前 言:作为当前先进的深度学习目标检测算法YOLOv7,已经集合了大量的trick,但是还是有提高和改进的空间,针对具体应用场景下的检测难点,可以不同的改进方法。此后的系列文章,将重点对YOLOv7的如何改进进行详细的介绍,目的是为了给那些搞科研的同学需要创新点或者搞工程项目的朋友需要达到更好的效果提供自己的微薄帮助和参考。由于出到YOLOv7,YOLOv5算法2020年至今已经涌现出大量改进论文,这个不论对于搞科研的同学或者已经工作的朋友来说,研究的价值和新颖度都不太够了,为与时俱进,以后改进算法以YOLOv7为基础,此前YOLOv5改进方法在YOLOv7同样适用,所以继续YOLOv5系列改进的序号。另外改进方法在YOLOv5等其他算法同样可以适用进行改进。希望能够对大家有帮助。
具体改进办法请关注后私信留言!关注免费领取深度学习算法学习资料!
解决问题:之前改进增加了很多注意力机制的方法,包括比较常规的SE、CBAM等,本文加入基于MLP的注意力机制,该注意力机制了保留通道和空间方面的信息以增强跨维度交互的重要性。因此,我们提出了一种全局调度机制,通过减少信息缩减和放大全局交互表示来提高深度神经网络的性能,提高检测效果。
基本原理:
视觉识别的“咆哮的20年代”始于视觉变形金刚(ViTs)的引入,它迅速取代ConvNets成为最先进的图像分类模型。另一方面,普通的ViT在应用于诸如对象检测和语义分割等一般计算机视觉任务时面临困难。正是分层的变形金刚(例如Swin Transformers)重新引入了几个ConvNet先验,使变形金金刚作为通用视觉骨干切实可行,并在各种视觉任务中表现出色。然而,这种混合方法的有效性仍然很大程度上归功于变压器的固有优势,而不是卷积的固有电感偏差。在这项工作中,我们重新审视了设计空间,并测试了纯ConvNet所能达到的极限。我们逐渐将标准的ResNet“现代化”为视觉变换器的设计,并发现了一些关键组件,这些组件在设计过程中会产生性能差异。这一探索的结果是一系列被称为Con-vNeXt的纯ConvNet模型。ConvNeXts完全由标准ConvNet模块构建,在准确性和可扩展性方面与Transformers竞争激烈,实现了87.8%的ImageNet顶级精度,在COCO检测和ADE20K分割方面优于Swin Transformers,同时保持了标准ConvNet的简单性和效率。
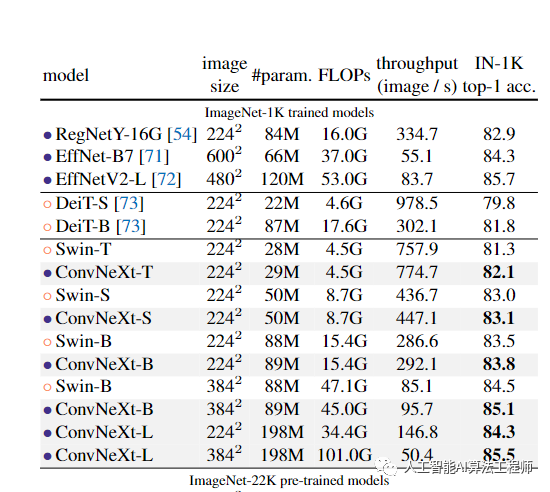
我们在表(下图)中展示了从ImageNet-22K预训练微调的模型的结果。这些实验很重要,因为人们普遍认为,视觉变形金刚具有较少的感应偏差,因此在更大规模的预训练时,其表现比ConvNets更好。我们的结果表明,当使用大数据集进行预训练时,设计得当的ConvNets并不比视觉变形金刚差-ConvNeXts的性能仍与同类尺寸的SwinTransformers相当或更好,吞吐量略高。此外,我们的ConvNeXt XL模型达到了87.8%的精度,比ConvNeXt-L的3842精度有了相当大的提高,表明ConvNeX是可扩展的架构。在ImageNet-1K、EfficientNetV2-L上,一个配备了高级模块(如挤压和激励[35])和渐进式训练程序的搜索架构实现了最佳性能。然而,通过ImageNet-22K预训练,ConvNeXt能够超越EfficientNetV2,进一步证明了大规模训练的重要性。在附录B中,我们讨论了ConvNeXt的鲁棒性和域外泛化结果。
添加方法:
第一步:确定添加的位置,作为即插即用的注意力模块,可以添加到YOLOv7网络中的任何地方。
第二步:common.py构建模块。部分代码如下,关注文章末尾,私信后领取。
class CNeB(nn.Module):
# CSP ConvNextBlock with 3 convolutions by iscyy/yoloair
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(ConvNextBlock(c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))第三步:yolo.py中注册CNeB模块
elif m is CNeB:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m is CNeB:
args.insert(2, n)
n = 1第四步:修改yaml文件,本文以修改backbone为例,将原C3模块后加入该模块。
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, CNeB, [1024]],
[-1, 1, Conv, [256, 3, 1]],
]第五步:将train.py中改为本文的yaml文件即可,开始训练。
结 果:本人在遥感数据集上进行实验,有涨点效果。需要请关注留言。
预告一下:下一篇内容将继续分享深度学习算法相关改进方法。有兴趣的朋友可以关注一下我,有问题可以留言或者私聊我哦
PS:该方法不仅仅是适用改进YOLOv5,也可以改进其他的YOLO网络以及目标检测网络,比如YOLOv7、v6、v4、v3,Faster rcnn ,ssd等。
最后,有需要的请关注私信我吧。关注免费领取深度学习算法学习资料!
文章出处登录后可见!