原文链接:https://blog.csdn.net/qq_43622216/article/details/124163883
2022年顶会、顶刊SNN相关论文
- 目录
- 说明
- AAAI2022(共7篇)
- NeurIPS 2022(共19篇)
- IJCAI(International Joint Conference on Artificial Intelligence 共5篇)
- IJCNN( International Joint Conference on Neural Networks)
- ICASSP(IEEE International Conference on Acoustics, Speech and Signal Processing 共12篇)
- NEURAL COMPUTATION
- Neural Networks
- IEEE TCYB(IEEE Transactions on Cybernetics)
- TNNLS(IEEE Transactions on Neural Networks and Learning Systems)
- ICML(共4篇)
- CVPR(共6篇)
- ECCV
- ICLR(共4篇)
目录
说明
这篇博客主要用于记录2022年在一些顶会顶刊(AAAI、CVPR等)上发表的一些不错的SNN方面的论文,会附上相关论文的链接,正在更新中…
更新SNN相关论文、动态信息,欢迎浏览讨论!
AAAI2022(共7篇)
-
论文1: Optimized Potential Initialization for Low-latency Spiking Neural Networks
- 由北京大学余肇飞组发表于AAAI 2022。
文章指出当模拟步长T足够大的时候,可以通过设置阈值电压等于对应ANN层最大的ReLU激活值和copy参数和偏差来将ANN转换为SNN。
当每一层神经元的初始膜电势为阈值电压的一半时(此时阈值电压设置为原始的ANN中那一层里ReLU激活输出的最大值),不仅可以使得转换误差最小,而且此时转换误差为0。
如果没有对膜电势进行合适的初始化,ANN转换后的SNN中的神经元往往需要很长时间才能发放第一个脉冲,因此网络的latency较大。
- 由北京大学余肇飞组发表于AAAI 2022。
-
论文2: PrivateSNN: Privacy-Preserving Spiking Neural Networks
- 由耶鲁大学研究人员发表于AAAI 2022,关注于SNN中的安全性隐私问题。
-
- 由上海交通大学研究人员发表于AAAI 2022。
- 使用soft reset scheme,比起hard reset能够在发放脉冲后保留更多的信息。
- 首先推导出了ANN转SNN的理想等式,等式成立需要有一个前提:在最后time step的最后时刻剩余膜电势应该为0即总输入和总输出能够抵消。
- 为了达到理想等式的条件,使用Temporal Separation的方法把time step分成两部分,第一部分accumulating phase接收脉冲而不发放,第二部分generating phase发放脉冲而不接收;
- 为了实现Time Separation提出了Inverse-Leaky Integrate-and-Fire Neuron(iLIF);实现的时候为了加快速度使用inter-layer direct delivery和inter-sample pipelining方式进行处理。
-
论文4: Multi-sacle Dynamic Coding improved Spiking Actor Network for Reinforcement Learning
- 由中科院自动所张铁林组发表于AAAI 2022,将SNN用于强化学习领域。
-
论文5: Fully Spiking Variational Autoencoder
- 由东京大学研究人员发表于AAAI 2022,使用SSN去构建一个VAE(变分自编码器)。
-
论文6: Spiking Neural Networks with Improved Inherent Recurrence Dynamics for Sequential Learning
- 由普渡大学研究人员发表于AAAI 2022,将SSN用于序列学习。
- 指出SNN的两个优点:参数数量少因此节省内存、计算开销小。
- 脉冲神经元层中有两个内在状态:突触电流(synaptic currents)和膜电势(membrane potentials),突触电流携带随时间的信息,膜电势追踪误差。
- 提出了Improved Inherent Recurrence Dynamics对LIF神经元中电流的计算公式进行修改,使其能够保留更多过去的信息从而进行序列学习。
- 设置LIF神经元的阈值为和训练过程中的最大膜电势(b)相关,在训练过程中使用指数移动平均(exponential moving average,EMA)记录膜电势,然后设置合适的阈值来进行多比特输出,能够减轻替代梯度和真实梯度之间的不匹配问题。
-
论文6: Spatio-Temporal Recurrent Networks for Event-Based Optical Flow Estimation
- 由北京大学黄铁军组发表于AAAI 2022。
NeurIPS 2022(共19篇)
-
论文1: GLIF: A Unified Gated Leaky Integrate-and-Fire Neuron for Spiking Neural Networks
- 由中科院自动化所研究人员发表于NeurIPS 2022。
- 使用α、β和γ调节神经元的膜电势延迟、充电、放电,大大提升了脉冲神经元的异质性。所有膜电势相关的参数以及这些调节因子都是可训练的,同一个channel的神经元共享参数。
 )
)
-
论文2: Biologically Inspired Dynamic Thresholds for Spiking Neural Networks
- 由大连理工大学、普林斯顿大学等研究人员发表于NeurIPS 2022。
- 提出了Bio-Plausible Dynamic Energy-Temporal Threshold (BDETT),结合Dynamic Energy Threshold (DET)和Dynamic Temporal Threshold (DTT)来根据平均膜电势和膜电势的去极化(增长)速度来调整阈值。
-
论文3: Online Training Through Time for Spiking Neural Networks
- 由北京大学(林宙辰组)、香港中文大学研究人员发表于NeurIPS 2022。
- 提出了online training through time (OTTT)。
-
论文4: Mesoscopic modeling of hidden spiking neurons
- 由洛桑联邦理工学院研究人员发表于NeurIPS 2022。
-
论文5: Temporal Effective Batch Normalization in Spiking Neural Networks
- 由北京大学于肇飞组发表于NeurIPS 2022。
-
论文6: Differentiable hierarchical and surrogate gradient search for spiking neural networks
- .
-
- .
-
论文8: Theoretically Provable Spiking Neural Networks
- .
-
论文9: Natural gradient enables fast sampling in spiking neural networks
- .
-
论文10: Biologically plausible solutions for spiking networks with efficient coding
- .
-
论文11: Toward Robust Spiking Neural Network Against Adversarial Perturbation
- .
-
论文12: SNN-RAT: Robustness-enhanced Spiking Neural Network through Regularized Adversarial Training
- .
-
论文13: Emergence of Hierarchical Layers in a Single Sheet of Self-Organizing Spiking Neurons
- .
-
论文14: Training Spiking Neural Networks with Event-driven Backpropagation
- .
-
论文15: IM-Loss: Information Maximization Loss for Spiking Neural Networks
-
由中国航天工业集团公司智能科学技术研究院研究人员发表于NeurIPS 2022。
-
提出了information maximization (IM)-Loss减小膜电压到输出脉冲的信息精度损失同时具有类似于标准化的效果(网络中可以无需BN层这种):

-
提出了Evolutionary Surrogate Gradients(ESG):

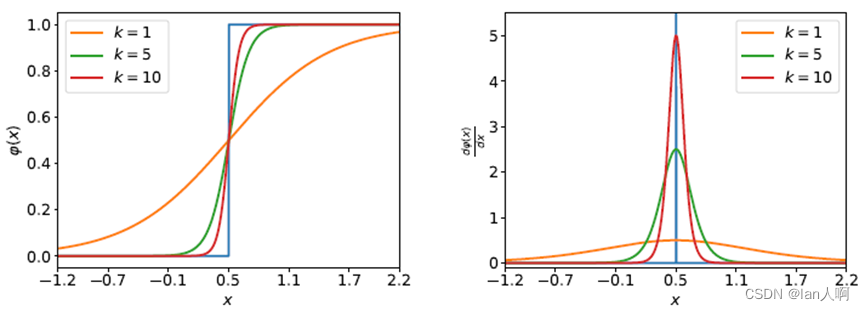
-
ESG实际使用时随epoch改变(设置K的上界和下界分别为10和1):


-
-
论文16: The computational and learning benefits of Daleian neural networks
- .
-
论文17: Dance of SNN and ANN: Solving binding problem by combining spike timing and reconstructive attention
- .
-
论文18: Learning Optical Flow from Continuous Spike Streams
- .
-
论文19: STNDT: Modeling Neural Population Activity with Spatiotemporal Transformers
- .
IJCAI(International Joint Conference on Artificial Intelligence 共5篇)
-
论文1: Efficient and Accurate Conversion of Spiking Neural Network with Burst Spikes
- 由中科院自动化所曾毅研究院组发表于IJCAI 2022。
- 代码链接
- 在ANN转SNN的过程中有三种error:residual information;spikes of inactived neurons(SIN)和SNN的最大池化中每次选择的神经元不稳定。
- 提出Burst neuron,使得在两个time step之间也可以发出脉冲(即一个time step内发出多个脉冲,可以设置脉冲数量上限)。
- 提出Lateral Inhibition Pooling(LIPooling)来解决转换中的最大池化引发的问题。
-
论文2: Spiking Graph Convolutional Networks
- 代码链接
- 由中山大学图学习团队发表于IJCAI 2022。
-
论文3: Signed Neuron with Memory: Towards Simple, Accurate and High-Efficient ANN-SNN Conversion
- 由电子科技大学计算机科学与工程学院计算智能团队发表于IJCAI 2022,代码链接
- 使用Signed Neuron with Memory (SNM)来将带有ReLU函数的ANN转换为SNN,使用memory机制确保脉冲神经元的发放率不会低于0(普通的signed neuron不能保证这个问题)。
- Neuron-Wise Parameter Normalization(NeuronNorm):分别记录下ANN中每个神经元的最大激活值,使用这些激活值作为对应脉冲神经元的发放阈值并根据这些激活值对参数进行正则化。由于同一层不同神经元的最大激活值相对独立,信息丢失量大大减少(同一层每一个神经元的阈值都不相同)。
-
论文4: Self-Supervised Mutual Learning for Dynamic Scene Reconstruction of Spiking Camera
- 由北京大学余肇飞组发表于IJCAI 2022。
-
- 由浙江大学(唐华锦组)研究人员发表于IJCAI 2022,代码链接
- 主要解决SNN直接训练过程中的梯度消失喝网络退化问题。
- 基于STBP设计了multi-level firing(MLF)方法,将几个具有不同发放阈值的LIF神经元结合组成一个MLF单元,每个神经元的发放阈值刚好相差a(矩形函数近似脉冲梯度的参数),使得各个LIF神经元的矩形函数区域相互衔接,这样计算梯度时非零区域更大,能减少休眠单元(dormant unit)的产生。
- 提出了脉冲休眠抑制残差网络(spiking DS-ResNet),将ResNet block中的BN层换成tdBN,ReLU换成MLF单元,并将原始的add操作后的ReLU位置替换成将MLF单元放在add操作前。
IJCNN( International Joint Conference on Neural Networks)
-
论文1: Object Detection with Spiking Neural Networks on Automotive Event Data
-
论文3: Spiking Approximations of the MaxPooling Operation in Deep SNNs
- 由滑铁卢大学人员发表于IJCNN 2022。
-
论文4: Event-Driven Tactile Learning with Location Spiking Neurons
- 由美国西北大学人员发表于IJCNN 2022。





ICASSP(IEEE International Conference on Acoustics, Speech and Signal Processing 共12篇)
-
论文1: Axonal Delay As a Short-Term Memory for Feed Forward Deep Spiking Neural Networks
- 由比利时根特大学研究人员发表于ICASSP 2022,提出了rectified axonal delay (RAD) module来调节轴突延迟使用SLAYER-PyTorch来实现。
- desired spike trains被设置为shifted spike trains,其中:

- 损失函数设置为:

-
论文2: Gradual Surrogate Gradient Learning in Deep Spiking Neural Networks
- 由电子科技大学计算机科学与工程学院计算智能团队发表于ICASSP 2022。
- 提出了Internal Spiking Neuron Model(ISNM)使得神经元的输入不再局限于二元(0、1),将脉冲序列作为神经元内部动态过程的一部分并使用突触电流传递信息;
- 提出了Gradual Surrogate Gradient(GSG),在网络的训练过程中可以调节GSG中的参数使得其在训练前期能够让更多的神经元参与学习而在后期有更高的准确率(和真实梯度更接近)。
- 这种方法不需要进行输入encoding和输出decoding。
-
论文3: T-NGA: Temporal Network Grafting Algorithm for Learning to Process Spiking Audio Sensor Events
- 由苏黎世大学研究人员发表于ICASSP 2022,非脉冲神经网络。
- 提出了一个自监督的Temporal Network Grafting Algorithm (T-NGA)来将一个预训练在频谱图特征上预训练的循环网络移植到耳蜗事件特征上。T-NGA可以在没有大型标记峰值数据集的情况下训练网络处理脉冲音频传感器事件。
-
论文4: Modeling The Detection Capability Of High-Speed Spiking Cameras
- 由北京大学Tiejun Huang组研究人员发表于ICASSP 2022,非脉冲神经网络。
- 提出了一种建模算法来研究脉冲相机的检测能力,该算法根据相机的基本技术参数(如像素大小、时空分辨率),推导出不同场景设置(如亮度强度、相机镜头、物-相机距离)下的脉冲相机的最大可检测速度。
-
论文5: DynSNN: A Dynamic Approach to Reduce Redundancy in Spiking Neural Networks
- 由上海交通大学研究人员发表于ICASSP 2022,提出了一个适用于SNN神经元的动态剪枝框架dynamic pruning framework(DynSNN),可以用于训练阶段也可以用于推理阶段。
- 通过对神经元的放射率设置阈值,低于阈值的神经元被认为是fading neuron。
- 在训练阶段使用:首先先标识出fading neurons然后对其连接的权重进行随机初始化,训练结束时如果神经元放射率还是低于阈值就从网络拓扑结构里移除。
- 在推理阶段使用:通过训练期间确定的阈值识别fading neurons,并从 SNN 计算中mask off这些神经元。
-
论文6: Optimizing The Consumption Of Spiking Neural Networks With Activity Regularization
- 由苏黎世大学研究人员发表于ICASSP 2022。
- 在转换前的ANN中加入activity正则化进行约束能够有效降低转换后SNN的突触操作数量和脉冲数量。对转换后的SNN进一步微调和正则化能够在保持精度的同时进一步稀疏化网络。
- 对转换前的ANN进行activity正则化约束可以通过以下损失函数:

-
- 由耶鲁大学研究人员发表于ICASSP 2022。
- 论文通过比较直接编码方式和速率编码方式得出结论:
1. 直接编码相对于速率编码在图像分类中能达到更高的精度;
2. 直接编码由于使用一个可学习的编码层对输入进行编码,这会导致梯度可以反向传播回输入图像,从而更容易受到对抗攻击的影响;
3. 在Eyeriss上实验得出:速率编码的SNN比起直接编码的SNN有着更高的energy-efficiency。
-
- 由中国科学院自动化所(张铁林组)研究人员发表于ICASSP 2022。
- 提出了MR-SNN网络,使用Motif topology和reward learning改进SNN的学习。
- 首先使用pseudo-BP和reward-learning在视觉数据集和听觉数据集上分别训练网络学习权重以及Motif mask,然后将两个Motif mask进行合成并使用合成后的Motif mask重新训练权重,最后在多感官分类任务中进行测试。
-
论文9: Event-Based Multimodal Spiking Neural Network with Attention Mechanism
- 由浙江大学(唐华锦组)研究人员发表于ICASSP 2022。
- 使用视觉子网络、听觉子网络和attention-based多模态交叉融合子网络构建了一个端到端的视听多模态SNN,整体框架如下图。
- 视觉子网络中使用卷积SNN,听觉子网络中使用循环SNN。
- attention-based多模态交叉融合子网络对视觉和听觉子网络的输出进行concatenate然后将其送入全连接层中,在该模块的最后一层通过使用fully connected layer学习两个模态信息的权重,然后权重用于对视听子网络的输出进行加权并输出最终结果。

attention-based多模态SNN架构 - 整体训练方案:损失函数由视听子网络的损失函数和整体多模态的MSE损失函数相加组成,训练中使用STBP算法并使用矩形函数的导数作为脉冲函数的替代梯度。
-
论文10: A Hybrid Learning Framework for Deep Spiking Neural Networks with One-Spike Temporal Coding
- 由新加坡国立大学(张马路)、香港中文大学研究人员发表于ICASSP 2022。
- 提出了先训练一个ANN将其转换为SNN,然后再对SNN进行微调的混合学习框架。
- 在训练的时候施加几个限制:
- activation constraint:限制ANN中ReLU激活函数的输入
;
- weight sum constraint:限制一个神经元和前一层所有神经元的权重之和等于1;
- full contribution property:极大概率在第
层的神经元放电时间晚于第
层的神经元;
- force firing:限制神经元的最晚放电时间(第一层的神经元最晚放电时间为2s,第二层的神经元放电时间
,第三层的神经元放电时间
…).
- activation constraint:限制ANN中ReLU激活函数的输入
- 将前两个限制施加到损失函数上形成一个新的损失函数然后对ANN进行训练。
- 在对转换后的SNN进行微调的时候应用作者之前提出的STDBP算法(发表于TNNLS 2022)。
-
论文11: Supervised Training of Siamese Spiking Neural Networks with Earth Mover’s Distance
- 由AGH科技大学研究人员发表于ICASSP 2022,训练了一个脉冲孪生神经网络。
-
论文12: A Time Encoding Approach to Training Spiking Neural Networks
- 由洛桑联邦理工学院研究人员发表于ICASSP 2022。
- 通过借助于time encoding machines (TEMs)来求解线性约束从而训练单层和两层的SNN,不需要进行BP训练参数。
- 目前能解决的问题还需要满足一定约束。
NEURAL COMPUTATION
- 论文1: Training Deep Convolutional Spiking Neural Networks With Spike Probabilistic Global Pooling
- 由浙江大学(唐华锦)团队发表于NEURAL COMPUTATION。
Neural Networks
- 论文1: Modeling learnable electrical synapse for high precision spatio-temporal recognition
- 由西安交通大学、中国科学院自动化所(李国齐)发表于Neural Networks
- 大多数研究都只关注细胞之间的化学突触(即不同层神经元之间的权重),该工作关注电突触,能够在彼此非常接近的体细胞之间形成,并通过间隙连接在局部交换信息,能够在耦合细胞之间直接传递电压信号。
- 构建Electrical Coupling LIF (ECLIF)模型,其中的电突触使得一个神经元的膜电位会影响相邻神经元的膜电位,通过1D卷积和2D卷积实现电突触的效果。

IEEE TCYB(IEEE Transactions on Cybernetics)
- 论文1: Toward Efficient Processing and Learning With Spikes: New Approaches for Multispike Learning
- 由天津大学(于强)、浙江大学(唐华锦)团队发表于IEEE TCYB。
- 提出了一个简化的LIF神经元(类似于SRM神经元的形式),又提出了两个多脉冲学习规则(EML和EMLC)。除此之外还应用STDP在特征检测任务上进行无监督学习,实验结果显示STDP进行特征检测在长时间学习的情况下效果会严重下降。
TNNLS(IEEE Transactions on Neural Networks and Learning Systems)
-
论文1: Supervised Learning in Multilayer Spiking Neural Networks With Spike Temporal Error Backpropagation
- 由电子科技大学计算机科学与工程学院计算智能团队发表于TNNLS。
- 基于SRM神经元,提出要同时学习神经元中的权重和突触延迟(synaptic decay),和作者以前提出的FE-Learn(first error learning)方法相结合来调节突触权重和延迟,并将其用于多层SNN中,取得了不错的效果。
-
论文2: Spiking Adaptive Dynamic Programming Based on Poisson Process for Discrete-Time Nonlinear Systems
- 由中国科学院自动化所(张铁林组)发表于TNNLS。
-
论文3: Synaptic Learning With Augmented Spikes
- 由天津大学(于强)发表于TNNLS。
- 提出了augmented spiking neuron model,其中每个神经元发放的脉冲有着不同的时间和强度(脉冲数量),信息同时由时间和强度来传递,在神经元的PSP核函数前加上脉冲系数来携带脉冲的极性和幅度信息。将LIF神经元修改为

- 结合Tempotron、PSD、TDP等学习方法使用augmented神经元。
-
论文4: Rectified Linear Postsynaptic Potential Function for Backpropagation in Deep Spiking Neural Networks
- 由电子科技大学(张马路组)发表于TNNLS,STDBP算法。
- 提出了基于新的PSP(突触后电势)函数ReL-PSP的新神经元:

-
- 由天津大学(于强)发表于TNNLS。
- 提出了两种ANN转SNN的方法。
- 第一种方法是使用正负双阈值的脉冲神经元,这样脉冲神经元就可以表示正值也可以表示负值,也可以在ANN中使用LeakyReLU激活函数。
- 第二种方法是使用augmented spiking neuron model,同样有正负阈值,神经元电压达到正负阈值时可以根据其电压强度发放多个脉冲。
- 论文中还给出了正负阈值和LeakyReLU函数中控制激活函数形状参数的关系:

-
论文6: Event-Driven Intrinsic Plasticity for Spiking Convolutional Neural Networks
- 由福州大学研究人员发表于TNNLS。
-
论文7: Robust Transcoding Sensory Information With Neural Spikes
- 由大连理工大学研究人员、浙江大学(唐华锦)发表于TNNLS。
- 提出了一个转码框架,将多模态感官信息编码到神经脉冲,然后从脉冲重建刺激,能够将感官信息压缩到10%的脉冲再通过重构重新提取出100%的感官信息,对各种类型的人工噪声和背景信号具有超强的抗噪声能力。
- 将各种类型的输入转换成统一的格式(如64*64的图像),然后在编码部分将图像编码为脉冲。
- 在解码部分再将脉冲转换为图像后对图像使用autoencoder进行重构(也可以直接使用SNN对脉冲进行解码)。
- 图像转脉冲:使用300个神经元覆盖整个图像空间(可以根据图像大小调整神经元数量)。
-
论文8: Improving Multispike Learning With Plastic Synaptic Delays
- 由天津大学于强组发表于TNNLS,基于作者之前的多脉冲学习TDP,在多脉冲学习中同时调节突触权重和延迟。
- 突触权重和突触延迟调节如下图:

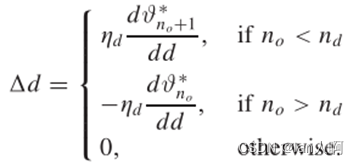
-
论文9: Multisample Online Learning for Probabilistic Spiking Neural Networks
- 由伦敦国王学院研究人员发表于TNNLS。
-
论文10: Online Spatio-Temporal Learning in Deep Neural Networks
- 由伦敦国王学院研究人员发表于TNNLS。
-
论文11: The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks
* -
论文12: Efficient Spiking Neural Networks With Radix Encoding
- 由新加坡科技研究局 (A*STAR) 高性能计算研究所研究人员发表于TNNLS。
ICML(共4篇)
-
论文1: State Transition of Dendritic Spines Improves Learning of Sparse Spiking Neural Networks
- 由北京大学余肇飞组发表于ICML2022。
- 将生物神经元中的dendritic filopodia建模为重新参数化映射来对SNN进行稀疏化。
- 建模两种状态转移:filopodia和mature spine之间的状态转移;兴奋性突触和抑制性突触之间的状态转移。
- 将spine/filopodium的size用
表示,连接size的阈值用d表示,在训练过程中d逐渐增大。w可以表示为下图:

- 在training时自适应调节权重和
-
论文2: AutoSNN: Towards Energy-Efficient Spiking Neural Networks
- 由首尔国立大学研究人员发表于ICML2022。
- 第一次在SNN中使用神经解构搜索(neural architecture search,NAS),提出了一个脉冲感知NAS框架:AutoSNN。
将搜索空间定义为宏观的主干结构和微观的候选block,在搜索最合适的SNN结构时按照两个步骤:首先根据宏观的主干结构训练一个super-network,然后根据architecture fitness来找到最合适的微观候选block。 - 全局平均池化(GAP)对SNN的精度和能量效率都有负面影响,不适用于SNN中。使用卷积进行下采样效果好些,使用最大池化进行下采样比较节省能量。
-
- 由哈佛大学研究人员发表于ICML2022,非脉冲神经网络。
- 提出了Scalable Spike-and-Slab,一个用于高维贝叶斯回归的可扩展的Gibbs采样实现。
-
论文4: Neural Network Poisson Models for Behavioural and Neural Spike Train Data
- 由莫纳什大学研究人员发表于ICML2022,非脉冲神经网络。
- 提出了一个端到端的模型,利用最近发展的灵活但易于处理的神经网络点处理模型来描述刺激、动作和神经数据之间的依赖性。
CVPR(共6篇)
-
论文1: Brain-inspired Multilayer Perceptron with Spiking Neurons
-
- 由香港中文大学(深圳)研究人员发表于CVPR 2022,相关代码。
- 提出了Differentiation on Spike Representation (DSR) method来训练SNN,将LIF神经元和IF神经元的前向传播过程使用可微分的脉冲表示来替代,在BP训练时使用可微分的脉冲表示的梯度更新参数,从而避免了在时间域上BP也避免了脉冲活动的不可微分性。
- LIF神经元和IF神经元的脉冲表示如下图:

- 为了在较小的time step下提升算法的效果,标识出表示过程中存在的两个误差:quantization error和deviation error。从统计学的观点来看deviation error的期望值接近0,因此提出两种方法来降低quantization error。
- 使用可自学习的脉冲神经元阈值,并在损失函数值使用L2正则项对阈值进行约束(小阈值能降低quantization error但是也会降低SNN的表示近似程度)。
- 在脉冲发放函数中引入一个新的超参数(IF神经元可以设置为0.5)

在实验中使用直接编码方式将图像直接送入SNN,此时第一层网络可以视为脉冲编码器。
-
论文3: Event-based Video Reconstruction via Potential-assisted Spiking Neural Network
- 由北京大学Tiejun Huang组研究人员发表于CVPR 2022,论文代码。
-
论文4: RecDis-SNN: Rectifying Membrane Potential Distribution for Directly Training Spiking Neural Networks
- 由中国航天科工二院研究人员发表于CVPR 2022,提出了MPD-Loss去显式地惩罚SNN训练过程中的膜电势(membrane potential distribution,MPD)偏移,其网络叫做RecDis-SNN(Rectified membrane potential Distribution)。
- 动机:随着脉冲逐层传播,膜电势的分布会逐渐的产生偏移(shift)并随着训练过程越来越严重。膜电势偏移会引起以下三种不平衡:
- Degeneration:如果一个通道中几乎所有神经元的膜电位值都超过或低于发放阈值,则该通道的脉冲将是同质的(即全0或全1),该通道的特征信息可以忽略不计;
- Saturation:如果通道中几乎所有神经元的膜电位值都超出区间 [0,1],则这些神经元的梯度将为0,导致无法BP。(所有神经元的膜电势都高于阈值太多,使用BP时即使使用替代函数其导数也接近于0)。
- Gradient mismatch:如果一个通道中几乎所有的膜电位值都落入区间[0,1],则相当于所有梯度计算都使用替代函数,这会扩大替代梯度的近似误差,从而导致更严重的梯度不匹配。
- 方法:假设膜电势的分布服从高斯分布,根据高斯分布的均值和标准差去构造膜电势的下
分位数和下
分位数,对于以上三种误差分别使用三种不同的损失函数去进行显式的惩罚,对于分类任务在最终的损失函数中再加上交叉熵损失函数。
-
论文5: Spiking Transformers for Event-Based Single Object Tracking
- 由大连理工大学研究人员发表于CVPR 2022,论文代码。
-
由北京大学Tiejun Huang组研究人员发表于CVPR 2022,论文代码。
ECCV
- 论文1: Lottery Ticket Hypothesis for Spiking Neural Networks
- 由耶鲁大学研究人员发表于ECCV 2022。
- 复杂的深层SNN里包含有较小的子网络(中奖彩票),这些子网络的性能和深层SNN性能相似但规模更小更稀疏。
- 论文2: Neuromorphic Data Augmentation for Training Spiking Neural Networks
- 由耶鲁大学研究人员发表于ECCV 2022。
- 对dynamic vision sensor(DVS)数据以index-based geometric augmentation(几何增强)的方式进行神经形态数据增强(Neuromorphic Data Augmentation,NDA),主要包含有Horizontal Flipping、Rolling、Rotation、Cutout、Shear、Mixup。Flipping和mixup默认使用,使用超参数M表示另外选取的增强方法数量,超参数N表示增强的强度intensity。文中还使用对比学习的方式训练一个encoder用于迁移学习。
- 论文3: Neural Architecture Search for Spiking Neural Networks
- 由耶鲁大学研究人员发表于ECCV 2022。
- 论文4: Real Spike: Learning Real-valued Spikes for Spiking Neural Networks
-
由中国航天工业集团公司智能科技研究院研究人员发表于ECCV 2022。
-
指出:在深度学习中常用的权重共享机制(比如卷积核)在SNN中并没有一样的效果,因此在SNN可以通过使用不共享的权重来提升其性能。
-
论文提出了Real Spike,神经元在训练时使用共享的卷积核发放real-valued spike,在推理时使用不共享的卷积核并且发放二元脉冲。
-
Real Spike:给脉冲神经元的输出乘以一个可学习的权重a即可使得原本为1的脉冲变成任意模拟值。脉冲卷积层的输入输出也可以这样变为实值数据。
-
在推理的时候,从卷积层的输入数据的每一个实值元素中提取出其实值权重并将其根据位置折叠到共享卷积核上就能得到多个不同的卷积核(通过re-parameterization来得到非共享卷积核),公式如下:

-
扩展方式:为每一层的LIF神经元变体提供三种方式引入可学习的权重a:
(1)每一层神经元共享一个a;
(2)每一层的神经元每个通道的神经元共享一个a;
(3)每一层的每个神经元有一个独立的a。
-
- 论文4: Reducing Information Loss for Spiking Neural Networks
- 由中国航天工业集团公司智能科技研究院研究人员发表于ECCV 2022。
ICLR(共4篇)
-
论文1: Optimal ANN-SNN Conversion for High-accuracy and Ultra-low-latency Spiking Neural Networks
- 由北京大学于肇飞组发表于ICLR2022,论文代码链接
- 分析了ANN-SNN转换中的三种误差:Clipping error、Quantization error和Unevenness error(不均匀误差)并且提出了quantization clip-floor-shift activation function去替代ANN中的Relu函数。
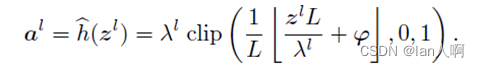
- 其中的
是可训练的参数,训练时的梯度计算如图:
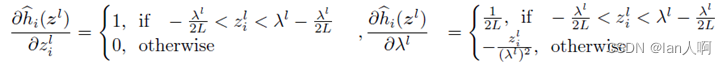
-
论文2: Spike-inspired rank coding for fast and accurate recurrent neural networks
- 由伦敦大学学院研究人员发表于ICLR2022。
- 将SNN中的Rank Coding引入RNN中去训练,从而能够使得RNN训练和推理的时间降低。牺牲了一小部分的精度换来了更快的速度。
-
- 由佐治亚理工学院研究人员发表于ICLR2022,指出通过异构神经元和skip-layer连接能够更好地逼近target脉冲序列,提出了Dual-search-space Bayesian Optimization来搜索最优网络结构和参数。
- 引理1:对于周期在[tmin,tmax]内的任意输入脉冲序列,存在着一个脉冲神经元(其阈值、重置膜电位、时间常数等参数都固定),通过改变该膜电位的可学习的参数突触电导G可以使其响应速率γ(神经元电压达到阈值需要接收的输入脉冲数量)为任意正整数。
- 定理1:通过将一组具有特定的响应速率序列γ的脉冲神经元按顺序连接并插入skip-layer连接(将source层的输出脉冲矩阵concatenated到target层的输入脉冲矩阵上),可以实现具有脉冲周期映射函数P (t)的网络来逼近目标脉冲序列。
- 引理2:如果不存在skip-layer连接的化,就不存在具有特定脉冲周期映射函数的网络,也就不能逼近目标脉冲序列。
- 引理3:一个脉冲神经元具有cutoff period,超过这个截止周期后输入的脉冲序列不能使神经元产生脉冲。
- 通过改变神经元参数可以使得神经元的cutoff period为任意正实数。
- 异构网络(网络中每一层的神经元有着不同的dynamics)和增加skip-layer都能够增加前馈SNN中不同记忆通路的最大可达数量。
- Dual-search-space Bayesian Optimization:分离离散搜索空间和连续搜索空间。先固定离散的网络参数去优化连续的网络结构信息,获取到最优的网络结构信息后再去固定网络结构优化网络参数。
-
论文4: Temporal Efficient Training of Spiking Neural Network via Gradient Re-weighting
-
由电子科技大学顾实组发表于ICLR2022,论文代码链接。
-
提出了temporal efficient training (TET)方法(对输出相对于权重的梯度进行重加权reweighting)来补偿梯度下降中的动量损失,使训练过程可以收敛到更平坦的最小值,具有更好的泛化性。
-
在训练阶段引入了新的损失函数优化每一个时刻的输出:
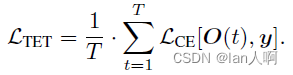
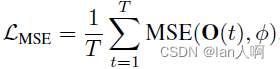
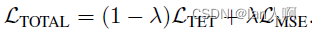
-
使用Time Inheritance Training (TIT)节省训练时间:首先用比较多的epoch和比较小的time step进行训练,然后增加time step至想要使用的time step并使用较小的epoch进行训练。
-
-
撤稿论文2: One Timestep Is All You Need: Training Spiking Neural Networks with Ultra Low Latency
- 普渡大学研究人员作,论文代码链接。
- 首先训练一个ANN然后将其转换为具有T个time step的SNN并使用BP算法进行训练,然后对训练好的SNN使用更少的time step进行训练再让其收敛,逐渐迭代能使得其在time step=1时达到不错的性能。
- 实验中使用直接编码,脉冲神经元的阈值、突触时间延迟
以及模型的权重都是可学习的。
-
撤稿论文3: Training Deep Spiking Neural Networks with Bio-plausible Learning Rules
本文出自于CSDN-lan人啊,转载请注明!
文章出处登录后可见!