hive/hql/sql 计算最长连续登录天数
sql计算最长连续登录天数
🌈 嗨,大家好,我是要努力成为大数据专家的Gene
🌈 我又回来发博客了
🌈 一起增长技术,一起🐮
前文:
我们hive里常会遇到类似的sql逻辑,也是我们面试的时候常被问到的如:
-
A:连续登陆3天的用户
-
B:最长连续登陆天数
那么我们来学习一下这种hql 思路吧
数据案例
ods 初始表
| uid | login_time |
|---|---|
| 1 | 2022-09-17 11:21 |
| 1 | 2022-09-18 11:21 |
| 1 | 2022-09-19 11:21 |
| 1 | 2022-09-22 11:33 |
| 2 | 2022-09-10 11:33 |
| 2 | 2022-09-10 14:33 |
| 2 | 2022-09-11 11:33 |
案例
1.清洗数据
现象:
如果原表给出的是登陆时间是时分秒的话,用户一天可能多次登陆,同一天多次登陆的情况
因此我们需要进行数据清洗
方案:
- 可以使用日期转型,时分秒—>yyyymmdd
- 按uid和login_time 分组去重
我们这里使用 data() 进行清洗就可以,然后groupby分组去重
这种表一般dwd层之后,就不存在了。一般存在于ods的用户登陆日志表。
-- 把ods的原始表 清洗后 刷到dwd表 dwd_user_login_d
INSERT OVERWRITE TABLE dwd_user_login_d PARTITION ('${event_day}')
-- event_day 为今天的日期分区
select
uid
,data(login_time) -- 转成日期
from ods_user_log
where dt='${event_day}'
group by id,login_time
我们假设把清洗后的数据存成了dwd层的用户登陆表
变成
| uid | login_time |
|---|---|
| 1 | 2022-09-17 |
| 1 | 2022-09-18 |
| 1 | 2022-09-19 |
| 1 | 2022-09-22 |
| 2 | 2022-09-10 |
| 2 | 2022-09-10 |
| 2 | 2022-09-11 |
2. 下面我们进入问题:连续登陆用户
我们可以采用 row_number()over() + date_sub ()的方式,方法如下:
- 首先 我们对用户的登陆天数排序
这里我们用row_number()over()窗口函数
select
uid
,login_time
,row_number()over(partition by uid order by login_time) as rank
from
dwd_user_login_d
| uid | login_time | rank |
|---|---|---|
| 1 | 2022-09-17 | 1 |
| 1 | 2022-09-18 | 2 |
| 1 | 2022-09-19 | 3 |
| 1 | 2022-09-22 | 1 |
| 2 | 2022-09-10 | 1 |
| 2 | 2022-09-11 | 2 |
| 2 | 2022-09-10 | 已经去重 |
2 然后用登陆时间减去排序号
DATE_SUB( login_time, rank )
解析:如果用户是连续登录,比如09-17 、18、19日都进行了登陆
DATE_SUB 登陆日期-排序序号 计算的逻辑就得到了
如下的连续登录的的前一天的日期
2022-09-17 -1 = 2022-09-16
2022-09-18 -2 = 2022-09-16
2022-09-19 -3 = 2022-09-16
所以如果用户连续登录那么登陆日期减去rank 得到的日期是一样的
对这个一样的日期进行计数,我们就可以得到这个用户的连续登录的的前一天
为开始的日期
的连续登录天数
字段为: login_group
| uid | login_time | rank | login_group |
|---|---|---|---|
| 1 | 2022-09-17 | 1 | 2022-09-16 |
| 1 | 2022-09-18 | 2 | 2022-09-16 |
| 1 | 2022-09-19 | 3 | 2022-09-16 |
| 1 | 2022-09-22 | 1 | 2022-09-21 |
| 2 | 2022-09-10 | 1 | 2022-09-09 |
| 2 | 2022-09-11 | 2 | 2022-09-09 |
| 2 | 2022-09-10 | 已经去重删除 | – |
3 根据日期差 login_group 字段出现的次数
按 uid 、日期差 分组groupby ,count 得到用户连续登录的天数
不过 用户可能在不同时间段都进行过登录,所以连续登录天数可能发生过几次
固我们加入 min(login_time) 连续登录开始日期/ max(login_time) 连续登录结束日期 计算同分组下的最小最大时间,标识 连续登录开始日期/连续登录结束日期
select
uid
,login_time --登陆日期
,date_sub(login_time,rank) as login_group -- 日期差
,min(login_time) as start -- 连续登录开始日期
,max(login_time) as end -- 连续登录结束日期
,count(1) as continue_days -- 连续登录天数
(
-- select
-- uid
-- ,login_time
-- ,row_number()over(partition by uid order by login_time) as rank
-- from dwd_user_login_d
) a
group by uid,date_sub(login_time,rank)
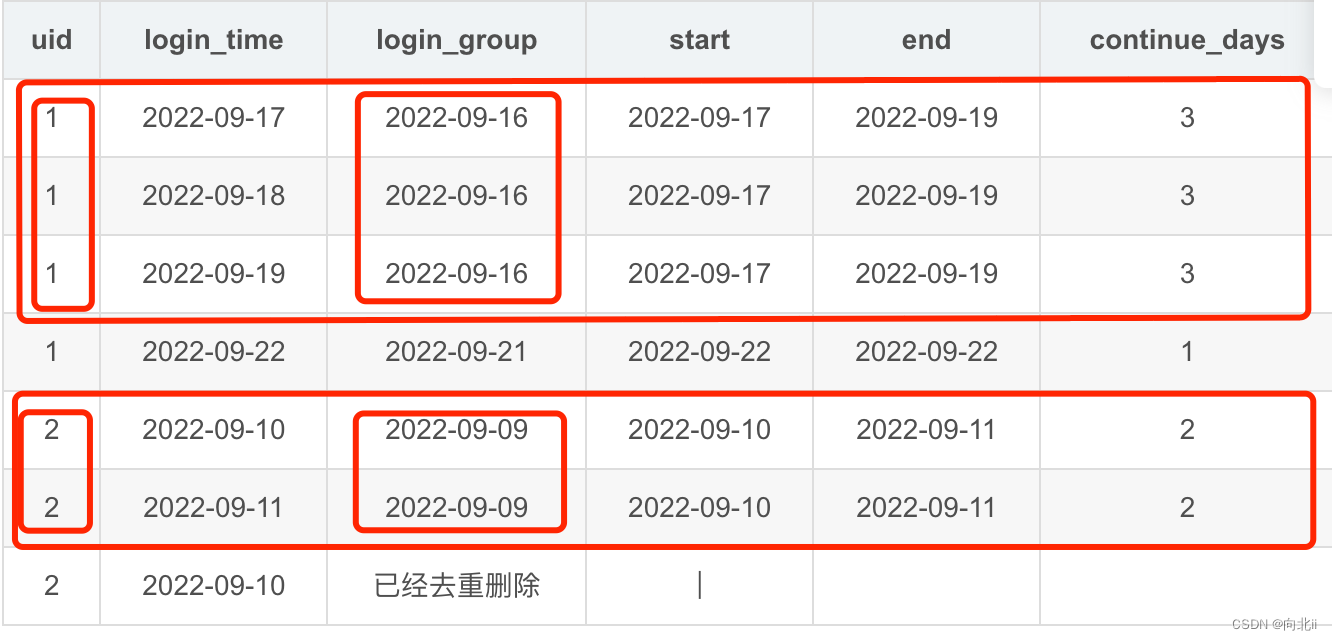
| uid | login_time | login_group | start | end | continue_days |
|---|---|---|---|---|---|
| 1 | 2022-09-17 | 2022-09-16 | 2022-09-17 | 2022-09-19 | 3 |
| 1 | 2022-09-18 | 2022-09-16 | 2022-09-17 | 2022-09-19 | 3 |
| 1 | 2022-09-19 | 2022-09-16 | 2022-09-17 | 2022-09-19 | 3 |
| 1 | 2022-09-22 | 2022-09-21 | 2022-09-22 | 2022-09-22 | 1 |
| 2 | 2022-09-10 | 2022-09-09 | 2022-09-10 | 2022-09-11 | 2 |
| 2 | 2022-09-11 | 2022-09-09 | 2022-09-10 | 2022-09-11 | 2 |
| 2 | 2022-09-10 | 已经去重删除 | | |
4 下一步清洗去重,按uid 、login_group 分组去重 orderby 保留 login_time 最大的
红框中只保留一条!!
3. 这里答案就出来了
- A: 如果我们想求
连续3天登陆的用户 - where continue_days=3
- 就好了
- B:如果我们想求用户
最大登陆天数 - 我们直接 按uid分组
- max(continue_days) 就得到每个用户的最大连续登陆天数了
小结
小章节 完结啦,有什么想交流的
欢迎留言评论呀
欢迎点赞收藏
感谢大家啦
文章出处登录后可见!