注意
本篇文章参考李宏毅老师的讲课视频,截图均来自老师的PPT,本文是学习笔记。原视频大家可以自行搜索观看
引言
自注意力机制最初是NLP领域的
首先我们了解一下三种任务分类:
输出一个句子,可以看作一个序列。
1、输入和输出长度一致,每个vector对应一个label
假定现在做一个词性分析的任务,就是输入英文句子,给出每个单词的词性
2、整个序列对应一个label
假定现在做一个语义判断的任务,输出英文句子,给出这个句子的好坏判断。好or不好
3、输出长度不确定,由机器决定输出label的长度,这种任务叫做seq2seq
我们常见的翻译任务就是seq2seq。输出句子,输出翻译好的句子的长度是不定的。
我们以第一种为例:
假定现在做词性分析,输入一句话I saw a saw,这句话的意思是我看到了一把锯子。
那么我们用最简单的全连接网络来做这个任务
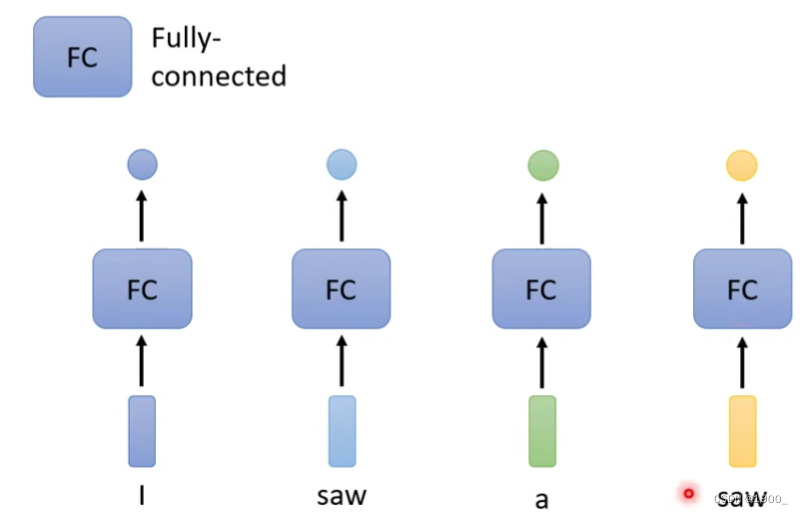
这种做法的缺点是,机器不能判断出来后一个saw做名词,表示锯子的意思
因为对于机器来说两个saw完全一样,不会输出不同的结果。
那么我们就想,如何让神经网络结合上下文的信息呢
我们可以将一个词汇的前后几个词汇串起来,称为一个window,一起输出到网络中训练
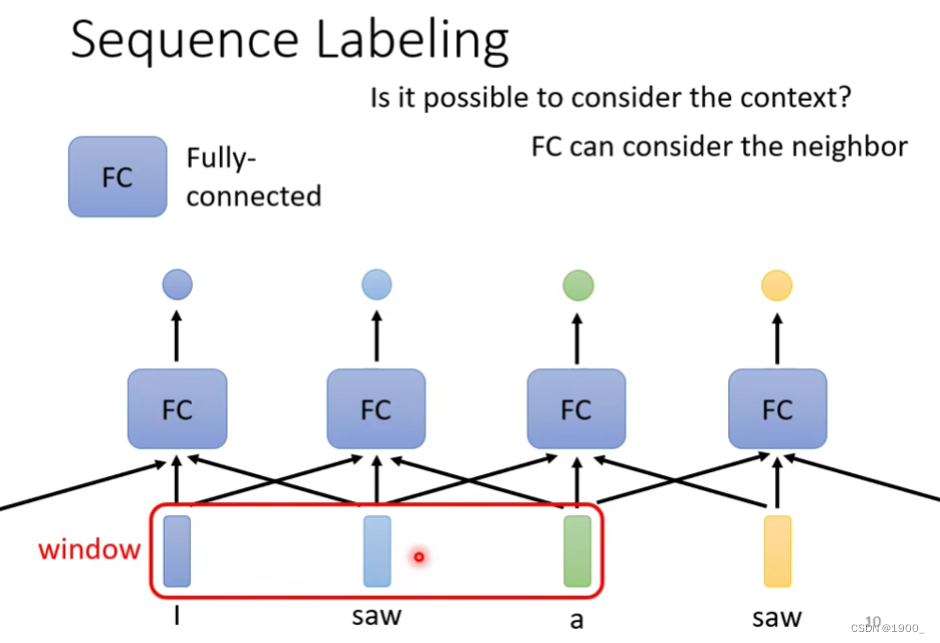
那么,按照这种方法,如果我们想考虑整个句子的信息,就需要把这个windows的大小设置为整个句子的大小。
他的问题在于:训练中每个句子都是不一样长度的,如果你想用一个windows把所有的句子都能框起来,那就需要以训练数据中最长的那个句子长度作为windows的长度来算,这样一来,计算量太大了。
所以,就引入了我们的自注意力机制
self-attention 自注意力机制
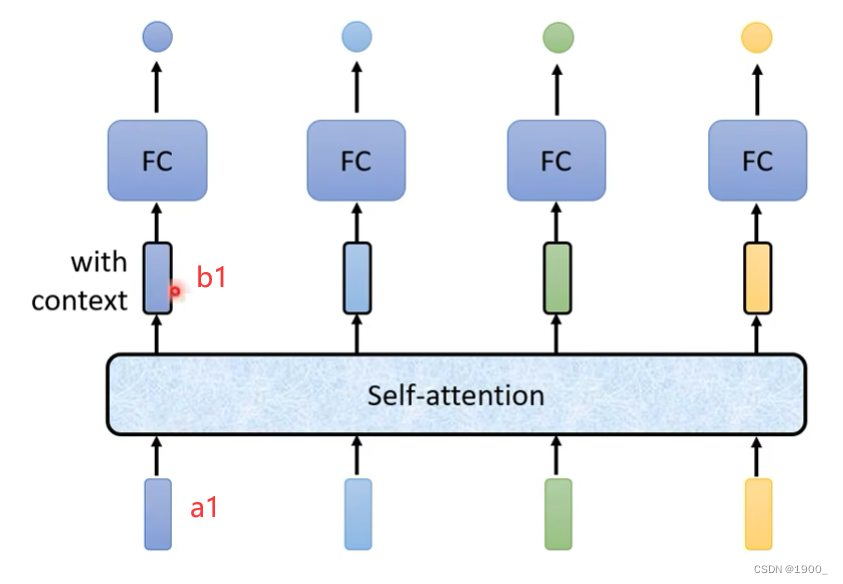
自注意力可以处理整个序列,如图
我们将一句话中每个单词,编码为一个词向量(方便网络处理),比如第一个单词“I”被编码后的向量为a1
a1经过自注意力机制输出的b1,b1是考虑了整个输入序列才得到的输出
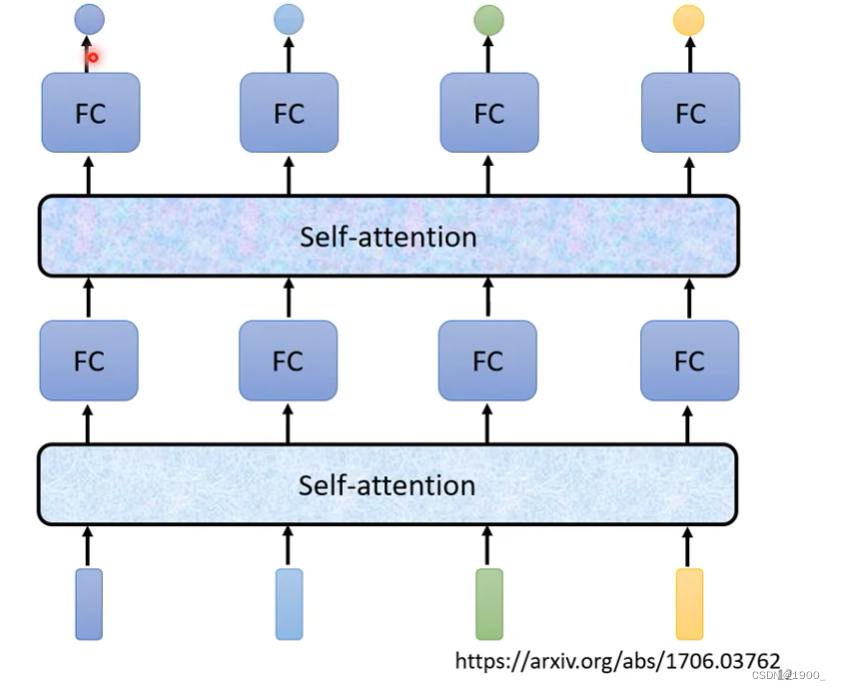
自注意力机制还可以堆叠,经过自注意力得到的输出还可以再做一遍自注意力
那么b1是怎么来的呢
首先,我们假设输入序列是a1,a2,a3,a4
第一步是,计算a1和其他向量的相关度(关联度)
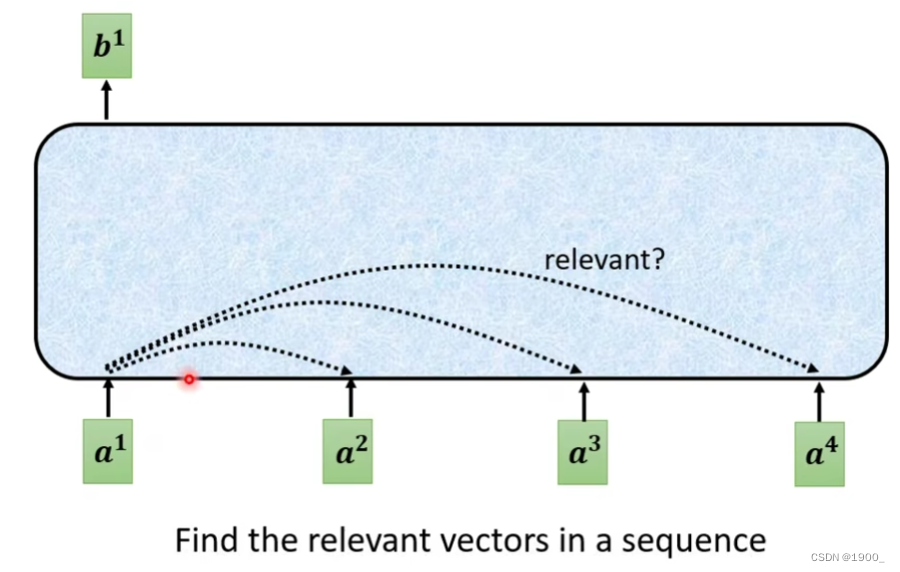
计算相关性有很多方法,常见的做法是点积。
如图,输入两个向量,分别乘上两个矩阵,得到q和k,再做一个点乘,就得到了相关度
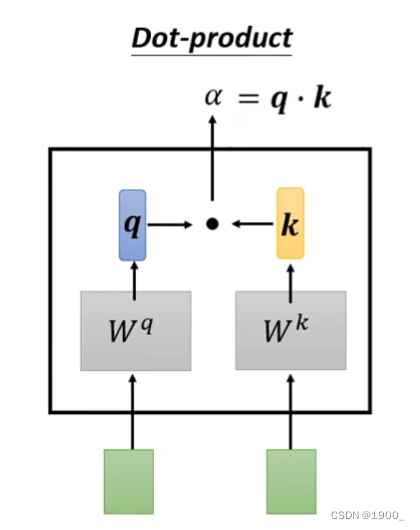
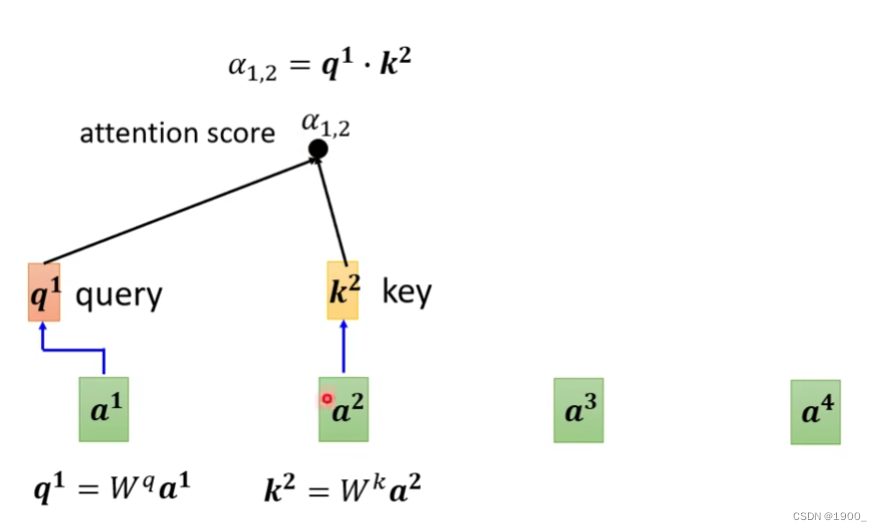
我们一般把这个q叫做query,k是key
那我们计算出a1的q,再计算出a2的k,我们就可以计算出a1和a2的关联性,我们把这个称作注意力分数
把a1和其他的所有输入的关联性全部算出来,同时,我们实际算的时候,还会计算a1和自己的关联性,如图,就是计算结果
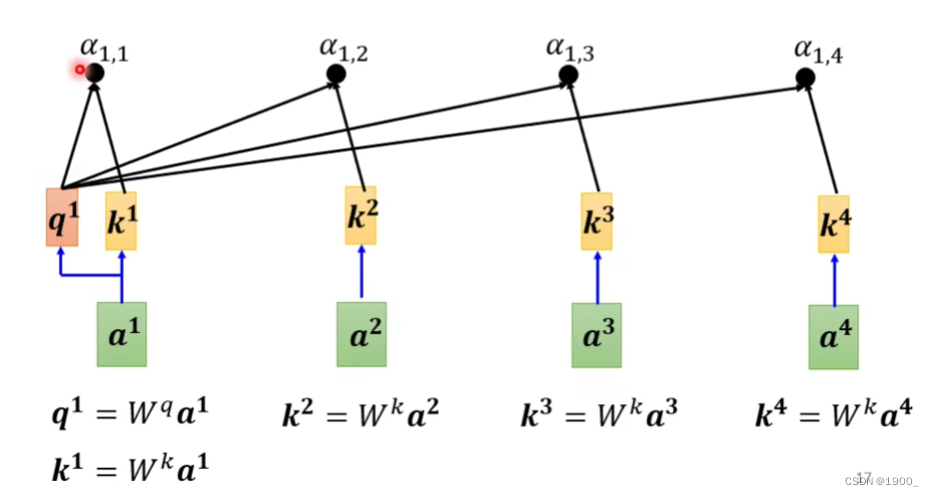
计算完了之后,经过一个softmax(这里用ReLU也行,都可以)
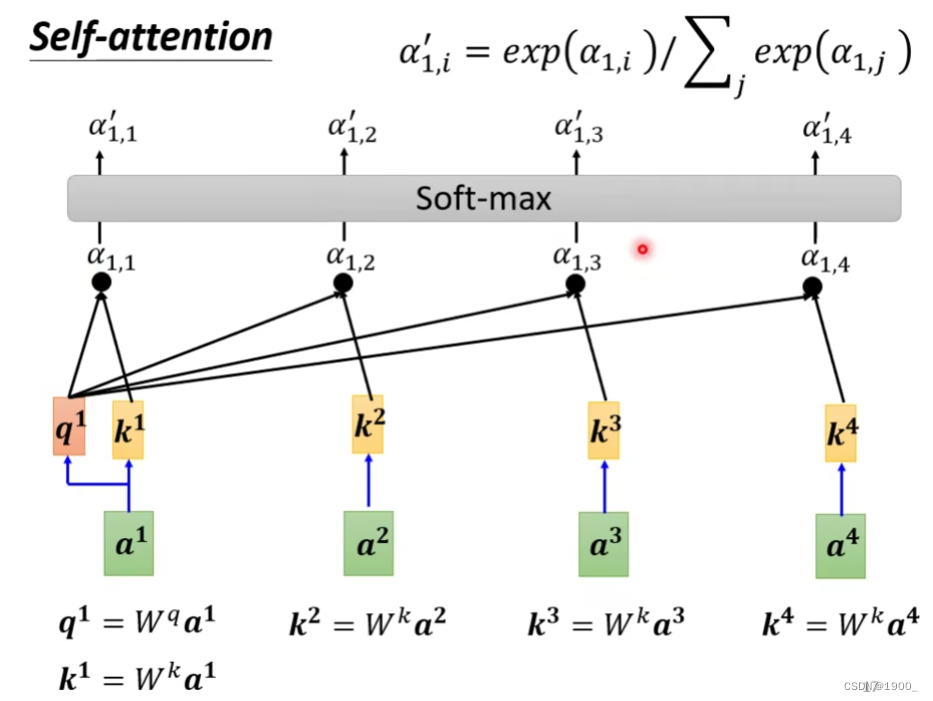
经过softmax后我们就得到了
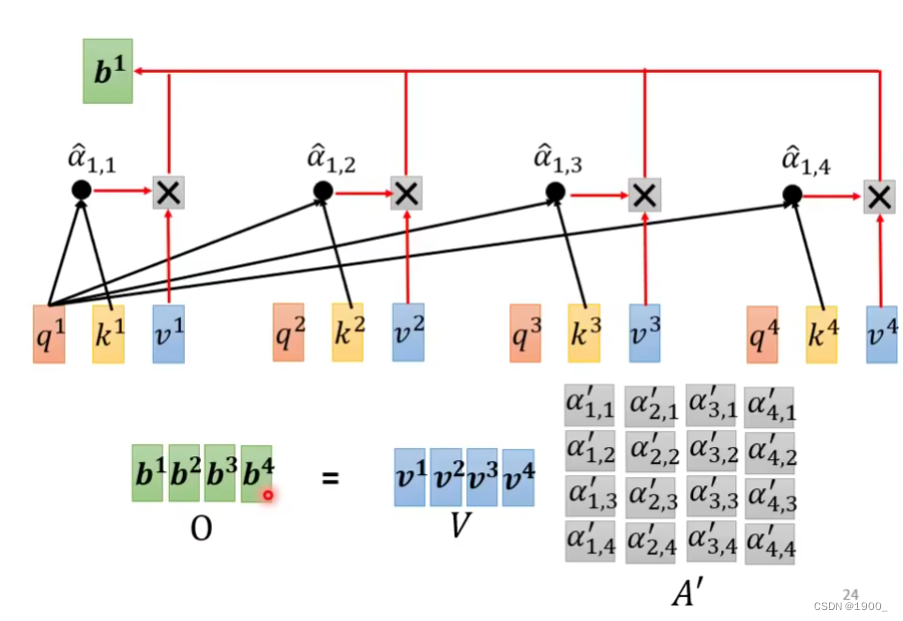
接下来,我们把原始的输入序列a1,a2,a3,a4分别乘以一个,得到对应的v1,v2,v3,v4
这个叫做value
我们把v1,v2,v3,v4分别与相乘
再把这个结果累加就得到了我们的输出b1
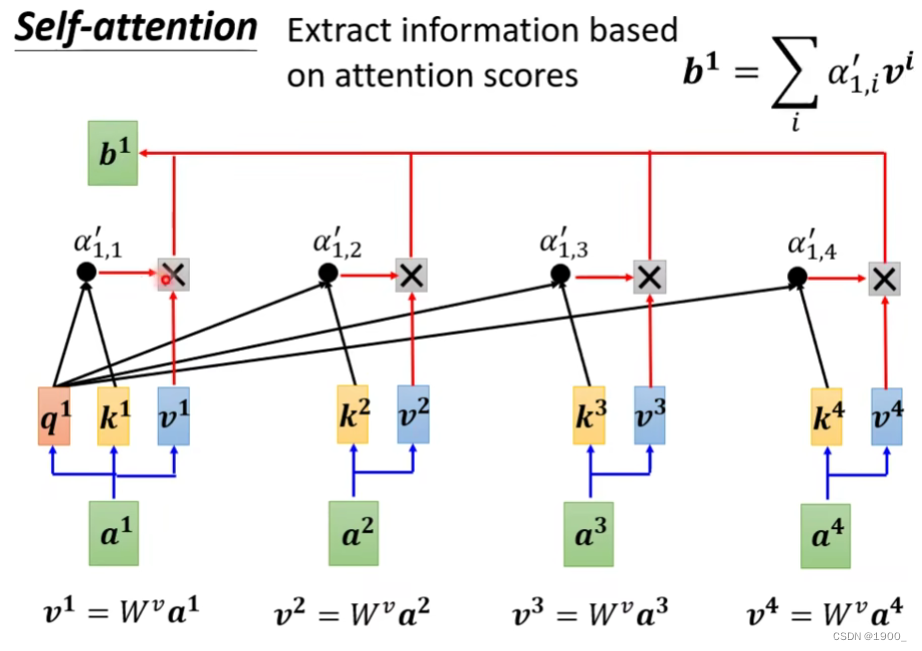
他这个原理其实就是,其实代表了a1与所有向量的相关度,如果和某一个向量的相关度比较高,那么与v相乘之后得到的值也会比较大,最后累加之后,累加得到的这个值,也会更加偏向于那个相关性更高的向量信息。
b2,b3,b4与b1的计算方式一样。最终得到自注意力的输出。
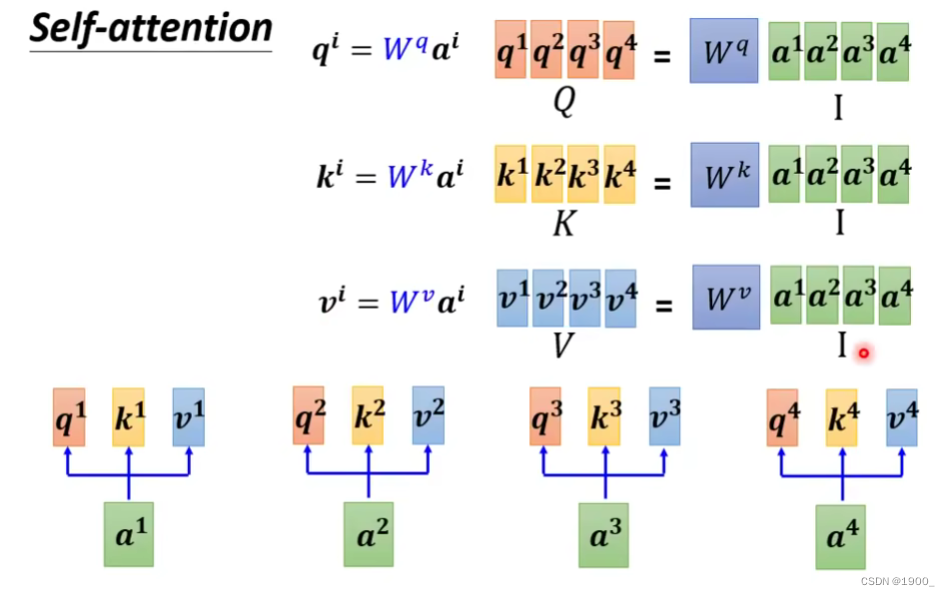
那么整个过程我们了解了,就会发现,对于每一个,我们都要产生对应的
那么用矩阵运算就是如图所示
把a1,a2,a3,a4组合成一个矩阵,乘以就行了
那么相关度的计算,或者说注意力分数的计算如图所示,用乘以
最后全部经过一个softmax,就得到了
,有时候我们把
也叫做Attention Matrix。这就是注意力分数
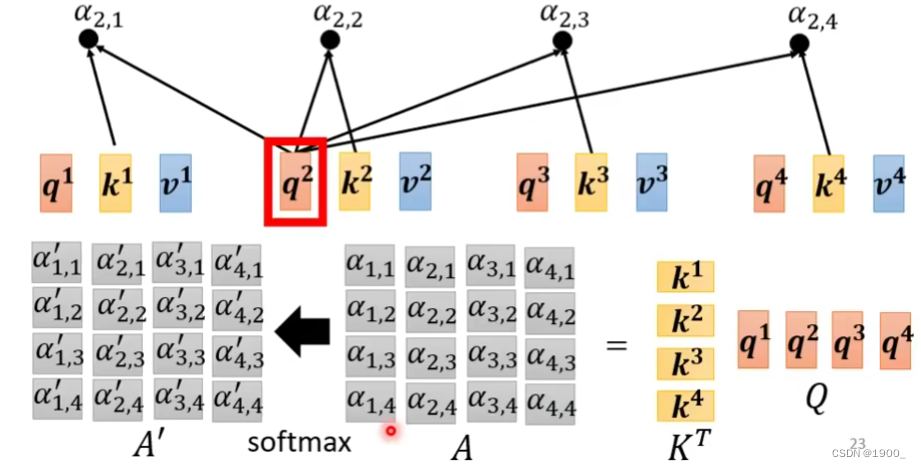
那么再把乘上V,就得到了自注意力的输出结果
在整个自注意力机制中,需要学习的参数就是这三个。
汇总图:
多头自注意力机制
Multi-head self-attention
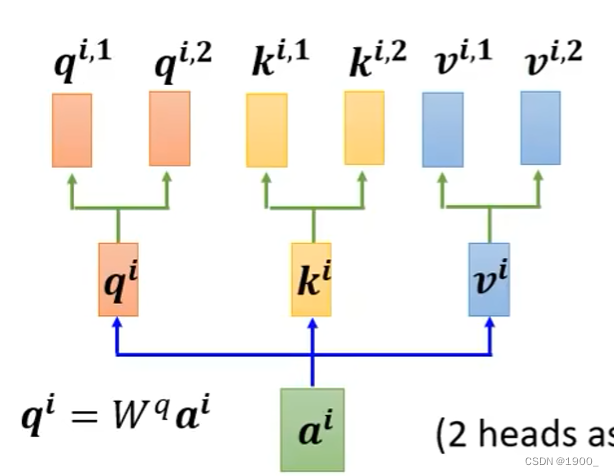
学习了自注意力机制之后,我们知道,我们用a1的q来计算他和其他元素的相关性,但是呢,相关性这个东西,其实有多种不同的,比如a1和a2在词性上相关,a1和a3在词性上不相关,但是在单词组成上相关(长得像),所以我们可以用多个q,来衡量相关性,目的是为了衡量不同角度的相关性。
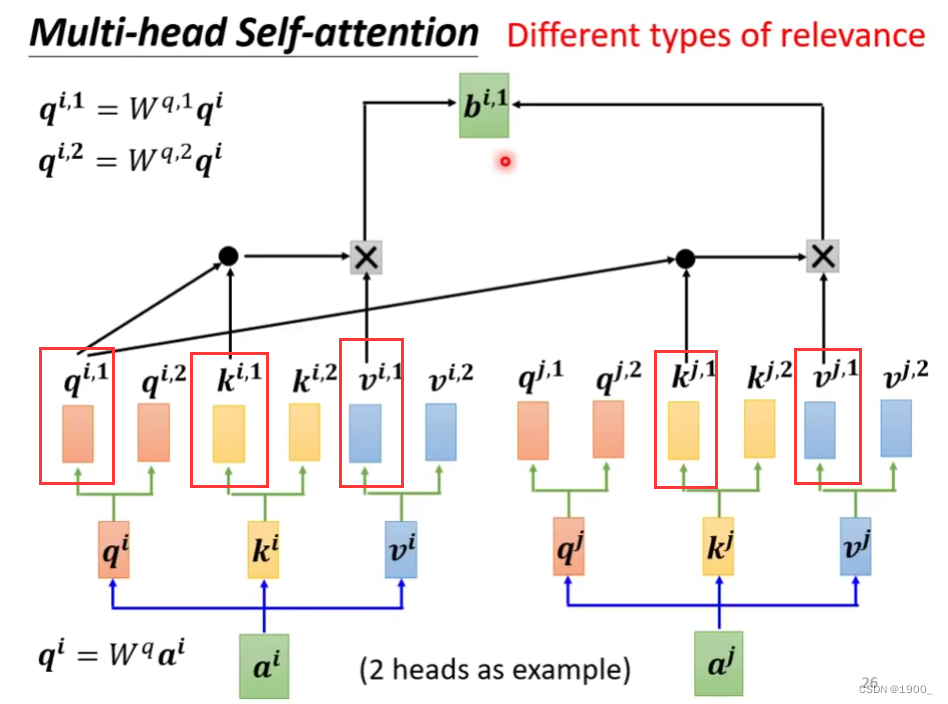
如果我们认为一个任务,存在两种不同的相关性,那我们就使用两个q,同理,对应的我们也需要两个k,两个v,如图所示,这就是双头自注意力
然后我们做softmax的时候,首先只用其中一个head,来做
再用另一个head来做,所以就得到两个b
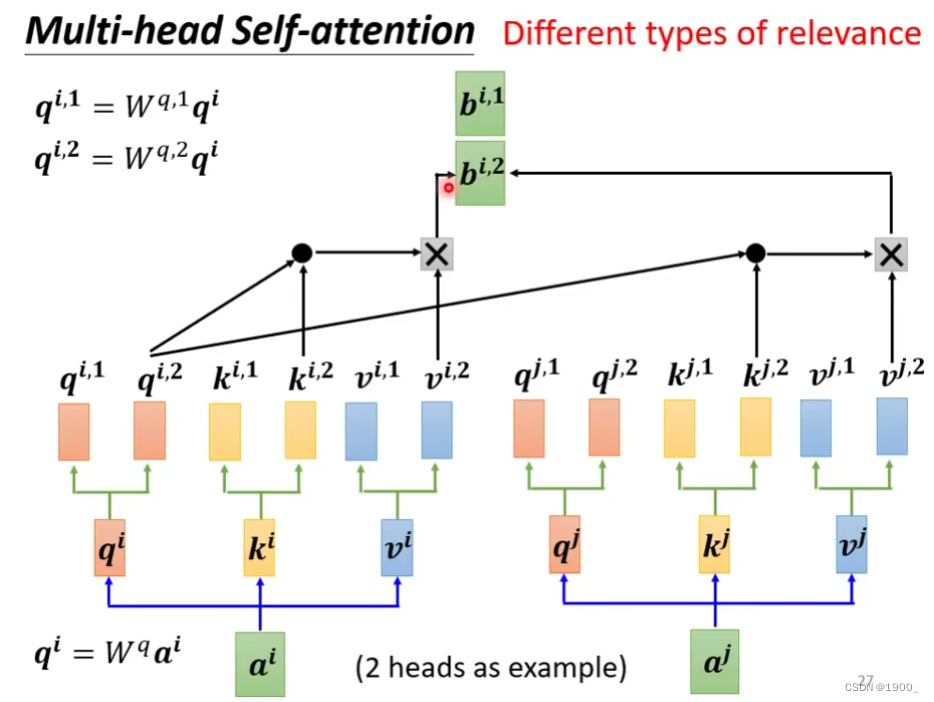
那么你多头注意力就会得到多个b,将这些并起来,然后乘以一个矩阵,就得到了输出
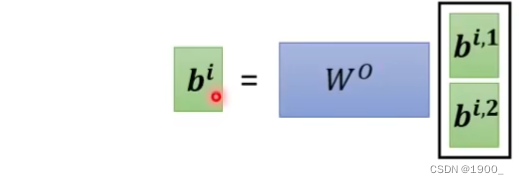
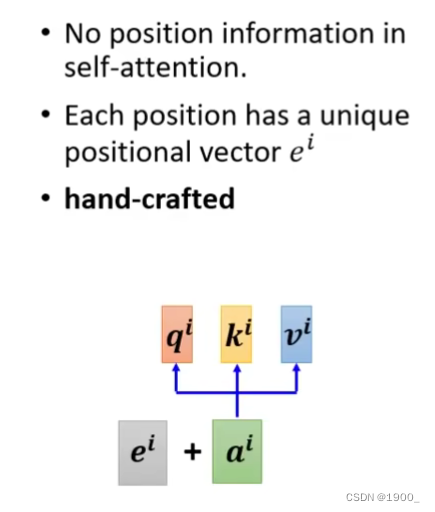
那么说到这里,自注意力机制就完了。但是他有一个问题,我们使用自注意力机制计算了不同单词之间的相关性,但是整个过程忽略了位置信息。经过softmax之后,没有各个向量之间的位置信息。但是位置信息对于我们来说是重要的,比如如果这个单词出现在句子首位那他可能大概率不是动词,所以位置有的时候是重要的。
如何把位置信息加进去呢,做法是把每一个位置,对应一个向量
把位置信息加上去就好了,这个是我们自己设置的。
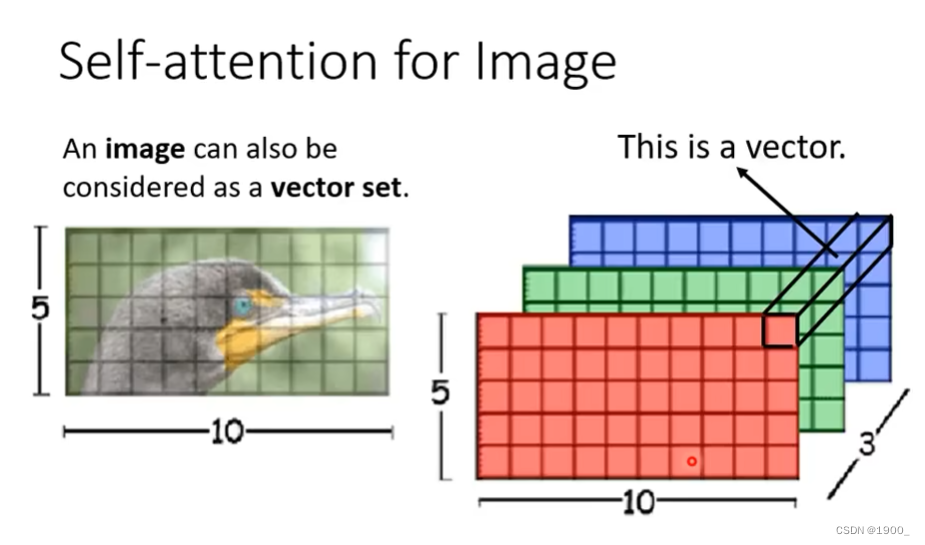
图像中的自注意力机制
那么刚才说的都是NLP领域的,每个句子我们编码成一个向量,那么图像里面怎么用自注意力机制呢
一张5×10的RGB图像就是5x10x3的矩阵,那么如果我们把每个像素在各个通道上的值拿出来,组成一个向量,这样这张图片就有5×10个向量了,把这些向量当作输入,进行自注意力就行了。
那么自注意力机制和CNN的区别在哪呢
我们用自注意力机制的时候,图像中的某个像素,会和其他所有像素做相关性计算,也就是说,对于一个像素,我们考虑了整张图像。
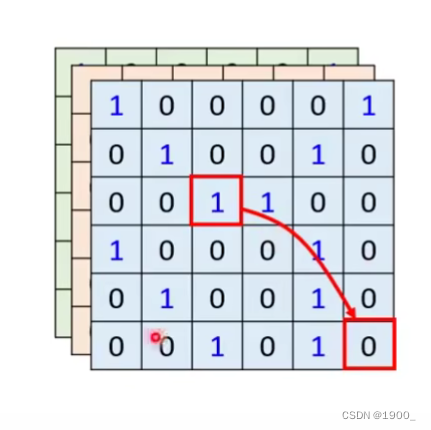
而CNN呢,由于卷积的特性,他只考虑感受野内的信息,所以没有self-attention考虑的多,我们可以认为CNN就是简化版的self-attention
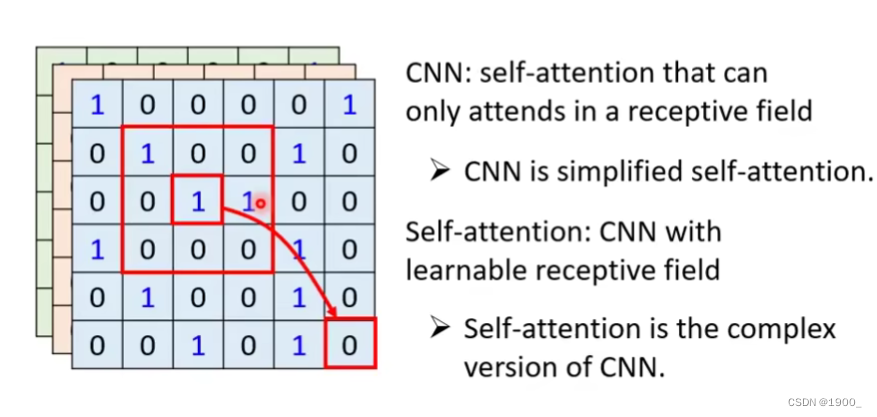
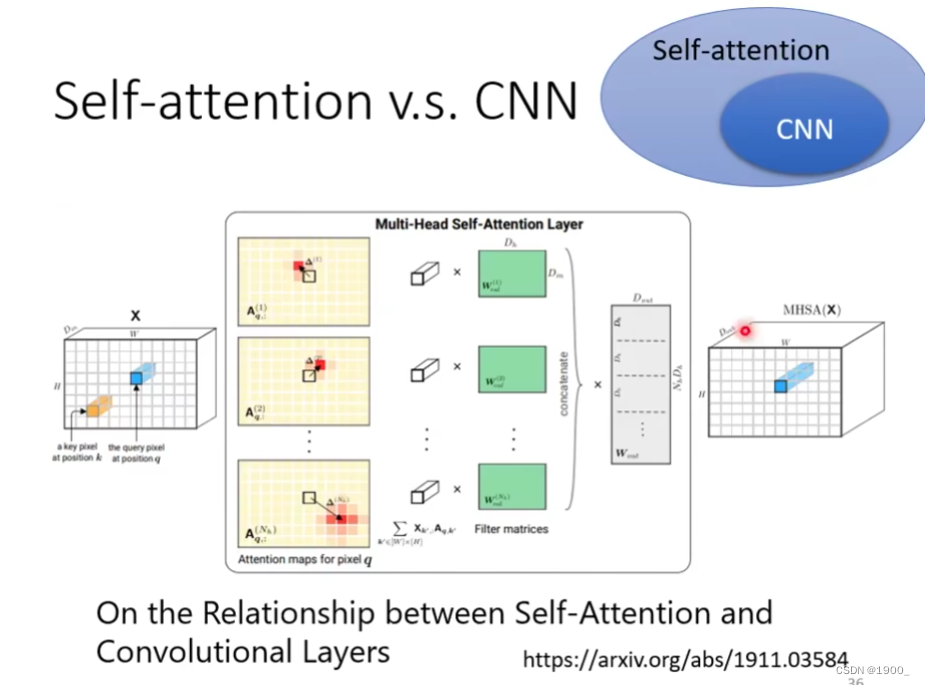
这篇论文证明了CNN就是self-attention的特例,self-attention只要经过精心的设计,就可以做到与CNN一样的效果。
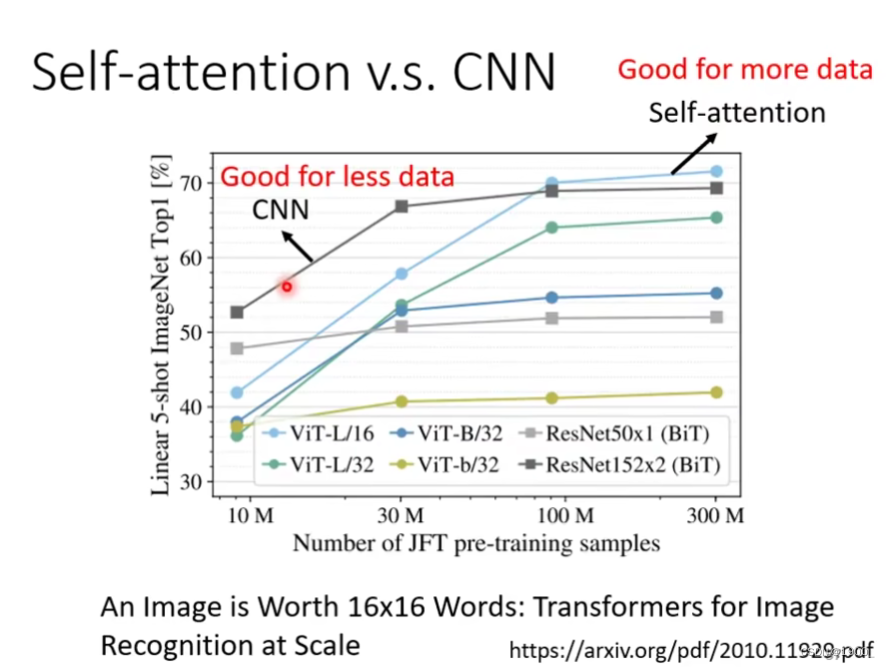
self-attention应用在图像上面,最著名的论文是An lmage is Worth 16x16 Words: Transformers for ImageRecognition at Scale
https://arxiv.org/pdf/2010.11929,pdf
谷歌的文章,他就是把一张图片,分成16×16的小块,每个小块看作一个向量,输入到self-attention上面。
这张图我们可以看出,训练资料少的时候,CNN的效果会好于自注意力,训练数据越来越大的时候,自注意力的效果会好于CNN。这个我们可以从一个角度解释:自注意力看的更多,所以训练数据少的时候,他容易过拟合,他需要更多的训练数据,而CNN 看的范围少,所以训练数据少的时候,效果更好
文章出处登录后可见!