本文分为两部分,分别是pc端yolov5演示,以及把yolov5模型部署到开发板。这是一套整体流程哦!!!对了,实现的功能是在高速路上完成各种检测:汽车爆炸,汽车碰撞,行人进入高速,应急车道占用,汽车逆向行驶
开发环境:
pc:python3.6,pytorch1.10,显卡1080,gcc7.5,ubuntu18.04
硬件:瑞星微1126
1.PC端
1.1 yolov5数据集
数据集为yolo形式的,car,fire,person,其中car分为正向和逆向,第一阶段为2229张图片和对应txt。我们团队已经全部标注完了,如果你需要可以评论区艾特我。
1.数据集制作。利用Make Sense
该软件可以帮助我们半人工进行标注,由于yolo已经识别了人和车,我们只需要自己把火标注,然后对已经标注的车,我们根据车的行驶方向再进行一次标注。

如上所示,紫色框为汽车,红色框为火焰。
2.最后我们的文件如下,其中包括图像和txt形式的标签文件。
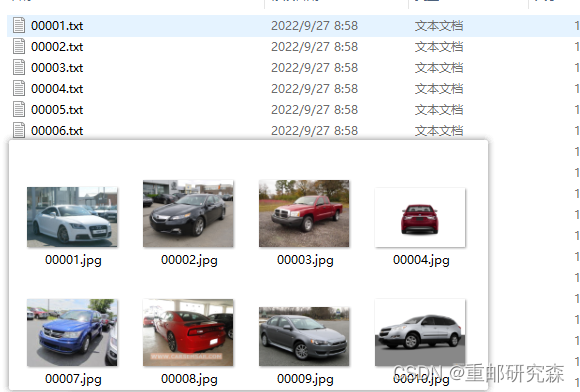
该类型的文件很方便我们训练,只需要把label文件和images文件分别放到指定文件夹即可。
1.2 yolov5训练
1.自建一个firecarpersn.yaml文件,该文件用来指定训练输出种类和数据地址。需要注意就是路径和分类的种类
2.修改tarin.py,这样才会去训练你自己的数据

3.可以使用 python train.py 运行啦!
2.模型部署
2.1 pt转为torchscript和onnx
1.首先对pt模型文件进行转换为torchscript.pt文件。值得注意的是,当前github上的yolo系列代码大多都是带有export.py这个文件,该文件就是进行模型转换的代码。现在我按照我这个代码进行演示如何进行转换。
我的这个export文件在models下面。运行代码如下:
python models/export.py --weights ./fireonly.pt这里的意思就是把fireonly.py转换,至于转换成什么我们不用担心,因为官方的export已经写好了,默认就是fireonly.xxx.pt。其中这里xxx包括本次的torchscript和onnx。此外,运行的路径必须在fireonly.py这个路径,这里出错的问题只可能是路径,你一定要看清楚linux路径!!!运行成功后,即可得到下面的文件。
附上所有模型格式截图。来表明哥确实转换成功了!!!

本次主要完成了数据集制作,已经模型环境部署,现在就等着实验室那个1080空闲了,开始训练。然后部署方面,我用单独检测火焰的pt模型也完成了torchscript和onnx格式的文件。好了,今天工作先到这里。下次再见!!!
2022.9.27 20.44
经过长达7小时的等待,第一轮模型训练结束!!!然鹅效果并不好
yolov5pc端第一次训练结果
可以发现对于火焰检测存在漏检现象,然后这种着火的车没有识别到车,于是我们下阶段准备把着火的车只识别出来是车,不是之前的车和火都会被检测出来。
于是乎,我们又开始准备数据集了,,,,当然了之前的数据集不是没用,而是不适合我们的应用场景罢了。
记录一下xml文件转txt文件
由于不想找数据集了,于是去下载了数据集,但是这里的不是txt,而是xml,因此我们需要对xml格式文件进行转换,其代码如下:
需要改动的地方就是classes的类,以及文件夹路径。
import xml.etree.ElementTree as ET
import os
from os import getcwd
from os.path import join
import glob
sets = ['train'] # 分别保存训练集和测试集的文件夹名称
classes = ['car'] # 标注时的标签
'''
xml中框的左上角坐标和右下角坐标(x1,y1,x2,y2)
》》txt中的中心点坐标和宽和高(x,y,w,h),并且归一化
'''
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(data_dir, imageset, image_id):
in_file = open(data_dir + '/%s_annotations/%s.xml' % (imageset, image_id)) # 读取xml
out_file = open(data_dir + '/%s_labels/%s.txt' % (imageset, image_id), 'w') # 保存txt
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
if obj.find('difficult'):
difficult = obj.find('difficult').text
else:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls) # 获取类别索引
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str('%.6f' % a) for a in bb]) + '\n')
wd = getcwd()
print(wd) # 当前路径
data_dir = 'F:/项目/yolo高速路检测/xml2txt'
for image_set in sets:
image_ids = []
for x in glob.glob(data_dir + '/%s_annotations' % image_set + '/*.xml'):
print(x)
image_ids.append(os.path.basename(x)[:-4])
print('\n%s数量:' % image_set, len(image_ids)) # 确认数量
i = 0
for image_id in image_ids:
i = i + 1
convert_annotation(data_dir, image_set, image_id)
print("%s 数据:%s/%s文件完成!" % (image_set, i, len(image_ids)))
print("Done!!!")
到这里,我们就准备好了数据集 ,分别是车,人,火。(因为我不准备直接通过分类识别逆行车了)
但是!!!,找的数据集标签都是0,因此还需要一个脚本把标签属性改一下。
import os
import re
# 路径
path = 'F:/项目/yolo高速路检测/fire_dataset/fire_dataset/labels/train/'
# 文件列表
files = []
for file in os.listdir(path):
if file.endswith(".txt"):
files.append(path+file)
# 逐文件读取-修改-重写
for file in files:
with open(file, 'r') as f:
new_data = re.sub('^0', '2', f.read(), flags=re.MULTILINE) # 将列中的0替换为2
with open(file, 'w') as f:
f.write(new_data)
ok,ok,ok终于把数据集制作完成了。
此外,今天也把上次的onnx后缀文件模型转为rkkn后缀,具体实现如下。
当然了,什么都不是一帆风顺,哥刚开始就遇到小问题了,这个Ubuntu18分辨率太差
然后系统设置里面最大分辨率为1024×768,都不能修改的,于是乎我们为了“面子”,把分辨率改改。
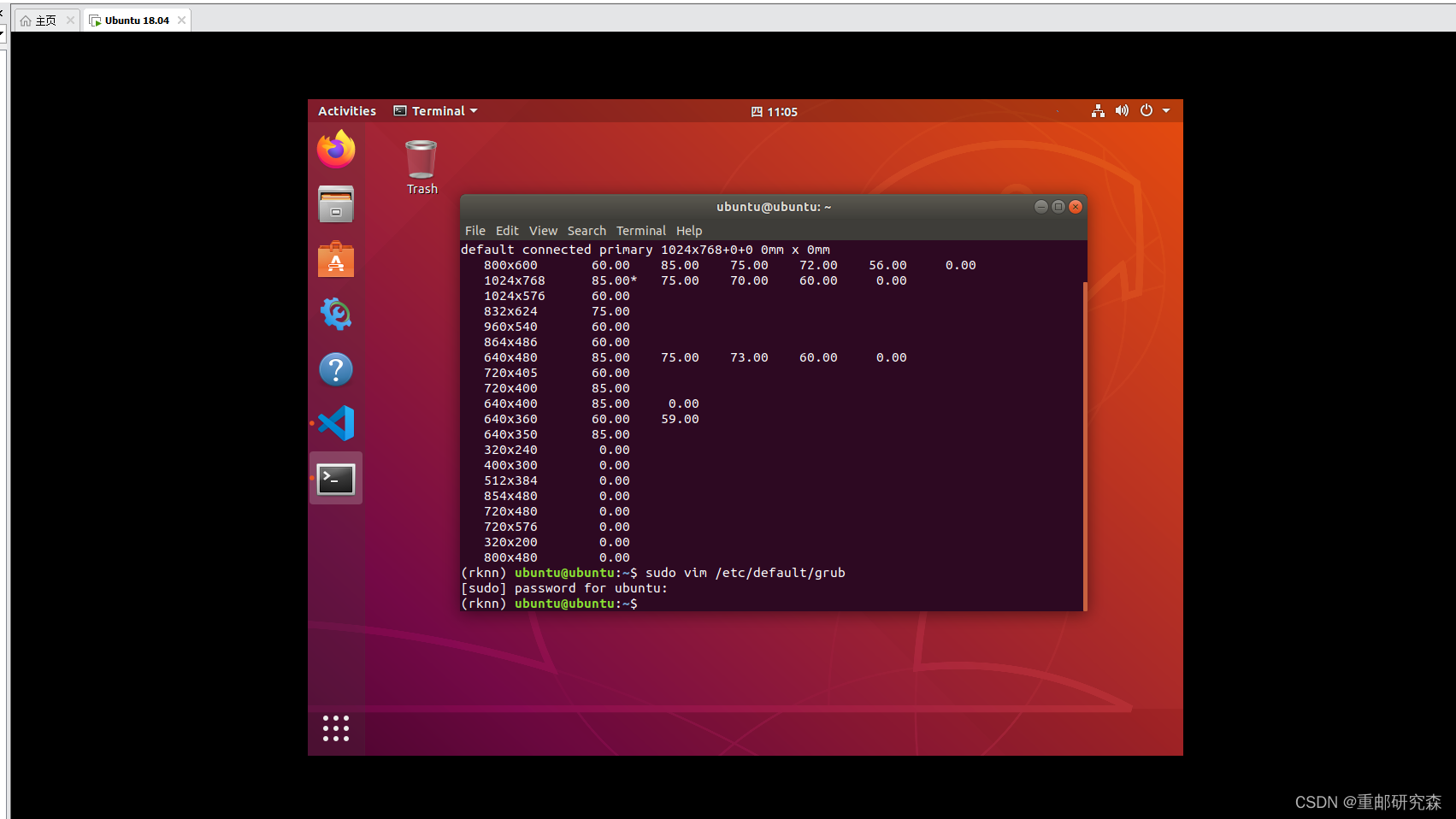
修改的方式为:
(12条消息) ubuntu18.04分辨率最高只有1024*768_Onwaier的博客-CSDN博客_ubuntu分辨率1024*768
改完之后的效果如下:十分完美
好了,现在我们开始模型转换的工作了。
转换工具路径为:
/home/ubuntu/project/rv1126_0310/external/rknn-toolkit/examples/onnx/yolov5
现在我们通过vsocd来看一下我们如何修改官方转换代码。
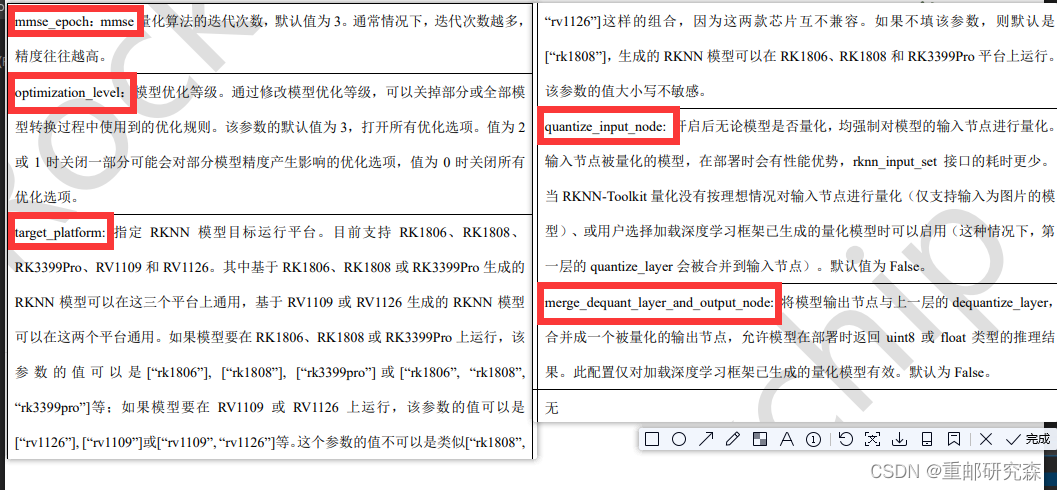
config修改,这里完成输入尺寸,平台等选项,具体说明参考下面官方文档截图

然后利用官方代码,把我第一轮结果的onnx模型进行转换,其结果如下:
python test.py转模型时,不需要开发板,可以直接转rknn。

当然了,在模型转换的过程中,需要改一下下面的代码。
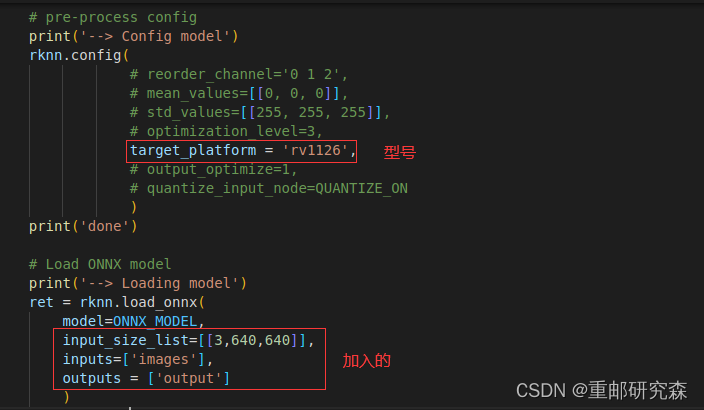
然后直接输入命令:就可以得到上面的结果。
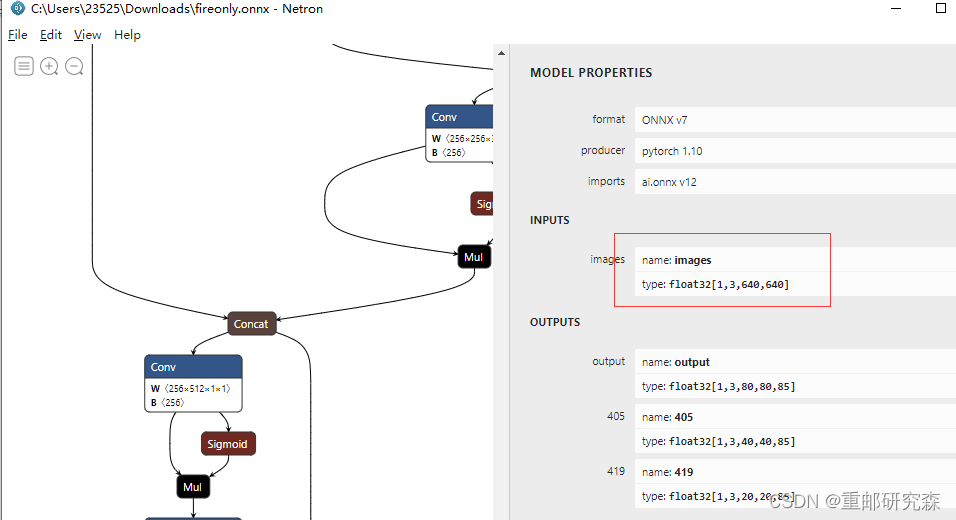
python test.py补充说明,我们还下载了一个看模型形状的软件,比如这里的输入尺寸,640×640就是根据软件看出来的。该软件地址如下。可以下载一下。
Netron download | SourceForge.net
它的使用截图如下:可以看到模型的结构
硬件环境先到这,接下来 我们来看看训练结果。
数据集1200car,1200fire,几十个person,因为我之前穿person数据的时候一直超时,就没搞这么多人。反正就是人的数据集没怎么准备好。其他的还好
由于本次训练实验室服务器有人使用,于是在本机电脑训练,由于时间原因,bathsize调到了24,轮数改为180轮,现在我们来看看第二次的训练结果。
yolov5pc端第2次训练结果
可以看到,这次对于火焰识别好了很多,对人还是不够好,上面也说了原因。
本次是第二轮训练,但存在训练时间不够,人数据集不够等问题,接下来会继续调整。好了,今天就先到这里吧。
2022.9.30 9.39
第三轮训练结束了,本次跑满了18个小时,训练结果更好了,训练结果如下:
yolov5pc第三次训练
同时本次我们也要在开发板上跑一下,利用开发板的npu来进行预测,当然这和部署还是两回事情,只是利用了开发板的npu跑代码。
1.我们已经完成了rknn模型转换
2.我们调整了官方代码中关于类的个数(因为官方的是几十种分类)

3.我们根据“自己”生成的模型改了输出
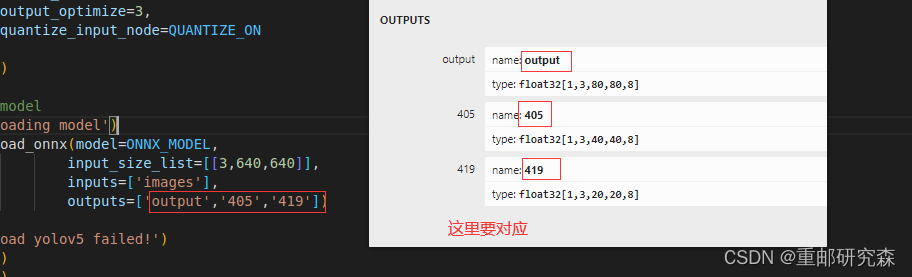
4.加入了循环通过输入名字进行预测(有bug)
然后我们运行代码:
python test2.py可以发现,对于火焰还是进行了识别,其中右侧是pc电脑端,左侧是开发板npu实现

今天我们主要完成了第三轮训练以及利用开发板的npu进行了测试。我们发现,pc端训练结果还是不够好,但是目前我不准备在数据集动手脚增加准确率了。因此后续主要针对开发板了。
2022.10.4
我是在2022.10.13才得知这个噩耗!高速路检测项目现在交给另外一个人了,我要去做雷达了。所以,更新结束了,不过!我会继续写一篇如何把雷达部署到1126开发板。提前透露一下,这里的雷达也是神经网络的方式去实现的。
2022.10.13
emmmmmm,我又回来了,因为一些奇奇怪怪的事情,我又接手这个项目了,那么我们就按照之前做吧。
2022.12.13
本次主要记录几个重要命令
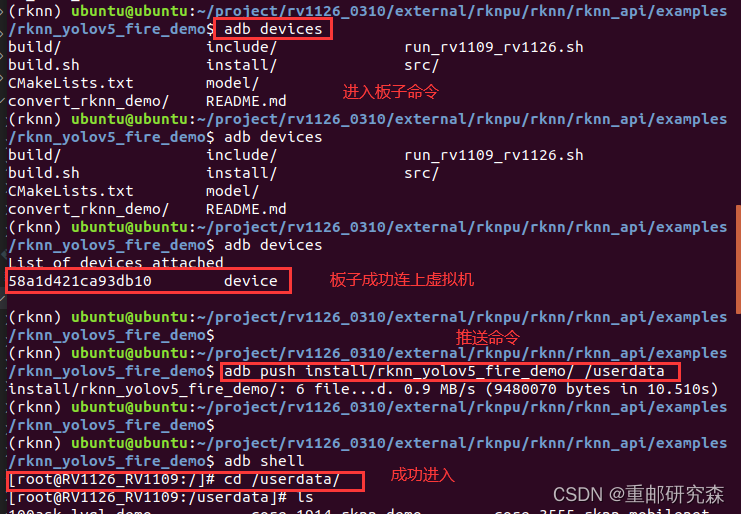
模型推送:adb push install/rknn_yolov5_fire_demo/ /userdata
板载进入:adb shell
拉取结果:adb pull /userdata/rknn_yolov5_fire_demo/out.bmp
现在进入正题,如何把一个模型进行部署(针对输入的是板子里面的图片,后续进行实时视频流处理)。
1.找到官方提供的原模型代码
2.更换里面的标签,模型,文件名字
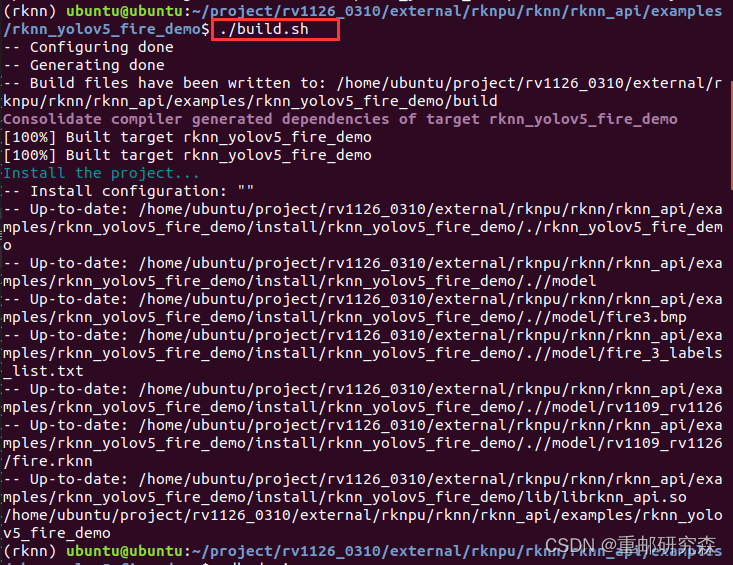
3./build.sh
4.把生成的文件推送到板子
5.进入板子运行代码,通过命令获取结果图片
1.找到官方提供的原模型代码
官方文件在下面这个地方:
/home/ubuntu/project/rv1126_0310/external/rknpu/rknn/rknn_api/examples/rknn_yolov5_demo
作为一个健康的码农,我们肯定是直接在别人官方的源码基础上进行修改,因此先复制一份,并且取名为:

2.更换里面的标签,模型,文件名字
这里比较麻烦一点,因为涉及到改很多地方。所以为了修改方便,我这里提前说明一个注意事项。因为改东西主要针对:文件名字,改模型,改
| 修改内容 | 颜色 |
| 文件名字 | 红框 |
| 具体内容 | 绿框 |


3./build.sh
这里替换之后,我们就可以运行了,正常运行界面如下
4.把生成的文件推送到板子
5.进入板子运行代码,通过命令获取结果图片
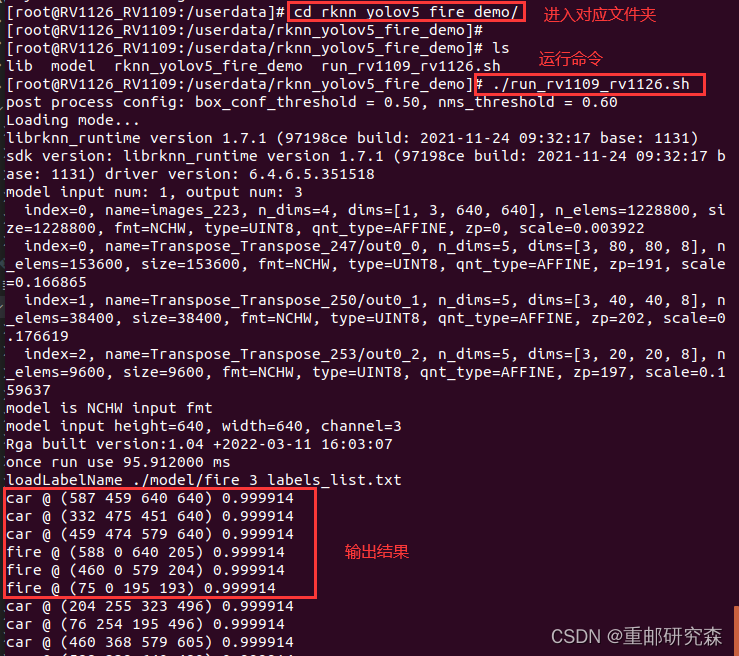
把带框的结果进行显示
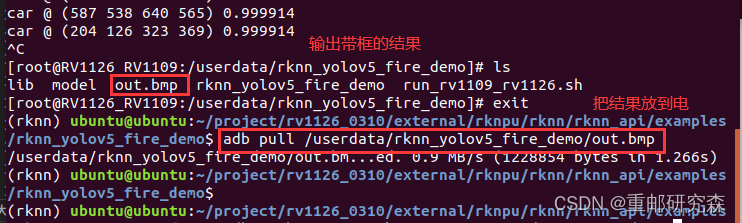

哈哈哈,这个结果说实话,很丑陋,嗯,我们后续将针对火焰单独数据集进行训练,因为我需要确定我转换模型有没有问题,顺便重新复习一下转模型的知识。
记录一个bug。在yolov5训练时报错了,你可以去看看你的数据集文件是不是有其他的东西,删除就好了,我是有train.cache这个。
_pickle.UnpicklingError: STACK_GLOBAL requires str
针对上次的模型部署之后效果很垃圾,于是乎我今天采用了yolo官方模型,看看到底是转换问题还是模型问题。
2022.12.14
首先签名的,模型转换都是一样的,我只是在模型部署的时候,需要注意,要把
build文件夹
内容也进行替换,否则会报错,这也是我怀疑昨天有问题的原因。
还有就是我发现了另外一个问题,我去github上找到了另外一个版本的模型转换代码,我今天这个官方yolo就是利用新代码转的,因此我下午将针对新代码对上次的火焰识别进行转换以及调用部署一些列问题。顺便附上一张官方模型部署的检测效果,可以看到效果还是不错。

文章出处登录后可见!