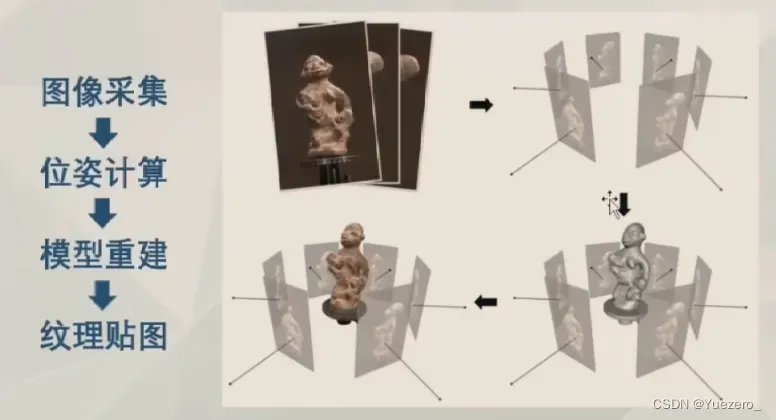
三维重建定义
在计算机视觉中, 三维重建是指根据单视图或者多视图的图像重建三维信息的过程. 由于单视频的信息不完全,因此三维重建需要利用经验知识. 而多视图的三维重建(类似人的双目定位)相对比较容易, 其方法是先对摄像机进行标定, 即计算出摄像机的图象坐标系与世界坐标系的关系.然后利用多个二维图象中的信息重建出三维信息。

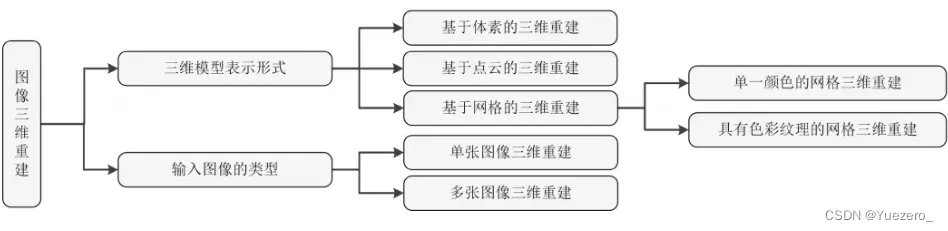
常见的三维重建表达方式
常规的3D shape representation有以下四种:深度图(depth)、点云(point cloud)、体素(voxel)、网格(mesh)。
RGB-D深度图的D通道每个像素值代表的是物体到相机xy平面的距离,单位为 mm,由深度摄像头获取。

Point Cloud点云是某个坐标系下的点的数据集。点包含了丰富的信息,包括三维坐标X,Y,Z、颜色、分类值、强度值、时间等等。在我看来点云可以将现实世界原子化,通过高精度的点云数据可以还原现实世界。万物皆点云,由三维激光雷达获取。

体素是三维空间中的一个有大小的点,一个小方块,相当于是三维空间种的像素。

三角网格就是全部由三角形组成的多边形网格。多边形和三角网格在图形学和建模中广泛使用,用来模拟复杂物体的表面,如建筑、车辆、人体,当然还有茶壶等。任意多边形网格都能转换成三角网格。

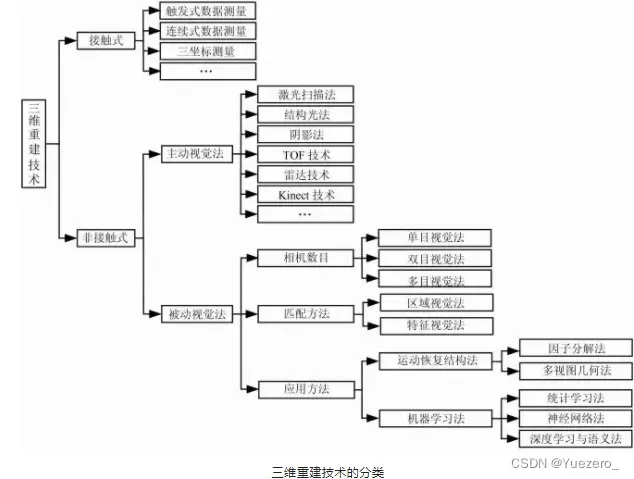
三维重建的分类
根据采集设备是否主动发射测量信号,分为两类:基于主动视觉理论和基于被动视觉的三维重建方法。
主动视觉三维重建方法:使用RGBD深度图和点云进行三维重建,主要包括结构光法、TOF飞行时间法、激光扫描法。每个点到深度相机所在的垂直平面的距离值。这个距离值被称为深度值(depth)深度图像可以看做是一副灰度图像,其中图像中每个点的灰度值代表了这个点的深度值,即该点在现实中的位置到相机所在垂直平面的真实距离。通过深度图像获得场景的数据,对点云数据进行基于平面的分割,提取平面特征实现三维场景的重现。
被动视觉三维重建方法:被动视觉只使用RGB二维图像,根据图像的纹理分布等信息恢复深度信息,进而实现三维重建,主要包括单目、双/多目。其中,双目视觉和多目视觉理论上可精确恢复深度信息,但实际中,受拍摄条件的影响,精度无法得到保证。单目视觉只使用单一摄像机作为采集设备,具有低成本、易部署等优点,但其存在固有的问题:单张图像可能对应无数真实物理世界场景(病态),故使用单目视觉方法从图像中估计深度进而实现三维重建的难度较大。
基于深度学习的三维重建算法研究主要有三种:
1.在传统三维重建算法中引入深度学习方法进行改进;
2.深度学习重建算法和传统三维重建算法进行融合,优势互补;
3.模仿动物视觉,直接利用深度学习算法进行三维重建,包括基于体素、基于点云和基于网格。
有前景的方向:基于SFM的运动恢复结构、基于Deep learning的深度估计和结构重建,基于RGB-D深度摄像头的三维重建、基于点云的三维重建
SFM(Structure From Motion),主要基于多视觉几何原理,用于从运动中实现3D重建,也就是从无时间序列的2D图像中推算出三维场景结构,是计算机视觉学科的重要分支,广泛应用于AR/VR、自动驾驶等领域。SFM是一个估计相机参数及三维点位置的问题,根据SfM过程中图像添加顺序的拓扑结构,SfM方法可以分为增量式、全局式、混合式、层次式、基于语义的SFM和基于深度学习的SFM。
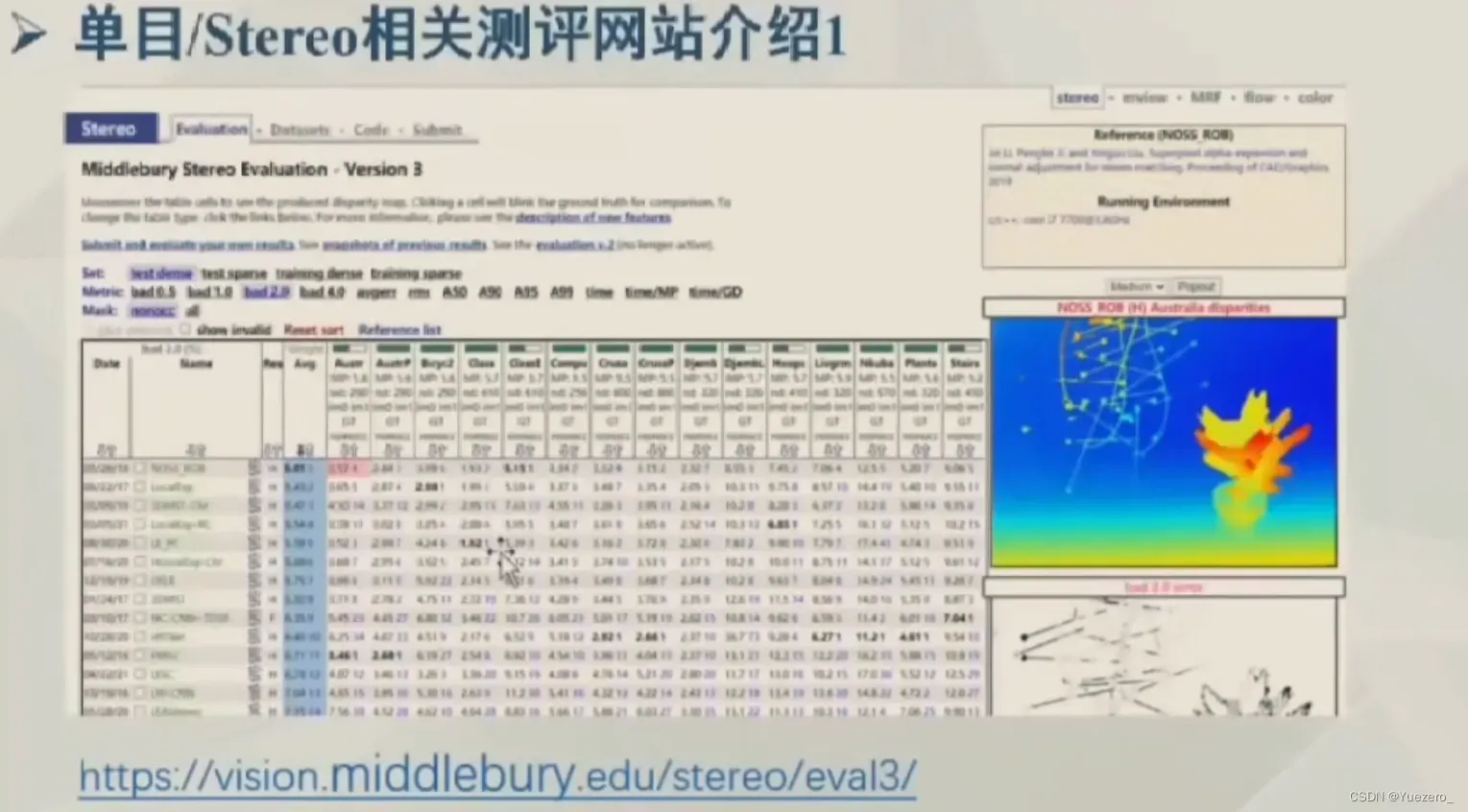
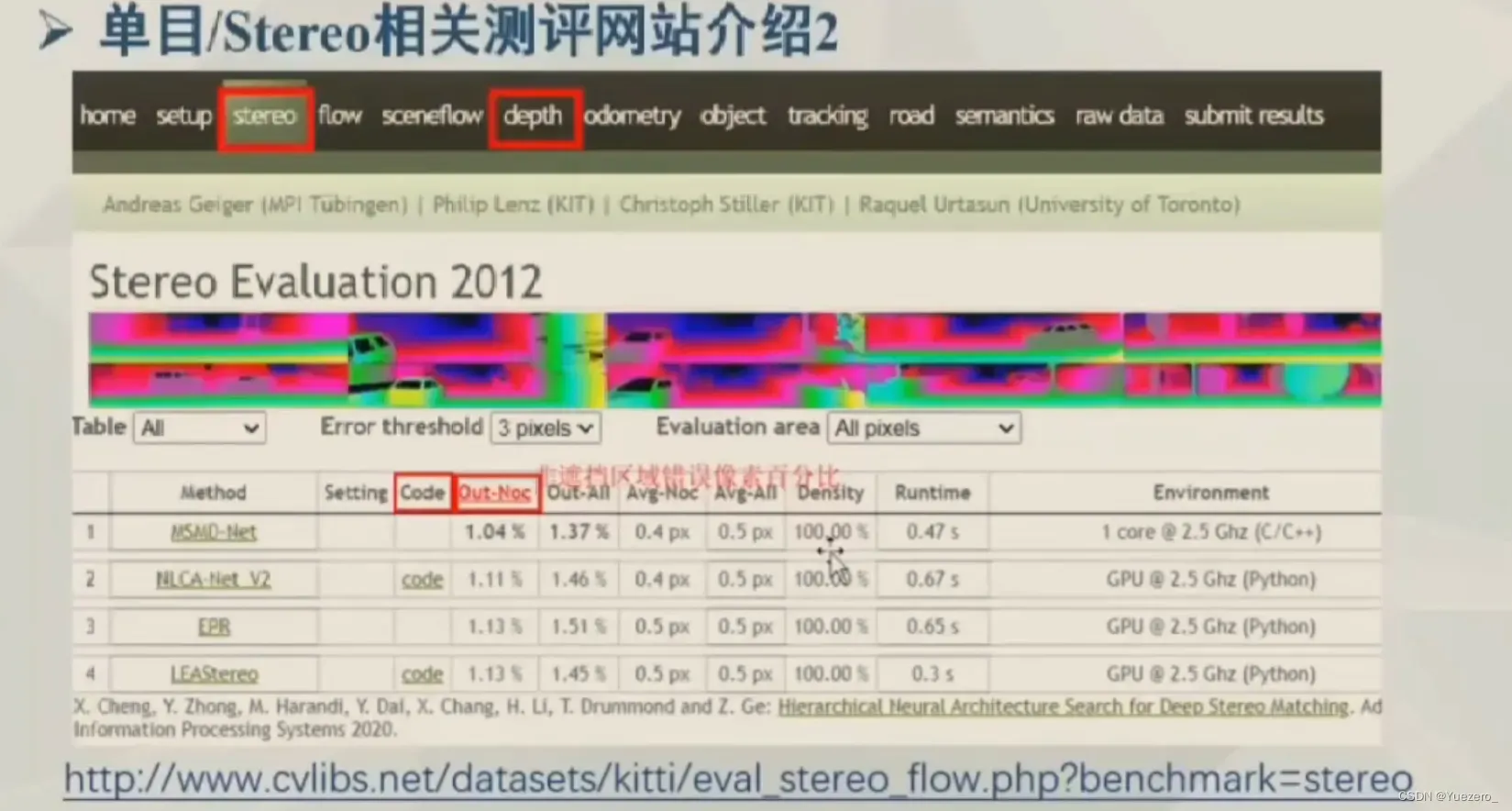
模型测评网站:
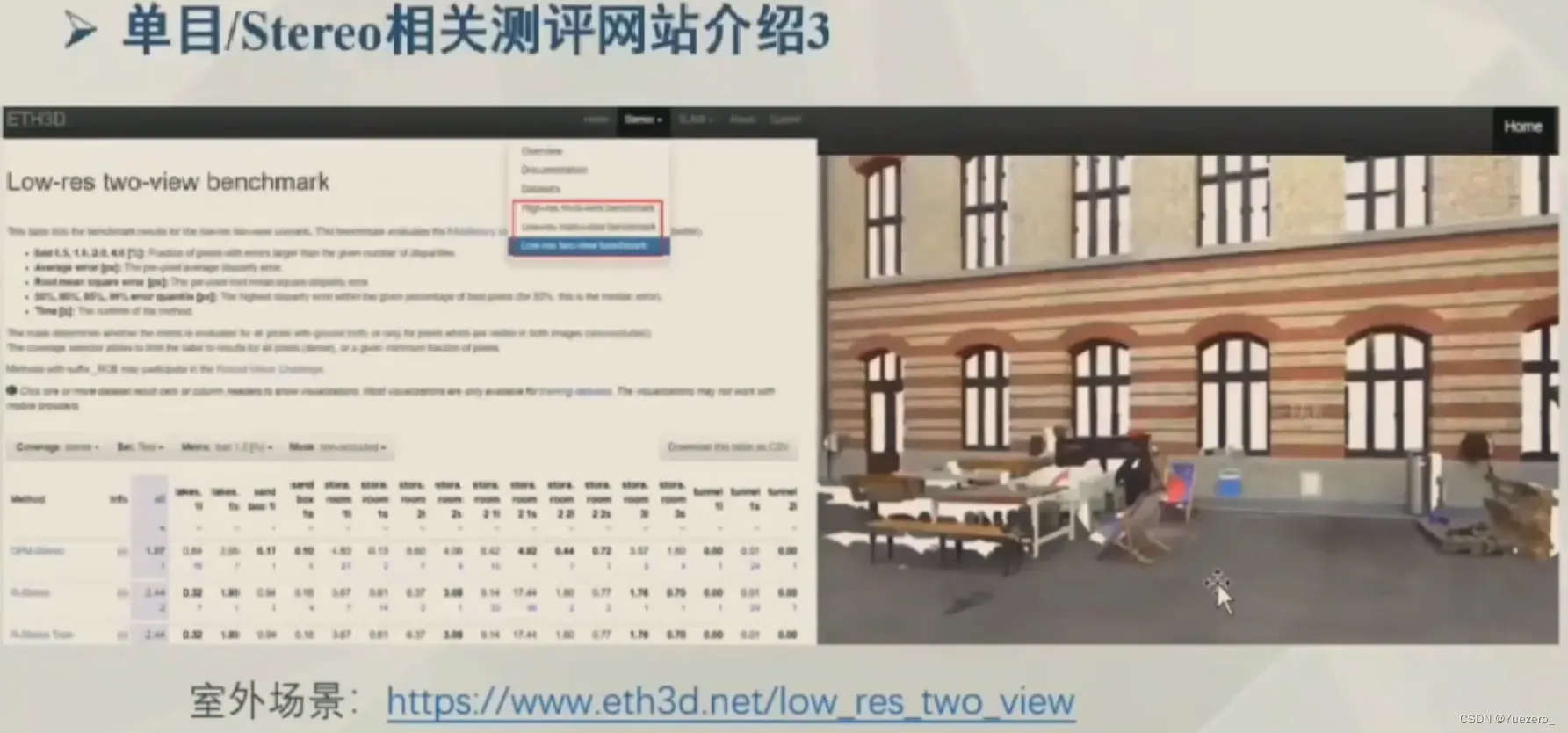

1 相机几何与标定
1.1 相机模型中的坐标系
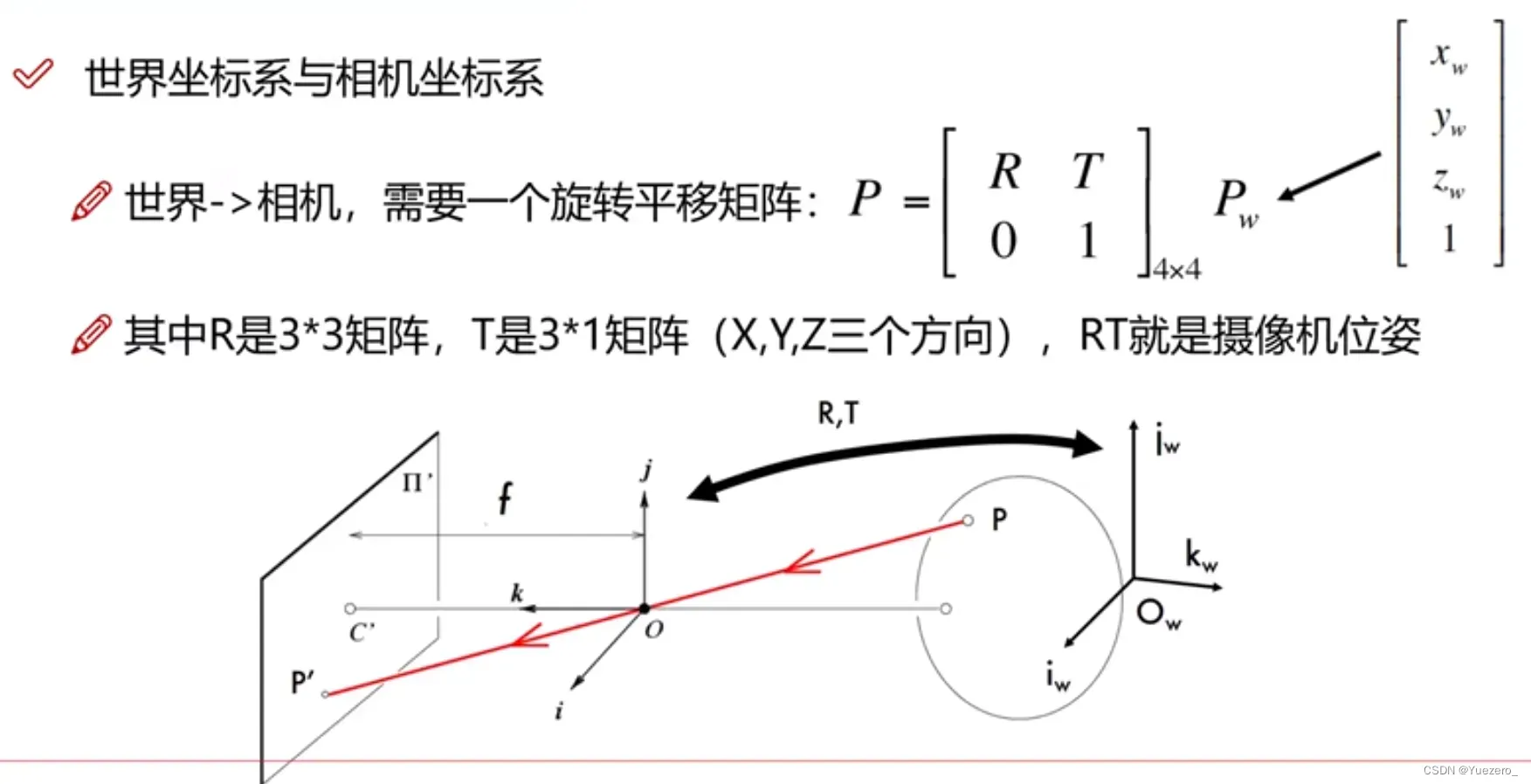
针孔相机模型存在4个坐标系:世界坐标系、摄像机坐标系、图像物理坐标系和图像像素坐标系。
光心:图像的中心。
光轴:穿过图像的光心,与图像平面垂直的轴。
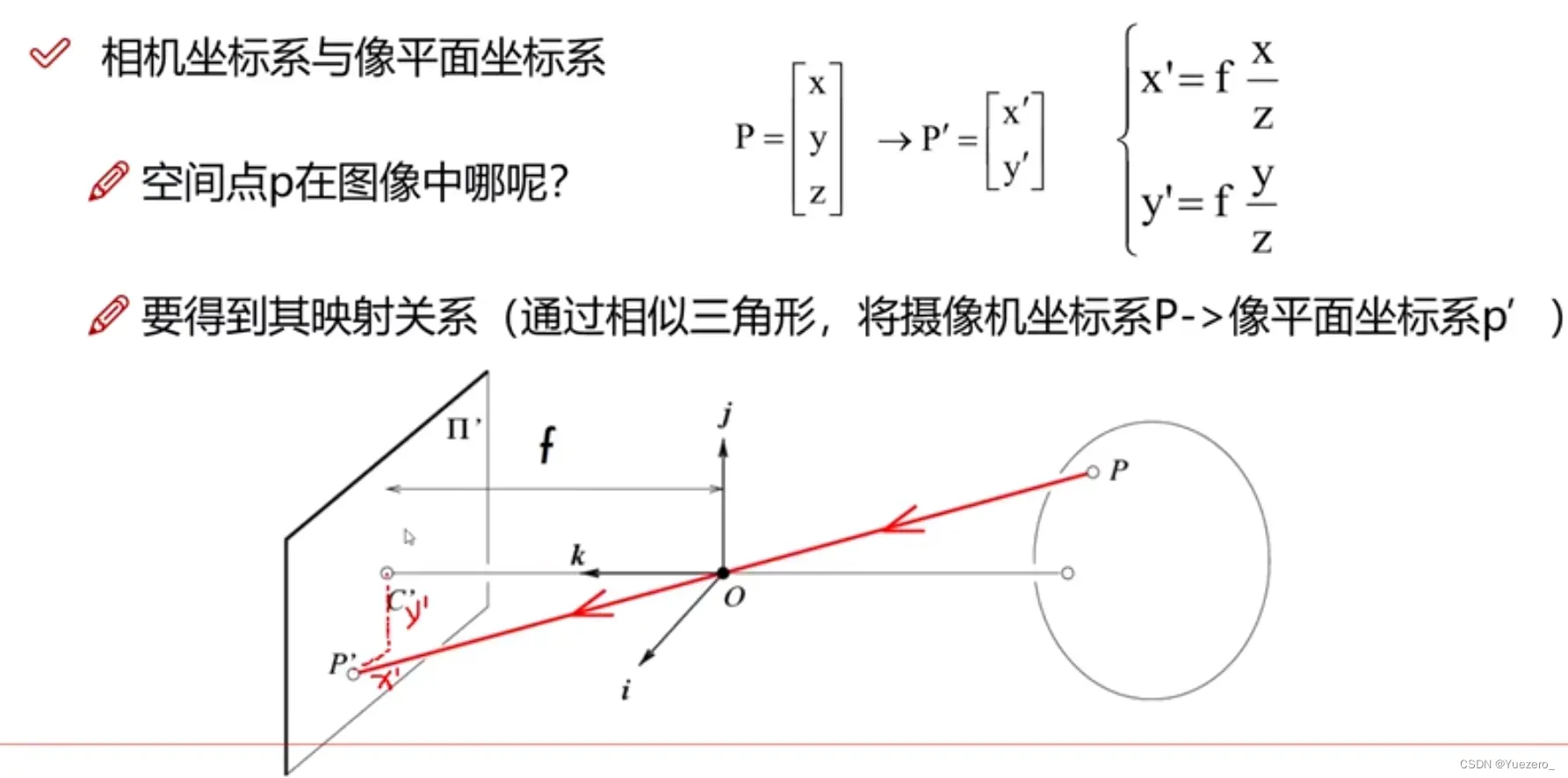
- 世界坐标系(x,y,z):是客观三维世界的绝对坐标系,也称客观坐标系,就是物体在真实世界中的坐标,世界坐标系是随着物体的大小和位置变化的,单位是长度单位
- 相机坐标系(x’,y’):以
相机的光心为坐标原点,以平行于图像的x和y方向为x轴和y轴,z轴和光轴平行,x, y,z互相垂直,单位是长度单位。
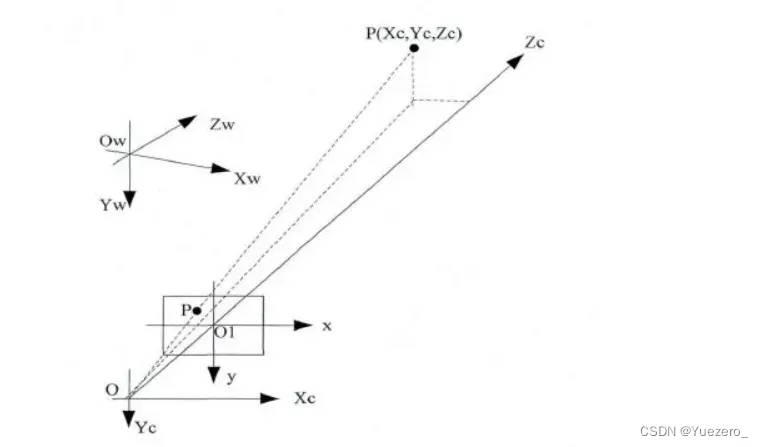
- 图像物理坐标系(X,Y):以
主光轴Zc和图像平面交点为坐标原点,x’和y’方向如图所示,单位是长度单位。 - 图像像素坐标系(Xc,Yc):以
图像的上/下/左/右顶点为坐标原点,u和v方向平行于x’和y’方向,单位是像素。(图像物理坐标系和像素坐标系仅通过平移可重合)
1.2 四种坐标系之间的转换
世界坐标系 -> 摄像机坐标系
从上面的坐标系介绍中我们可知世界坐标系和摄像机坐标系都是三维坐标系,而物体在三维空间中的位置变化只有两种,即平移和旋转,这个时候就用到我们的欧式变换了,即使原始坐标的齐次坐标乘以我们的欧式变换矩阵,就能得到最终的结果(使用欧式变换本质上就是为了实现矩阵相乘,齐次就是方便我们进行乘法)
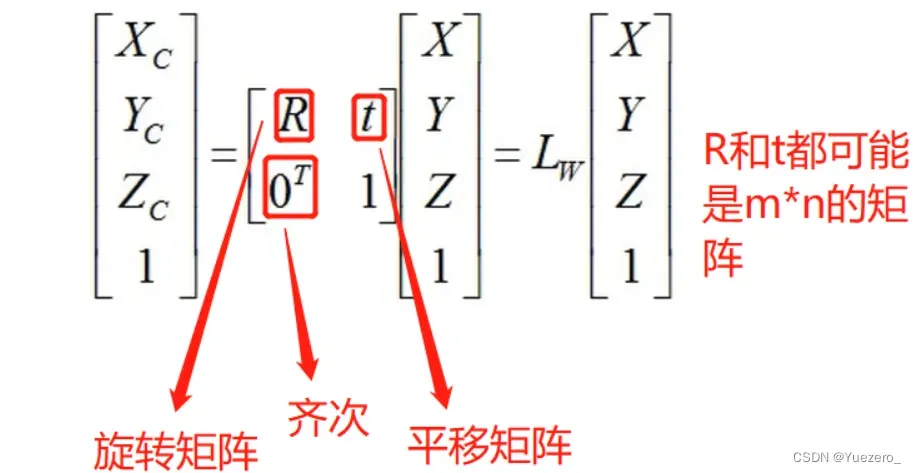
但是很多时候平移和旋转都不止进行了一次,在多次连续的平移和旋转的情况下,加入假如我们将向量a进行了两次欧式变换,旋转和平移分别为R1,t1和R2,t2。

摄像机坐标系 -> 图像物理坐标系
从摄像机坐标变换到图像物理坐标,我们利用了相似三角形的原理,根据相似三角形的性质列出对应的矩阵计算式,即可求出我们需要的结果,但是摄像机坐标是3维的,而现在要求的图像物理坐标是2维的,所以我们还是需要用到齐次坐标。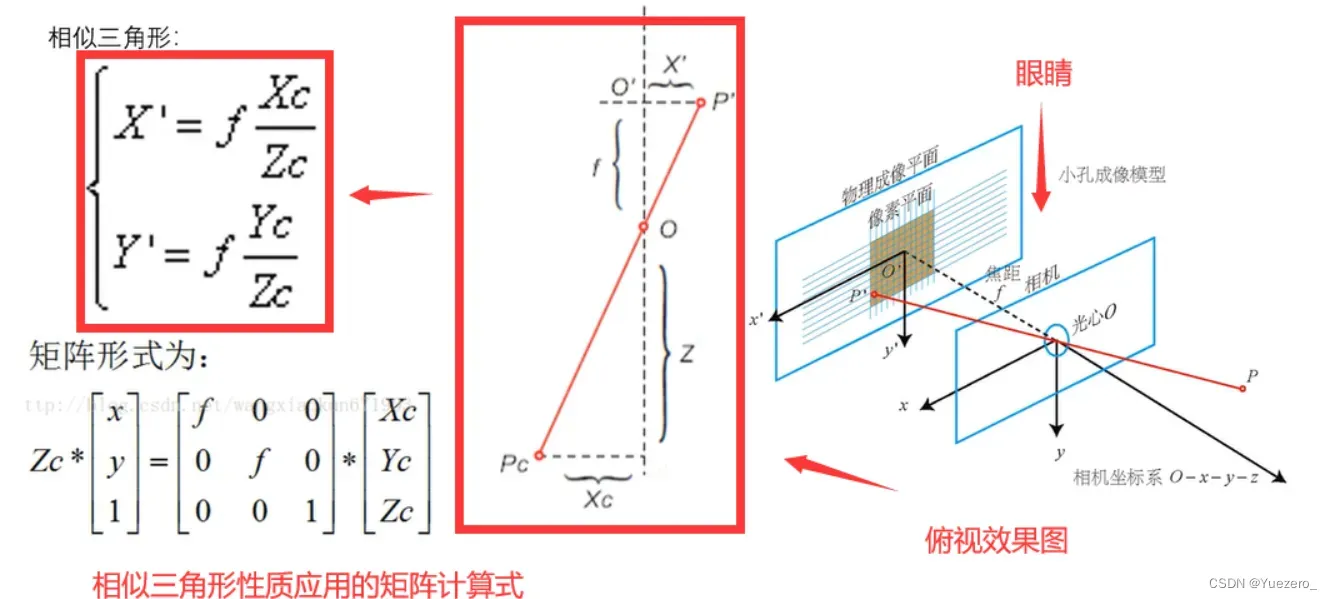
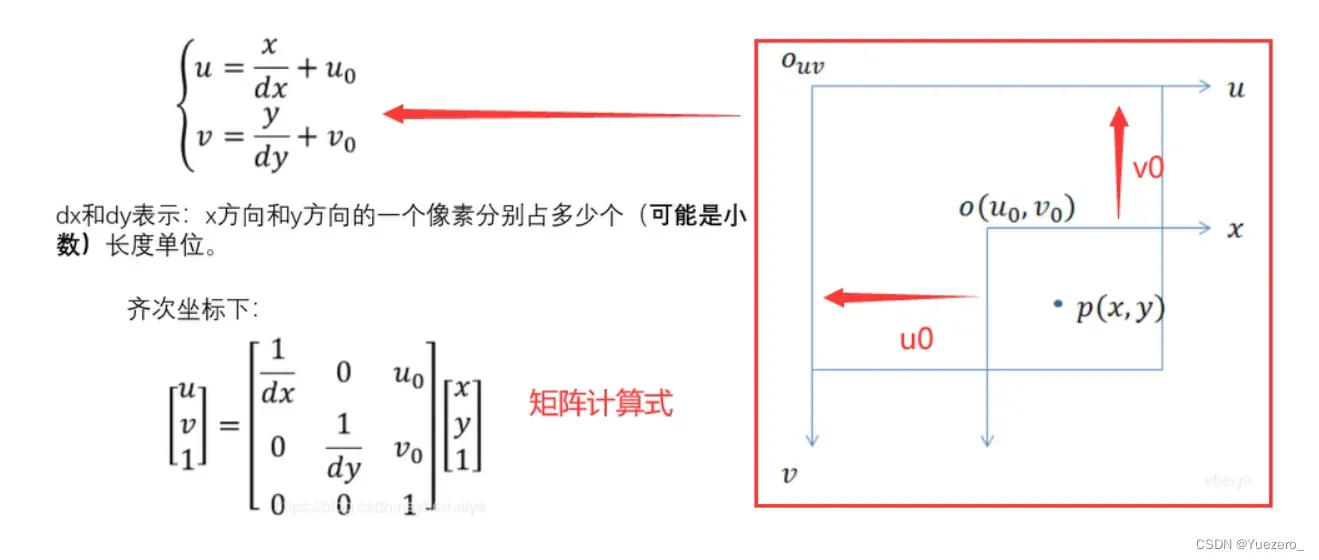
图像物理坐标系 -> 图像像素坐标系
图像物理坐标系与图像像素坐标系之间的转换其实就是单位转换和中心原点的转换,一个是中心点和长度单位,另一个是左上角和像素单位
1.3 相机内参
相机成像原理
这些坐标系转换过程(世界->相机->物理->像素)就是相机的成像原理,相机坐标系是中间商。
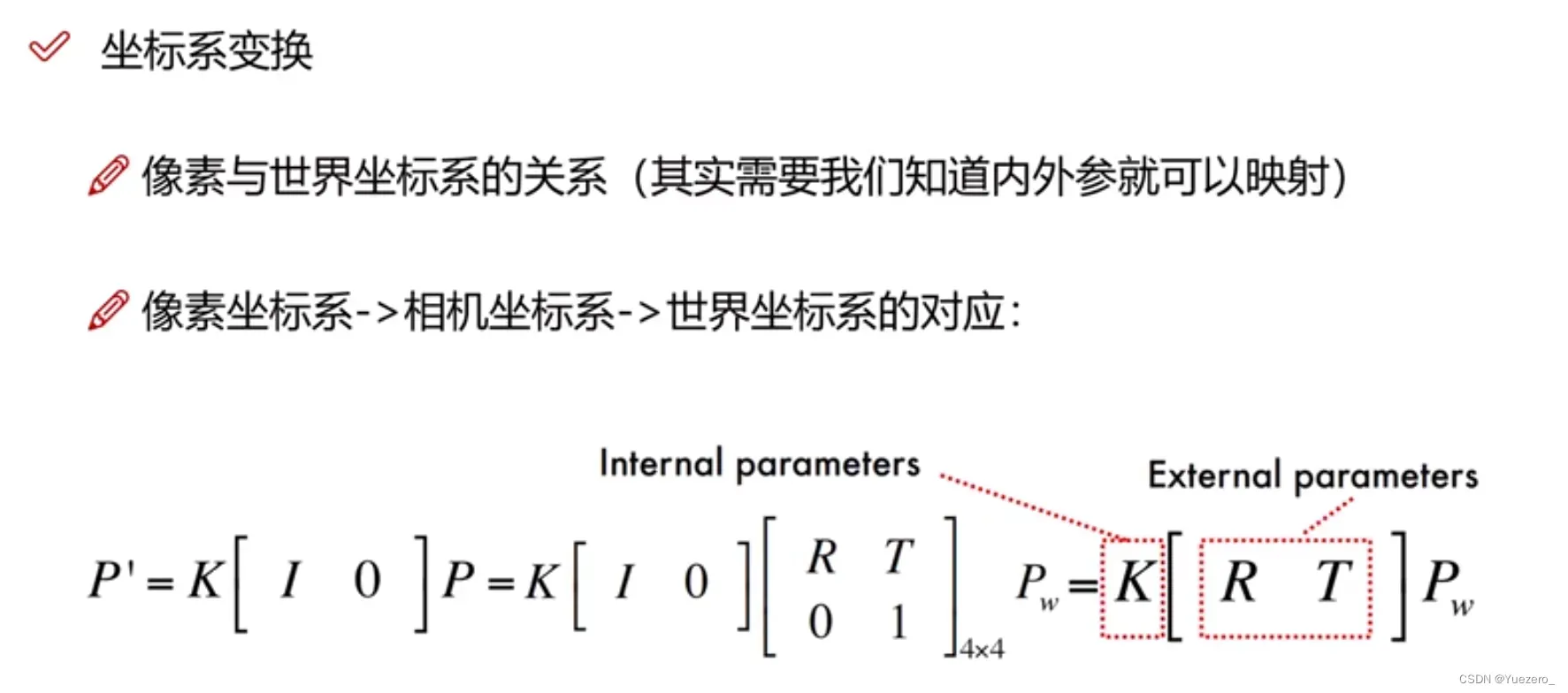
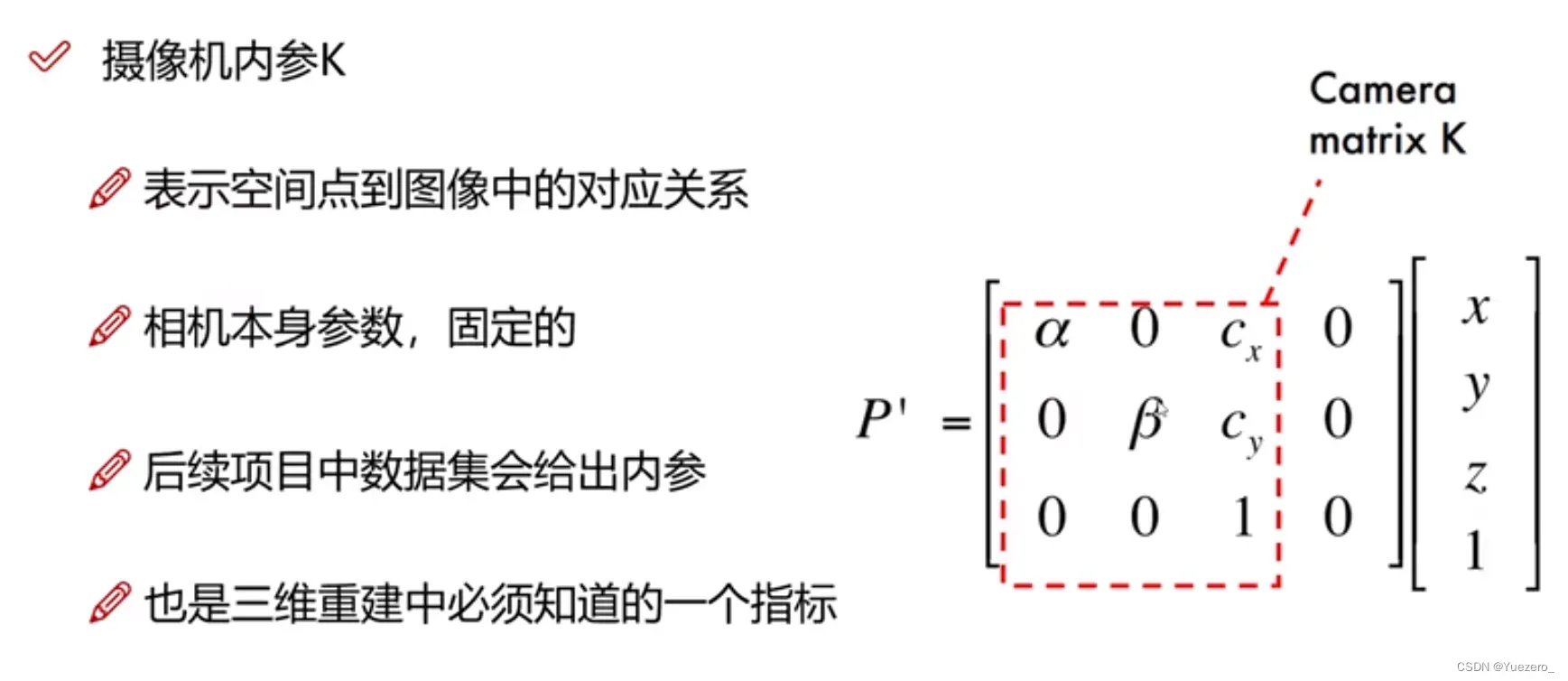
相机内参K: 相机坐标系<->像素坐标系的齐次转换矩阵,由相机本身决定。
相机外参RT:旋转平移矩阵,世界坐标系<->相机坐标系,外参由视角决定。
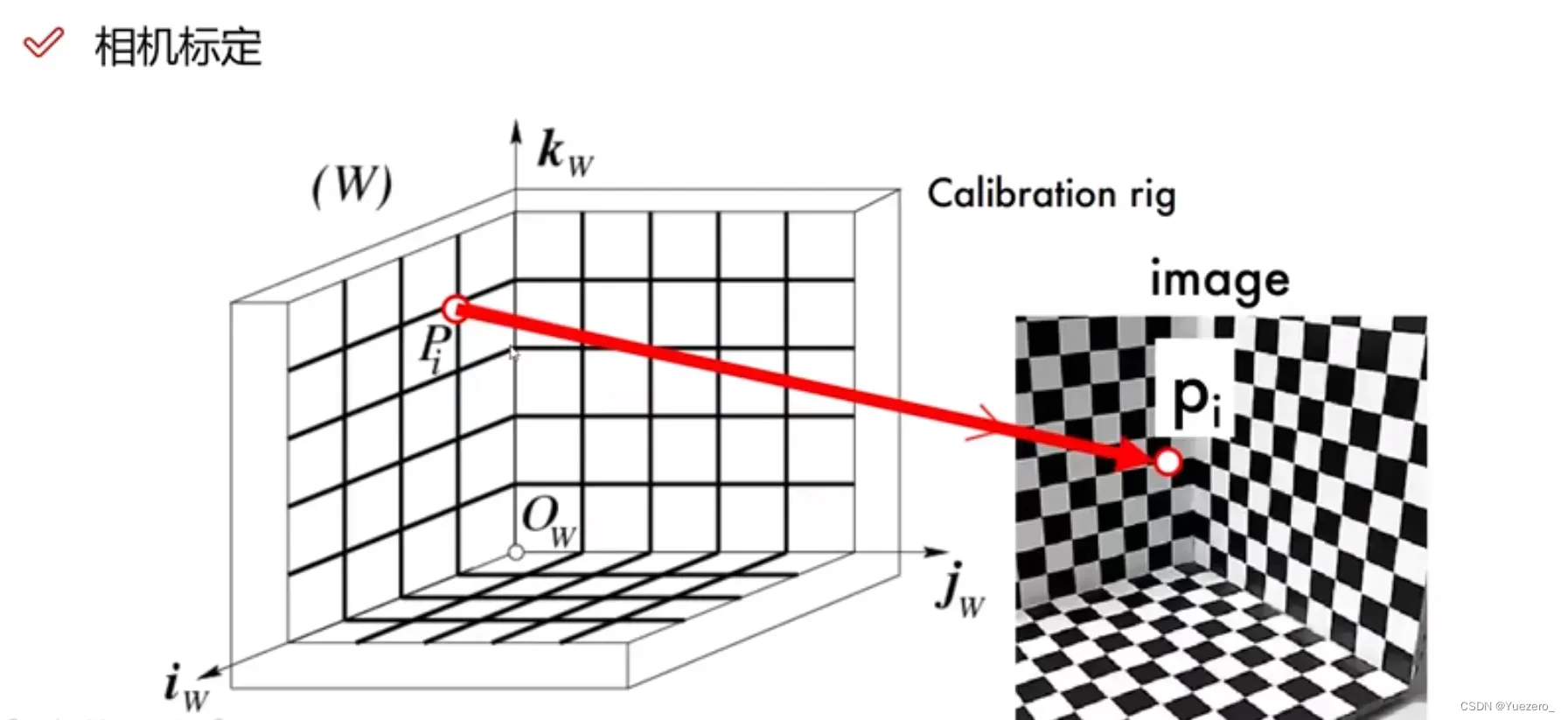
1.4 相机标定
获取相机内参和外参的方法就是相机标定,找到很多对儿点的世界坐标系和像素坐标系的对应关系,求解内外参。

2 传统三维重建
2.1 RGBD三维重建
深度相机(RGB-D Camera): 可以直接获取被测对象的三维信息 (深度图)的相机。
深度相机具有一个RGB相机和一个深度传感器,相比于单独使用深度传感器有如下优势:首先可以显示场景的RGB图像让人们有更直观的认知;其次可以将点云配准和二维图像特征点匹配相结合提高配准精度;最后可以将彩色值用于纹理贴图使重建模型具有颜色属性,增加重建的真实度和还原度。
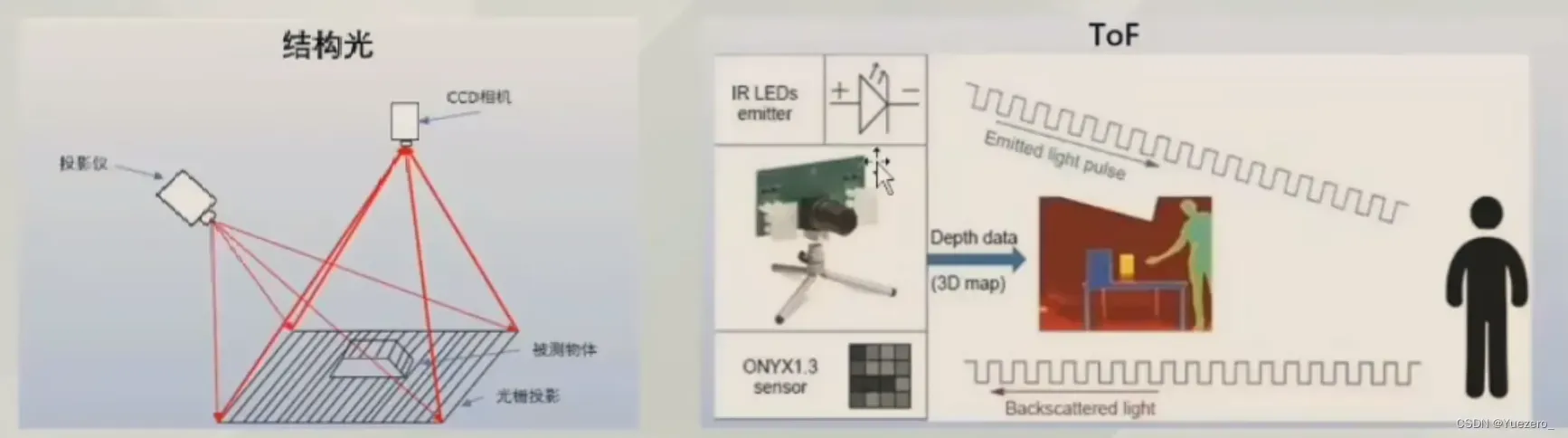
深度相机主要分为结构光和ToF:目前比较主流的就是TOF相机,以Kimect为例Kinect v1是采用结构光方案,Kinect v2采用TOF方案。
经典RGBD三维重建算法:

2.1.1 KinectFusion

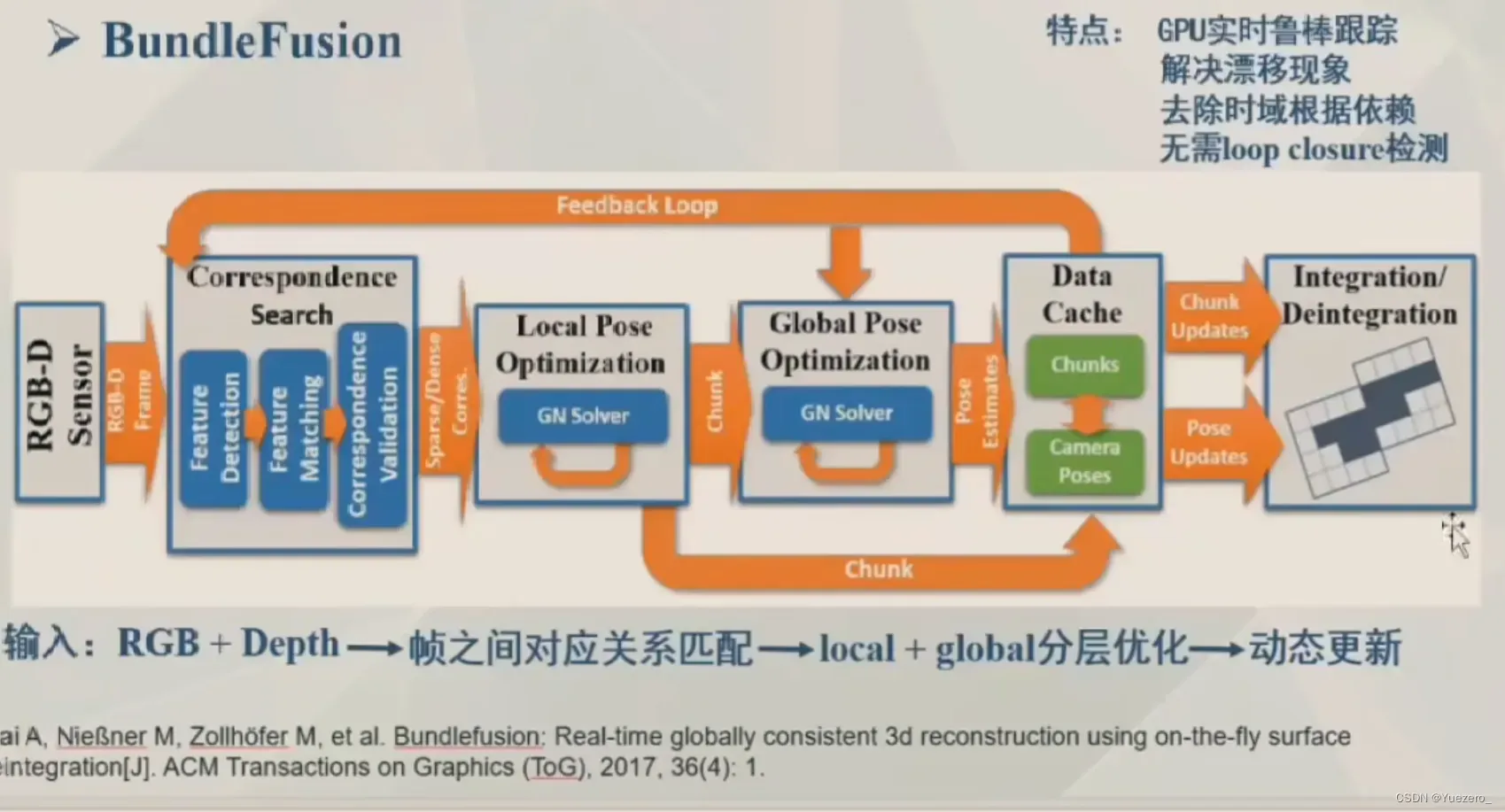
2.1.2 BundleFusion
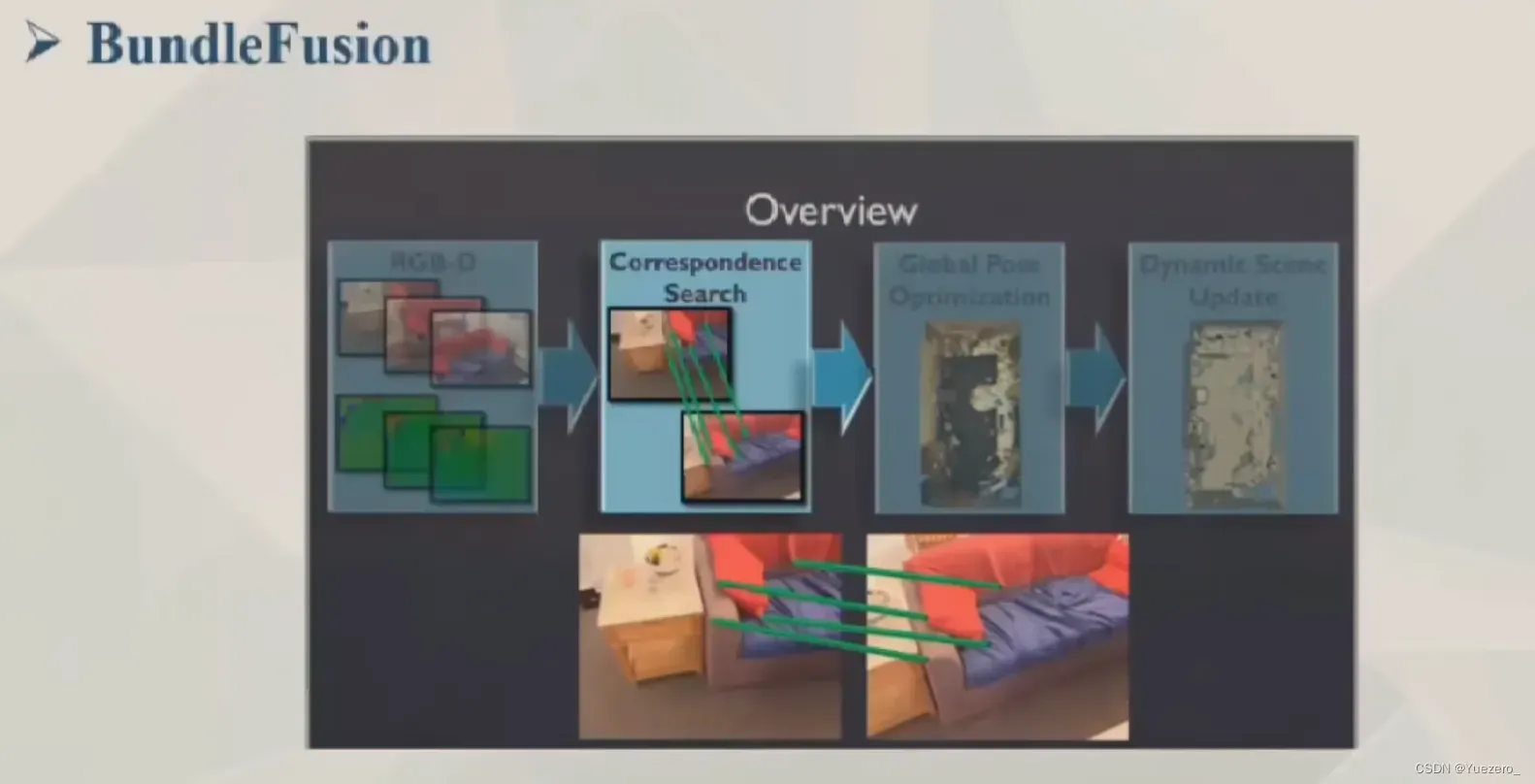
2.1 MVS三维重建
多角度重建(Multi-View Stereo, MVS): 从一系列不同角度的RGB图像中重建3D模型,即基于纯RGB的建模(刚体重建)。
经典开源框架:
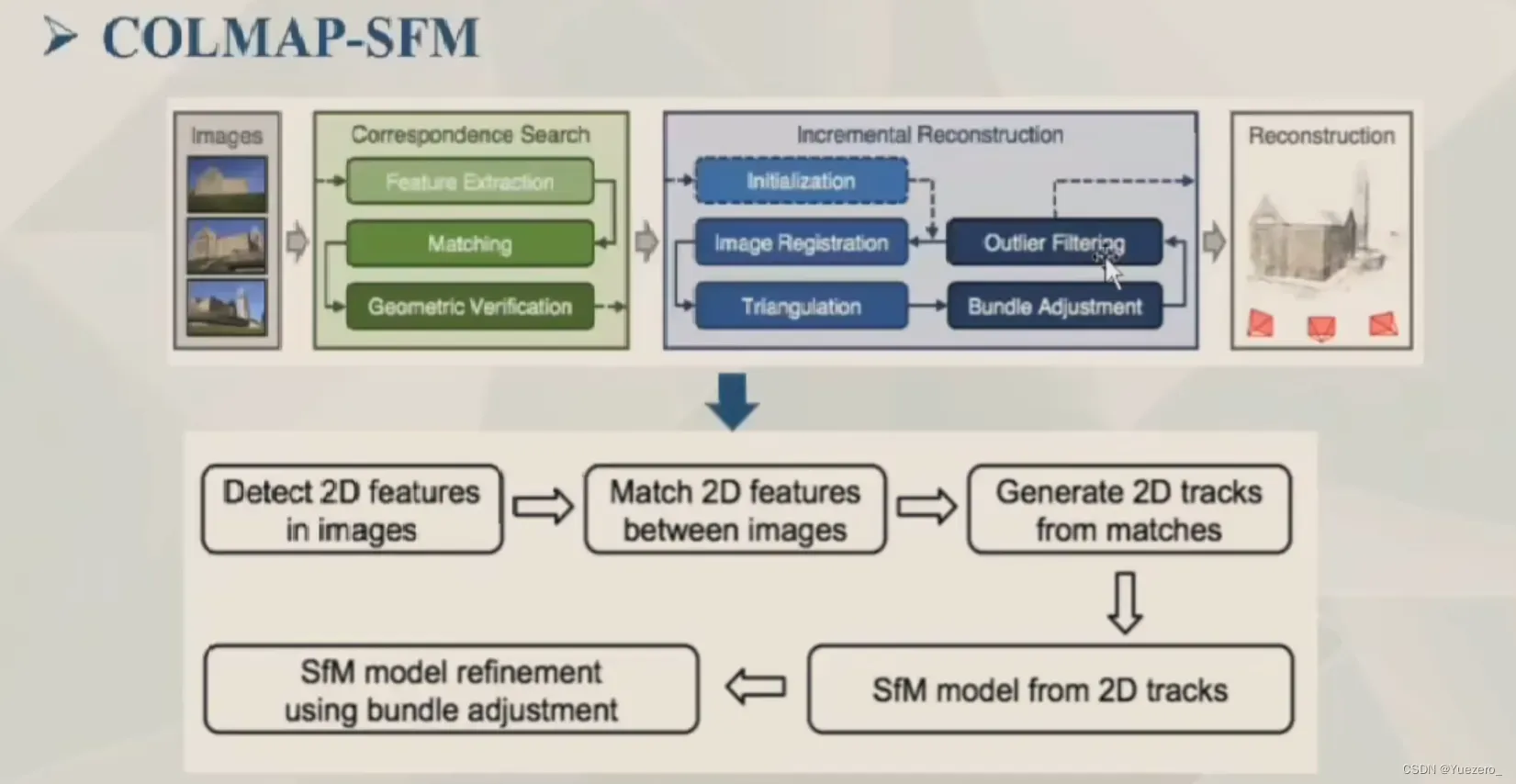
位姿计算: COLMAP, MVE, OpenMVG, Slam等;
MVS: COLMAP, MVE, PMVS, SMVS, OpenMVS等;
综合性能效果等,目前比较好的重建方案: COLMAP + OpenMVS
经典必读论文:
综述: Multi-View Stereo: A Tutorial
MVS开源框架测评:Tanks and Temples: Benchmarking Large-Scale Scene Reconstruction
2.2.1 COLMAP

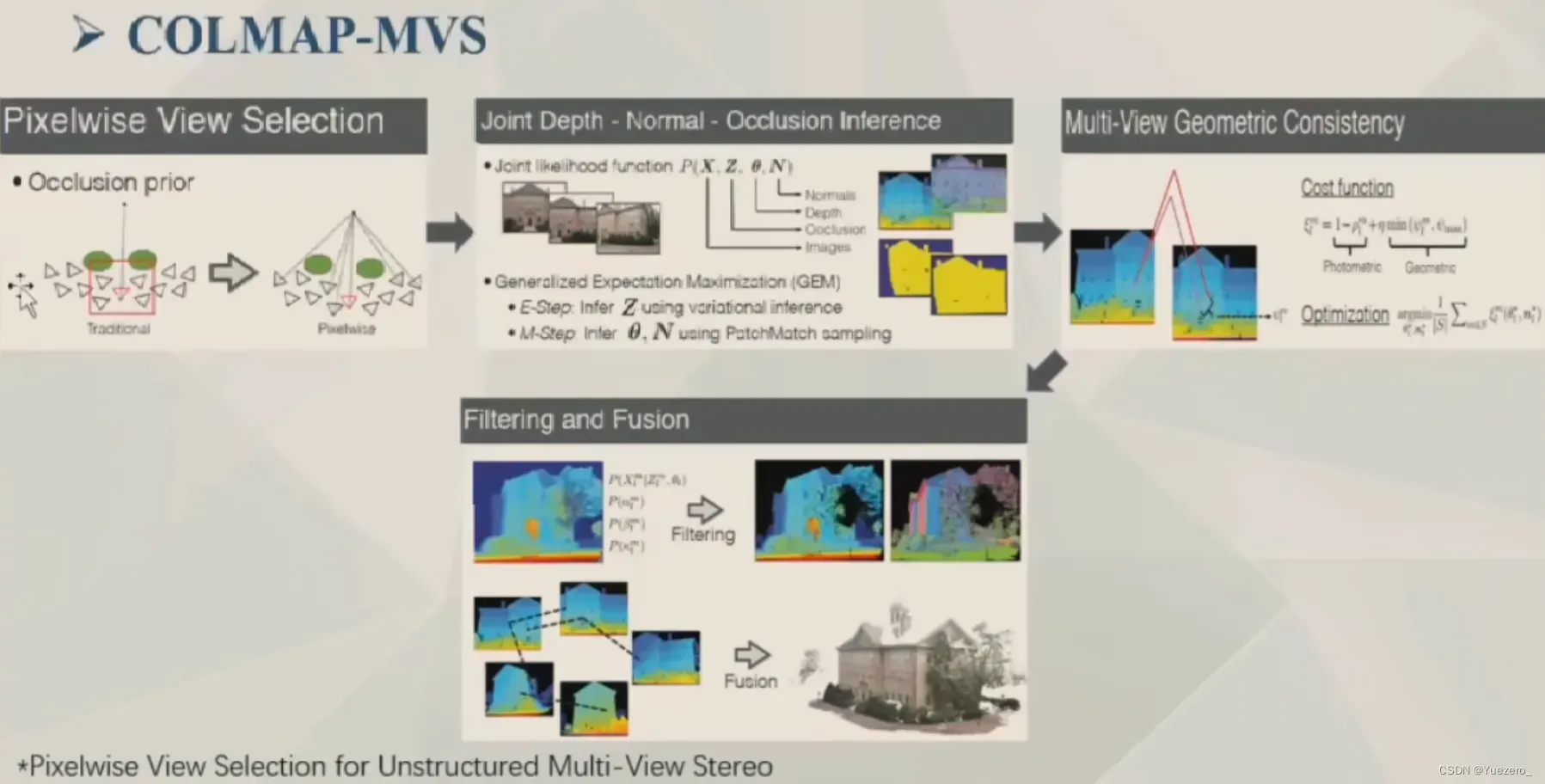
2.2.2 OpenMVS
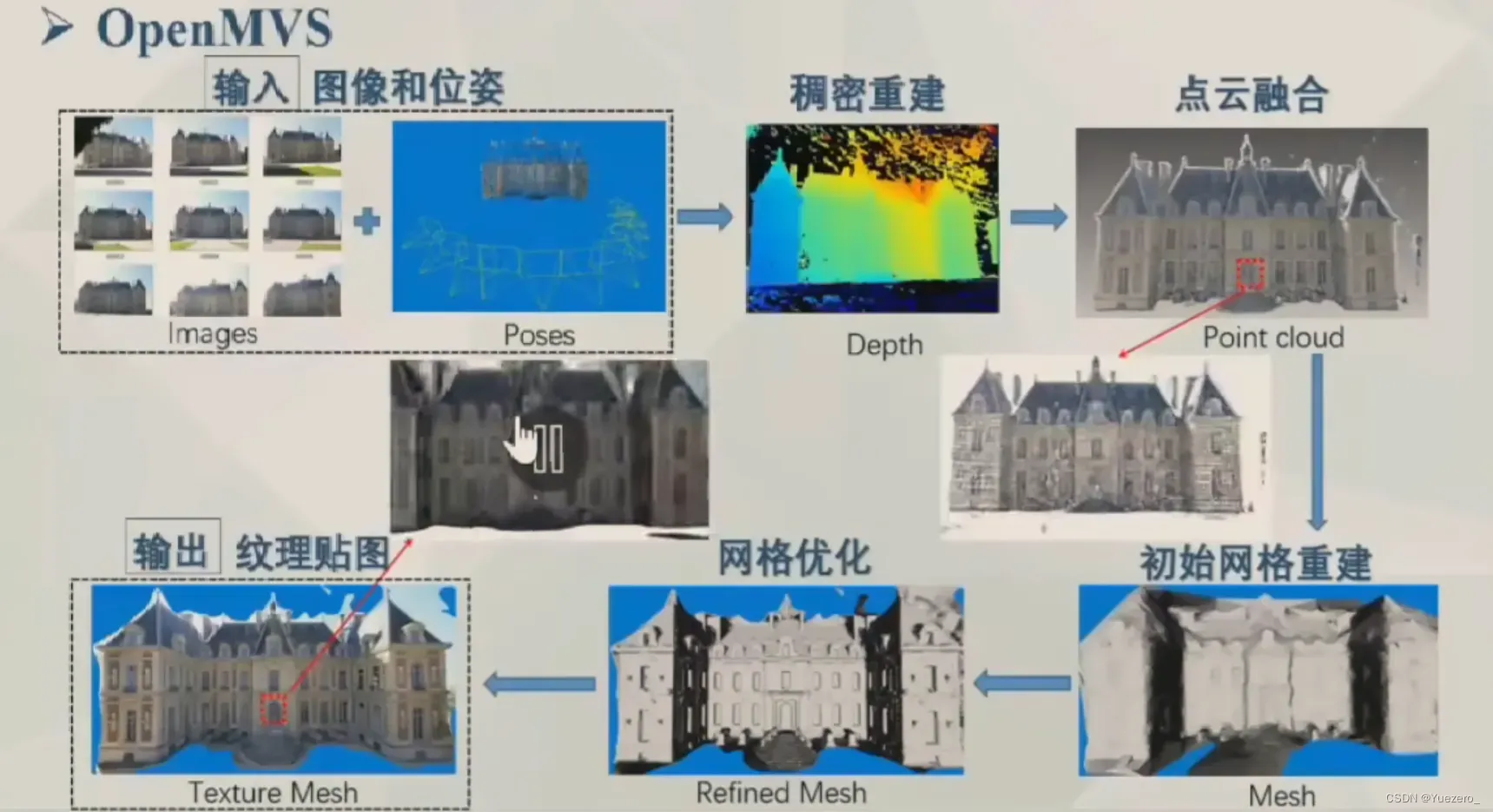
3 点云三维重建
3.1 3D点云任务
5大任务:
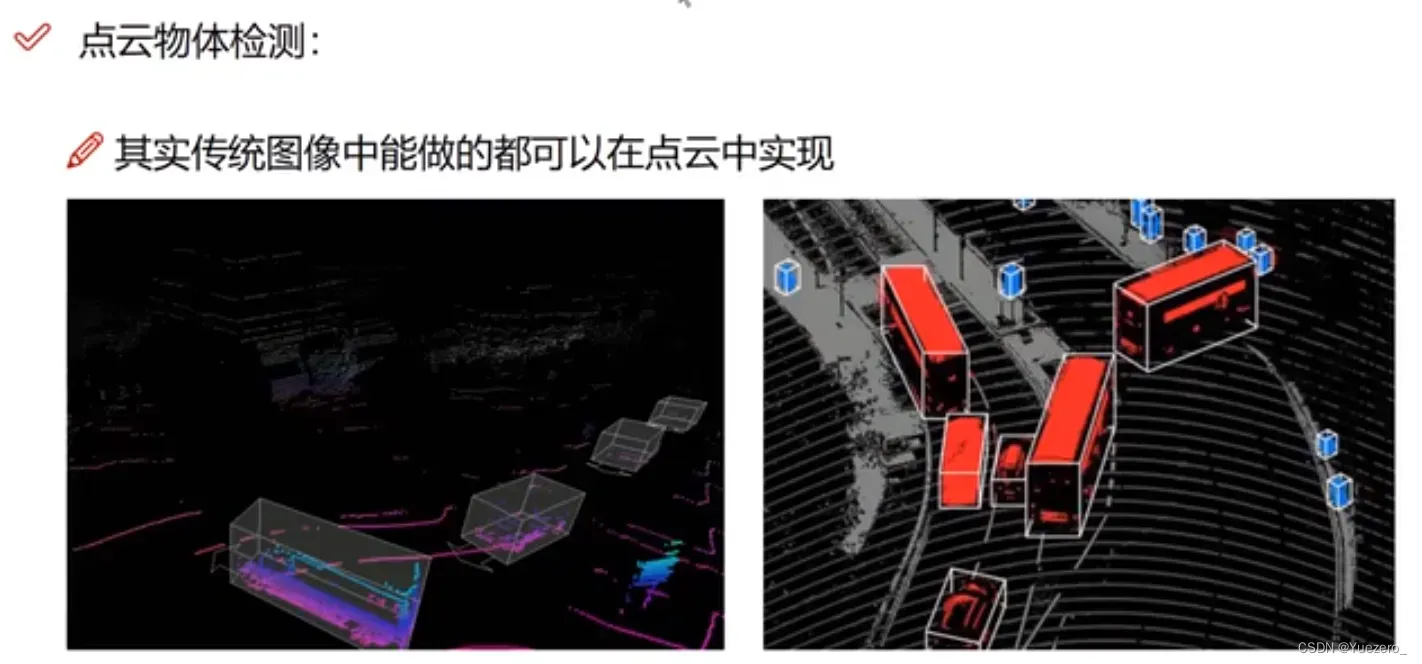
- 点云检测(定位+分类):点云物体定位+分类,同二维。
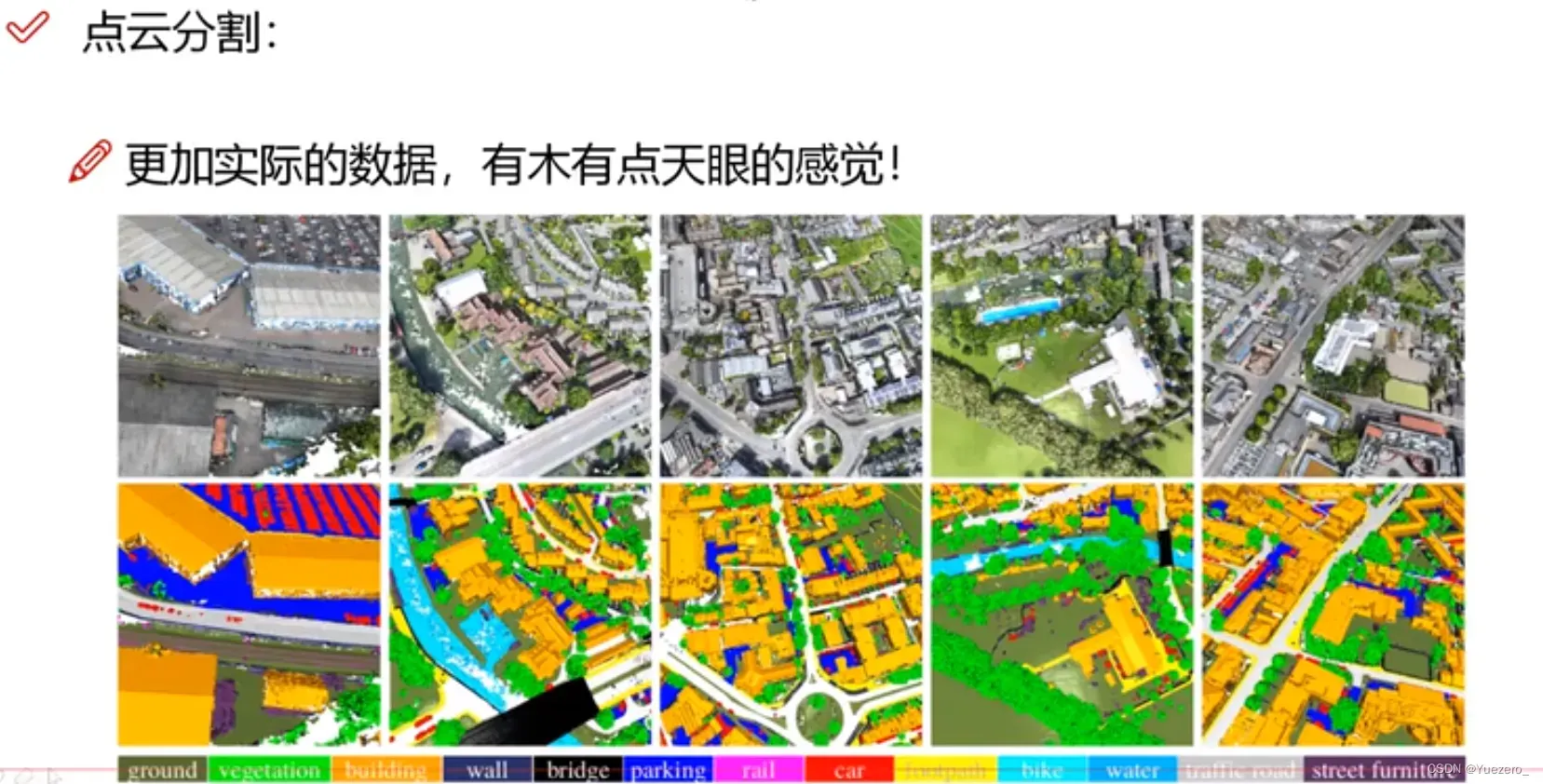
 – 点云分割(部位解析,语义分割):部位解析是对同一类物体的不同部位进行点分类,语义分割是对不同物体进行点分类。
– 点云分割(部位解析,语义分割):部位解析是对同一类物体的不同部位进行点分类,语义分割是对不同物体进行点分类。
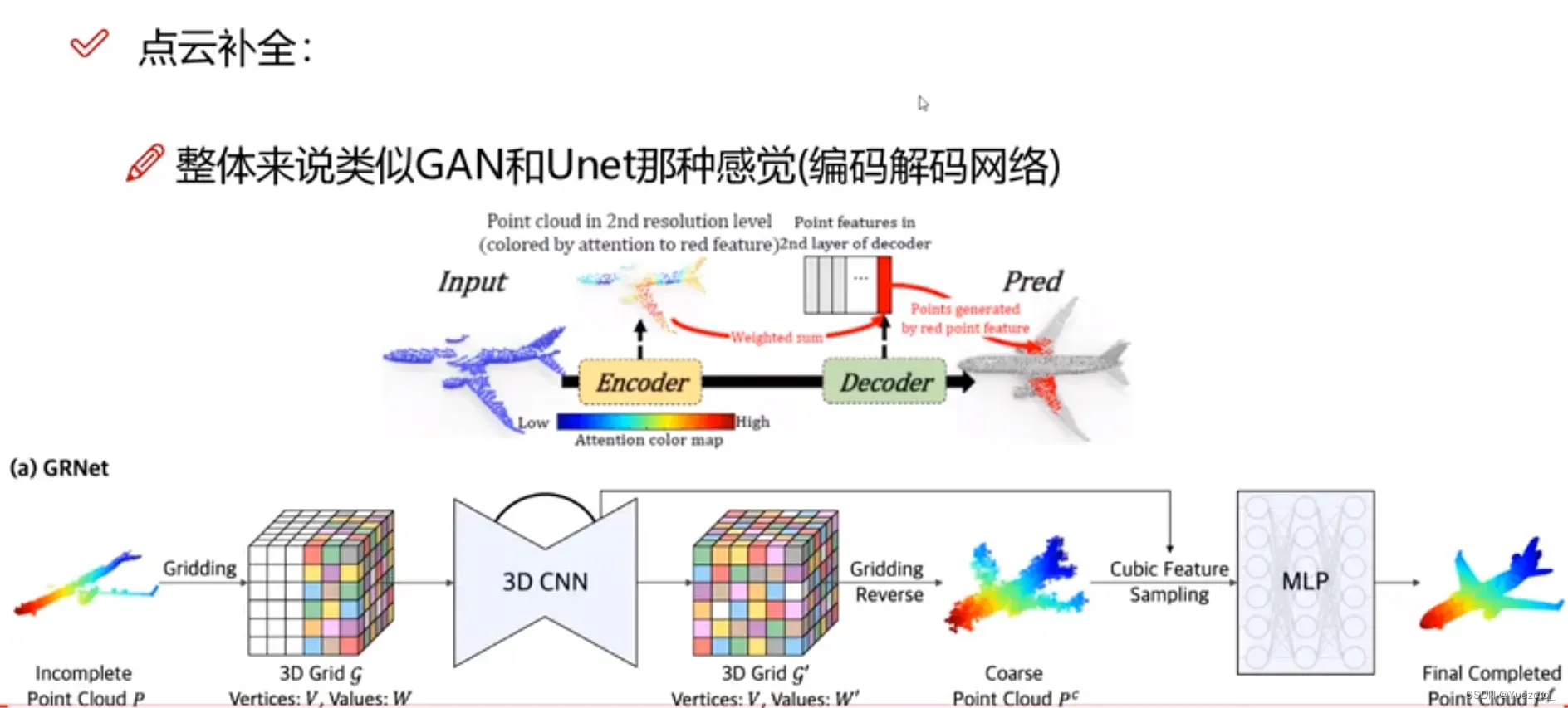
- 点云补全:由于近密远疏,将边缘稀疏的点云密集化。
 – 点云生成:将原始的视频/图像转换为点云。
– 点云生成:将原始的视频/图像转换为点云。 – 点云配准:完成不同视角的数据对齐,用于三维重建。
– 点云配准:完成不同视角的数据对齐,用于三维重建。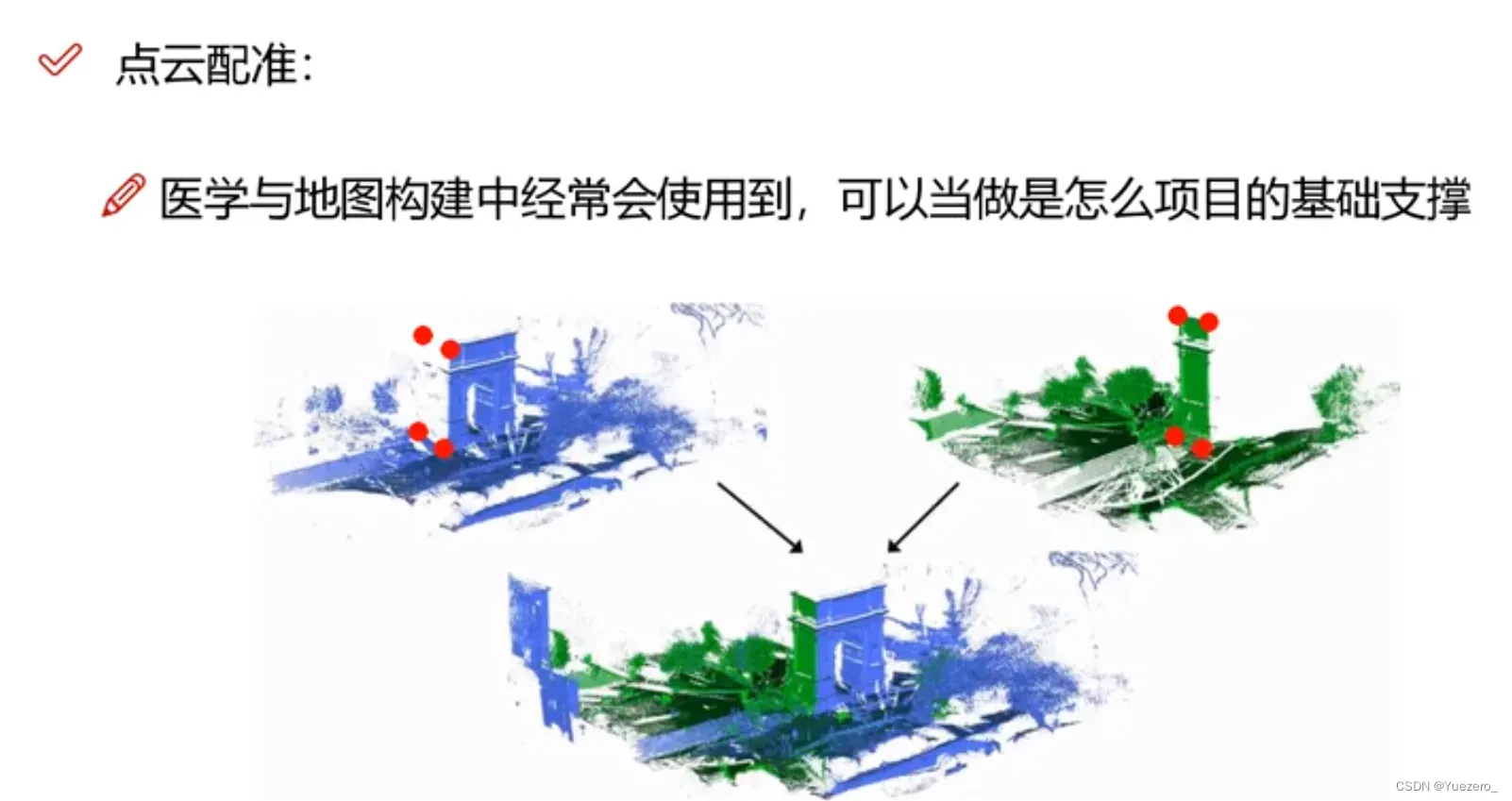
3.2 点云数据
3D点云由激光雷达扫描得到,每个样本包含n个点的(x,y,z)坐标和(Nx,Ny,Nz)法向量数据,是一个nx6的txt,每行表示一个点。
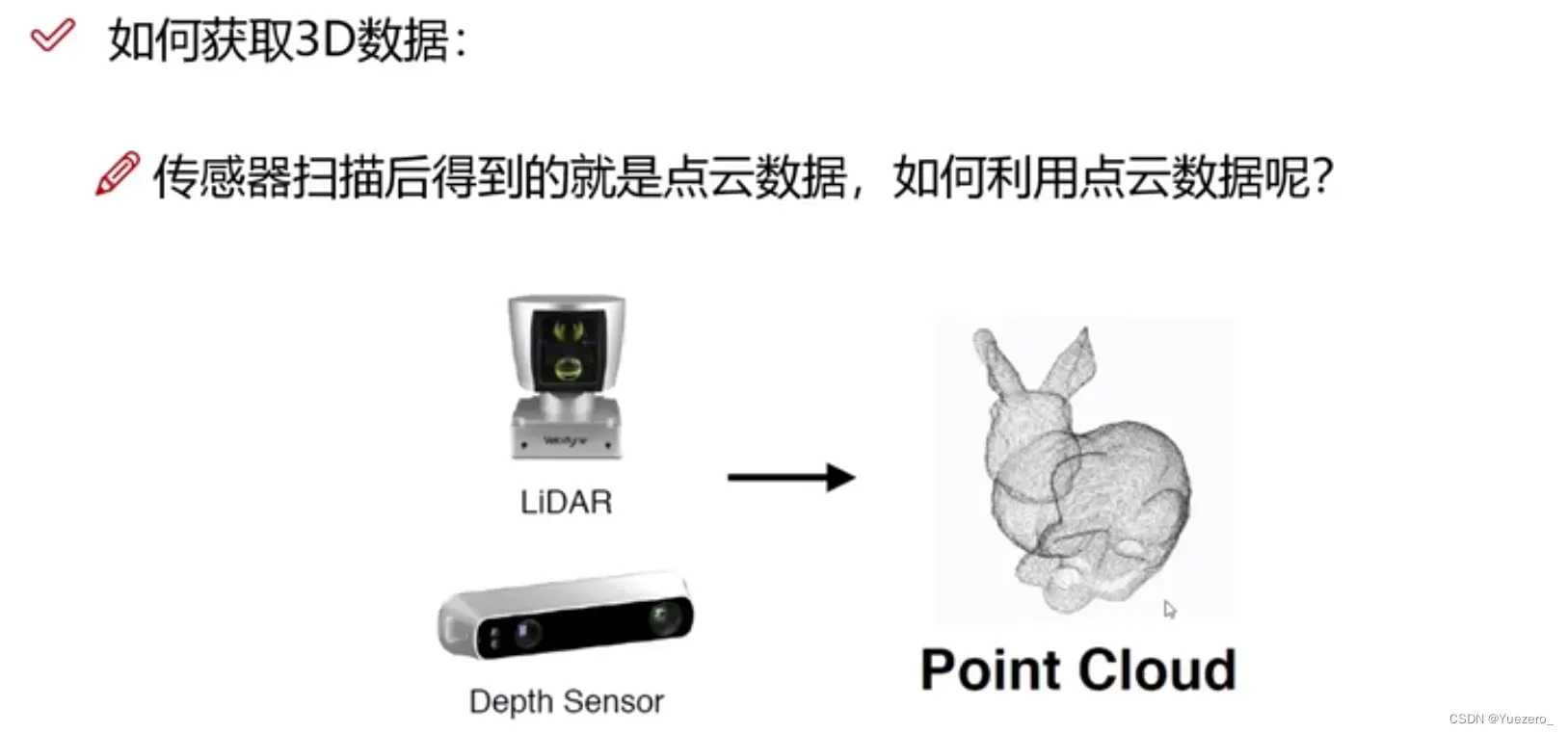
特性:无序性、近密远疏、非结构化。

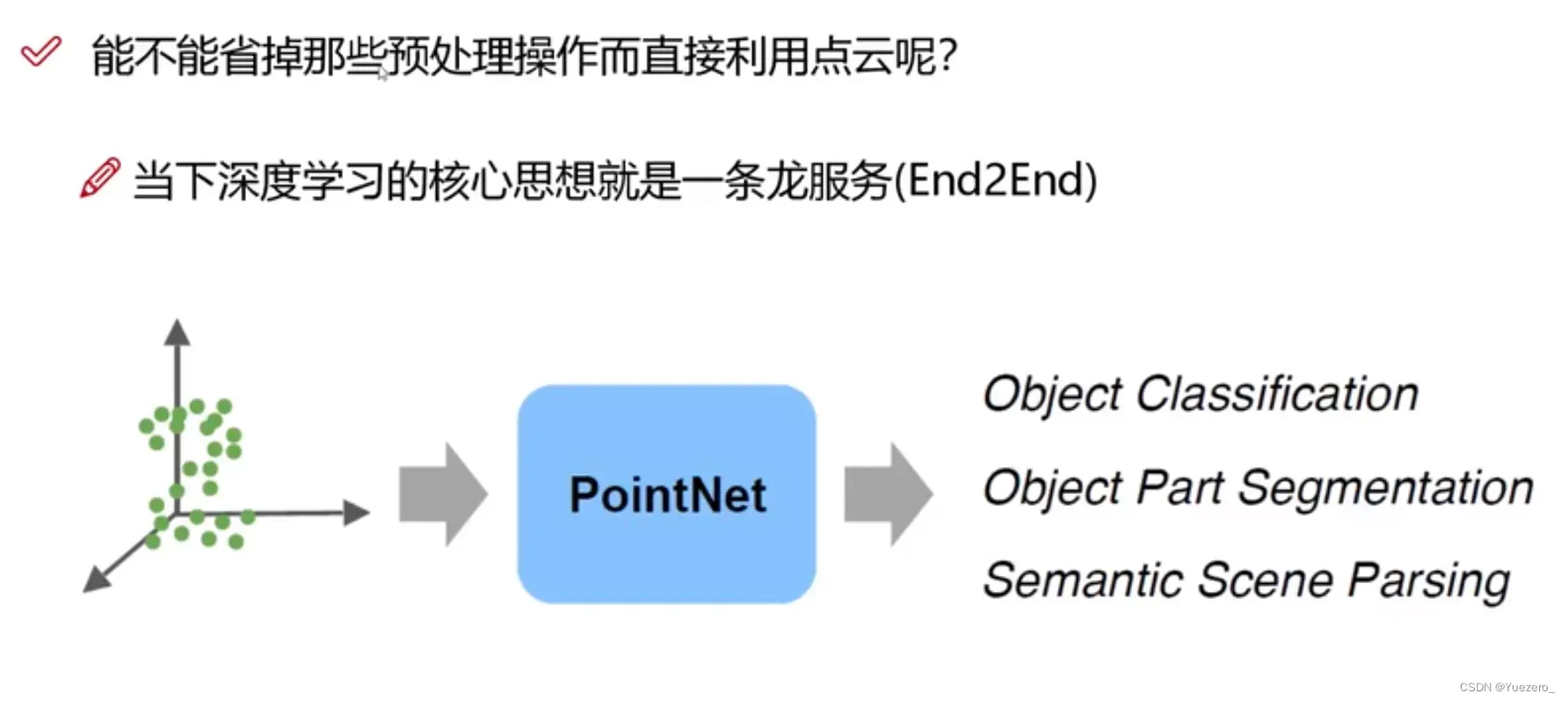
3.3 特征提取
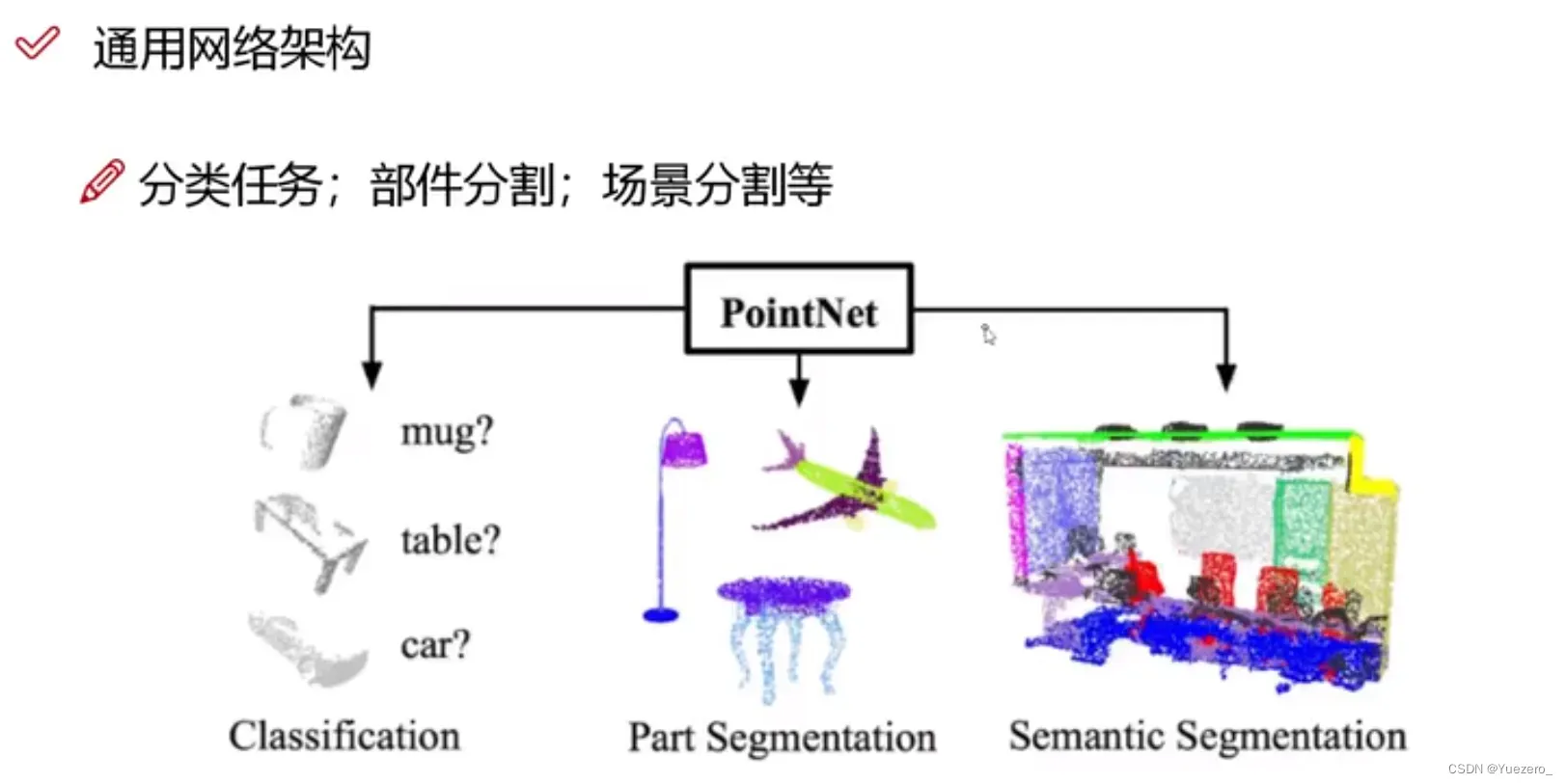
3.3.1 PointNet
点云无序性->置换不变性(MLP升维+max)


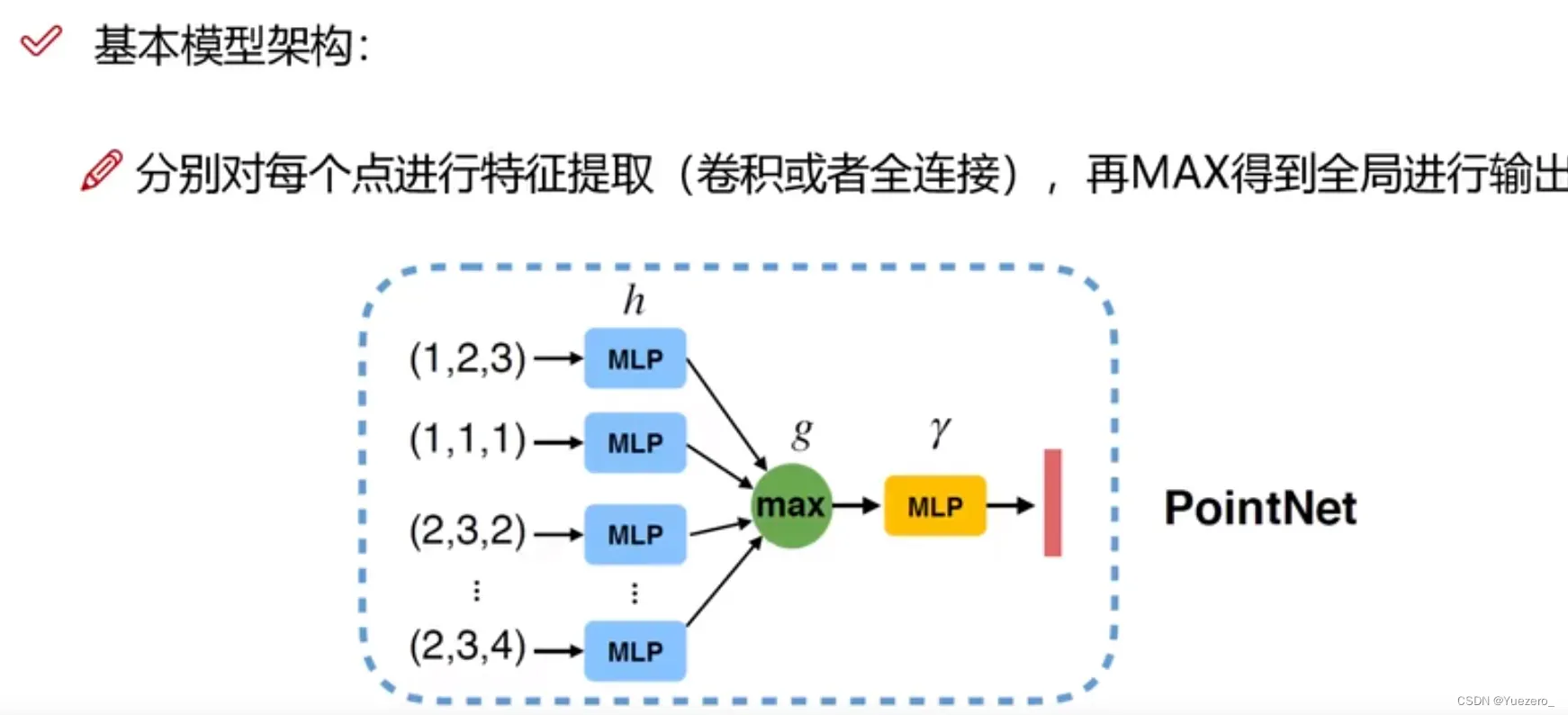
网络架构:
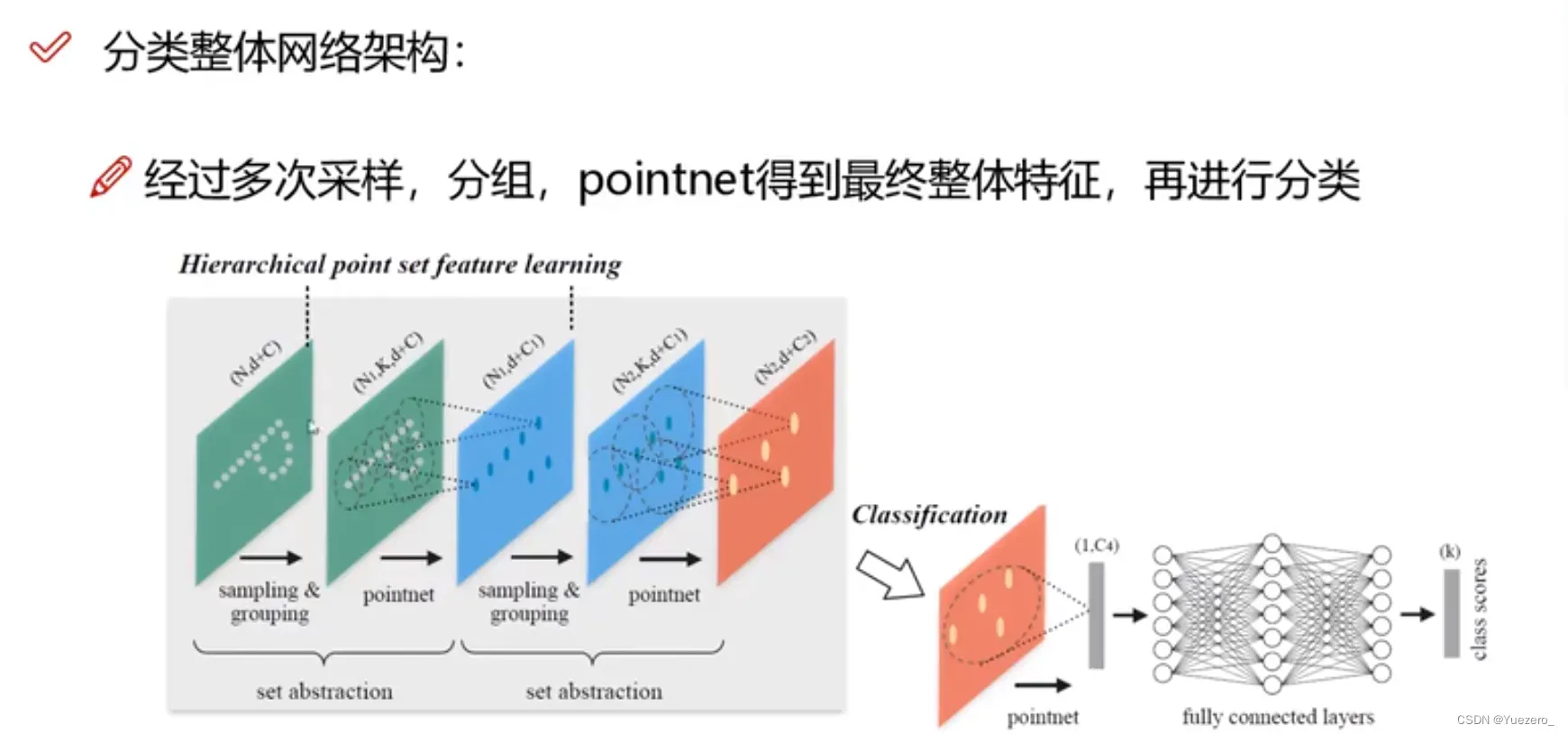
分类网络(全局特征->全局分类):输入n x 3(x,y,z)的点云信息,进行T-Net转化,对n个点分别进行MLP升维(3-> 64-> 128-> 1024),然后对n个点进行maxpooling(nx1024 -> 1x1024),得到全局特征,实现置换不变性,最后进入MLP(FC)进行k分类(1xk:此样本对应k个类的概率)。
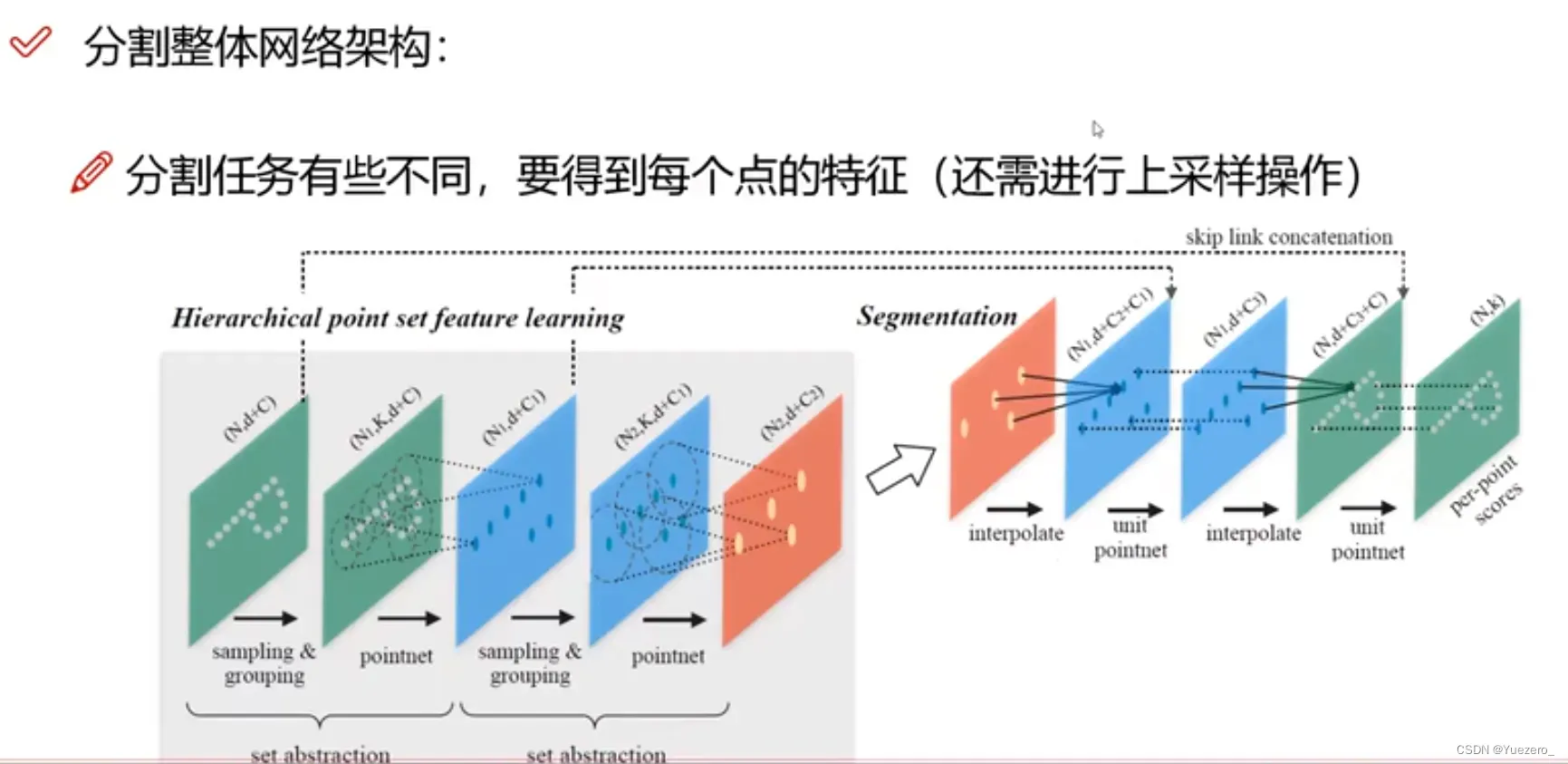
分割网络(各点特征->单点分类):输入n x 3(x,y,z)的点云信息,进行T-Net转化,对n个点分别进行MLP升维(3-> 64-> 128-> 1024),然后对n个点进行maxpooling(nx1024 -> 1x1024),得到全局特征,实现置换不变性,接着将nx64的各点特征与全局特征concat拼接,最后经过几个MLP(FC)进行单点m分类(nxm:此样本中n个点对应m个类的概率)。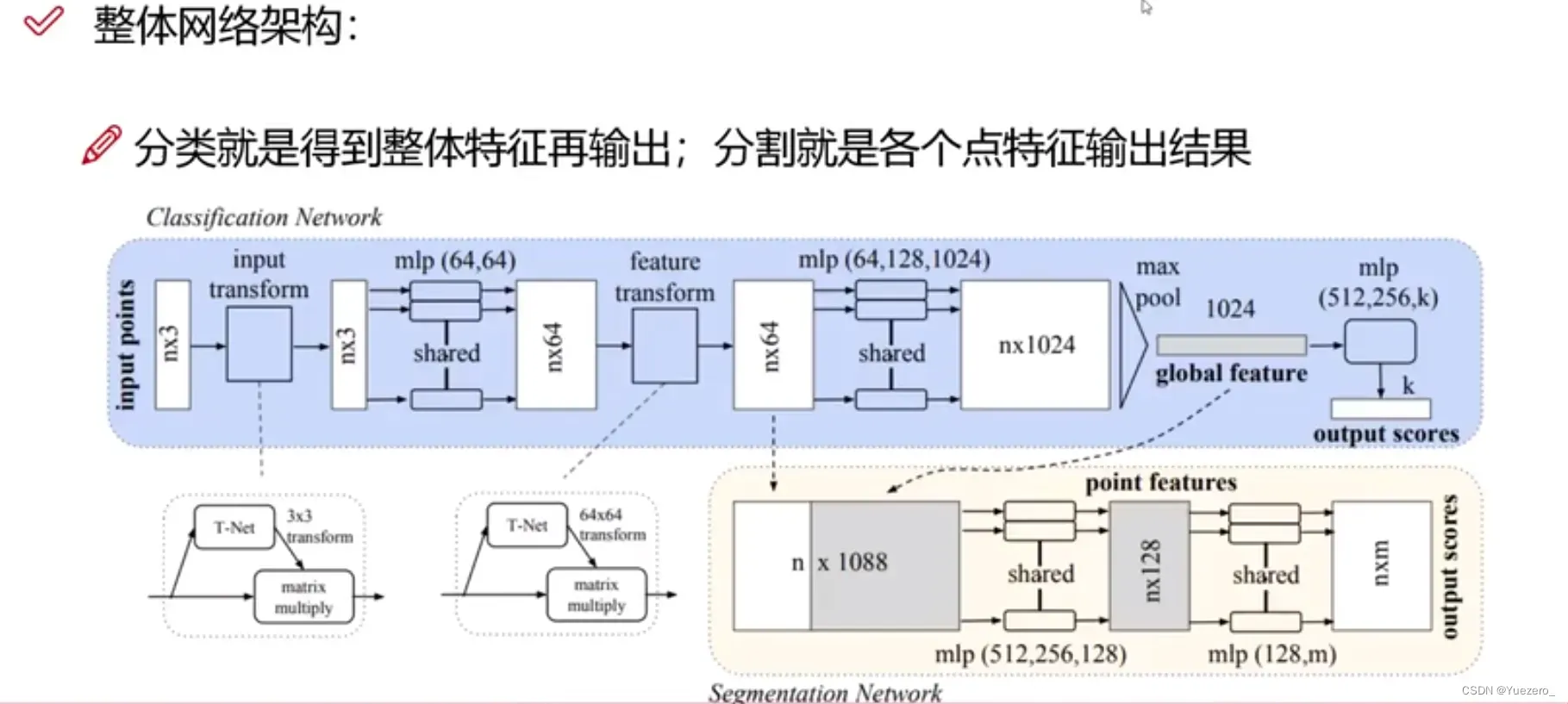
缺点:缺乏局部特征融合!!
3.3.2 PointNet++
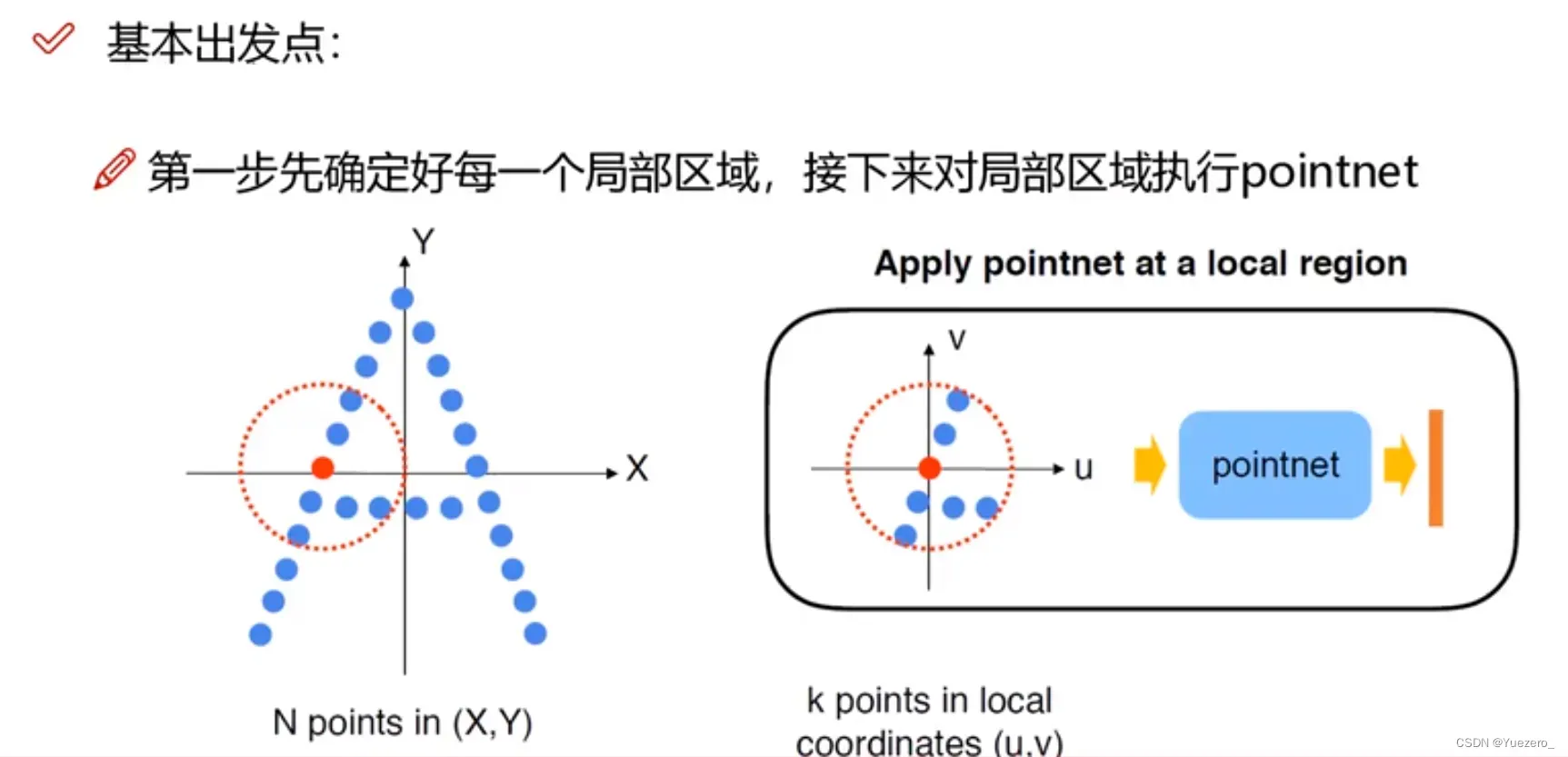
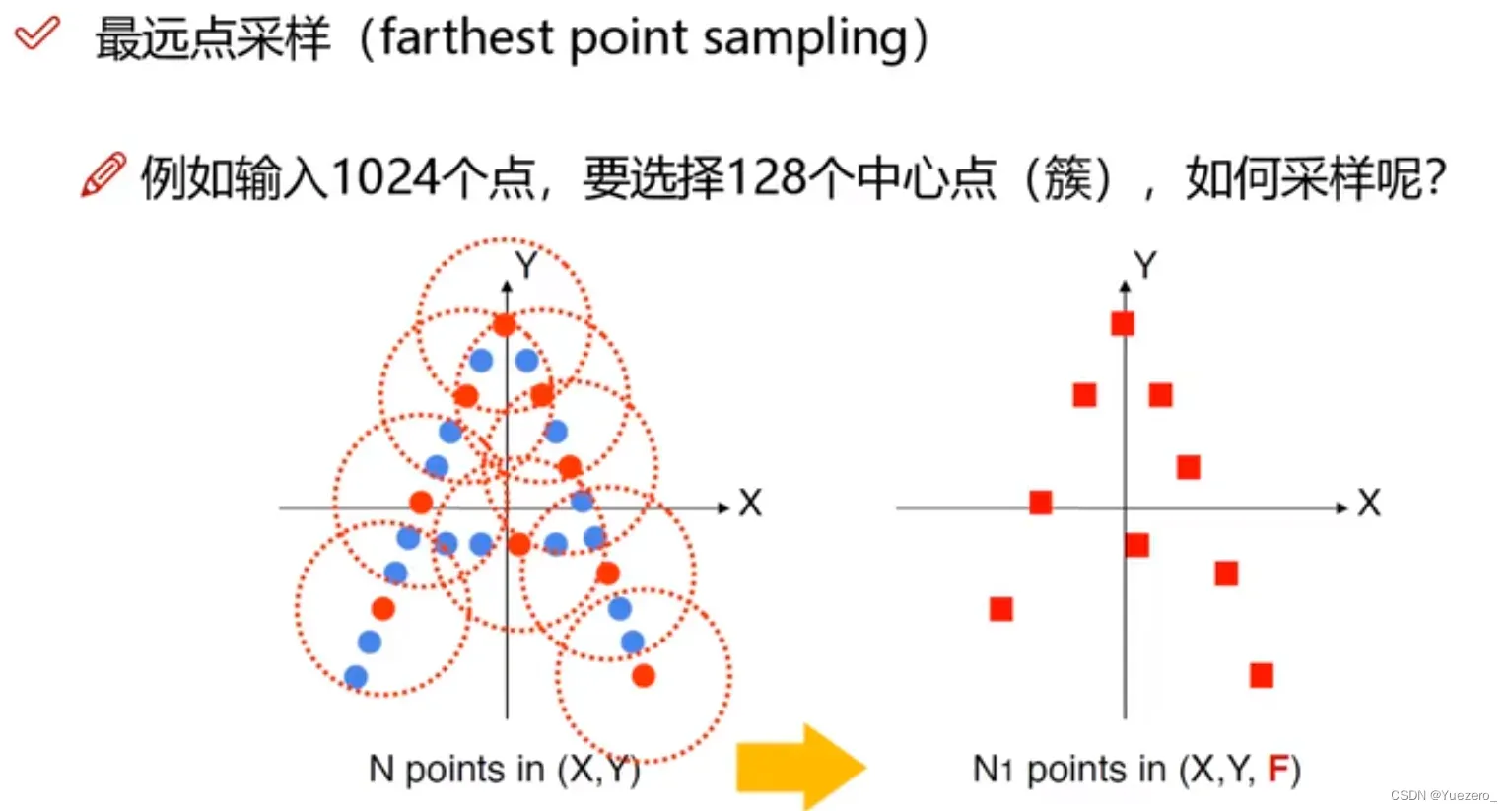
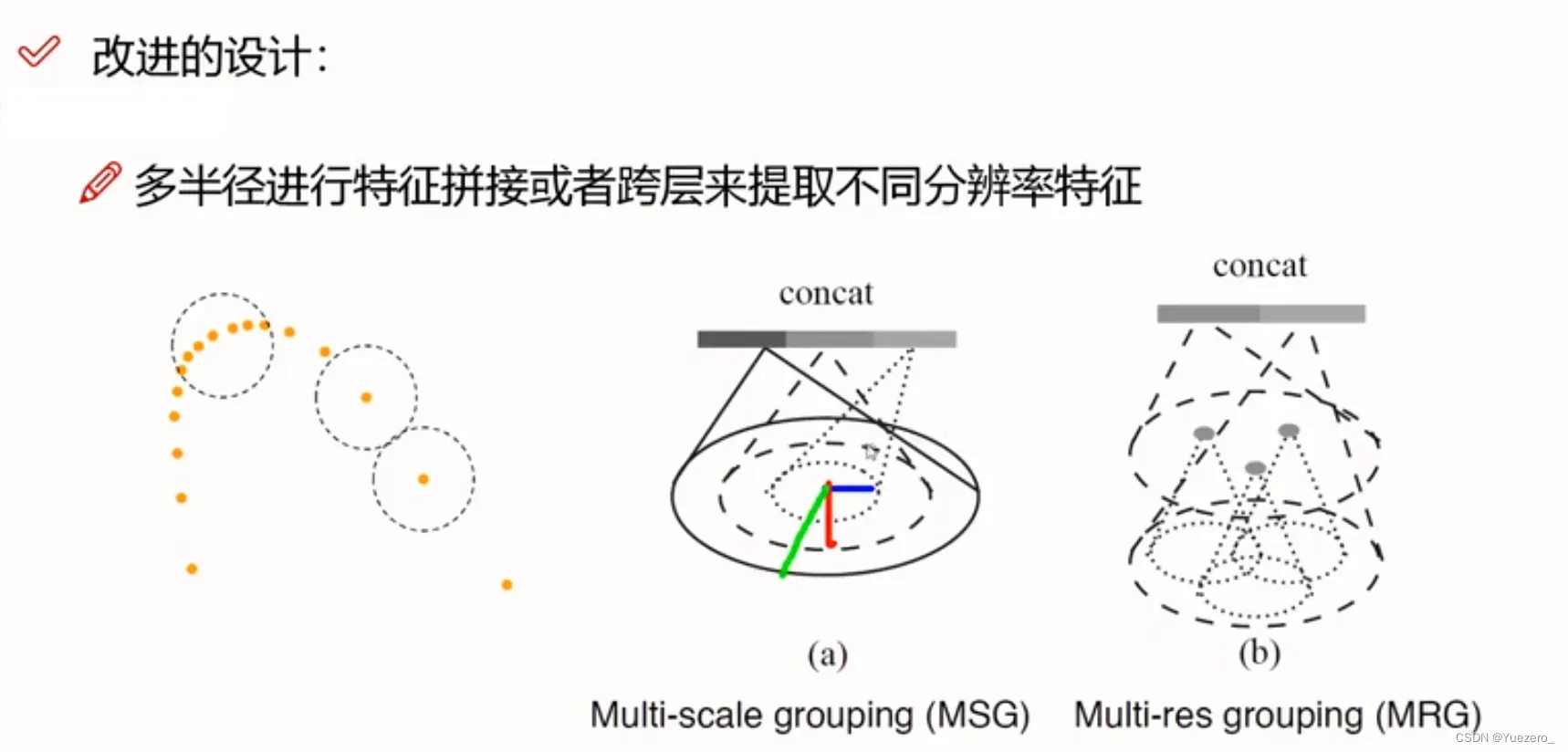
改进:使用最远点采样划分不同区域(中心点)内数量相等的点云分组Group,使用局部聚合(图卷积)进行局部特征融合,对每个区域使用PointNet 求出对应的区域特征向量,将不同半径的区域特征融合,最后进入FC层分类。


Pytorch卷积:Channel First!,把6当作channel提前,放在batch之后。


3.4 PointNet分割和分类
4 单目三维重建
传统三维重建:需要深度估计和点云融合的中间步骤,而深度三维重建使用End2End模型一条龙完成。

单目视觉是仅使用一台相机进行三维重建的方法。
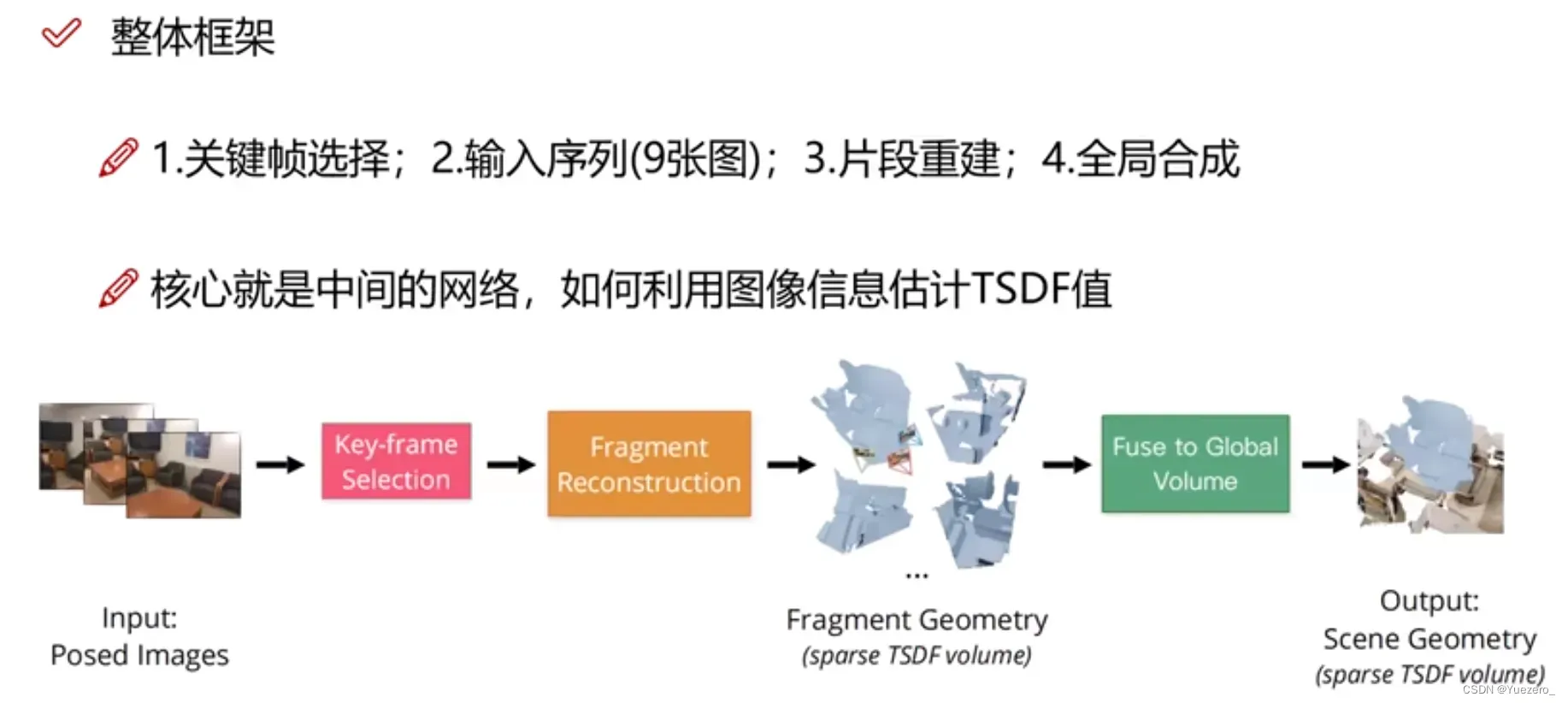
4.1 NeuralRecon
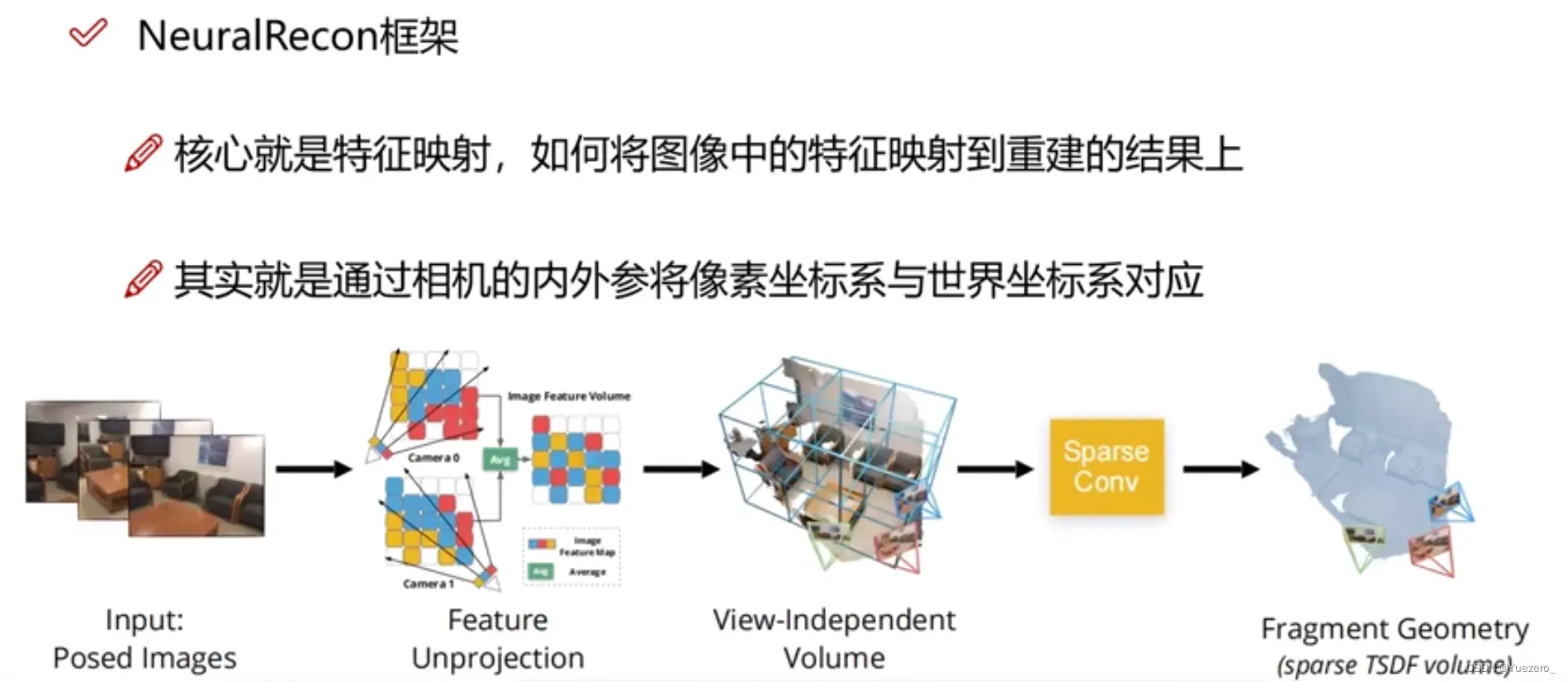
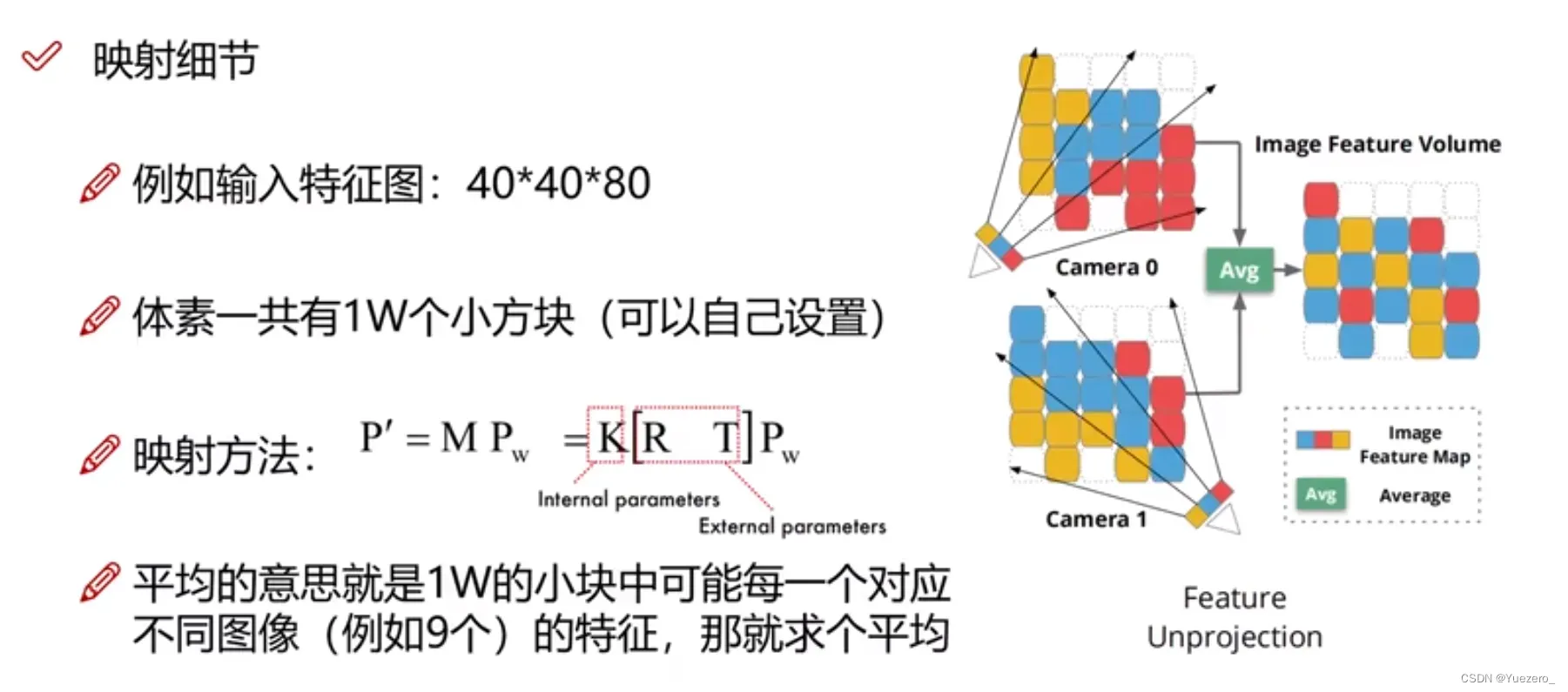

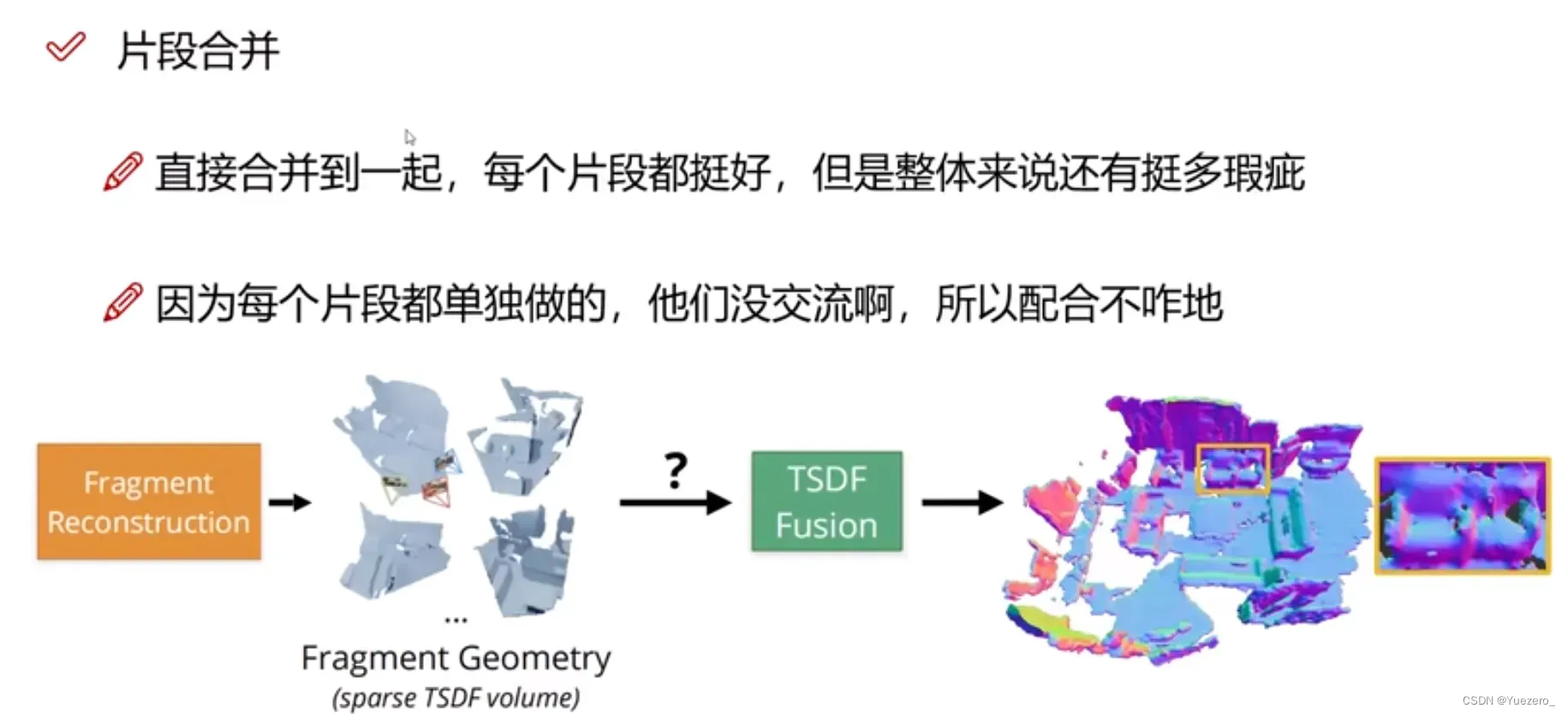
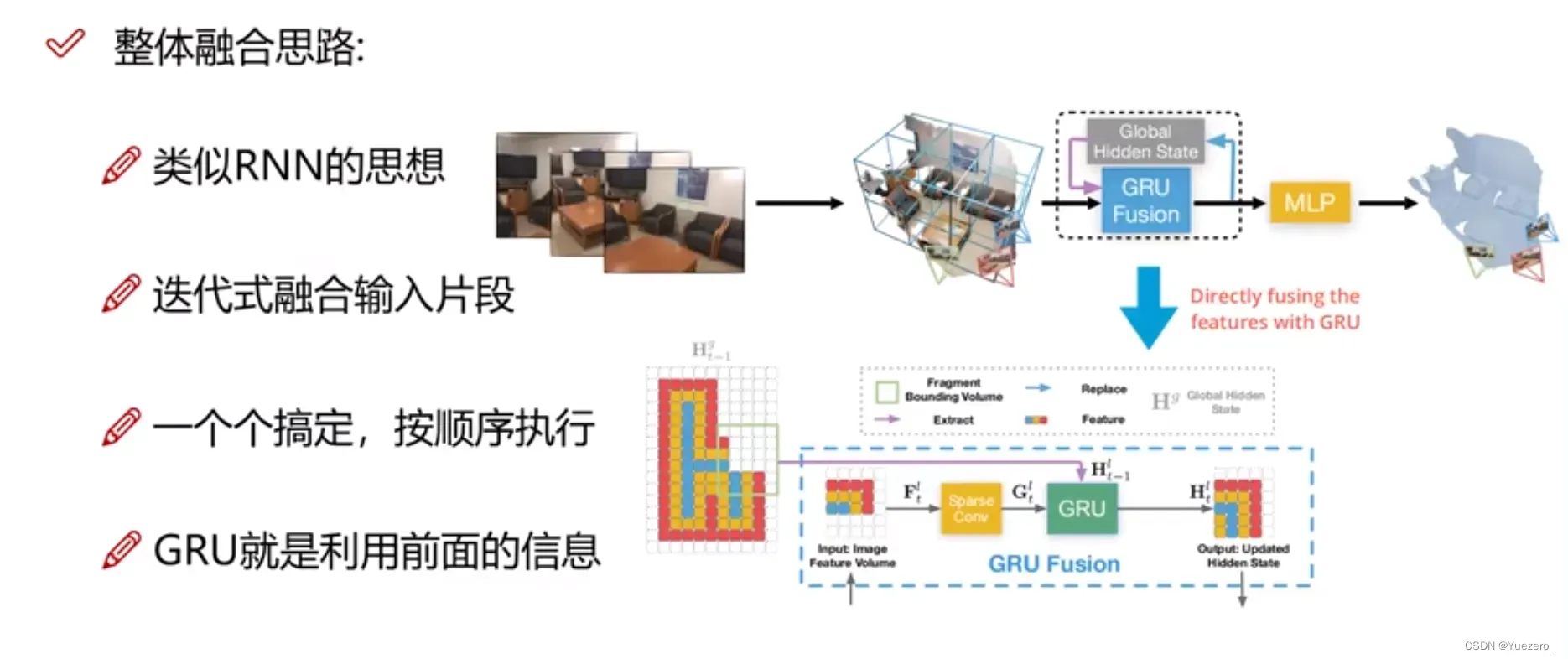
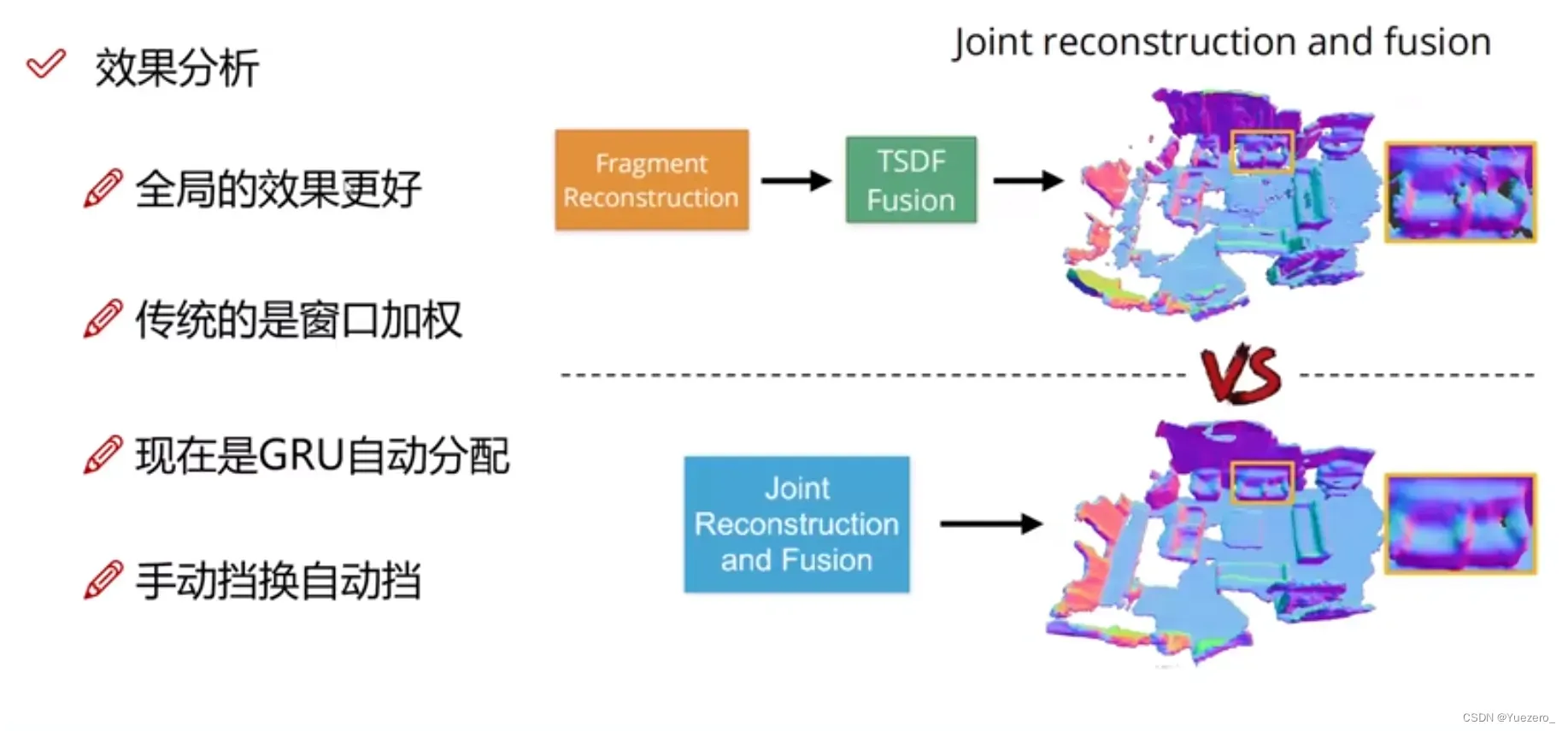

4.2 单帧重建Mesh
单帧重建Mesh主要用于人脸重建:
基于3DMM重建:Nonlinear 3D Face Morphable Model,On Learning 30 Face Morphable Model from In-the-wild Images,2DASL …
端到端重建:VRNet, PRNet …

4.2.1 3DMM
3D可变形模型(3DMM):利用统一人脸重建公式进行变形。

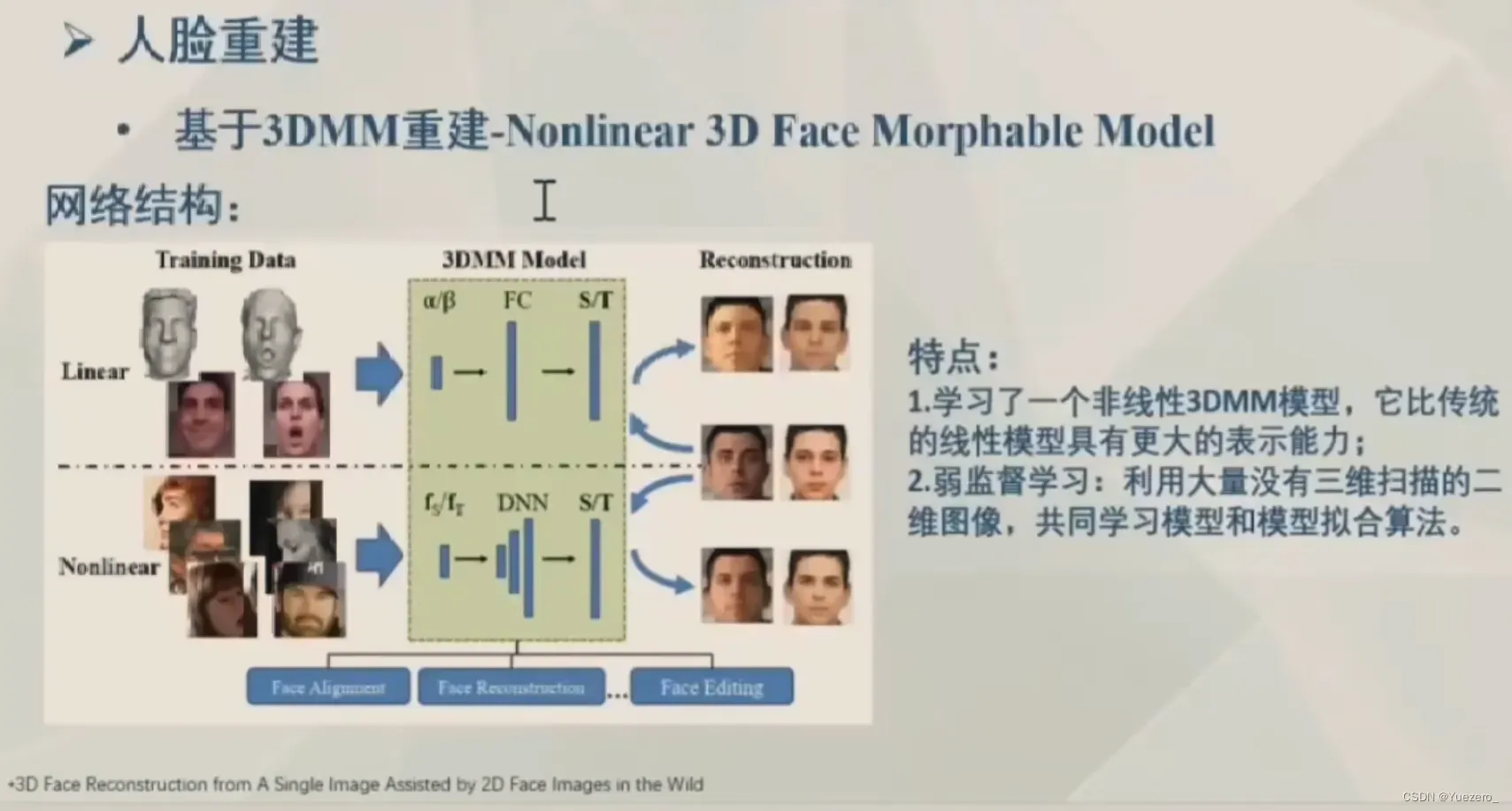
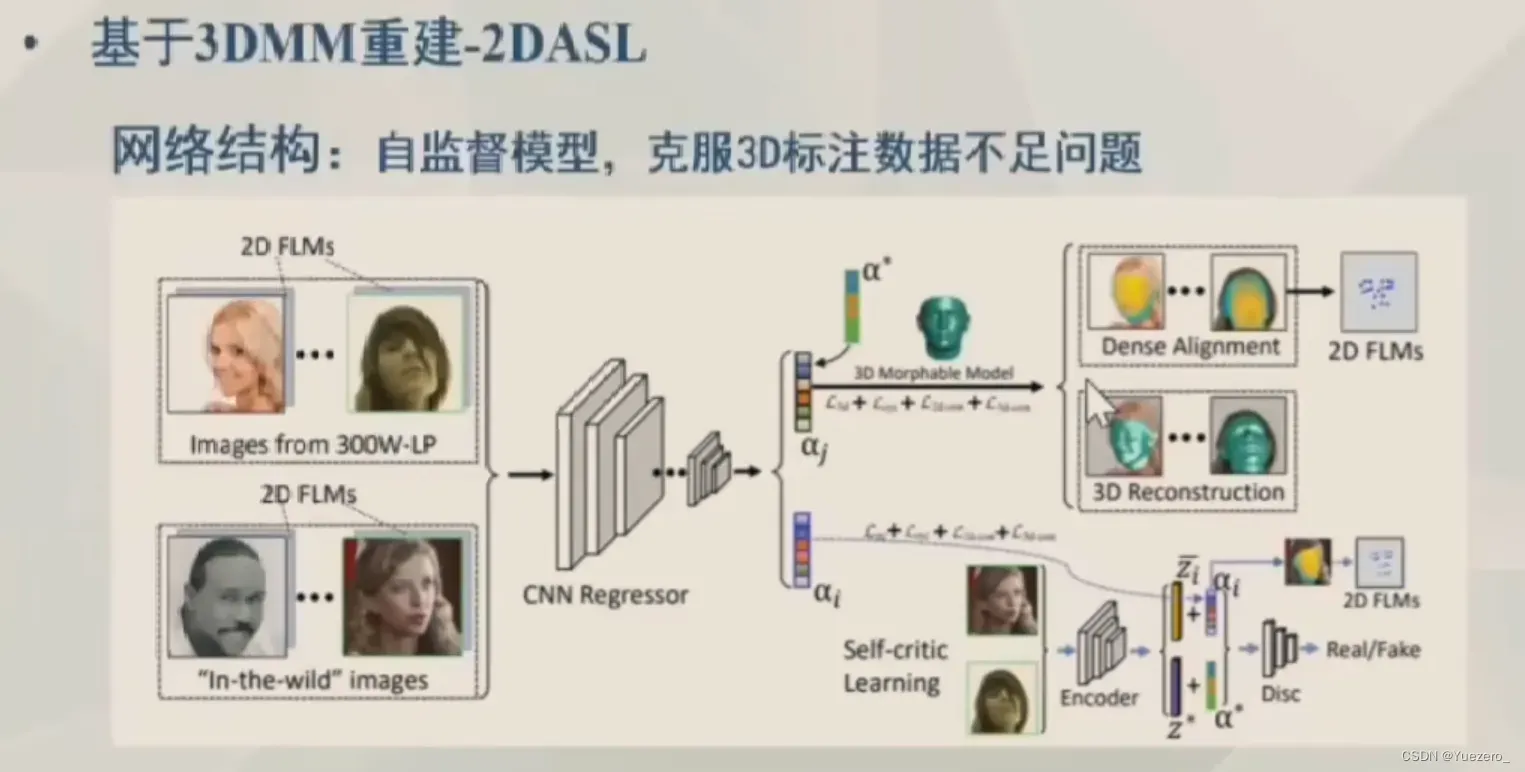
4.2.2 端到端重建
如轻量化的PRNet

单帧重建Mesh也可以用于物体/人体重建:如IF-Nets
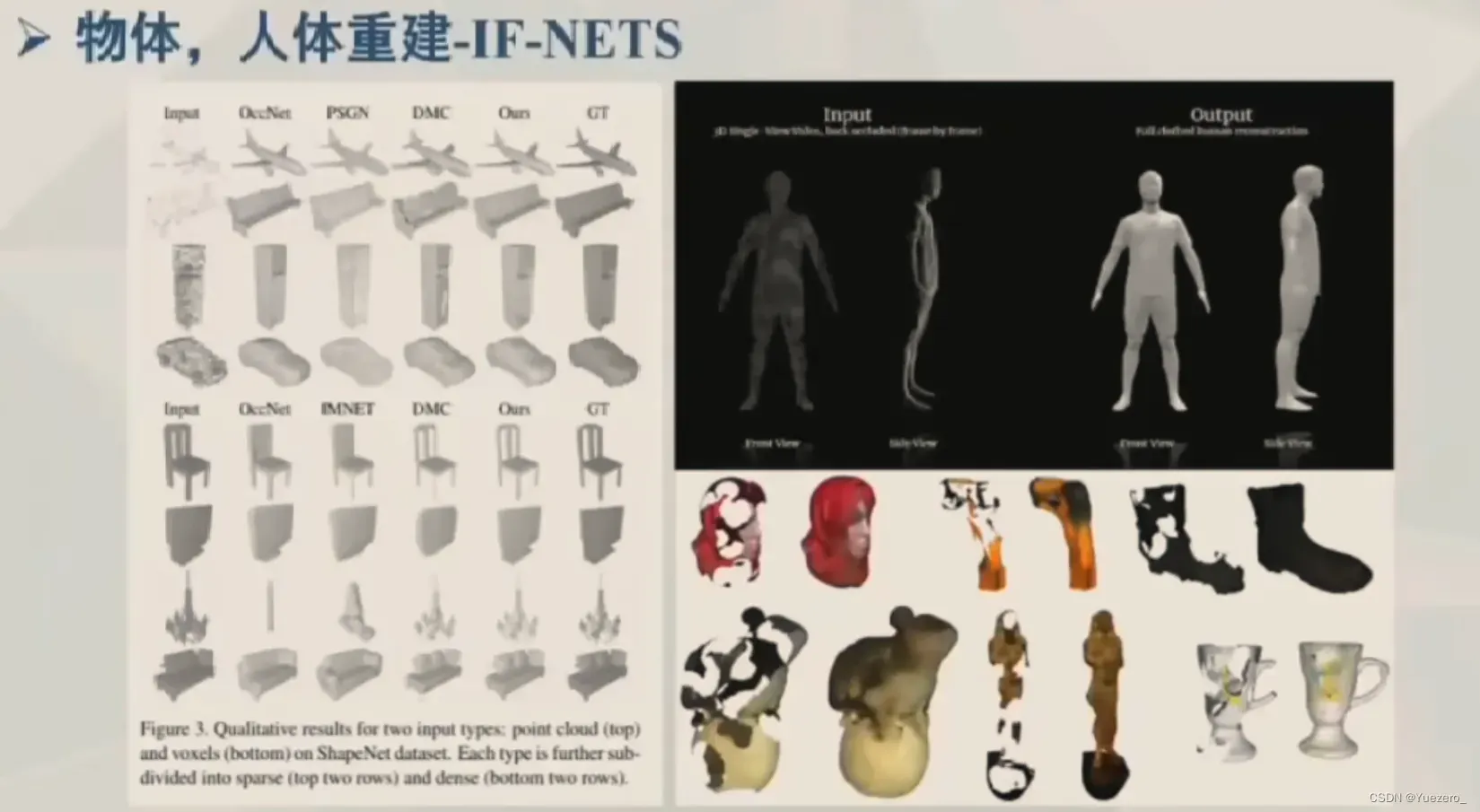
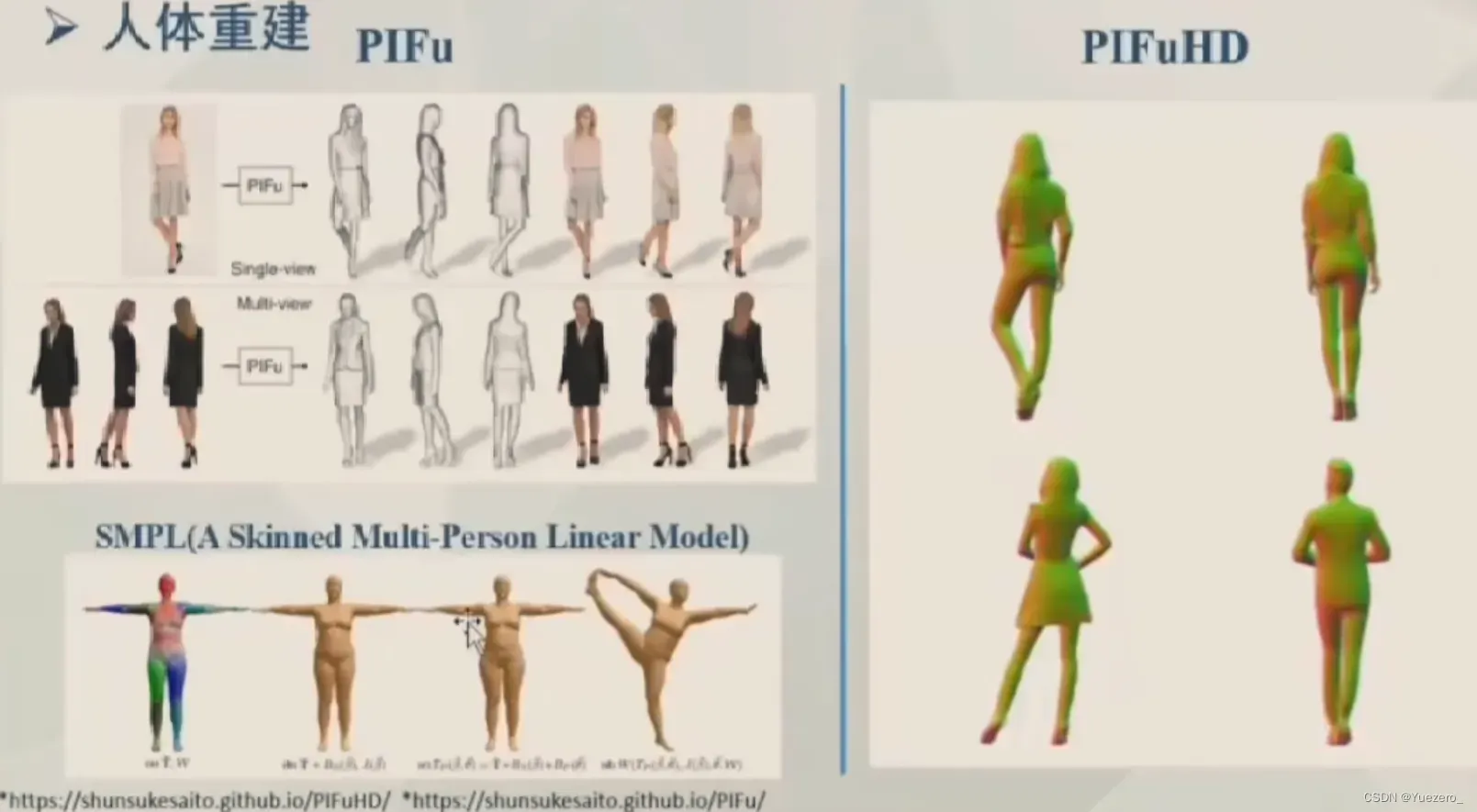
4.2.3 多目三维重建MVS
MVS(Multi-View Stereo)
- 经典开源框架:
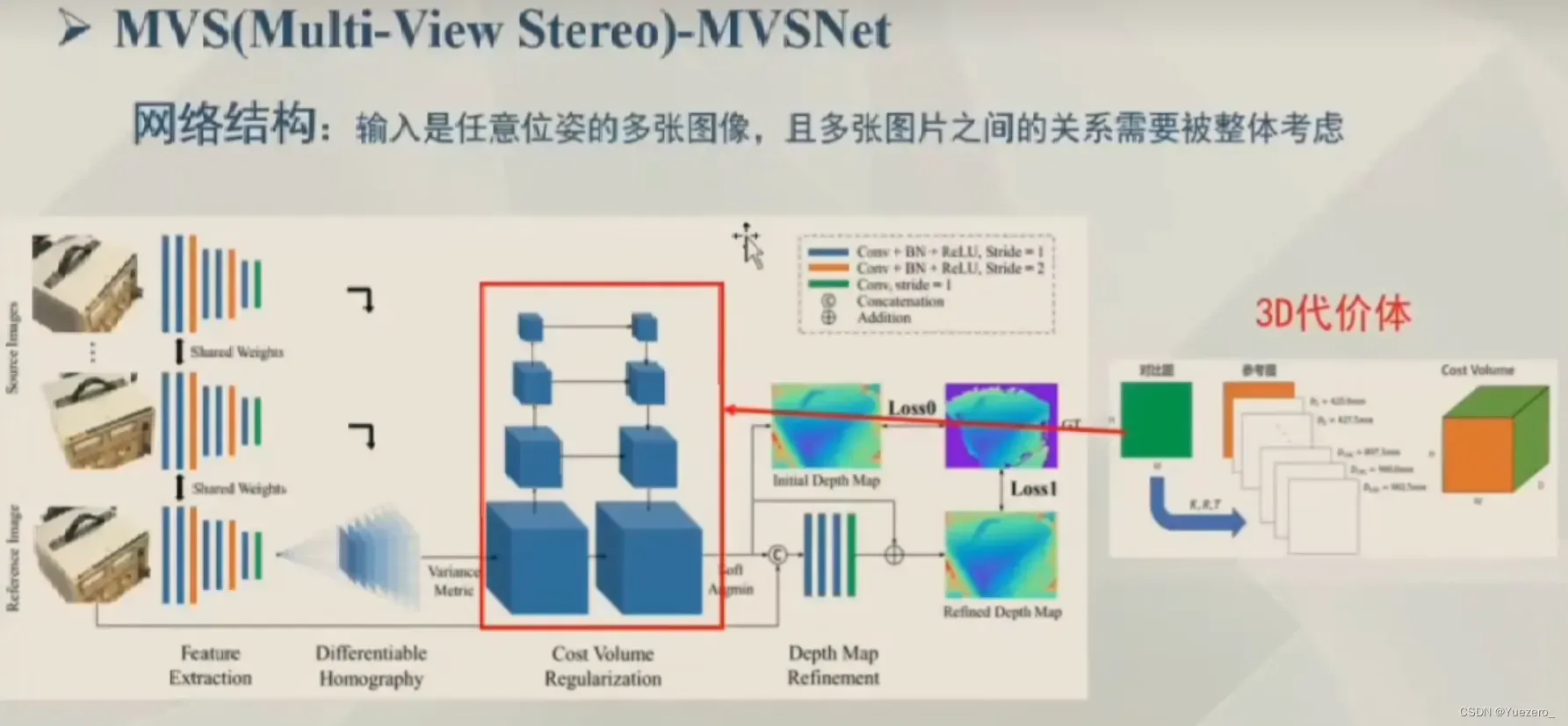
MVSNet-必读经典
P-MVSNet– 从pixel-wise拓展到patch-wise cost volume
Unsupervised MVSNet– 无监督网络
Fast-MVSNet– 速度快
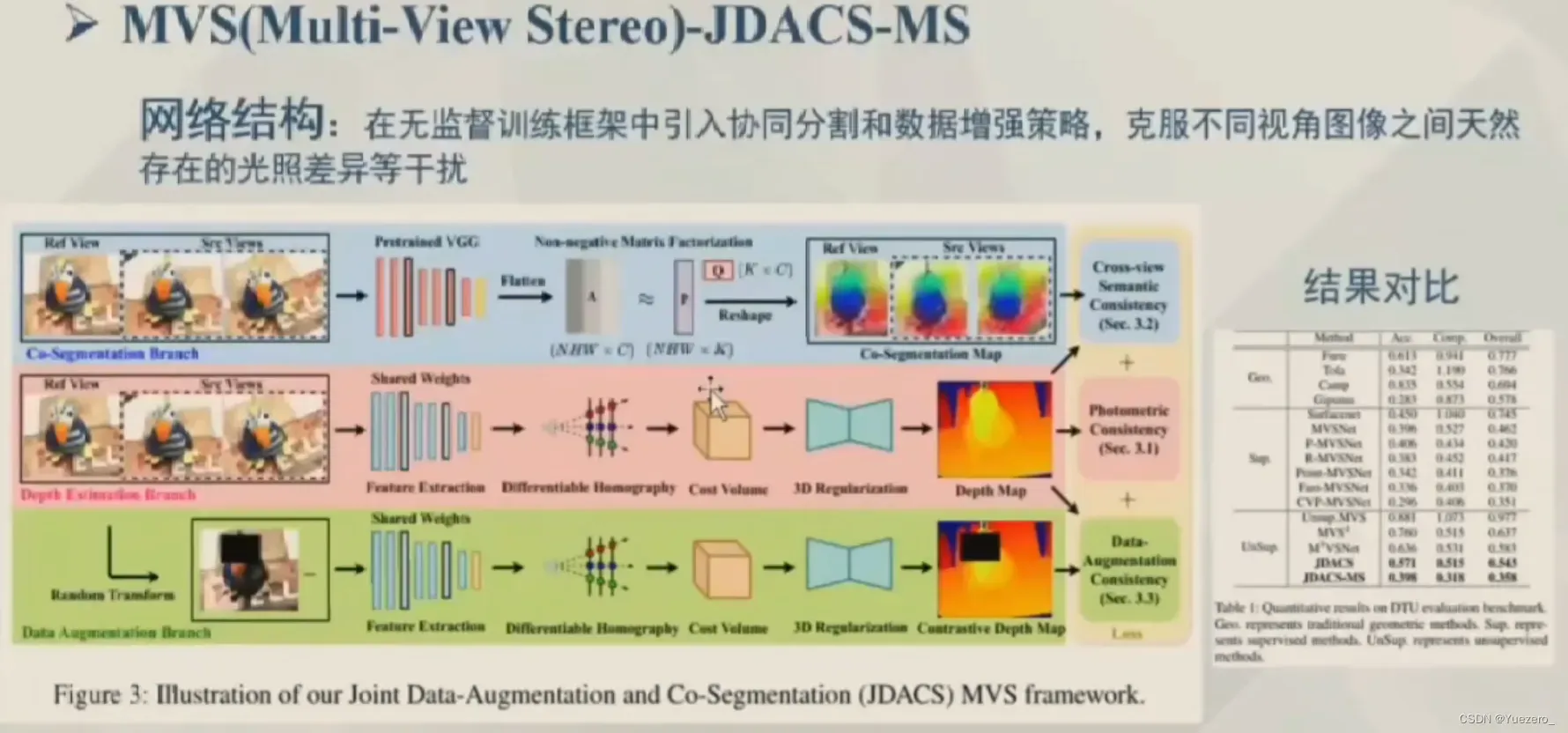
JDACS-MS-无监督MVS网络效果较好
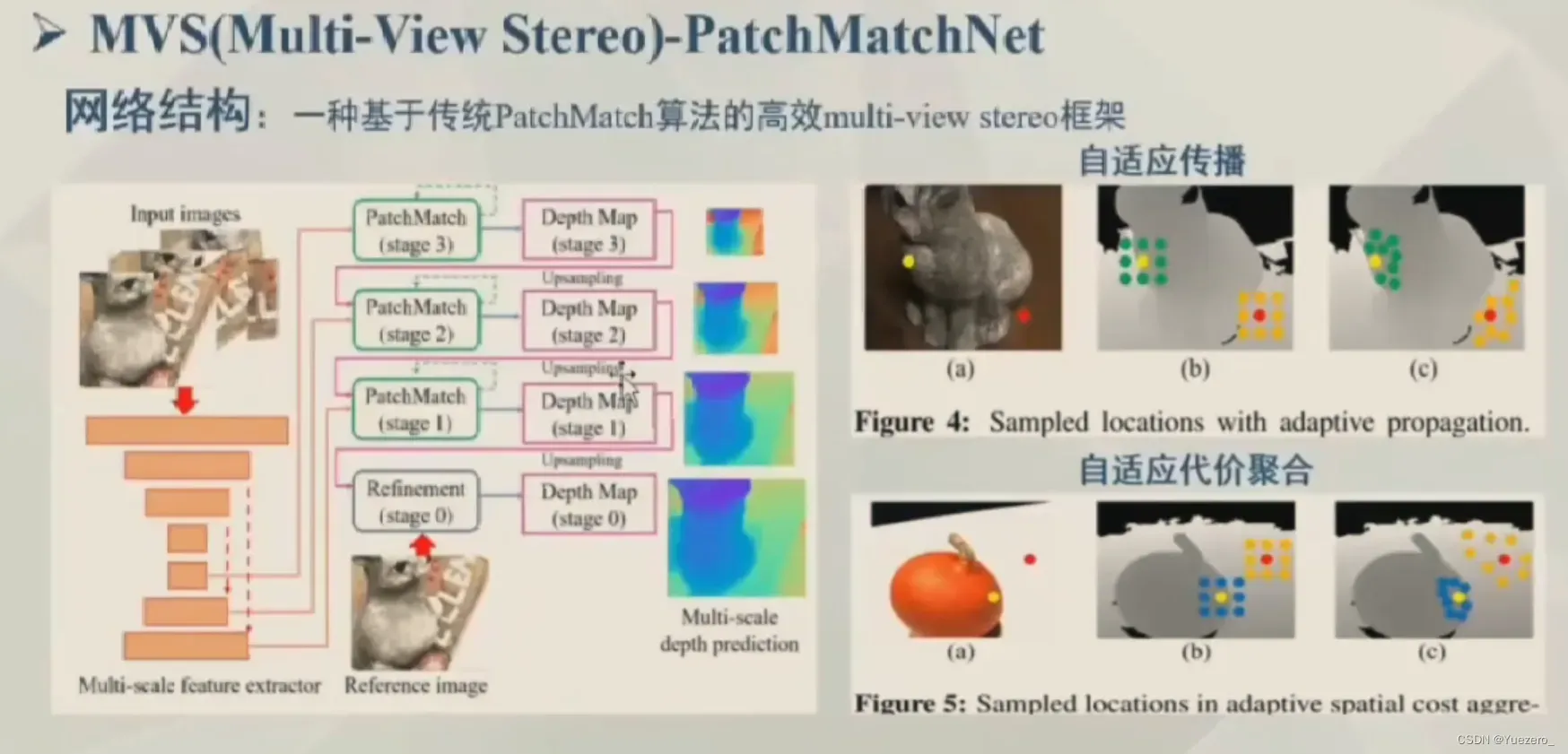
PatchMatchNet-有监督MVS网络效果较好
5 基于NeRF的SLAM
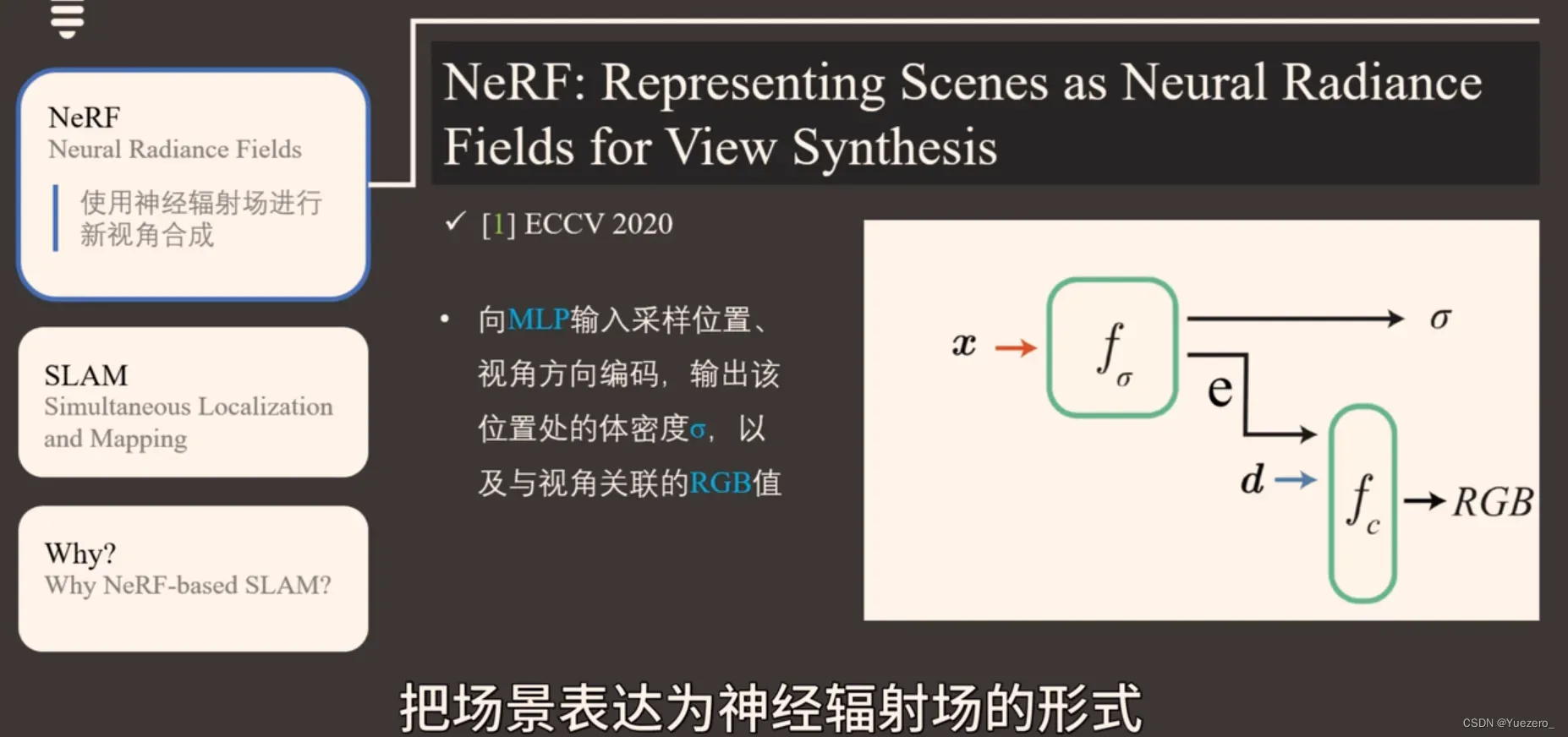
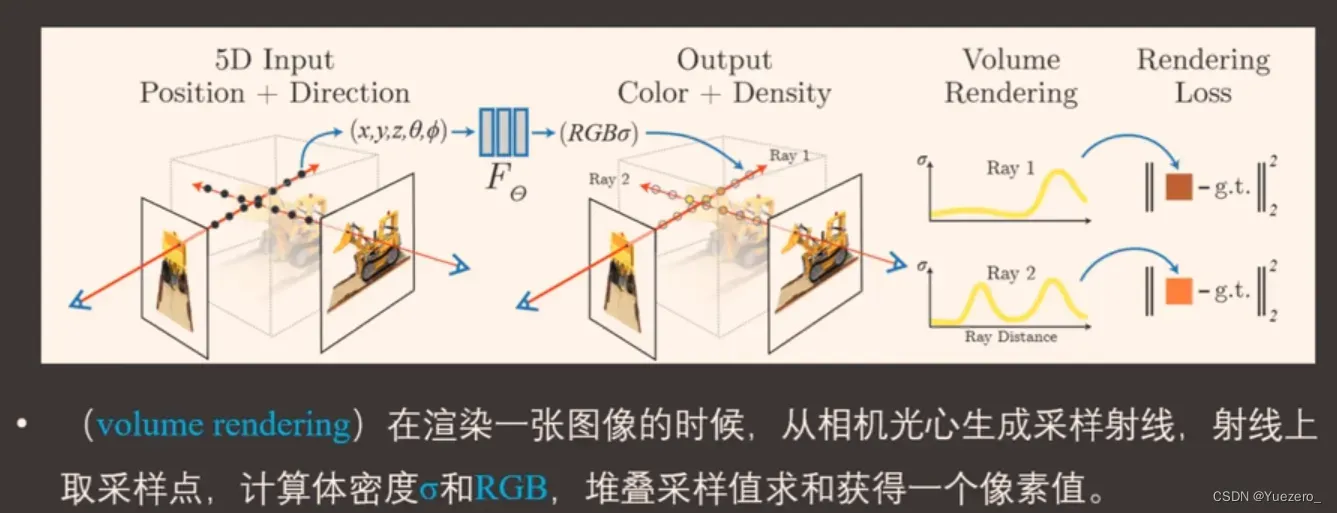
神经辐射场(NeRF):用于场景表达,本质是两个全连接的MLP,用于 拟合空间位置 和 视角方向 到 该点提密度 和 RGB值的映射。
文章出处登录后可见!