该分类器最早由Leo Breiman和Adele Cutler提出。
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。
我们都知道,在Python中,可以通过调用sklearn快速构造一个模型,但是我们如何在MATLAB中构建一个随机森林呢?本文将通过MATLAB的随机森林分类实例进行探讨。
step1:数据归一化处理
集成学习算法对数值大小不敏感,树模型主要关心变量之间的分布和变量之间的概率分布,因此我们会发现,很多时候数据归一化与未归一化的的结果差别不大。但是,很多时候我们都把他进行归一化处理,因为这样可以降低计算机计算的难度,减少并行运算时间。我们可以使用mapminmax函数进行归一化处理。
step2:构建流程
采取有放回的抽样方式构造子数据集,保证不同子集之间的数量级一样(元素可以重复);利用子数据集来构建子决策树;将待预测数据放到每个子决策树中,每个子决策树输出一个结果;统计子决策树的投票结果,投票数多的就是随机森林的输出结果。
(1)从样本集中用 Bootstrap采样选出一定数量的样本,可以通过简单交叉验证进行划分训练集和测试机;
(2)从所有属性中随机选择K个属性,在K个属性中再选择出最佳分割属性作为节点创建决策树;
(3)重复以上两步m次,即建立m棵决策树。可以并行:即m个样本同时提取,m棵决策树同时生成;
(4)这m个决策树形成随机森林,通过投票表决结果(比如少数服从多数)决定待预测数据的结果。
代码:
首先设置trees,leaf,Method参数
net = TreeBagger(trees, p_train, t_train, 'OOBPredictorImportance', OOBPredictorImportance, ...
'Method', Method, 'OOBPrediction', OOBPrediction, 'minleaf', leaf);
step3:计算重要性
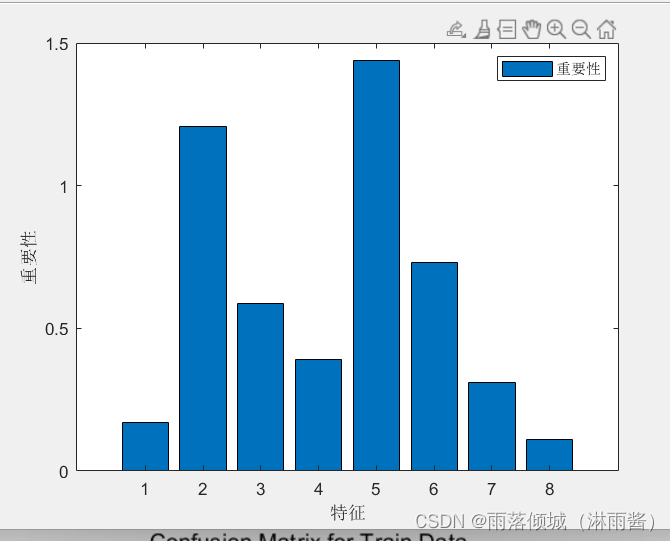
1:对于随机森林中的每一颗决策树,使用相应的OOB(袋外数据)数据来计算它的袋外数据误差,记为errOOB1.
2: 随机地对袋外数据OOB所有样本的特征X加入噪声干扰(就可以随机的改变样本在特征X处的值),再次计算它的袋外数据误差,记为errOOB2.
3:假设随机森林中有Ntree棵树,那么对于特征X的重要性=∑(errOOB2-errOOB1)/Ntree,之所以可以用这个表达式来作为相应特征的重要性的度量值是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度降低,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高。
代码:
importance = net.OOBPermutedPredictorDeltaError; % 重要性step4:混淆矩阵计算
在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。
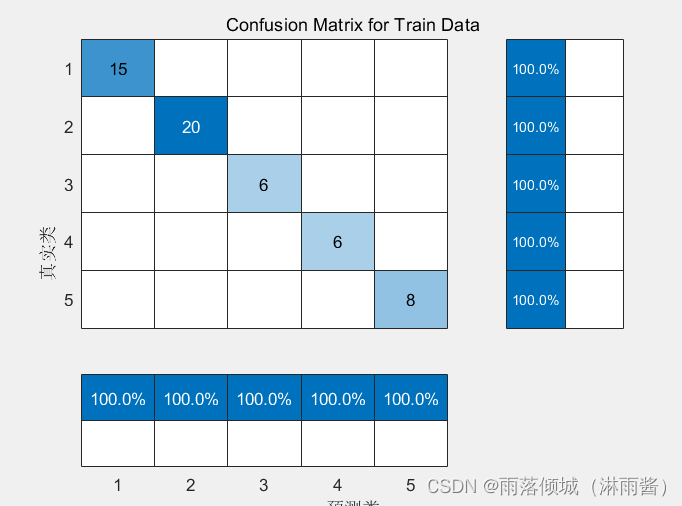
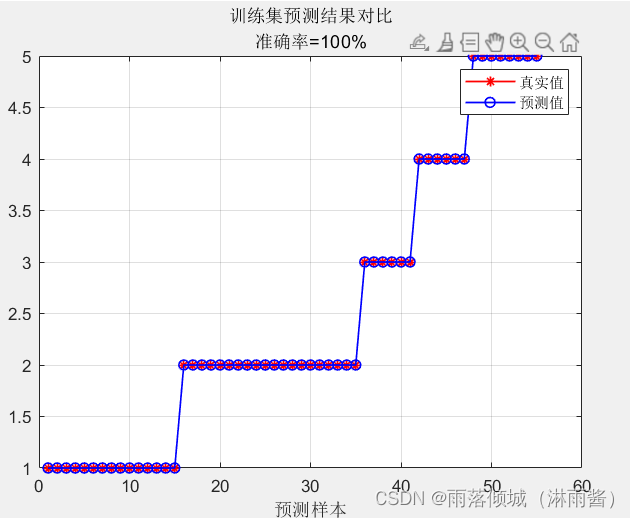
矩阵对角线上的数值为预测正确的格式,比如以下训练集的混淆矩阵,类别1的预测正确个数为15个,正确率为100%。
训练集的混淆矩阵
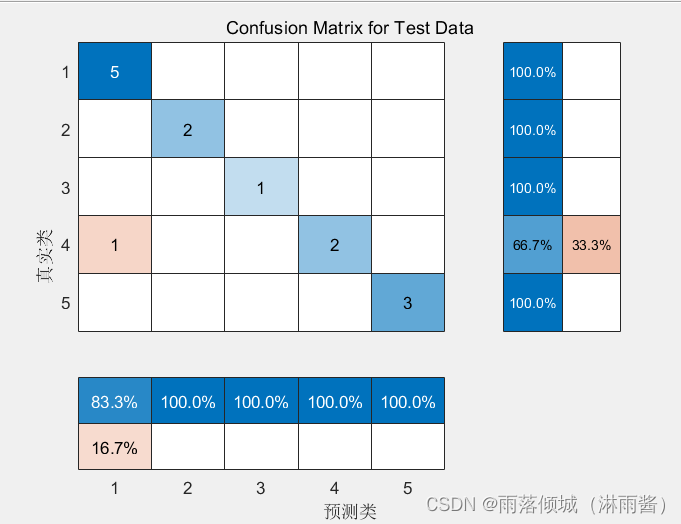
测试集的混淆矩阵
可以通过confusionchart来输出混淆矩阵。
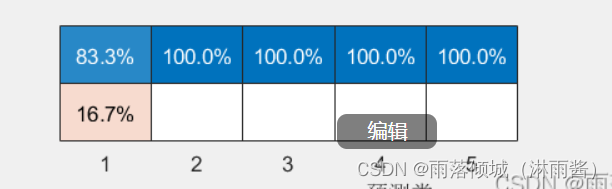
该图第一列为判断为某一类别的正确率。如第一类数据预测为正确的召回率为83.3%。
step5:准确率:
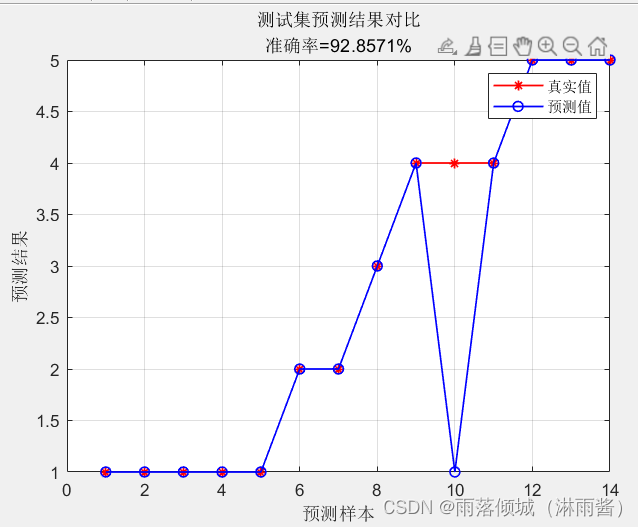
将同类别的数据放在同一段显示,可以直观看到预测结果与实际值的偏离度
step6:评价指标:召回率、精确率,ACC等等。
文章出处登录后可见!