
- 更新:

2.训练当前基分类器
- 使用具有权值分布
- 训练方法:1.在
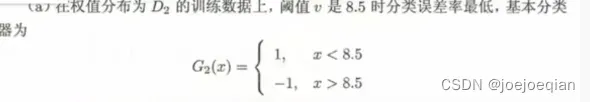
3.计算当前基分类器的权值
-
1.计算当前
-
2.根据分类误差率
-
3.计算
4.将更新到加法模型
中
得
5.判断是否满足循环退出条件
- 分类器个数是否达到M
- 总分类器误差是否低于设定的精度
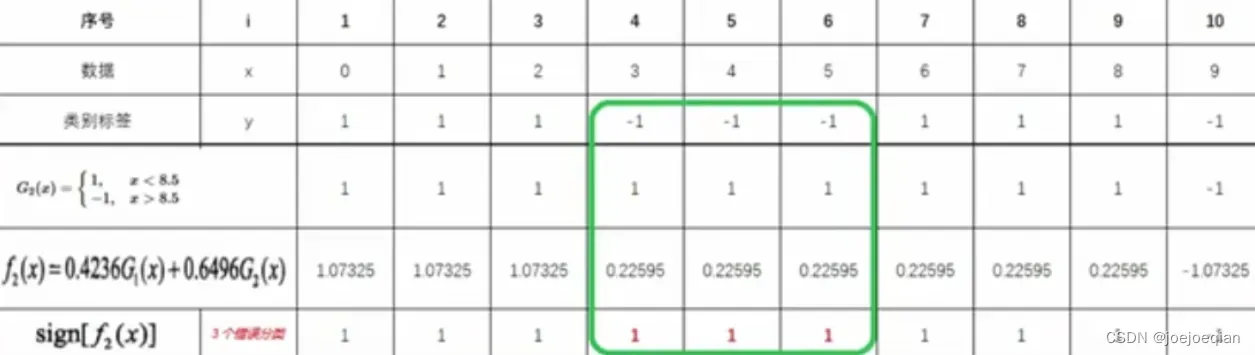
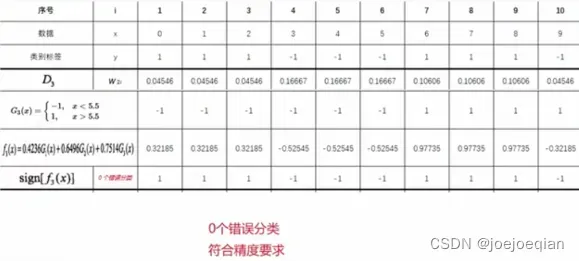
M=3时:
2.4 加法模型
2.4.1 预测函数
其中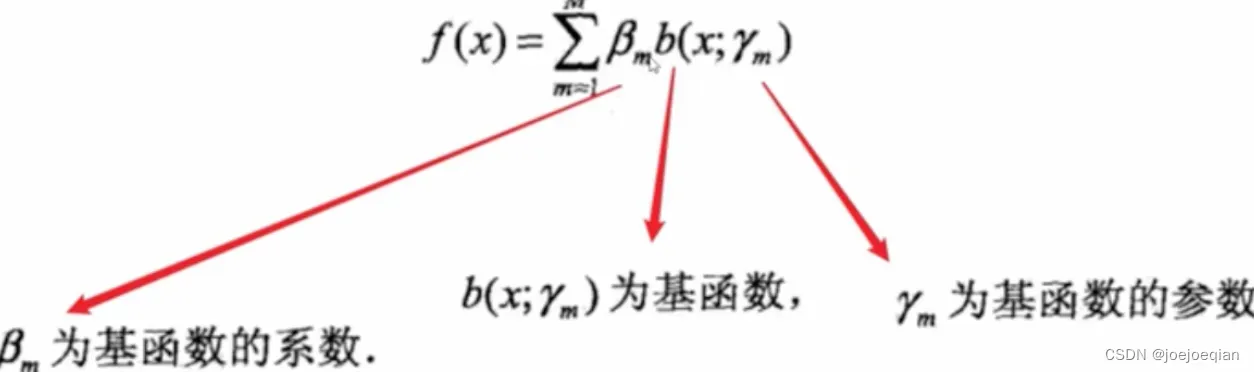
2.4.2 损失函数的设计
1.自定义损失函数
2.回归问题
MSE均方误差
3.分类问题
- 指数函数
- 交叉熵损失
4.优化方法
- 为什么不用梯度?
- 梯度下降的缺点:整体损失极小化:
- 梯度下降的缺点:整体损失极小化:
- 缺点:复杂度高;举例:假设
,假设L为MSE,
如:假设你用梯度下降优化,单词迭代过程,就需要同时优化4个参数(而且
是向量),如果
再大些,单词迭代需要同时更新
个参数,复杂度高。
- 使用的方法:前向分步算法
- 具体步骤:

- 具体步骤:
2.5 算法原理
2.5.1 需要优化的问题:二分类
1.二分类训练数据集
2.
,其中,每个样本点由实例与标记组成。实例
,标记
,
是实例空间,
是标记集合。
2.5.2 模型:加法模型
2.5.3 最终分类器
2.5.4 损失函数:指数损失函数
1.二分类问题,使用指数损失函数
- 当
分类正确时,与
同号,
。
- 当
。
2.将损失函数视为训练数据的权值
非常符合训练样本中:提高前一轮“错误分类”的样本权值;降低前一轮“正确分类”的样本的权值。(就是因为)
3.单个样本损失函数
4.总体损失函数(把所有样本放进去)
2.5.5 优化方法:前向分步算法
1.算法流程

2.第m轮
-
1.极小化损失函数:
-
2.式子变换:
,其中
推导过程:
3.求解 -
1.优化
- 从
- 从
-
2.优化
- 推导过程:
式子变换:
凸优化:
求导:
导数为0:令,即:
公式转换:
其中是损失并不是
限定空间里面的,而之前算法流程中的w是加了规范化因子进行归一化操作,保证了系数和为
。
-
3.前向更新
:
-
4.更新训练数据权值
:
- 推导:
更新
根据公式:
有:
- 推导:
3.四个问题
3.1 如何计算学习误差率?
根据分类误差率,计算基分类器
的权重系数:
为什么这样计算基学习器权重系数?
,
下降时,
单调增,
单调增。
推导过程:
看2.5 算法原理
3.2 如何得到基学习器权重系数?
3.3 如何更新样本权重?
更新:
根据公式:
有:
这里 是除以过规范化因子
的,从公式
可以看出,如果有第
个样本分类错误,则
,导致样本的权重在第
个基分类器中增大,如果分类正确,则权重在第
个基分类器中减少。
3.4 使用何种结合策略?
4.小结
Adaboost的主要优点有:
- 1.Adaboost作为分类器时,分类精度很高
- 2.在Adaboost的框架下,可以使用各种回归分类模型来构建弱学习器,非常灵活。
- 3.作为简单的二元分类器时,构造简单,结果可理解。
- 4.不容易发生过拟合
Adaboost的主要缺点有:
- 1.对异常样本敏感,异常样本在迭代中可能会获得较高的权重,影响最终的强学习器的预测准确性。
文章出处登录后可见!