🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 – 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋

文章目录
关系抽取 Relation Extraction
关系提取是一项自然语言处理 (NLP) 任务,旨在提取实体(例如,比尔盖茨和微软)之间的关系(例如,创始人)。例如,从句子 比尔盖茨创建了微软 中,我们可以提取关系三元组 (比尔盖茨, 创始人, 微软)。
关系提取是自动知识图谱构建中的一项关键技术。通过关系抽取,我们可以累积抽取新的关系实体,扩展知识图谱,作为机器理解人类世界的一种方式,在问答、推荐系统和搜索引擎等下游应用很多。
信息抽取
大部分的信息抽取任务,实际上就是从语句中抽取“三元组”的任务,具体描述如下:
三元组指的是:主实体(subject)、实体间关系(predicate)、目标实体(object)
三者之间的关系概况为:“subject的predicate是object”。所以抽取三元组,也称为spo抽取。
信息抽取任务就是:输入一个句子,目标就是抽取出句子中包含的所有三元组。
论文名称:《A Novel Cascade Binary Tagging Framework for Relational Triple Extraction》论文链接: https://aclanthology.org/2020.acl-main.136.pdf
代码地址: https://github.com/weizhepei/CasRel
CasRel 框架提出的核心观点是:我们不将关系看做实体对儿上的离散标签,而是将关系建模为主实体映射到对象实体的函数。更确切地说,我们不是学习关系分类器 f(s,o) → r,而是学习关系特定的标记器 f_{r}(s)→ o,每个标记器都识别给定主实体下的目标实体所有可能的关系。在这个框架下,关系三元组抽取是分两步完成的:首先我们识别一个句子中所有可能的主实体;然后对于每个主实体,我们应用特定于关系的标记器来同时识别所有可能的关系和相应的目标实体。
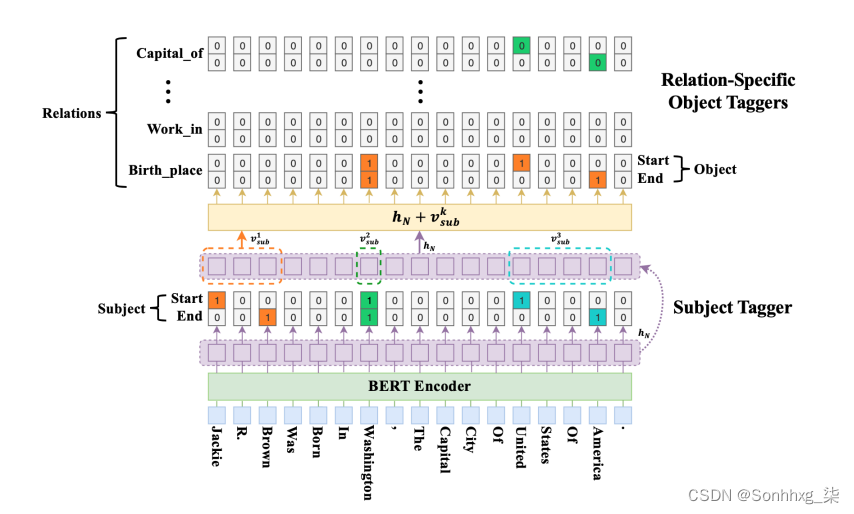
关系三元组抽取(Relational Triple Extraction, RTE),也叫实体-关系联合抽取,是信息抽取领域中的一个经典任务,旨在从文本中抽取出结构化的关系三元组(Subject, Relation, Object)用以构建知识图谱。有时也与关系分类(Relation Classification, RC)任务统称为关系抽取(Relation Extraction, RE)。
RC与RTE的主要区别在于:RC是在给定实体对和输入文本的情况下,抽取出实体对在句子中所表达的关系;而RTE则是在仅给定输入文本的情况下,抽取出包含在文本中的所有可能的关系三元组。
信息抽取是构建大规模知识图谱的必备关键,先来说一下图谱的三元组形式,在以往常常将三元组以 (head,relation, tail) 的形式表示,在这里以(subject, relation, object)的形式表示,即(S, R,O),为了方便描述,后文将以这种形式阐述。
信息抽取分为两大部分,一部分是命名实体识别,识别出文本中的实体,另外就是关系抽取,对识别出来的实体构建对应的关系,两者便是构建三元组的基本组成。
在以往的研究工作中,早期两个任务以pipline的方式进行,先做命名实体识别,然后做关系抽取。但是pipline的流程可能造成实体的识别错误,也就造成关系构建的错误,所以后续的一些研究工作将两者采用联合学习的方式。
关系抽取实现
一对多的抽取分类任务,样本主要特点如下:
- s和o未必是分词工具分出来的词,因此要对query做标注才能抽取出正确的s、o,而考虑到分词可能切错边界,因此应该使用基于字的输入来标注;
- 样本中大多数的抽取结果是“一个s、多个(p, o)”的形式,比如“周杰伦的《告白气球》、《龙卷风》《明明就》等等歌曲都是我常伴我的良友”,那么要抽出“(周杰伦, 歌曲, 告白气球)”、“(周杰伦, 歌曲, 龙卷风)”、“(周杰伦, 歌曲, 明明就)”;
- 抽取结果是“多个s、一个(p, o)”甚至是“多个s、多个(p, o)”的样本也占有一定比例,比如“《战狼》、《战狼2》的主演都是吴京”,那么要抽出“(战狼, 主演, 吴京)”、“(战狼2, 主演, 吴京)”;
- 同一对(s, o)也可能对应多个p,比如“《如果我爱你》是由海润影视与明道工作室联合出品”,那么要抽出“(如果我爱你, 出品公司, 海润影视)”、“(如果我爱你, 出品公司, 明道工作室)”;
- 极端情况下,s、o之间是可能重叠的,比如“《鲁迅自传》由江苏文艺出版社出版”,严格上来讲,除了要抽出“(鲁迅自传, 出版社, 江苏文艺出版社)”外,还应该抽取出“(鲁迅自传, 作者, 鲁迅)”。
需要抽取的spo类别如下:
{"object_type": "地点", "predicate": "祖籍", "subject_type": "人物"}
{"object_type": "人物", "predicate": "父亲", "subject_type": "人物"}
{"object_type": "地点", "predicate": "总部地点", "subject_type": "企业"}
{"object_type": "地点", "predicate": "出生地", "subject_type": "人物"}
{"object_type": "目", "predicate": "目", "subject_type": "生物"}
{"object_type": "Number", "predicate": "面积", "subject_type": "行政区"}
{"object_type": "Text", "predicate": "简称", "subject_type": "机构"}
{"object_type": "Date", "predicate": "上映时间", "subject_type": "影视作品"}
{"object_type": "人物", "predicate": "妻子", "subject_type": "人物"}
{"object_type": "音乐专辑", "predicate": "所属专辑", "subject_type": "歌曲"}
{"object_type": "Number", "predicate": "注册资本", "subject_type": "企业"}
{"object_type": "城市", "predicate": "首都", "subject_type": "国家"}
{"object_type": "人物", "predicate": "导演", "subject_type": "影视作品"}
{"object_type": "Text", "predicate": "字", "subject_type": "历史人物"}
{"object_type": "Number", "predicate": "身高", "subject_type": "人物"}
{"object_type": "企业", "predicate": "出品公司", "subject_type": "影视作品"}
{"object_type": "Number", "predicate": "修业年限", "subject_type": "学科专业"}
{"object_type": "Date", "predicate": "出生日期", "subject_type": "人物"}
{"object_type": "人物", "predicate": "制片人", "subject_type": "影视作品"}
{"object_type": "人物", "predicate": "母亲", "subject_type": "人物"}
{"object_type": "人物", "predicate": "编剧", "subject_type": "影视作品"}
{"object_type": "国家", "predicate": "国籍", "subject_type": "人物"}
{"object_type": "Number", "predicate": "海拔", "subject_type": "地点"}
{"object_type": "网站", "predicate": "连载网站", "subject_type": "网络小说"}
{"object_type": "人物", "predicate": "丈夫", "subject_type": "人物"}
{"object_type": "Text", "predicate": "朝代", "subject_type": "历史人物"}
{"object_type": "Text", "predicate": "民族", "subject_type": "人物"}
{"object_type": "Text", "predicate": "号", "subject_type": "历史人物"}
{"object_type": "出版社", "predicate": "出版社", "subject_type": "书籍"}
{"object_type": "人物", "predicate": "主持人", "subject_type": "电视综艺"}
{"object_type": "Text", "predicate": "专业代码", "subject_type": "学科专业"}
{"object_type": "人物", "predicate": "歌手", "subject_type": "歌曲"}
{"object_type": "人物", "predicate": "作词", "subject_type": "歌曲"}
{"object_type": "人物", "predicate": "主角", "subject_type": "网络小说"}
{"object_type": "人物", "predicate": "董事长", "subject_type": "企业"}
{"object_type": "Date", "predicate": "成立日期", "subject_type": "机构"}
{"object_type": "学校", "predicate": "毕业院校", "subject_type": "人物"}
{"object_type": "Number", "predicate": "占地面积", "subject_type": "机构"}
{"object_type": "语言", "predicate": "官方语言", "subject_type": "国家"}
{"object_type": "Text", "predicate": "邮政编码", "subject_type": "行政区"}
{"object_type": "Number", "predicate": "人口数量", "subject_type": "行政区"}
{"object_type": "城市", "predicate": "所在城市", "subject_type": "景点"}
{"object_type": "人物", "predicate": "作者", "subject_type": "图书作品"}
{"object_type": "Date", "predicate": "成立日期", "subject_type": "企业"}
{"object_type": "人物", "predicate": "作曲", "subject_type": "歌曲"}
{"object_type": "气候", "predicate": "气候", "subject_type": "行政区"}
{"object_type": "人物", "predicate": "嘉宾", "subject_type": "电视综艺"}
{"object_type": "人物", "predicate": "主演", "subject_type": "影视作品"}
{"object_type": "作品", "predicate": "改编自", "subject_type": "影视作品"}
{"object_type": "人物", "predicate": "创始人", "subject_type": "企业"}object和predicate之间组合一个重复
文章出处登录后可见!