1.摘要
目标检测是计算机视觉主要应用方向之一。目标检测通常包括两方面的工作,首先是找到目标,然后就是识别目标。常用的目标检测方法分为两大流派:一步走(one_stage)算法:直接对输入的图像应用算法并输出类别和相应的定位,典型的算法有yolo,ssd;两步走(two_stage)算法:先产生候选区域,然后在进行CNN分类,代表的算法有R-CNN。其中一步走目标检测算法检测速度快,实时性好,在模型的快速部署上有着很强的优势,被广泛应用在各行各业中。本文也将选择yolov5算法对目标物体进行目标预测。训练好模型要部署在不同的边缘端,才会产生价值,本文将采用Openvino(Open Visual Inferencing and Neural Network Optimization/ 开放视觉推理和神经网络优化)来部署目标检测模型,Openvino是一个用于解决在intel硬件平台上进行深度学习部署的方案,支持windows、linux和macOS,有效地避免了不同软硬件平台兼容性的问题。
2.yolov5如何实现目标检测?
如何采用yolov5训练自己的数据,我已经在之前的博客里详细讲了训练过程,参照博客:【计算机视觉】目标检测—yolov5自定义模型的训练以及加载-https://blog.csdn.net/qq_43018832/article/details/128054360?spm=1001.2014.3001.5502。本文为了方便起见,不再进行训练自己的数据,将yolov5官方的预训练模型进行Openvino加速,查看加速效果。首先,去yolov5官网(https://github.com/ultralytics/yolov5)进行下载官方文件,也可以通过克隆地址(git clone https://github.com/ultralytics/yolov5.git)进行获取,并且下载预训练权重文件,放到yolov5文件下。结果如图:
运行下面的代码detection_show.py,在运行之前,首先安装yolov5文件下的requirements里面的依赖包,命令:pip install -r requirements.txt,运行后可以看到yolov5的官方预训练模型的检测结果,我使用的是笔记本,帧率只有2,3,如下图所示:
import cv2
import numpy as np
import torch
import time
# local repo
model = torch.hub.load('./yolov5', 'custom', 'weights/yolov5n.pt',source='local')
model.conf = 0.4
cap = cv2.VideoCapture(0)
fps_time = time.time()
while True:
ret,frame = cap.read()
# frame = cv2.flip(frame,1)
img_cvt = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
# Inference
results = model(img_cvt)
result_np = results.pandas().xyxy[0].to_numpy()
for box in result_np:
l,t,r,b = box[:4].astype('int')
cv2.rectangle(frame,(l,t),(r,b),(0,255,0),5)
cv2.putText(frame,str(box[-1]),(l,t-20),cv2.FONT_ITALIC,1,(0,255,0),2)
now = time.time()
fps_text = 1/(now - fps_time)
fps_time = now
cv2.putText(frame,str(round(fps_text,2)),(50,50),cv2.FONT_ITALIC,1,(0,255,0),2)
cv2.imshow('demo',frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()

3.Openvino如何加速模型?
3.1.原理简介
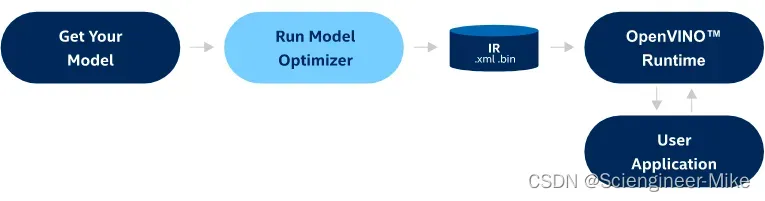
要使用它,你需要一个预先训练好的深度学习模型,支持的格式有:TensorFlow、PyTorch、PaddlePaddle、MXNet、Caffe、Kaldi或ONNX,本文选用的是yolov5官方预训练模型yolov5n.pt,读者可以训练自己的预训练模型。模型优化器将模型转换为OpenVINO中间表示格式(IR),稍后您可以使用OpenVINO™运行时进行推断。注意,模型优化器不推断模型。下图说明了部署经过训练的深度学习模型的典型工作流。
模型优化器通过以下机制来优化模型:
1. 对模型进行修剪:移除部分在训练时候需要的,而推理时候不需要的网络;DropOut 就是这种网络层的一个例子;
2. 融合操作:有些时候多步操作可以融合成一步,模型优化器检测到这种就会进行必要的融合;
优化过程结束后会生成一个 IR model / 中间表示模型,模型可以被分成两部分:
1. model.xml: XML 文件包含网络架构;
2. model.bin: bin 包含 Weights / 权重 和 Biases / 误差的二进制数据。
3.2.环境配置
首先,我们在安装openvino之前,使用conda创建自己的虚拟环境,安装pytorch CPU版本,命令:pip install torch torchvision torchaudio。接下来,将pytorch预训练模型转化为ONNX,安装依赖的环境ONNX,命令:pip install onnx==1.11.0,最后将转换为的onnx文件转换为openvino需要的.bin和.xml文件,安装依赖包:pip install openvino-dev[onnx],pip install openvino。
3.3.预训练模型.pt转ONNX文件
接下来,开始吧!将预训练模型yolov5n.pt转换为ONNX文件,可以直接使用yolov5中的文件export.py文件,此文件的作用是将yolov5 pytorch模型转换为各种格式(onnx,tensorrt,coreml,tensorflow等等)的文件。
执行命令为:
python export.py --weights yolov5n.pt --include onnx --img 640 --device 0
也可以通过执行下面代码转换为onnx格式。
if not onnx_path.exists():
dummy_input = torch.randn(1, 3, IMAGE_HEIGHT, IMAGE_WIDTH)
# For the Fastseg model, setting do_constant_folding to False is required
# for PyTorch>1.5.1
torch.onnx.export(
model,
dummy_input,
onnx_path,
opset_version=11,
do_constant_folding=False,
)
print(f"ONNX model exported to {onnx_path}.")
else:
print(f"ONNX model {onnx_path} already exists.")
转换后的结果如下。
![]()
3.4.ONNX文件转IR文件
使用模型优化器将ONNX模型转换为具有FP16精度的OpenVINO IR。模型被保存到当前目录。向模型中添加平均值,并使用——scale_values按标准偏差缩放输出。有了这些选项,在通过网络传播输入数据之前就没有必要对其进行规范化。有关模型优化器的更多信息,请参阅模型优化器开发人员指南https://docs.openvino.ai/latest/openvino_docs_MO_DG_Deep_Learning_Model_Optimizer_DevGuide.html。转换为IR文件的命令格式如下:
# Construct the command for Model Optimizer.
mo_command = f"""mo
--input_model "{onnx_path}"
--input_shape "[1,3, {IMAGE_HEIGHT}, {IMAGE_WIDTH}]"
--mean_values="[123.675, 116.28 , 103.53]"
--scale_values="[58.395, 57.12 , 57.375]"
--data_type FP16
--output_dir "{model_path.parent}"
"""
mo_command = " ".join(mo_command.split())
print("Model Optimizer command to convert the ONNX model to OpenVINO:")
display(Markdown(f"`{mo_command}`"))
if not ir_path.exists():
print("Exporting ONNX model to IR... This may take a few minutes.")
mo_result = %sx $mo_command
print("\n".join(mo_result))
else:
print(f"IR model {ir_path} already exists.")
命令行为:
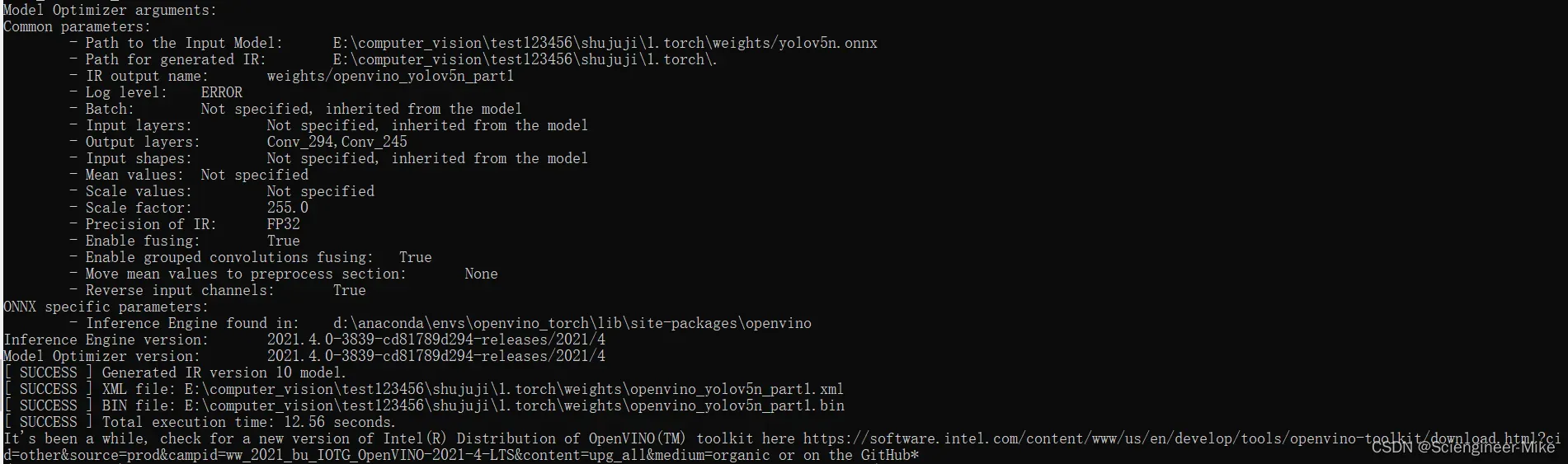
mo --input_model yolov5n.onnx --model_name openvino_yolov5n_part1 -s 255 --reverse_input_channels --output Conv294,conv245
出现这种情况,代表模型转换成功。
4.查看加速结果
最后使用推理引擎查看推理结果。
# Load the network in OpenVINO Runtime.
ie = Core()
model_ir = ie.read_model(model=ir_path)
compiled_model_ir = ie.compile_model(model=model_ir, device_name="CPU")
# Get input and output layers.
output_layer_ir = compiled_model_ir.output(0)
# Run inference on the input image.
res_ir = compiled_model_ir([input_image])[output_layer_ir]
result_mask_ir = np.squeeze(np.argmax(res_ir, axis=1)).astype(np.uint8)
viz_result_image(
image,
segmentation_map_to_image(result=result_mask_ir, colormap=CityScapesSegmentation.get_colormap()),
resize=True,
)
为了直观的看出加速结果,在不影响检测效果的前提下,丢弃部分小目标检测,查看加速结果提升至9.8帧。

本篇简单记录了作者在学习openvino加速模型的过程,希望对大家有所帮助。
文章出处登录后可见!