目录
1. 问题描述
系统:Windows10,CUDA11.1.96
开始学习PyTorch。在用PyTorch进行一个深度学习训练时发现报告以下Warning信息:
rank_zero_deprecation( GPU available: False, used: False TPU available: False, using: 0 TPU cores IPU available: False, using: 0 IPUs HPU available: False, using: 0 HPUs
有点纳闷。用Tensorflow-GPU也不是一天半天了,为什么会报告找不到GPU?
2. 调查和解决
2.1 初步调查
啥也不说,先上网兜一圈收集信息。。。
首先运行以下命令(当然要先进入python环境)再次确认一下是否能找到GPU(能找到CUDA自然就是找到了GPU)。
import torch
print(torch.cuda.is_available())
返回False。
初步调查的结果是,
(1) 我之前只是单纯地用“pip install pytorch”来安装pytorch。而这样的缺省安装是不会安装pytorch-gpu版本的。
(2) 其次,必须在pytorch安装时指定与机器匹配的CUDA版本。不匹配的话也可能会出问题。
顺便提一下,tensorflow早期版本的安装也是这样的,不特意指定的话,缺省地就是安装cpu版本,后来tensorflow学乖了,安装时自动检测自动匹配,有GPU就安装匹配的tensorflow-gpu,没有就安装tensorflow-cpu。在这一方面pytorch落在了后面。
2.2 官网安装方法
首先先看官网上的说法(根据既往各种安装搏斗经验,官方方案解决不了的再去求各路民间偏方的路径比较好^-^)。
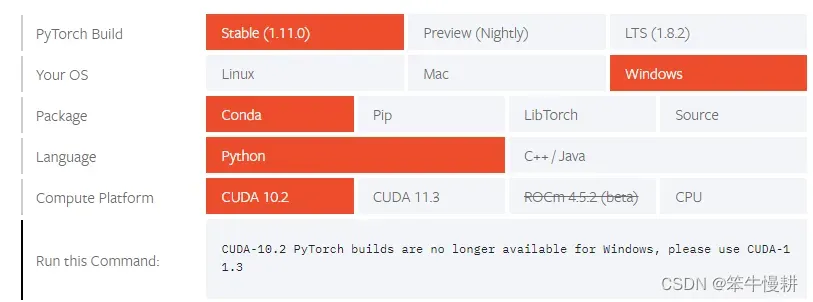
在官网首页(Start Locally | PyTorch) 有一个友好的傻瓜菜单供选择。
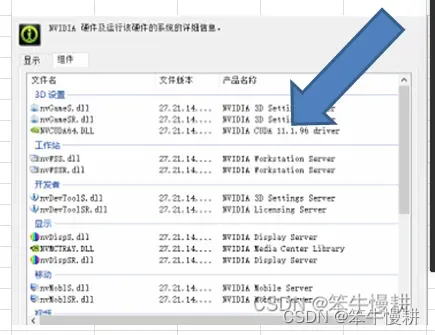
查了查机器上的CUDA版本(控制面板–>硬件和声音–>NVIDIA控制面板–>帮助–>系统信息–>组件),如下所示,CUDA版本为11.1.96。
CUDA11.1.96,但是上面只有10.2(no longer available) 和11.3,咋办?
差异不大,估摸着没有那么敏感吧。先选11.3试试看?
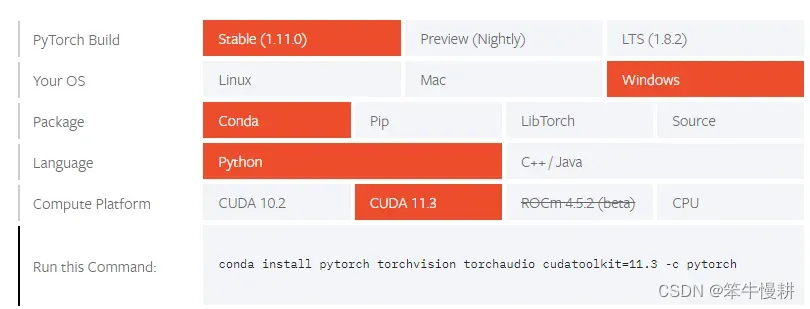
很好,给出该运行的命令(最喜欢这种傻瓜式投喂了)。运行以下命令:
conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
一路顺风顺水,安装好后重新运行“print(torch.cuda.is_available())”进行检测,这回返回了True,妥了。
重新运行训练,GPU找到了,不过又碰到新问题。。。找是找到了,不过没有使用。

不过已经明确地给出了解决指示,照着修改一下代码就妥了。
trainer = pl.Trainer(
max_epochs=train_args.max_epochs,
callbacks=get_callbacks(),
accelerator='gpu',
devices=1,
progress_bar_refresh_rate=20,
flush_logs_every_n_steps=1,
log_every_n_steps=1)不过,还是要吐个槽。谁家会搁着GPU故意不使用啊。所以缺省值难道不是应该设置为{ accelerator=’gpu’, devices=1}更加友好嘛?
2.3 如果还是不匹配呢?
以上安装表明CUDA版本有点小的差异也可能没有问题。
但是,如果版本差异比较大的话,怎么办呢?在以上安装过程中顺便调查了一下。在“PyTorch + CUDA 11.6 – deployment – PyTorch Forums”看到一个解决方案可以参考。找到这个网页是因为我一开始看错了把我的CUDA版本错看成11.6了^-^。关键点是,如果没有找到匹配CUDA版本的稳定发布的话,可以用编译nightly binaries进行安装的方式解决,如下所示(假定CUDA11.6,其它CUDA版本估计也可以照猫画虎)
pip install torch –pre –extra-index-url https://download.pytorch.org/whl/nightly/cu116
文章出处登录后可见!