案例与数据
某研究者想要研究关于教师懈怠感的课题,教师懈怠感是指教师在教育情境的要求下,由于无法有效应对工作压力与挫折而产生的情绪低落、态度消极状态,这种状态甚至会引发心理、生理的困扰,终至对教育工作产生厌倦,缺乏热忱与成就感。影响教师倦怠感的因素相当复杂,为了研究教师倦怠感的原因,研究者分发收集了1430份问卷,在正式分析前想要研究实际数据是否符合理论模型假设的结构,部分数据如下:
分析问题
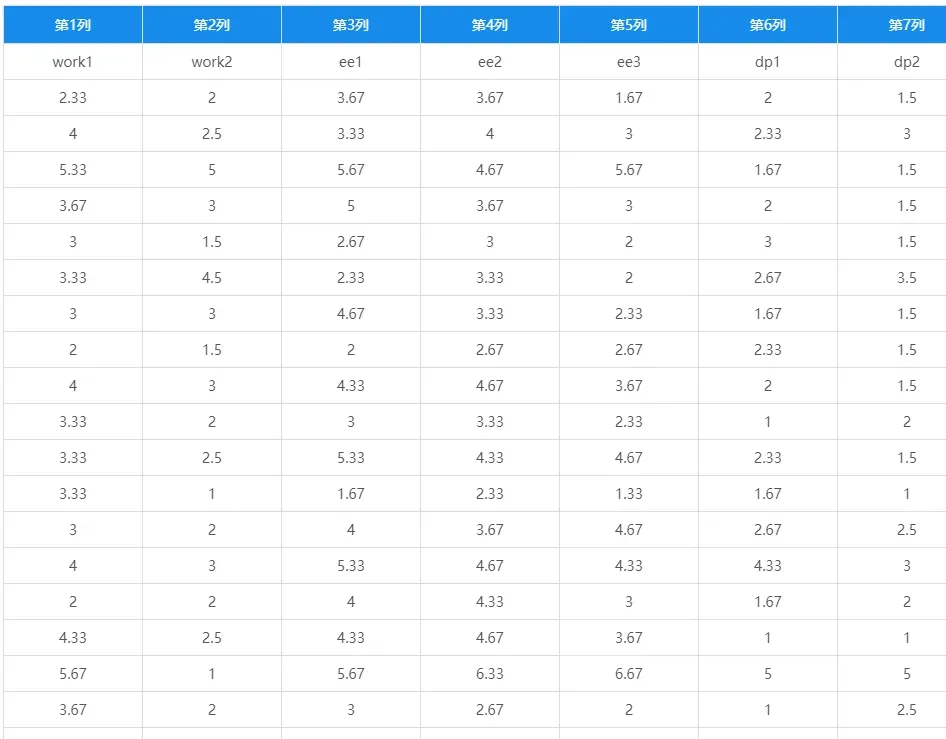
想要研究实际数据是否符合理论模型假设的结构,这7个测量变量一共测量了三个变量,其中work1和work2用于测量工作超负荷,ee1、ee2、ee3用于测量情感枯竭,dp1和dp2用于测量自我感丧失,可以利用验证性因子分析对数据的合理性进行分析,假设模型如下:
分析前检验
在使用问卷调查数据之前,需要对该数据进行信效度分析,以证明问卷设计问题具有较高的解释力,以及模型设计的问题能够反映模型中的潜变量。接下来分别进行说明。
内在信度
内在信度顾名思义指问卷内部的可信度,SPSSAU共提供四种信度系数,其中包括Cronbach α系数、折半信度系数、McDonald’s ω信度系数、theta信度系数,一般Cronbach α系数比较常用,这里也使用Cronbach α系数进行描述。其中有三个维度,所以按维度进行,整理表格如下:
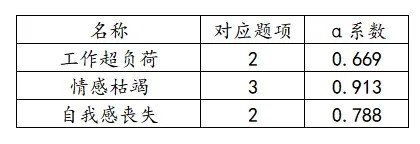
三个维度则有三个α系数值,从表格中可以看出α系数均大于0.6,表述信度质量可以接受,可以进行下一步操作。
探索性因子分析
在进行验证性因子分析前,一般会先进行探索性因子分析,该步骤不仅可以分析测量题项设计是否合理还可以分析变量与测量项的对应关系。
对于测量题项设计是否合理一般使用 KMO值(判断变量之间相关性指标)和 Bartlett 球形检验方法(用于检验各变量是否互相独立),KMO 值大于或者等于0.7时,认为其非常适合做因子分析,在0.5以下不适合使用。拒绝原假设说明可以做因子分析。操作如下:
结果如下:

从上表可以看出KMO值为0.809大于0.7,并且Bartlett 球形检验p值小于0.05拒绝原假设,说明数据适合进行分析。接下来查看变量与测量项的对应关系(旋转后因子载荷系数表格)。整理后如下:
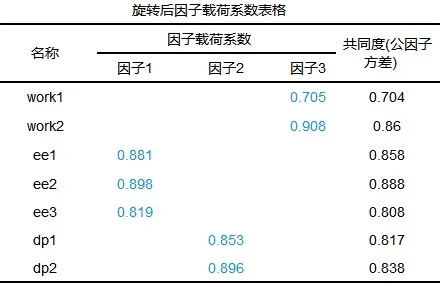
上表中共3个因子均来自初始问卷的原有假设因子,把第一个因子命名为“情感枯竭”其中包括“ee1、ee2和ee3”,把第二个因子命名为“自我感丧失”其中包括“dp1、dp2”、第三个因子命名为“工作超负荷”其中包括“work1和work2”。发现变量与分析项之间的对应关系良好。可以进行CFA分析。
CFA模型构建与修正
验证性因子分析(CFA)是在先前探索性因子分析获得一直因子的情况下。检验所搜集的数据是否按事先预定的结构方式产生作用,从而说明因子的理论模型拟合实际数据的能力。
在进行模型评价前,首先要查看模型是否需要修正,如果模型不能很好的拟合数据,就需要修正,如果拟合指标好,则不需要该步骤,模型拟合指标有许多测量标准,一般在报告中对常用指标进行描述即可,部分指标说明如下:
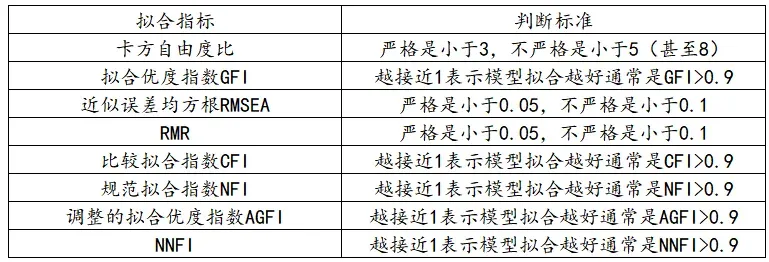
对于CFA模型的修正,包括删除不合理项和建立协方差关系(如下有说明)两项。模型的修正最好基于一定的理论基础,比如:专业上不允许即使MI值很大也不能修正模型,或者增加路径无实际意义等。
CFA操作如下:
指标拟合如下:
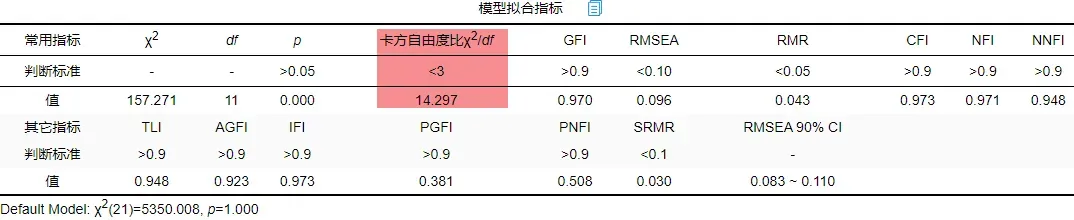
表中展示的卡方自由比为14.297远远大于标准3,所以需要进行修正。其余常用指标在可接受范围内。
CFA模型构建
对于模型的构建需要检查是否含有不合理项,不合理测量项;如果因子与测量项间的对应关系出现严重偏差,此时可考虑删除某测量项;也或者某测量项与因子间的载荷系数值过低(比如小于0.5),说明该测量项与因子间关系较弱,需要删除掉该测量项。结果如下:
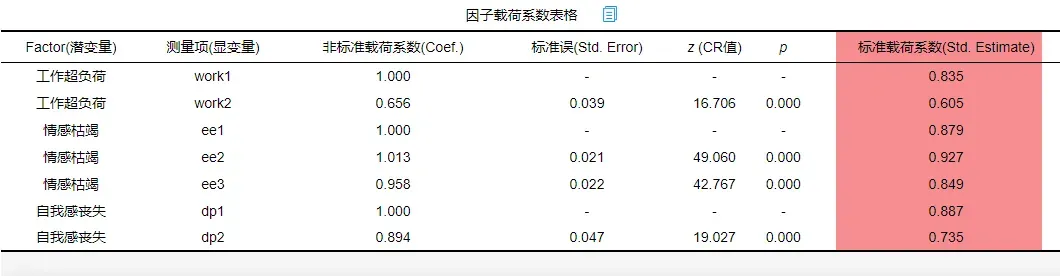
从上表可以看出,测量关系时,标准化载荷系绝对值均大于0.6且呈现出显著性,意味着有着较好的测量关系。所以无需删除分析项。那么是否需要建立协方差关系呢?
建立协方差关系
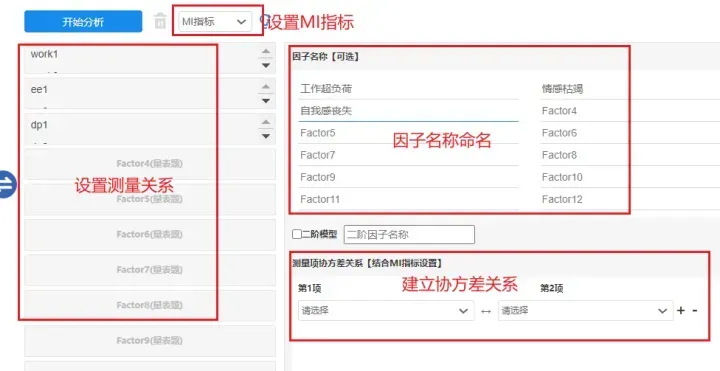
协方差关系是指建立项之间的相关关系,一般来讲,MI指标越大,说明关联关系越强越应该建立关系。MI指标是用于调整模型的一个指标,一般MI大于20需要进行调整。首先让SPSSAU输出MI指标,MI指标的选择有很多,通常选择“MI>10”进行输出。如下:
结果如下:
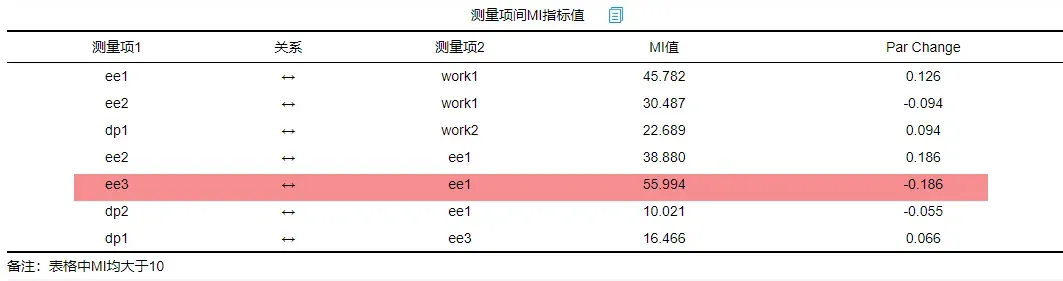
从图可以看到,ee3和ee1之间的MI值最大为55.994,也就是说如果ee3和ee1之间建立协方差关系,意味着预期可以减少卡方值为55.994,因而可考虑建立该两项之间的协方差关系。
建立协方差关系如下:
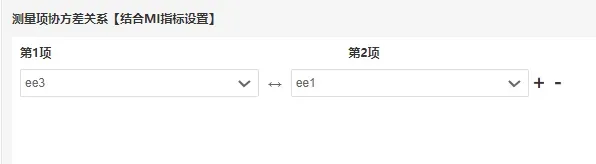
结果如下:
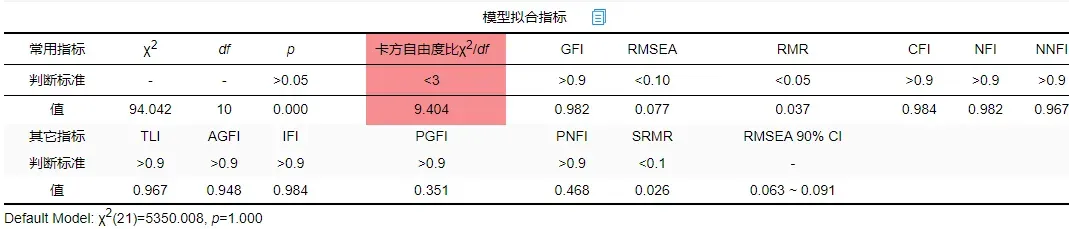
发现卡方自由度比仍然不达标需要继续进行修正。

建立ee1和work1之间的协方差关系如下:
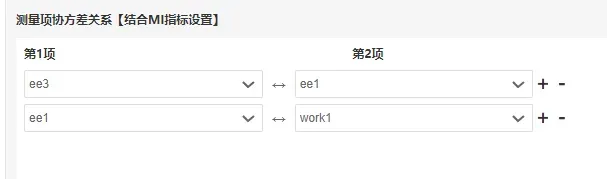
结果如下:
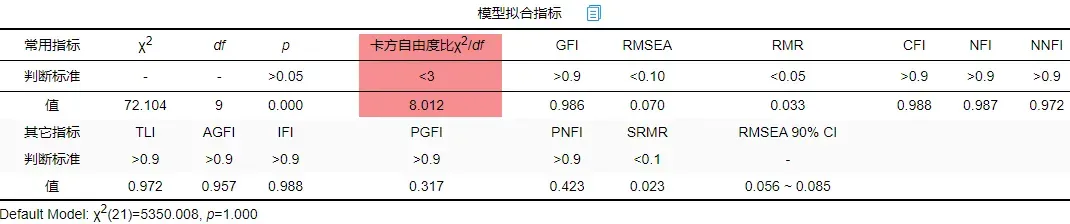
发现卡方自由度比仍然不达标需要继续进行修正。重复上述步骤,分析后建立ee2与ee1之间的协方差关系。结果如下:
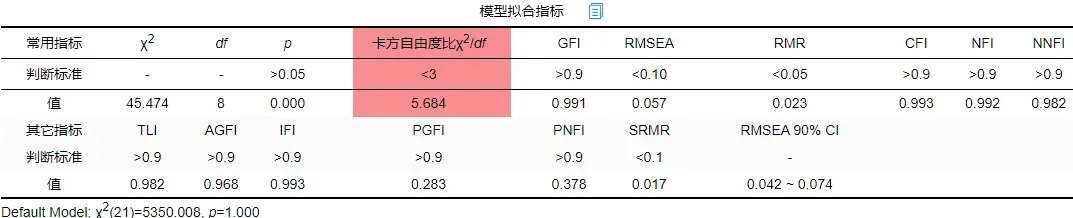
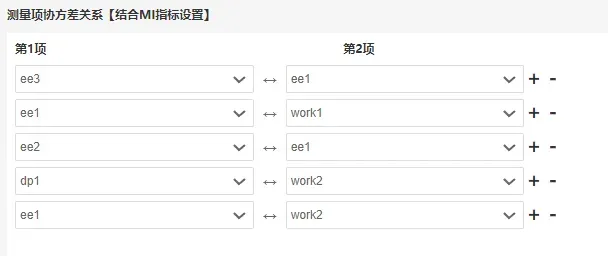
重复进行修正,直到模型拟合指标达到可接受范围内,建立的协方差关系如下:
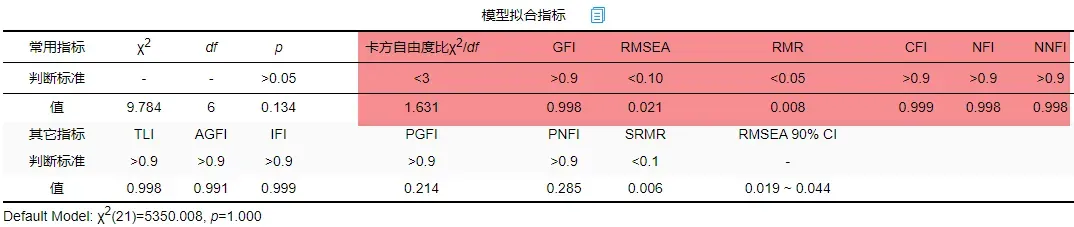
最终结果如下:
最后在原模型上建立了“ee3”与“ee1”、“ee1”与“work1”、“ee2”与“ee1”、“dp1”与“work2”、“ee1”与“work2”共5个协方差关系(所有添加路径均有意义),最终模型如下:
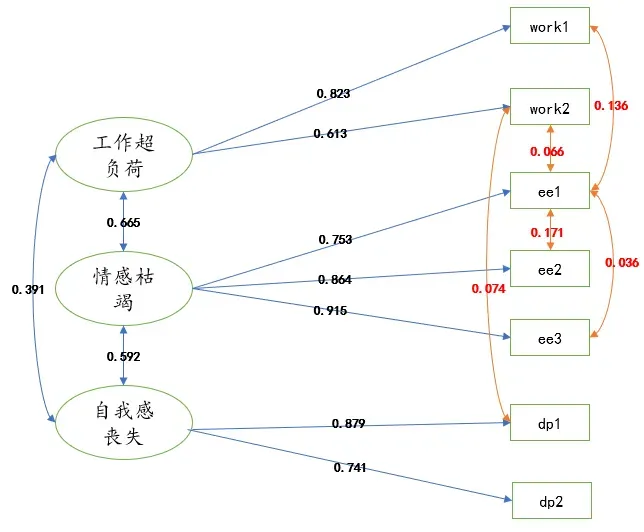
最后对模型进行评价,包括区分效度、聚合效度以及模型拟合程度。
CFA模型评价
利用验证性因子分析可以得到聚合效度和区分效度的好坏,首先进行聚合效度的说明。
聚合效度
聚合效度强调本应该在用一个因子下面的测量项,确实在同一个因子下,一般观察AVE和CR指标。AVE反映了每个潜变量所解释的变异量中有多少来自该潜变量中所有题目,加入AVE越高,则表示潜变量(factor)有越高的收敛效度,一般需要大于0.5,CR值是所有测量变量信度的组合,表示潜变量(factor)的内部一致,所以CR值越高,表示内部一致性越好,一般大于0.7。结果如下:

从上表可以看出,本模型的factor的AVE均大于0.5,CR值虽然有小于0.7的情况,但考虑接近0.7,所以表示可以接受。所以该模型各个factor具有良好的信度以及收敛效度。接下来与区分效度进行说明。
区分效度
区分效度,强调本不应该在同一因子的测量项,确实不在同一个因子下面,区分效度SPSSAU共提供三种,一种是AVE和相关分析结果对比,还有一种是HTMT(异质-单质比率)法,以及MSV和ASV法,其中AVE和相关分析结果对比比较常用,这里使用AVE和相关分析结果对比进行说明。

针对工作超负荷,其AVE平方根值为0.726,大于因子间相关系数绝对值的最大值0.550,意味着其具有良好的区分效度。针对情感枯竭,其AVE平方根值为0.846,大于因子间相关系数绝对值的最大值0.550,意味着其具有良好的区分效度。自我感丧失同样。所以可以得出数据具有良好的区分效度。至于其它检验区分效度的方法,可以查看SPSSAU帮助手册。最后岁模型拟合指标进行查看。
拟合指标值
SPSSAU提供很多指标,通常在分析中无法满足所有的指标达标,所以这里列举了常用的指标进行分析。

通过模型拟合指标结果可以查看到,所有指标均在可接受范围内,所以模型拟合良好,综上,实际数据符合理论模型假设的结构。
总结
本篇案例想要研究“实际数据是否符合理论模型假设的结构”,利用验证性因子分析进行说明,由于是问卷数据,所以进行信度分析和探索性因子分析,分析数据的信度、效度以及变量与测量项之间的关系,发现数据良好,接着对数据进行验证性因子分析,发现数据拟合不是很好,对模型进行修正,建立协方差关系,经过反复修正,最后得到更好的模型,然后对模型进行评价。分析结束。
更多信息请登录SPSSAU官网平台进行查看。
文章出处登录后可见!