目录
一、题目以及大概的思路


先对数据进行无量纲化处理,根据所给不确定度与数据,计算出相对不确定度,并将其异常点剔除,通常情况下相对不确定度不超过百分之5,对于剩下有效数据,按照不同地区每10年进行取值,这里可以采用平均值、标准值代替,或者进一步考虑四季平均气温不同进一步处理。结合同比增长率,判断每隔十年以来气温的升幅变化趋势,判断2022年3月导致的升幅是否大于以往十年。
(这个地方似乎有不同的理解,是仅2022年3月的升幅与2012-2022年比,还是比以往的任何十年。题目中的一个any让解题方法出现偏差)
接着是温度预测模型,可以采用时间序列分析、回归预测、灰色系统预测、深度学习等等
方法可以参考我之前的文章:数学建模–预测类模型_派大星先生c的博客-CSDN博客_模型预测
对比模型的的准确性得出第一题的结论。
第二题建立⼀个数学模型来分析全球温度、时间和位置之间的关系,首先可以采用的是因子分析。通过找寻数据 ,利用主成分分析法,考虑到温室气体的排放是导致全球气候变暖的主要原因,统计这些数据随时间的变化规律,根据主成分分析的一般步骤,进行降维处理,根据贡献率选取合适的主成分建立多元线性回归模型,并通过已有数据对拟合优度进行评估。
二、数据预处理
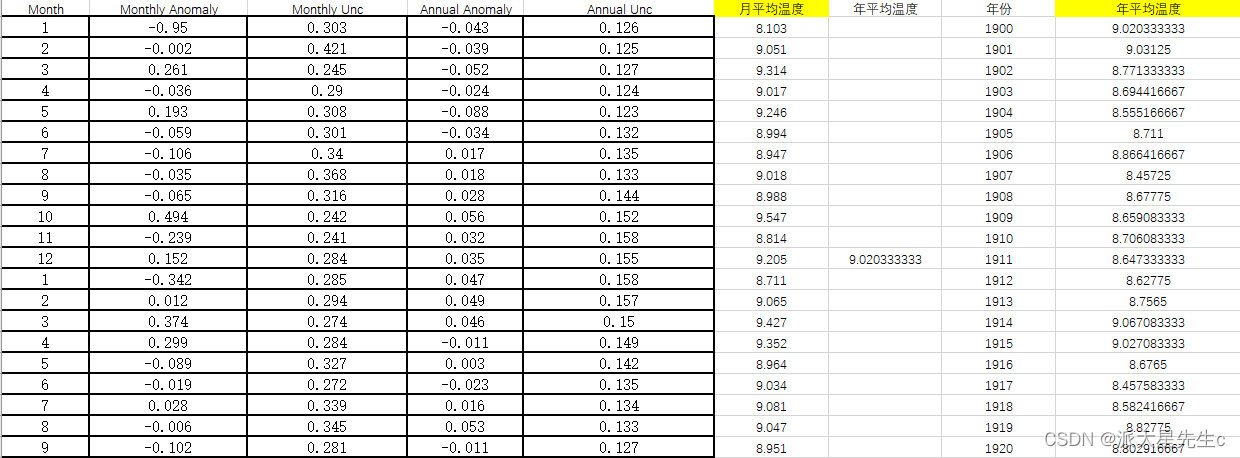 利用excel将所给的数据集处理成有月平均气温和年平均气温的表格便于后续计算
利用excel将所给的数据集处理成有月平均气温和年平均气温的表格便于后续计算
通过 excel的筛选器功能可以得到每10年的三月份气温
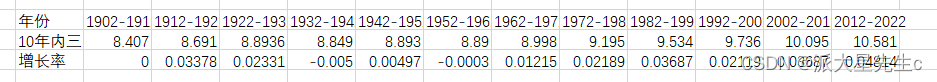
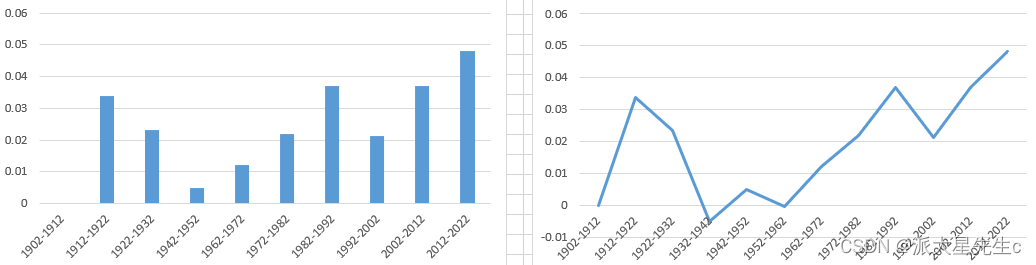
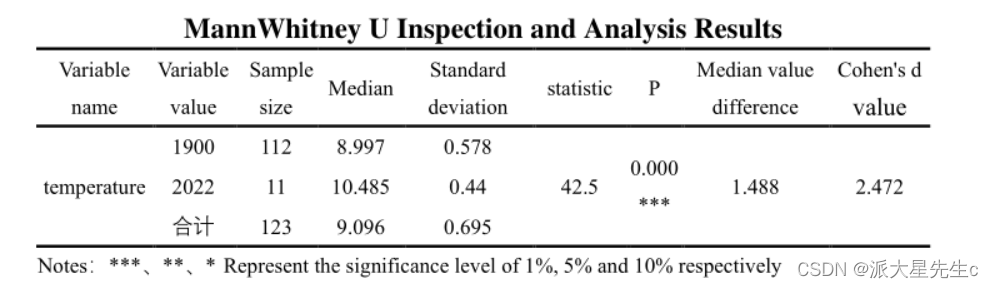
分析得到图表,同时通过spsspro做独立样本T检验得出具有显著差异 从而得出题目结果。
三、预测模型
预测模型我们选用了时间序列模型和LSTM神经网络进行预测
将年份和年平均气温选出
通过SPSSPRO进行时间序列分析
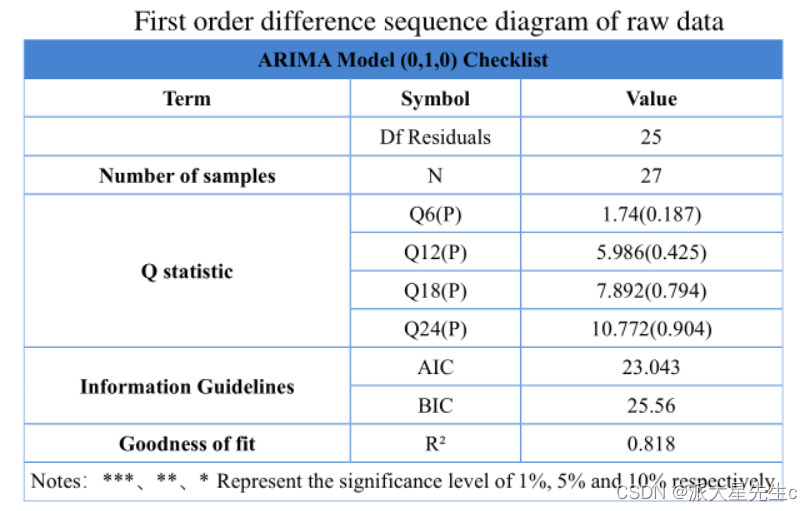
R方大概在0.8左右,拟合度较高基本满足题目需求,然后向后预测2050、2100年的年平均气温。
接着用lstm代码实现预测
import numpy
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.models import Sequential, load_model
# 将整型变为float
dataset = dataset.astype('float32')
def mean_absolute_percentage_error(y_true, y_pred):
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
test_size = -8
trainlist = dataset[:test_size]
testlist = dataset[test_size:]
def create_dataset(dataset, look_back):
#这里的look_back与timestep相同
dataX, dataY = [], []
for i in range(len(dataset)-look_back):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return numpy.array(dataX),numpy.array(dataY)
#训练数据太少 look_back并不能过大
look_back = 1
trainX,trainY = create_dataset(trainlist,look_back)
testX,testY = create_dataset(testlist,look_back)
trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1] ,1 ))
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(4, input_shape=(None,1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
# model.save(os.path.join("DATA","Test" + ".h5"))
# make predictions
#%%
#模型验证
#model = load_model(os.path.join("DATA","Test" + ".h5"))
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#反归一化
trainPredict_ = scaler.inverse_transform(trainPredict)
trainY_ = scaler.inverse_transform(trainY)
testPredict_ = scaler.inverse_transform(testPredict)
testY_ = scaler.inverse_transform(testY)
#%%
from sklearn.metrics import mean_squared_error,mean_absolute_error
def score(y_true, y_pre):
# MAPE
print("MAPE :")
print(mean_absolute_percentage_error(y_true, y_pre))
# RMSE
print("RMSE :")
print(np.sqrt(mean_squared_error(y_true, y_pre)))
# MAE
print("MAE :")
print(mean_absolute_error(y_true, y_pre))
# # R2
# print("R2 :")
# print(np.abs(r2_score(y_true,y_pre)))
#%%
score(trainPredict_,trainY_)
#%%
score(testPredict_,testY_)
#%%
df['Year'].values.astype('float32')[:test_size].shape
#%%
plt.plot(df['Year'].values.astype('float32')[:test_size-1],trainY_, label='observed data')
plt.plot(df['Year'].values.astype('float32')[:test_size-1],trainPredict_, label='LSTM')
plt.xlabel( '年份')
plt.ylabel( '平均温度')
plt.title( '训练集平均温度情况')
plt.savefig('./Q1/训练集平均温度情况.jpg')
plt.show()
#%%
plt.plot(df['Year'].values.astype('float32')[test_size+1:],testY_, label='observed data')
plt.plot(df['Year'].values.astype('float32')[test_size+1:],testPredict_, label='LSTM')
plt.xlabel( '年份')
plt.ylabel( '平均温度')
plt.title( '测试集平均温度情况')
plt.savefig('./Q1/测试集平均温度情况.jpg')
plt.show()
得到拟合图像
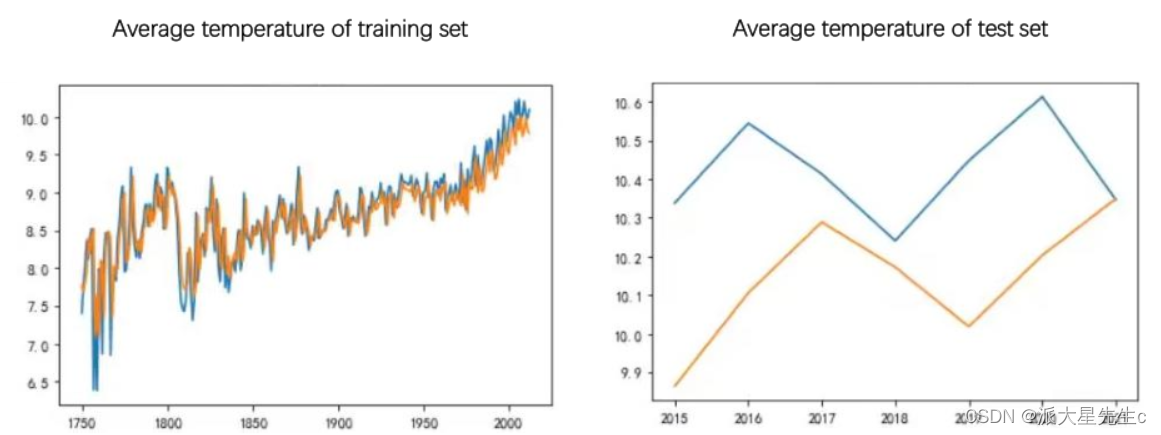
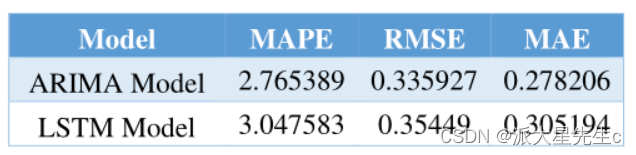
比较模型的mape、rmse、mae得出ARIMA模型(时间序列模型)更好一点。
(可能是我们在这个地方的数据处理有问题,导致数据量很少,在用深度学习的方法时甚至不及线性回归等常规预测方法)
四、全球变暖的相关性分析
我们根据大多数网上的思路,将数据按照国家、大洲、南北半球等方式进行区分
分别进行了Kendall一致性检验
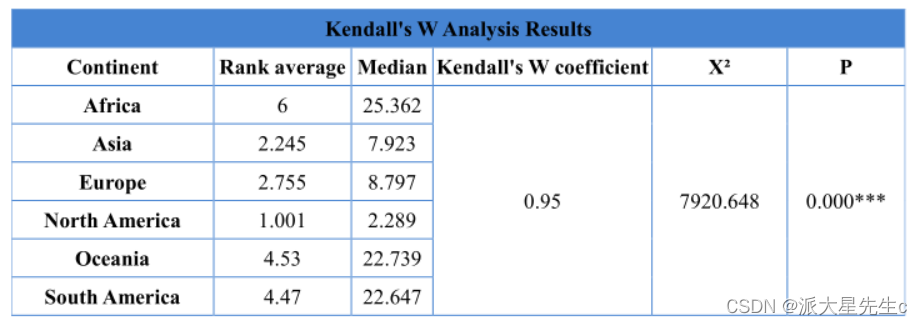
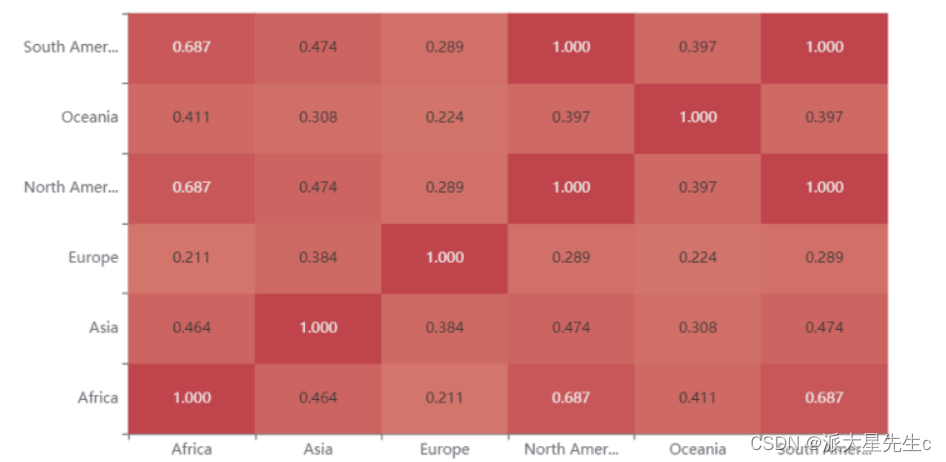
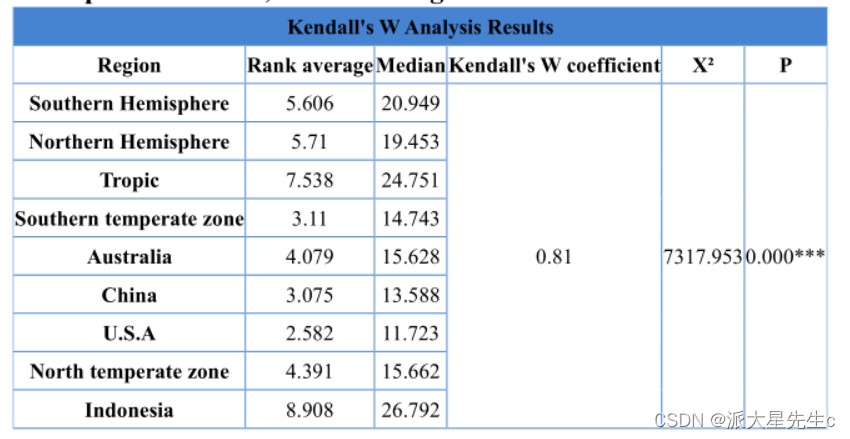
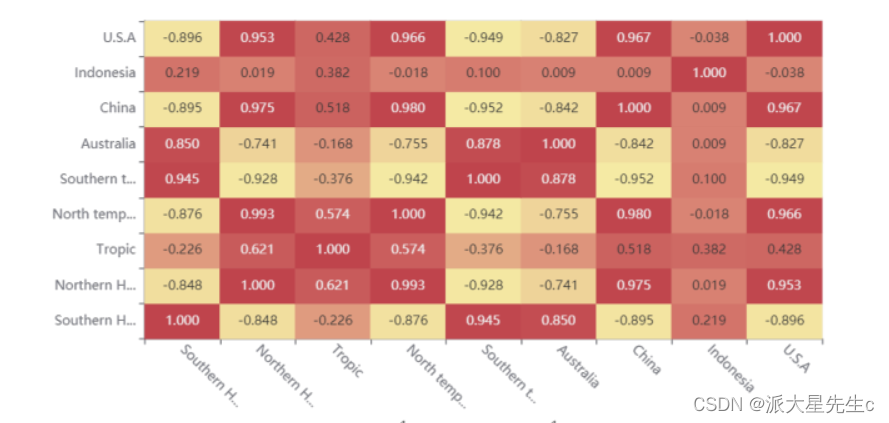 不管是哪一种区分 都充分证明了,全球变暖与地区时间的相关性。
不管是哪一种区分 都充分证明了,全球变暖与地区时间的相关性。
后面使用的纤维束模型分析了自然灾害中哪一个因素影响全球变暖最多。(这里如果数据合适也可以使用主成分分析,最为一个简单的评价类模型考虑)
五、赛后总结
对于此次APCMC亚太赛C题来讲,整体的难度不是很大,拿到题目不到一个上午就出现了很多思路,并且在解题过程中也没有太大的难点。如果数据处理的相对较好的情况下,题目答案很容易就解答出来,但是在运用excel和lstm模型的时候出现了一些问题,虽然不影响最后完赛,还是给我们一个警醒,更多的还是要参考一些比较成熟的论文,打磨词句,才能获得一个不错的成绩。
后续主要加强数据处理和论文撰写排版的能力。
文章出处登录后可见!