目录
什么是模仿学习呢?简单来说,模仿学习(Imitation Learning),就是要训练机器能够复制人类的连续动作,进而达到模仿的目的。其实,Imitation Learning的实用性很高,假设今天有一个训练场景,你不知道该怎么定奖励值(reward),但是你可以收集到专家的示范数据(expert demonstration data),你就可以考虑用Imitation Learning这个方法。因此,模仿学习也被寄予很高的期待,成为下一代强人工智能的关键技术。
模仿学习主要有三个部分构成,首先是policy network(策略神经网络),其次是behavior demonstration(专家的连续行为,也就是示范动作),第三,就是simulator(环境模拟器)。为了达到模仿学习的目的,目前主要有2种方法,一是Behavior cloning,即行为克隆方法;二是Inverse Reinforcement Learning(IRL),即逆向强化学习方法。那么接下来,我们首先在第1部分分别介绍这三种方法,其次,在第2部分,对这两类方法进行比较,最后,在第3部分介绍Imitation Learning算法的应用。
1 算法介绍
1.1 什么是专家示范数据?
虽然很多场景下,我们没有办法定出reward,但是可以收集专家的示范数据expert demonstration data,例如,在自驾车里面,在你没有办法定出自驾车的reward,但是可以收集很多老司机开车的记录;在人机对话系统中,你可能没有办法定义什么是好的对话,什么是不好的对话,但是可以收集到很多人的对话作为示范。
好,对于模仿来说,我们首先是需要专家给出一些模仿的数据,我们称为expert demonstration data,那么,expert demonstration data是什么样式的呢?它通常是专家去观测当前时刻的Environment(环境)是什么样一个state(状态),专家在这个state下给出了一个什么样的action(动作),action作用于Environment之后,这个Environment会进入下一个state,在这个state,专家又会做出什么样的action,这样一系列的数据进行下去,我们称这个状态动作序列为一个专家示范数据。我们把专家的示范数据,拆分成状态和动作的配对,我们下面要做的模仿学习,其实是从这样的一个数据上面,来学到一个比较好的策略出来。

后面我们介绍的两种模仿学习的算法,Behavior Cloning,Inverse Reinforcement Learning,以及IRL的典型算法,Generative Adversarial Imitation Learning,他们或是想模仿一个动作,或是想模仿动作背后的一些动机,或是去对数据的整体分布进行模仿,这是两种算法去做模仿学习的思路,也是目前最主要的模仿学习方法的设计思想。
1.2 Behavior Cloning
1.2.1 算法思路
我们把专家的示范数据,拆分成状态和动作对以后,就看到这些数据,看起来就是些有标记的数据。也就是说我们可以看到每一个状态上面,专家都做了什么动作?让机器学习连续动作的直观想法是,用一种监督学习的方式,可以把这个状态作为我们监督学习里面的样本,动作作为监督学习里面的标记,把我们的状态当成神经网络的输入,把神经网络输出当成动作,最后用期望的动作,教机器学习状态和动作之间的相对应关系。如果我们这里的动作是一个理想的动作,我们可以用一些分类的算法,如果这里是一个控制的动作,我们可以用一些回归的方法。
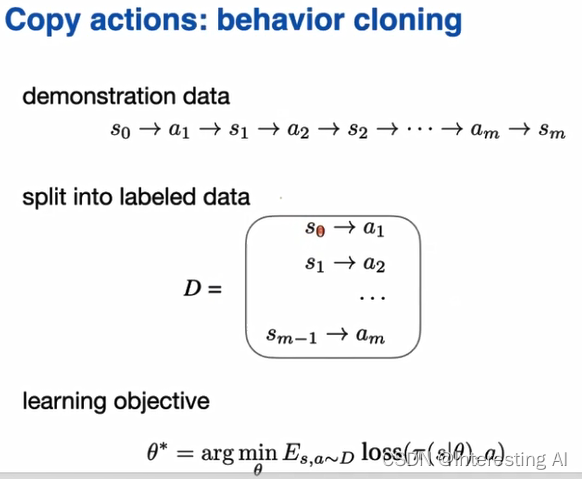
1.2.2 算法步骤
学习方法如下,首先把训练数据分成训练集合与验证集合,然后再把训练集合的误差最小化,训练到验证集合的误差一直不收敛为止。接下来将训练好的神经网络在环境中测试。首先从环境中取得当前时刻状态state,利用训练好的神经网络决定相对应的动作action,然后作用于环境,这样子一直重复到游戏结束,看训练效果。
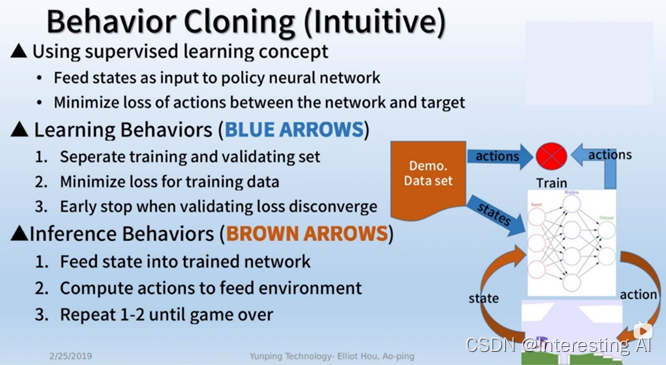
1.2.3 算法特性
(1)算法的优点是实际操作简单,也容易出错。算法训练是很有效率的,但是缺点是当训练数据少的时候,无法训练出完整的策略分布。
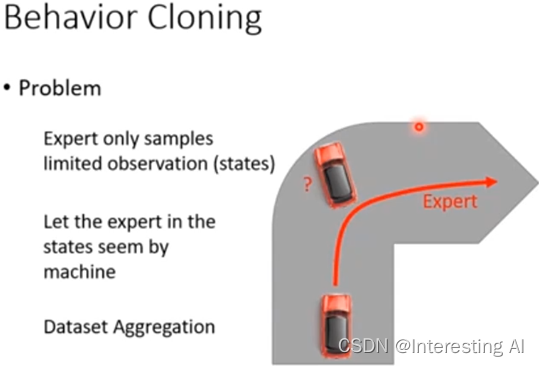
Behavior Cloning虽然非常简单,但是问题是今天如果只收集expert的数据,expert看过的observation会是非常limited。举例来说,假设你learn一辆自驾车过弯道,不管是找多少expert来,他就是把车顺着红色的线就开过去了。但是假设agent很笨,它今天开着不知道怎么回事就快要撞墙了,它会永远不知道撞墙这种情况怎么处理,因为training data里面从来没有撞过墙,所以他根本就不知道撞墙这种case要怎么处理。
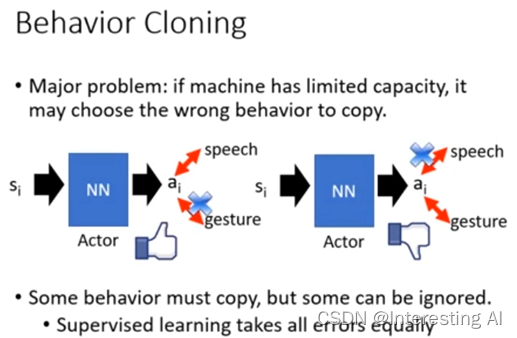
(2)机器唯一做的事情是复制expert所有的行为,他并不知道哪些行为是重要的,是对接下来情况会产生影响,哪些行为不重要,对接下来的事情没有影响。但是,Network的Capacity是有限的,我们知道说今天就算给network training data,它在training data上正确率往往不是100%,有些事情他是学不起来的,这个时候什么该学,什么不该学就变得很重要。举例而言,在学习一个英文的时候,你看到老师既有语音,也有手势动作,但是今天其实只有语音部分是重要的,手势动作部分是不重要的。也许machine他只能够学一件事,也许他就只学到了语音,那没有问题,如果他今天只学到了动作手势,这样子就有问题了。
(3)在做behavior cloning的时候,training data跟testing data的data distribution其实是不一样的。这里我们又再来强调一下这个事情,因为在监督学习的setting上面,我们总是假设我们的数据分布是不会变的,我们在用behavior cloning的时候,实际上就是在用监督学习的技术来解决决策学习的问题,所以我们会继承监督学习的假设,也就是说我们要求这个数据是不会变的,但是在强化学习里面,数据分布是会变的,怎么个变法,实际上就会和我们得到的策略会有关系。在training和testing的时候,在Reinforcement Learning里面,有一个很重要的特征就是,你采取的action会,会影响到接下来所看到的state。例如,我们先由state s1,看到action a1,action a1其实会决定了接下来看到什么样的state s2。
如果我们做behavior cloning的话,我们只能够观察到expert的一堆状态-动作对。我们希望可以learn一个policyπ*,跟π hat越接近越好,如果π*确实可以跟π hat一模一样,这个时候,你training的时候看到的state,跟test的时候看到state会是一样的,因为,虽然action会影响我们看到state,假设两个policy一模一样,在同样的state都会采取同样的action,接下来看到的state都会是一样的。
但问题是expert是一个人,机器 learn出来的policy跟expert的policy一模一样会很难。今天如果π*跟π hat有一点误差,这个误差也许在一般Supervise Learning里面,每一个example都是独立的,也许还好,但是假设是在reinforcement Learning里面,我们要走很多步,我们走每一步可能会发生一些误差,而且我们是在每一步走了之后,在他的基础上继续往前走,换句话说这个误差会不断的进行累积,所以这就是在强化学习这样的环境里面,它会有一个误差累积的问题。如果我们综合起来看,也就是说它的误差每一步在累积,而且随着它的误差的累积,它会越来越脱离原来训练的时候的数据,这个时候它的误差会越来越大,误差越大,它偏离原来的数据的速度会越来越快,所以就会导致对于behavior cloning这种技术虽然用起来很方便,但是它的效果就会很有限。你可能在某个地方就是失之毫厘,差之千里。例如可能在某个地方,你的machine,没有办法完全复制expert的行为,它只复制了一点点,差了一点点,也许最后得到的结果就会差很多。因此,算法对长时间且多变化的游戏是比较难训练成功的。也就是说,如果在环境或要解决的问题中,agent一步(step)的差异导致结果不会相差很多,并且给予的动作可以囊括大多数的动作,这样的环境或是问题是可以适合被behavior cloning解决的。但是,如果环境或问题是一失足成千古恨的情况,或是整个游戏需要长远的计划与目标,那么,behavior cloning方法就不适合了,因为它会造成训练与测试集合的误差。

所以今天 behavior cloning的方法并不能够完全解决imitation learning这件事情。

1.2.4 算法改进data aggregation
Behavior Cloning面临的问题是怎么让agent,采集到的训练数据跟它遇到的实际数据的分布尽可能的一致。这里我们可以采取的一个办法,就是一直保证采取更多的数据。如果他进入某一个状态之前没有遇到的状态,我们就把这个状态收集过来,让人在这个状态里面给一个标签,我们就可以收集到这种状态,放入我们的数据库,再重新训练我们的policy网络,就可以在我们deploy policy的时候不停的采集更多的数据,使得我们之前的数据库变得越来越完善。agent训练出来的效果也会越来越好。

所以,今天只做behavior cloning是不够的,只观察expert的行为是不够的,这里需要一个招数,这个招数叫做数据聚合,data aggregation,我们希望收集更多样性的data,而不是只收集expert所看到的observation,我们希望能够搜集expert在各种极端情况下,会采取什么样的行为。以自驾车为例,假设一开始你的actor叫做policy π,接下来你让policy π1真的去开这个车,但是车上坐了一个expert,这个expert会不断的做记录,说如果今天在这个情况下我会怎么样开。所以今天policy π1 自己开自己的,但是expert会不断的表示自己的想法,比如说在这个时候,expert可能说好就往前走,那个时候expert可能就会说往右转,但是policy π1是不管expert的指令的,policy π1会自己做自己的事情,因为我们要记录的是,expert在policy π1 看到的这种observation下,expert应该做什么样的反应,然后再把收集到的data拿去做新的policy π2,这个process就会反复继续下去,这种方法就叫做data aggregation。
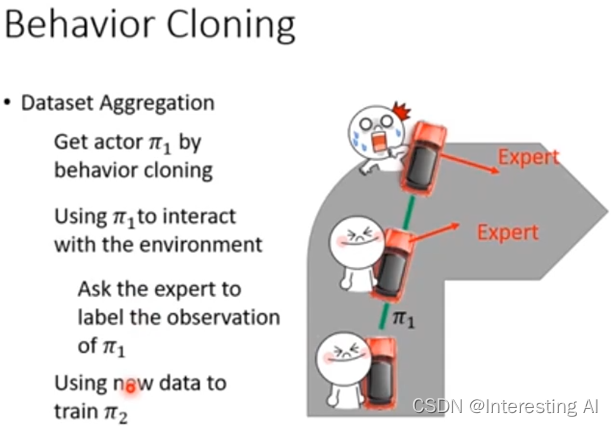
这也就是DAgger算法的一个核心,DAgger缩写是Dataset Aggregation,他希望解决一个问题,希望使得我们的训练数据p data它的分布跟policy我们训练出来的它采集到的数据尽可能的一致,他这里采取的一个办法,就是说,先利用一个初步的human data训练一个agent,让agent在这个环境里面进一步去采集,相当于跟环境进行交互,采集到另外一个数据库,这个数据库上面我们可能有些时候并没有标签,那么第三步的时候,就可以让人来把我们新采集到的数据进行标签,每一步给他一个正常的标签,把它组合到原来的训练库里面去,然后再重新训练我们的policy,就这样一个迭代的过程,我们就可以采集到越来越多更完善的实际数据,这样就可以使得agent他在运作的过程中遇到的数据都是在我们训练数据中出现过的,这里你可以发现,第三步其实是一个比较耗时的过程,这也是个DAgger的limitation,他总需要去carry experts,比如说expert,我们这里是人,人需要给出新采集到的数据的正确标签。
behavior cloning是1减伽马的平方分之1,现在变成了1减伽马分之一,也就是对于我们在每一次做behavior cloning的误差来说,它的敏感性会下降,机器和专家策略之间的距离会拉的更近一些。

我们这里可以改进的一个办法是我们可以在第三步的时候,与其用人,我们可以用其他的一些算法,因为很多时候其他的一些算法他自己有一些劣势,比如说可能速度比较慢,它并不是很快的一个算法,但是因为我们这里是一个离线的过程,可以允许比较慢的一些算法,或者我们可以用一个优化的办法去search它最佳的结果,所以我们可以把第三步改成用一些其他比较慢的,但是效率准确度很高的一些算法来对它进行一个标签,这样就可以产生一个数据集团来训练我们的policy network。


1.3 Inverse Reinforcement Learning
1.3.1 算法思路
算法思路是,从数据里面还原出专家当时学出策略的reward函数,根据某一个reward函数来学到一个最优的策略。即,在强化学习中,我们给定环境(状态转移)和奖励函数,我们需要通过收集的数据来对自身的策略函数和值函数进行优化。在逆强化学习中,提供环境(状态转移),也提供策略函数或是示教数据,我们希望从这些数据中反推奖励函数。即给定状态和动作,建立模型输出对应奖励。在奖励函数建立好后,我们就能新训练一个智能体来模仿给定策略(示教数据)的行为。

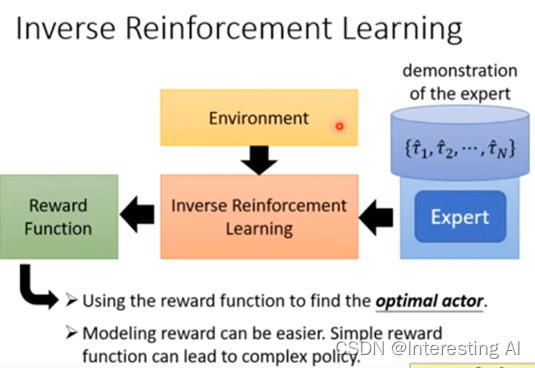
所以接下来就有另外一个比较好的做法叫做Inverse Reinforcement Learning,为什么叫Inverse Reinforcement Learning?因为在原来的reinforcement Learning里面,你有一个跟你互动的环境,你有一个reward function,根据环境和reward function,通过IRL这个技术,你会找到一个optimal 的actor。Inverse Reinforcement Learning刚好是相反的,今天没有reward function,只有一堆expert demonstration,但还是有环境,Inverse Reinforcement Learning的做法是,假设现在有一堆expert demonstration,这里我们用τ hat代表expert demonstration,如果今天是在玩电玩的话,每一个τ就是会玩电玩的人他玩一场游戏的记录,如果是自驾车的话,就是这个人开车的记录,这些就是expert demonstration。将expert demonstration收集起来,使用Inverse Reinforcement Learning技术的时候,机器是可以跟环境互动的,但是它得不到reward,它的reward必须要从expert那边推论出来,现在有了环境,有了expert demonstration以后,反推出reward function长什么样,之前是由reinforcement learning是由reward function反推出什么样的action,actor是最好的。Inverse Reinforcement Learning是反过来,我们有expert demonstration,我们相信他是不错的,然后去反推expert既然做这样的行为,那实际的reward function到底长什么样子。我就反推说,expert是因为什么样的reward function,才会采取这些行为。你今天有了reward function以后,接下来你就可以套用一般的reinforcement Learning的方法去找出optimal 的actor。有时候很简单的reward function,也许可以推导出非常复杂的行为。
1.3.2 算法步骤
Inverse Reinforcement Learning实际上是怎么做的?
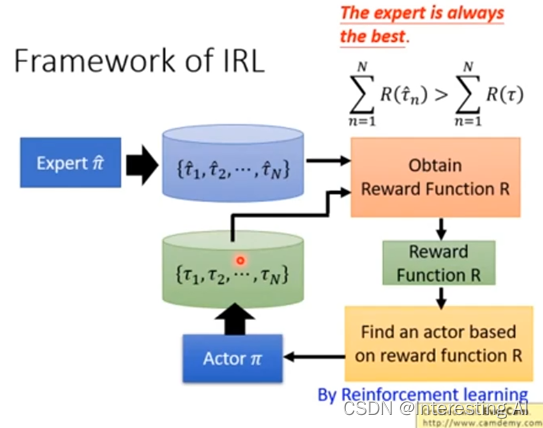
首先我们有一个expert,我们叫做π hat,这个expert去跟环境互动,给我们很多τ1 hat到τN hat,如果是玩游戏的话,就是有一个电玩高手去玩N场游戏,把N场游戏的state,跟action 的sequence统统都记录下来。接下来你有一个Actor,一开始Actor很烂,他叫做π,Actor也去跟环境互动,他也是玩了n场游戏,他也有n场游戏的记录。接下来我们要反推出reward function,怎么推出reward function,这边的原则就是expert永远是最棒的,今天是先射箭再画靶的概念,expert跟他去玩一玩游戏,得到这些游戏的记录,你的Actor也去玩一玩,得到这些游戏的记录。接下来你要定一个reward function,这个reward function的原则就是expert得到的分数要比Actor得到的分数高,要先射箭再画靶。所以我们今天就learn出一个reward function,会使得expert所得到reward大过于Actor所得到的reward。你有了新的reward function以后,你就可以去learn一个actor,你用reward function就可以套用一般的reinforcement learning的方法去learn一个actor,这个actor会对这一个reward function,去maximize它的reward。他也会采取一大堆的action。
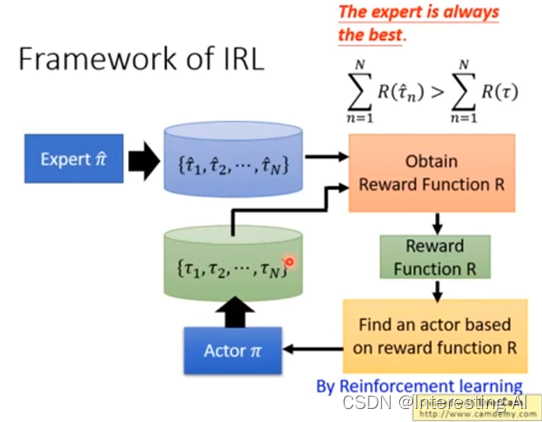
但是,今天这个Actor可以maximize这个reward function ,采取一大堆的行为,得到一大堆游戏的记录,但接下来,我们就改reward function了,就是先射箭再画靶的概念, Actor已经可以在这个reward function得到高分,但他得到高分以后,我们就改reward function了,仍然要让expert比我们的actor可以得到更高的分数,这个就是Inverse Reinforcement Learning,你有新的reward function以后,根据新的reward function,你就可以得到新的Actor,新的Actor,再去跟环境做一下互动,但他跟环境做互动以后, 你会重新定义了reward function,要让expert得到reward function,大过于它。
这里,我们的reward function也许就是一个neural network,这个neural network就是θ和τ,然后input,output就是θ和τ就是要给他们多少的分数,或者是说你假设觉得input 整个τ太难了,因为τ是s跟a很长的sequence,也许就说他就是input s 跟a,它是一个s跟a的pair,然后output一个number,然后把整个sequence加起来,就得到一个total R,在Training的时候,就说今天这组数字,希望它output R越大越好,今天这个希望output R越小越好。
1.3.3 算法特性
你只要把它换个名字说actor就是generator,reward function就是discriminator,其实,他就是GAN,所以他会不会收殓就等于问这个GAN会不会收敛。我们把它跟GAN比较一下,在GAN里面你有一堆很好的图,第二个generator一开始他可能不知道产生什么样子,所以他就乱画,expert画的图就是高分,generator画的图就是低分,你有了discriminator以后,generator会想办法骗过discriminator,generator会希望它产生的图,discriminator也会给它高分。整个process跟IRL是一模一样的,我们只是把所有的东西换个名词而已,今天这些人画的图在这边,就是expert demonstration,你的generator就是Actor。
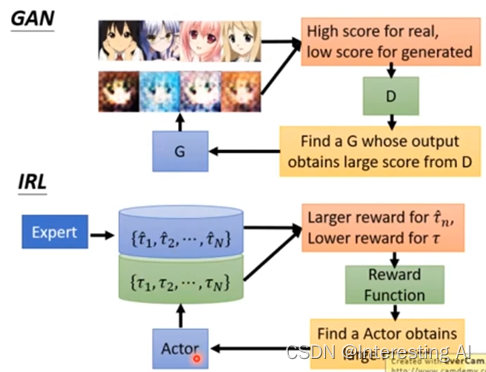
今天generator会画很多图,Actor会跟环境互动,产生很多trajectory,这些trajectory跟环境互动记录游戏的记录,其实就是等于这些GAN里面的游戏画面,就等于是GAN里面的这些图,你learn一个reward function,这个reward function其实就是discriminator,这个reward function,要给expert demonstration高分,给actor互动的结果低分,接下来,actor会想办法从这个已经learn出来的reward function获得高分,跟GAN一模一样的,我们只是换个说法来讲同样的事情而已。
sentence generation也可以想成是Imitation learning。你在写句子的时候,你写下的每一个word想成是一个action,所有的word合起来就是一个episode。在sentence generation里面,你会给机器看很多人类写的文字,但人类写的文字仍然说你要让机器学会写诗,你就要给他看唐诗三百首,人类写的文字其实就是expert的demonstration,每一个词汇其实就是一个action。

让机器做sentence generation的时候,其实就是在imitate expert trajectory,Chat-bot也是一样,在Chat-bot里面你会收集到很多人互动对话记录那些expert demonstration。如果我们今天单纯的用maximum likelihood 这个技术来maximize,我们会得到likelihood,这个其实就是behavior cloning。我们今天说behavior cloning就是看到一个state,接下来预测我们会得到怎么样的action,在做likelihood的时候也是一样,given sentence已经产生的部分,接下来我们要写哪一个word才是最好的。所以其实maximum likelihood在做这种sentence generation的时候,maximum likelihood其实对应到Imitation Learning里面,就是Behavior Cloning。我们说maximum likelihood那些都是不够的, sequence gan,就是对应到IRL,我们刚才有讲过,其实IRL就是一种GAN的技术,你今天把IRL的技术放到sentence generation,chat-bot里面,其实就是sequence gan跟它的种种的变形。
1.3.4 IRL典型算法Generative Adversarial Imitation Learning(GAIL)
在IRL领域有名的算法是GAIL,这种算法模仿了生成对抗网络GANs。把Actor当成Generator,把Reward Funciton当成Discriminator。我们要训练一个策略网络去尽量拟合提供的示教数据,那么我们可以让需要训练的reward函数来进行评价,Reward函数通过输出评分来分辨哪个是示教数据的轨迹,哪个是自己生成的虚假轨迹;而策略网络负责生成虚假的轨迹,尽可能骗过Reward函数,让其难辨真假。两者是对抗关系,双方的Loss函数是对立的,两者在相互对抗中一起成长,最后训练出一个较好的reward函数和一个较好的策略网络。
(1)算法的由来
我们想做的事情,是希望策略跑出来的分布和专家演示的数据的分布,尽可能的一致。所以这个目标看起来我们可以设立一个这样的目标, p表示的是分布,这个p r表示的是专家的一个分布,pg表示的是策略跑出来的分布,我们给一个这样的归一化的方式,当等式相等以后,就意味着生成的分布和我们专家的分布一致。为了去度量它的不一致性,我们用以下分布差异度量的方法,比如说JS divergence来度量,如果我们把上面的分布把它放进去,这个就是两个方向的KL,我们把它写出来,我们可以去想办法去最小化divergence,会使得它们两个的分布要尽可能一致。

到这里为止,我们一直讲的都是分布,分布是一个连续的概念,但是我们的专家的数据以及我们的策略跑出来的数据,它本身还不是分布,它是一个分布下面的一个采样,所以我们要去算分布的时候,我们要去从数据上面去把分布来给它还原出来,我们才能够计算分布之间的相似性,怎么去做到这件事情,我们可以从数据上来做一个分布的学习。
我们希望从数据上去近似一个分布,现在一种做法是去学一个现在我们有的两套数据,我们希望能够知道在任何一个点,这个点它是属于这两个数据所来源的分布的概率是多少。在这种情况下面,一种实现方法,我们去学一个分类器,我们把专家的数据和我们自己的策略跑出来的数据当成是两类数据,我们去学一个分类器,把这两类数据分开,我们有很多分类器的输出,它是一个有连续值的输出,所以我们可以把输出做成一种类似于后验概率的这么一种形式,我们把它当成是对于概率的一个近似。

这个事情实际上就是我们现在比较常见的GAN的框架,所以我们回过头来看这个GAN的框架,实际上他做的这个事情,是说我们这里有一群数据,这个是我们的专家数据或者叫做真实数据,另外这边会有一个数据的生成,对于GAN框架,它最初面临的数据的环境来说,这里就是一个随机的向量,产生了一个随机的隐分布上面的采样,随机的向量,输入了以后,通过我们的generator,或者decoder能够生成一个样本出来,我们的判别器去判断这两个说出来的生成的样本和我们的真实样本它之间的相似性怎么样。
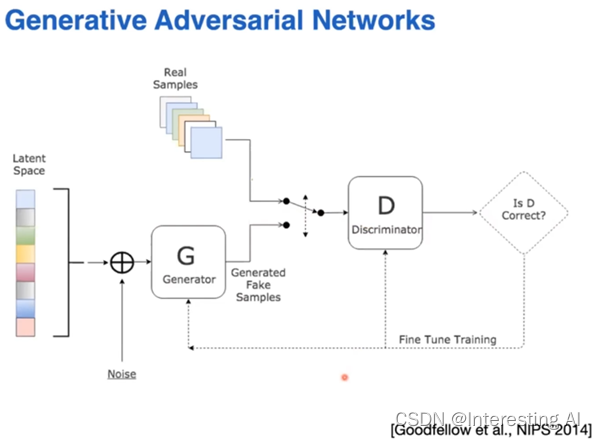
实际上在模仿学习这边也会有类似的一个做法,我们刚才说的GAN框架上面数据的生成。
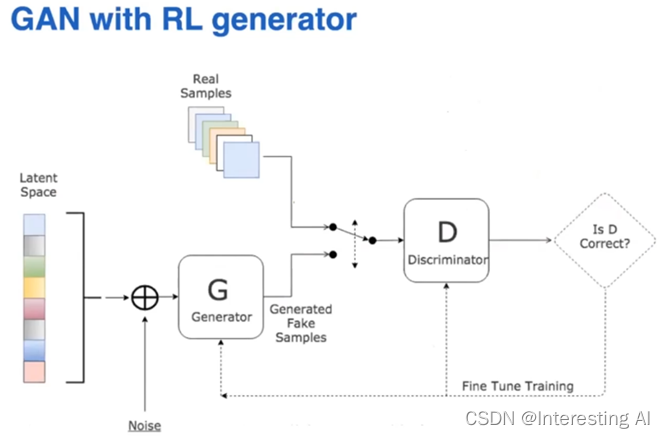
(2)算法思路
强化学习和我们要做的模仿这件事情是没有关系的,这里我们需要用强化学习在环境里面具体的去采样一些数据来生成数据,所以这个地方需要被替换成这样用强化学习。所以强化学习需要的reward从哪里来,这里我们是把Discriminator给出来的这个值来作为它的reward,来给强化学习。所以整个框架我们叫做Generative Adversarial Imitation Learning(GAIL),就GAIL这么一个框架。

在这个框架里面,它的整个学习的过程和GAN的框架的学习过程,比如说我们一步步来学习Discriminator,来把专家的样本和我们策略跑出来的样本,要尽可能把它分开。第二步就是以discriminator给出来的分值,我们把它当成是reward,把他交给强化学习去最大化reward。所以不断的进行学习以后,我们强化学习生成出来的数据,最后会比较接近于专家的数据,这个就是最基本的生成对抗的模仿学习的方法,那么刚才提到的一样,GAN之前的一些不足的地方,GAIL 框架也把它继承了过来,所以后面也会对于GAIL提出了各种各样的一个变形,一些改进。包括WGAIL,就是说我们这里用的是JS散度,为这边的度量来做一些改进,这个都是有一系列的改进的方法就诞生了
接着具体介绍一下对抗生成模仿学习,它主要是利用discriminator神经网络当作奖励函数给agent学习的方向。在学习神经网络过程中,我们需要最大化专家给予的标准动作奖励,并且最小化agent输出的动作的奖励值。
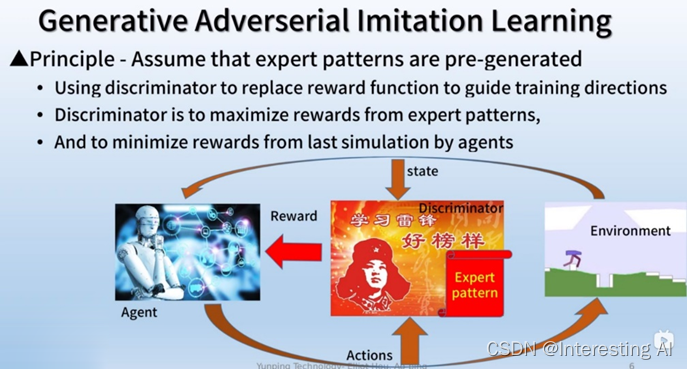
(2)算法步骤
1)在游戏的一开始,环境会给予agent目前的状态,agent会根据目前的状态生成一个动作给环境,而在同时discriminator也会截取目前的状态与动作,在截取之后,discriminator会送出一个奖励值给agent,作为后续的训练。在这边请注意专家给予的标准动作尚未使用,他只是用在训练discriminator当中。
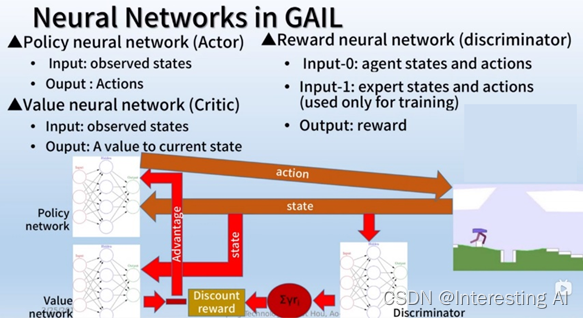
这边我们来看一下GAIL里面有哪些神经网络,首先是策略网络actor,它的输入输出分别为观测的状态与动作,然后是价值网络critic,它的输入输出分别为观测状态与价值,最后是奖励网络discriminator,它的输入很特别,它需要环境的状态与agent的动作,而在训练的时候还需要专家的状态与动作,而它的输出则是奖励值。
这些网络的工作顺序如下,首先环境会把状态喂给策略网络,策略网络会根据目前的状态做出相对应的动作反馈给环境,在经过数个步骤后就开始训练策略网络。
2)首先我们把刚才的状态放进discriminator中求取奖励,把它们累加计算discounted的reward,也就是估计每个状态的价值。接着我们把刚才的状态喂给价值网络,计算目前神经网络估计的状态价值,我们把这两个价值相减作为的advantage来导引策略网络的学习,完成策略网络的训练。
3)刚才我们讲解了如何利用discriminator训练策略网络,接着我们看看整个流程,在游戏开始之前,我们先把专家给予的标准动作与对应的状态,载入到资料库当中,然后完成一个剧本的游戏,并且记录经历的状态与动作。
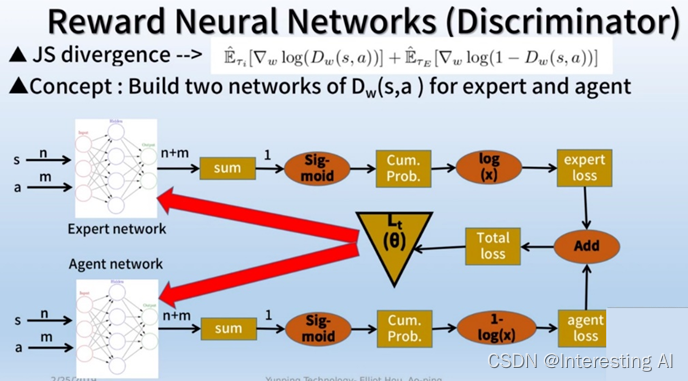
4)接着利用ppo或是trpo训练策略网络,在此当中,我们使用的是训练好的奖励网络,也就是discriminator来导引训练,最后利用Jensen-Shannon divergence来训练discriminator,其微分的loss函数如下,在这当中dw为cdf几率函数,左边是专家的loss,右边是agent的loss。

5)由于ppo算法之前讲过了,所以这边我们直接讲解如何训练discriminator,也就是完成Jensen-Shannon divergence的最小化。虽然discriminator是一个神经网络,一个是专家的ddf几率神经网络,另外一个是代理人的cdf几率神经网络。在一开始的时候,我们会把专家与agent的动作分别喂给这两个网络,然后求和,利用sigmoid的函数求出一个介于0跟1的值,这个值也会被我们定义成为cdf的几率。接下来我们取log当做专家与agent的loss,把两个相加计算total loss,对total loss进行微分,最极值求解。最后更新神经网络。
2 算法总结
这里我列了一些模仿学习跟强化学习的它的优势以及劣势,比如说模仿学习它的劣势,它是需要我们提供demonstration,它也存在distributional shift,data分布不一致的问题,这里很大一个好处是模仿学习,类比于监督学习,训练是非常稳定的,另外一方面对于我们强化学习,里面我们是需要提供reward function,而且我们需要去处理exploration的问题怎么balance?Exploration和 exploitation。

当然强化学里面它有一点是它可以取得superhuman这种performance。这里一个很直接的想法是我们怎么把模仿学习跟强化学习两者结合起来,我们在训练过程中,既有人的示教demonstration,也有reward function,两者把它结合起来,就可以得到一个更好的训练框架。

模仿学习本身因为是监督学习是非常稳定的,因为它存在distributional shift的问题,我们pure reinforcement Learning里面也存在很多的问题,怎么把两者结合起来就可以,一种办法是pretrain & Finetune的办法,一种是off policy learning的一个办法结合起来,另一种是可以把它跟损失函数还不是objective。把imitation learning当成一个acceptable loss,这样也可以把强化学习跟模仿学习两者结合起来。

3 算法应用
这里是一个behavior coloning代码,在一个赛车游戏的环境下面,把赛车游戏车辆的观测以及人在手柄上面的操控也记录下来,用这样的一个示教的demonstration,作为一个训练数据,训练一个在虚拟环境里面可以开车的一个agent。
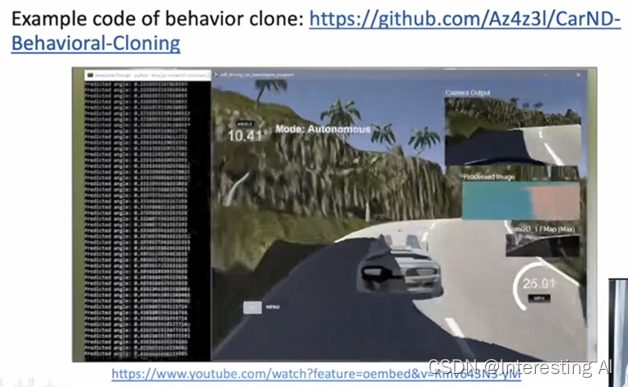
总的来说,这样的一个思路是一个比较简单比较直接的一个方法,这样我们就可以用监督学习的方式来从专家的数据上面来进行模仿,这样的一个模仿的应用,我们前面其实在AlphaGo的最初的版本以及最近像AlphaStar这样的系统上面,其实我们都看到了,在AlphaGo的最初的版本,我们去收集了应该是上千万盘。我们看到的阿尔法狗的最初的版本的时候,收集了大量的职业5段以上的玩家,他的选手他去下围棋的数据,在AlphaStar也开始收集了很多的职业选手的replay,能够去用这样的一个人去玩游戏的数据来做模仿学习,所以这一类方法叫behavior cloning。

商品推荐

动作模仿

文章出处登录后可见!