机器学习【期末复习总结】——知识点和算法例题(详细整理)
1、什么是机器学习,什么是训练集,验证集和测试集?(摘自ML科普系列(一))
机器学习: 对计算机一部分数据进行学习,然后对另外一些数据进行预测与判断
① 训练集:
作用:估计模型
学习样本数据集,通过匹配一些参数来建立一个分类器。建立一种分类的方式,主要是用来训练模型的
② 验证集:
作用:确定网络结构或者控制模型复杂程度的参数
对学习出来的模型,调整分类器的参数,如在神经网络中选择隐藏单元数。验证集还用来确定网络结构或者控制模型复杂程度的参数。
③ 测试集:
作用:检验最终选择最优的模型的性能如何
主要是测试训练好的模型的分辨能力(识别率等)
2、监督、无监督和半监督学习各自的特点,区别以及各自对应的算法

补充说明:
主动学习: 学习算法通过标记数据从未标记数据中筛选出很有价值的数据给专家标注,并进行训练。但需要引入专家进行交互标注
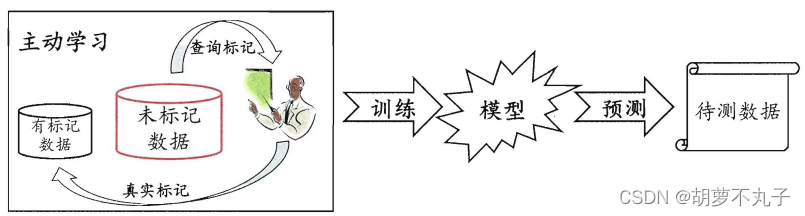
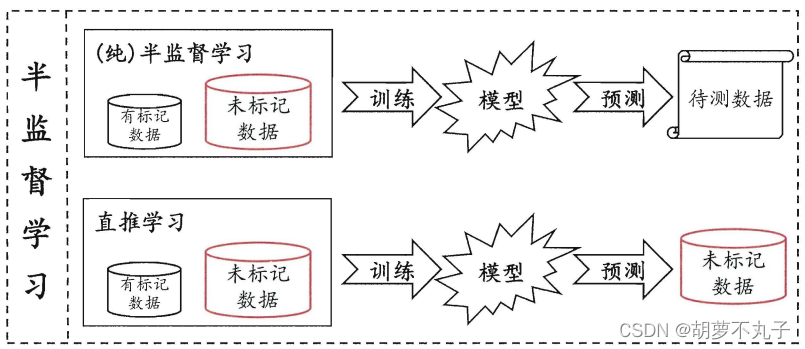
半监督又分为纯半监督学习和直推学习:
① 纯半监督学习: 预测的数据是训练集之外的为观测数据
② 直推学习: 预测的数据是训练集中的未标记数据
共同点: 它们都是利用少量的标注样本和大量的未标注样本进行训练和分类的问题
自学习(半监督学习的典例):
输入:有标签数据 { x , y },无标签数据 { x },距离函数 d ()
1、初始化:L= { x , y },U= { x }
2、重复(U 不为空):
3、使用有标签数据 L 训练 f(监督学习)
4、应用f到无标签数据 U 中,并取出部分数据加入有标签数据集 L
3、试述真正例率(TPR)、假正例率(FPR)与查准率(P)、查全率(R)的联系
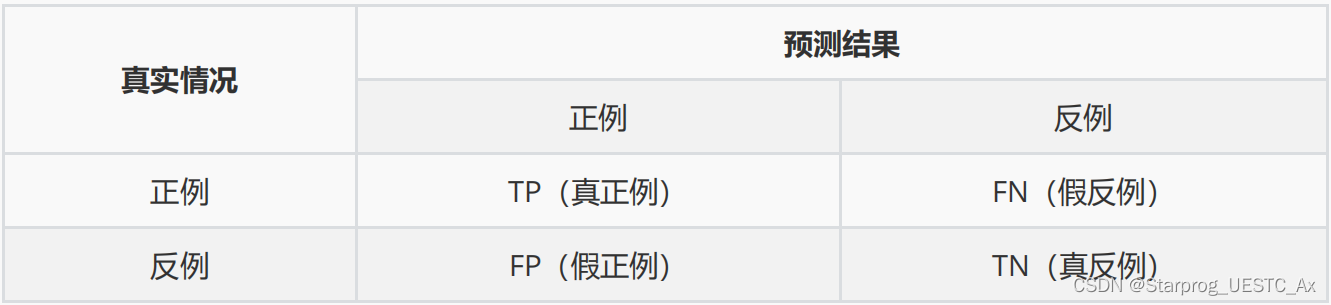

查全率: 真实正例被预测为正例的比例
真正例率: 真实正例被预测为正例的比例
显然,查全率 = 真正例率
查准率: 预测为正例的实例中真实正例的比例
假正例率: 真实反例被预测为正例的比例
两者并没有直接的数值关系
4、PR 曲线怎么得到
说明: 由 PR 曲线引出 F1-score 指标,度量来平衡查准率 P 和查全率 R,在第 8 个考点中有提及
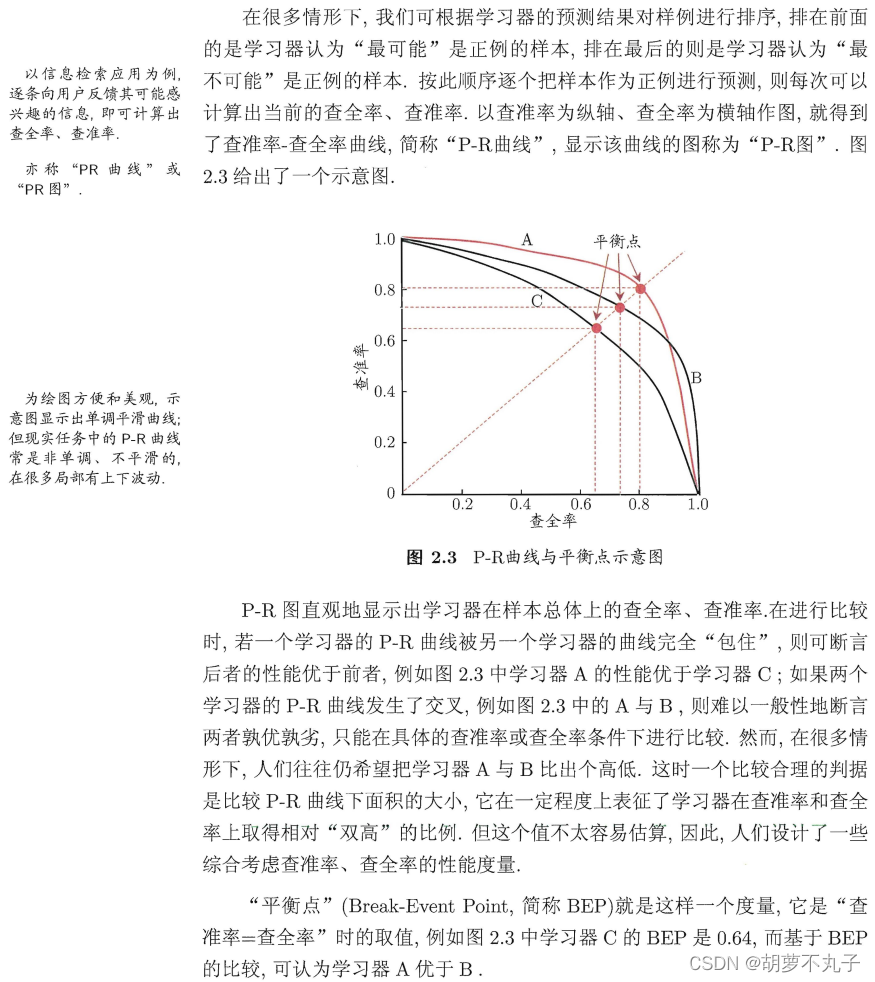
5、怎么得到 ROC 曲线,并试述与错误率之间的关系
ROC 曲线的纵坐标和横坐标分别为真正例率和假正例率(图摘自知乎):

根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算引出两个重要量的值,分别以它们为横纵坐标作图,就得到了 “ ROC曲线 ”
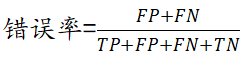
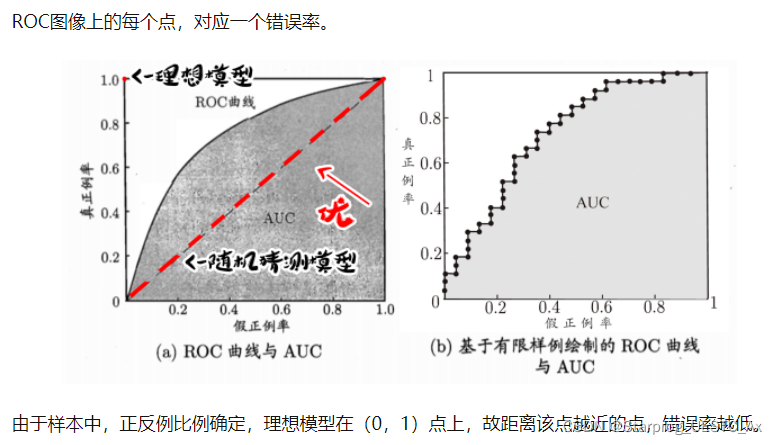
6、神经网络中激活函数有哪些?它们的作用是什么?它们的函数图像是怎样的,有什么优缺点?
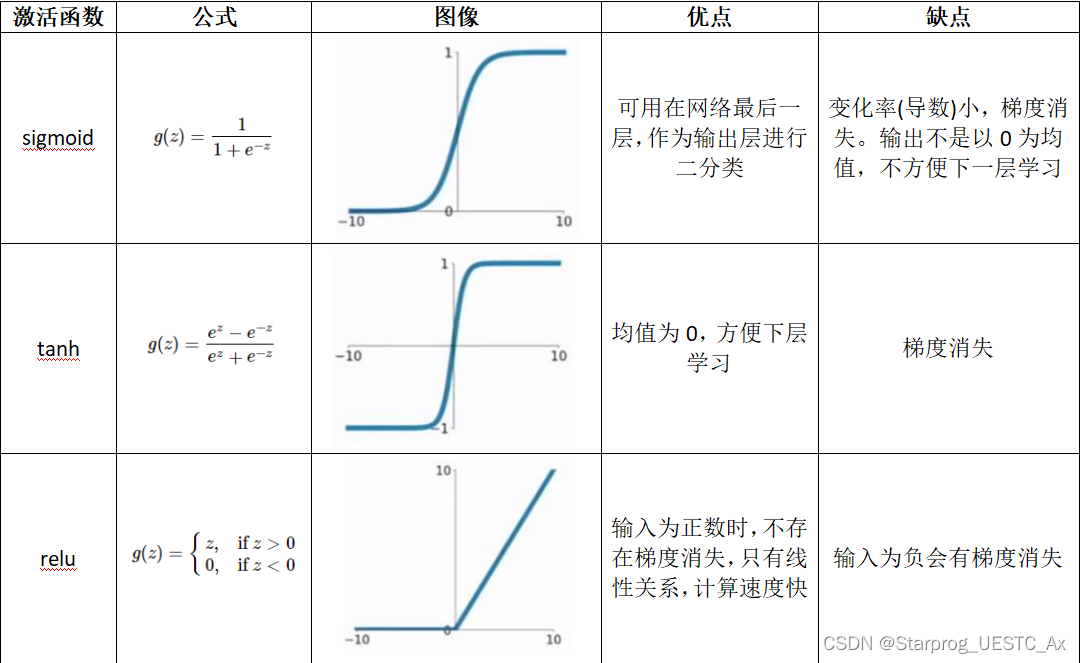
7、分类和回归之间的联系、区别以及对应的算法
回归: 通常是预测一个值,是对真实值的一种逼近预测
分类: 给事务打上一个标签,通常结果为离散值,正确结果只有一个没有逼近的概念
以下是它们之间的联系、区别和对应的算法:
关于上边提到的几种回归的补充说明:

8、分类和回归问题的相关指标
① 分类指标
1、准确率(Accuracy): 表示正确分类的测试实例的个数占测试实例总数的比例,计算公式为:
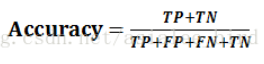
2、精确率(Precision): 也叫查准率,表示正确分类的正例个数占分类为正例的实例个数的比例,计算公式为:
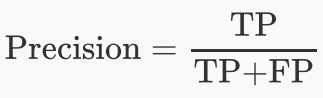
3、召回率(Recall): 也叫查全率,表示正确分类的正例个数占实际正例个数的比例,计算公式为:

4、F1-score : 基于召回率(Recall)与精确率(Precision)的调和平均,即将召回率和精确率综合起来评价,计算公式为【更接近于两个数较小的那个,所以精确率和召回率接近时, 值最大,很多推荐系统的评测指标就是用F值的】:
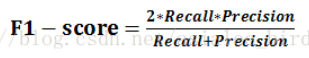


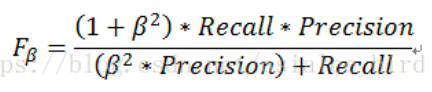
② 回归指标
1、平均绝对值误差(MAE): 表示预测值和观测值之间绝对误差的平均值
2、均方误差(MSE): 表示参数估计值与参数真值之差平方的期望值
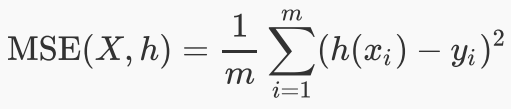
3、均方根误差(RMSE): 表示预测值和观测值之间差异的样本标准差。均方根误差为了说明样本的离散程度。做非线性拟合时,RMSE越小越好
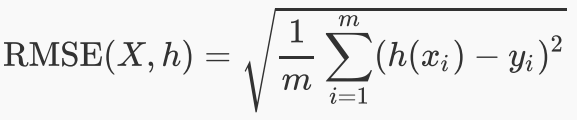
9、线性回归、逻辑回归有什么区别,各自的损失函数表达式是怎样的?

10、链式法则
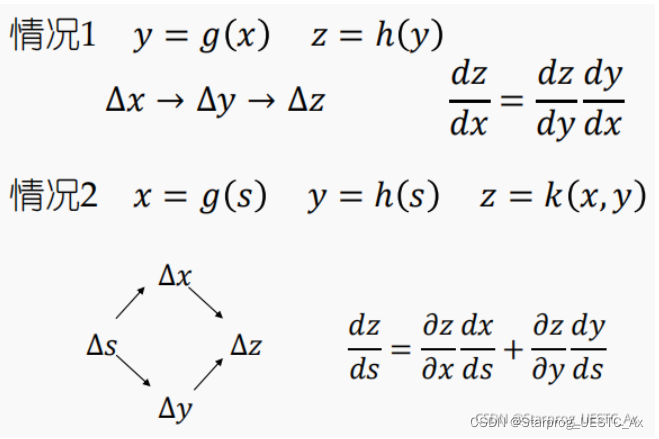
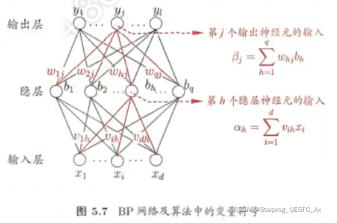
11、BP 算法例题
① 对于下图中的 vih,试推导出 BP 算法中的更新公式【摘自博客】
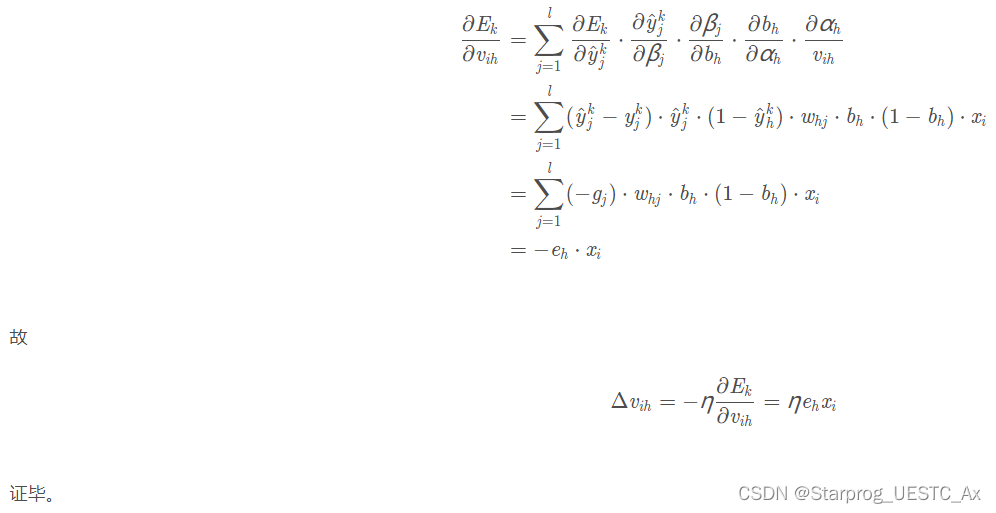
② 试设计一个算法,能通过动态调整学习率显著提升收敛速度,编程实现该算法,并选择两个 UCI 数据集与标准的 BP 算法进行实验比较,点击此处查看答案
12、神经元激活函数例题
试述将线性函数 f(x)=wTx 用作神经元激活函数的缺陷(来源于简书)

13、偏差、方差的定义以及出现偏差和方差的情况
偏差: 度量了学习算法预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
高偏差(欠拟合): 训练误差和验证误差十分接近,但很大
应对方法: 引入更多相关特征;采用多项式特征;减弱正则化
方差 度量了同样大小训练集的变动所导致的学习性能的变化。即刻画了数据扰动所造成的影响
高方差(过拟合): 训练误差较小,验证误差较大
应对方法: 增加训练样本;去除非主要特征;加强正则化
一般训练趋势:高偏差->高方差
模型复杂度并非越高越好,可能复杂度变高,效果反而更差
14、K-means 算法的实现和例题

试析 K 均值算法能否找到最小化式 (9.24) 的最优解(给定数据集):
K 均值算法的运行结果依赖于初始选择的聚类中心,找到的结果是局部最优解,未必是全局最优解
参考西瓜书 P203,数据集不会太大:

15、集成算法的流程以及优缺点
集成算法通过构建并结合多个学习器来提升性能,提高泛化能力
个体学习器越多,越精确,差异越大,集成越好,但随着个体增多,需要更大的计算开销和存储开销,并且个体学习的差异更难获得。有数据不平衡问题,会导致精度下降
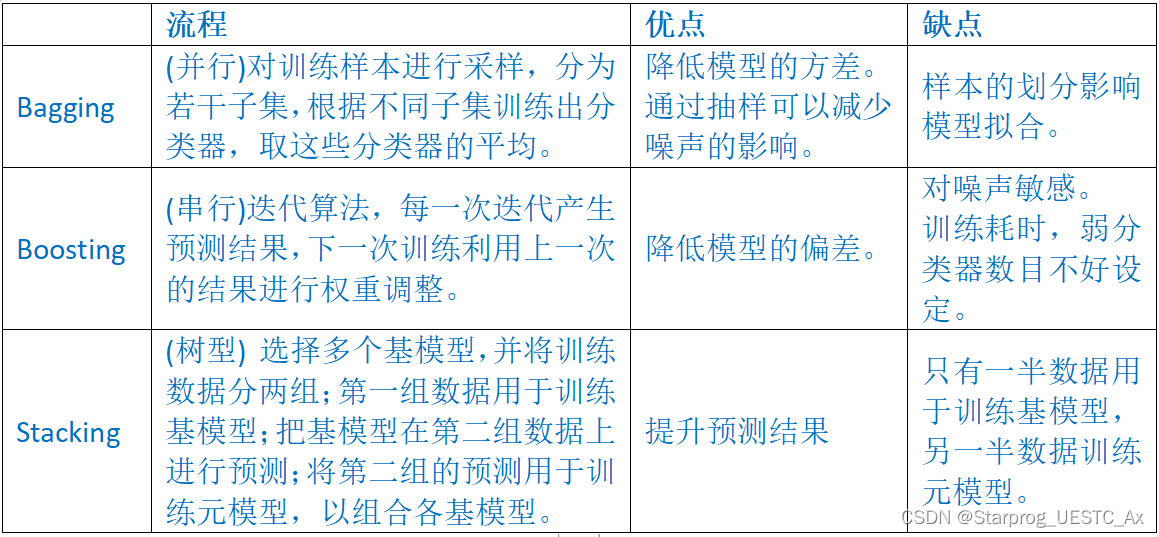
Bagging 算法:(多个学习器并行):
输入:训练样本D,弱学习算法,迭代次数T
过程:
For t=1,…,T:
对训练集进行随机采样,得到采样集 Dt
用 Dt 训练第 t 个学习器 Ct(x)
若是分类,则选取投票数最多的为结果;若为回归,则设置算术平均数

Boosting 流程(串行,将弱学习器提升为强学习器):
先从初始训练集训练一个基学习器
再根据基学习器的表现对训练样本分布进行调整
然后基于调整后的样本分布来训练下一个基学习器
直到学习器数目达到事前制定的数目 T
最终将 T 个基学习器进行加权结合
Boosting 族算法最著名的代表是 AdaBoost,AdaBoost 流程(注重分类错误的样本,重视准确率高的学习器)如下:

Stacking 算法:

16、基于分歧的半监督方法
协同训练

利用多视图的 “ 相容互补性 ”
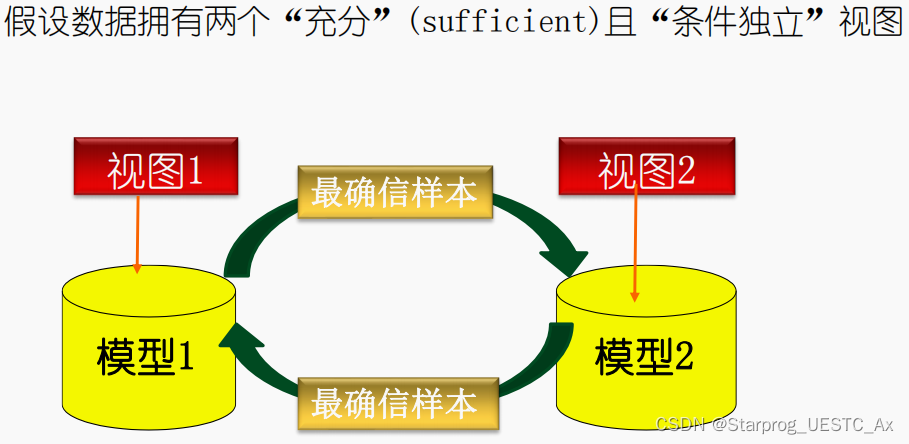

协同训练算法

协同训练实现

多视图的分歧方法改进

17、SVM
① SVM 原理

② SVM 中的 SMO 算法的思路以及约束条件
SMO 算法即序列最小优化算法(Sequential Minimal Optimization)
思路: 每次只优化两个变量,将其余变量视为常数,将一个复杂的优化算法转化为较简单的两变量优化问题

③ 例题
例一【来源于李航《统计学习方法》】
(a) 解法一

(b) 解法二

例二【来自于张栗粽老师 PPT】
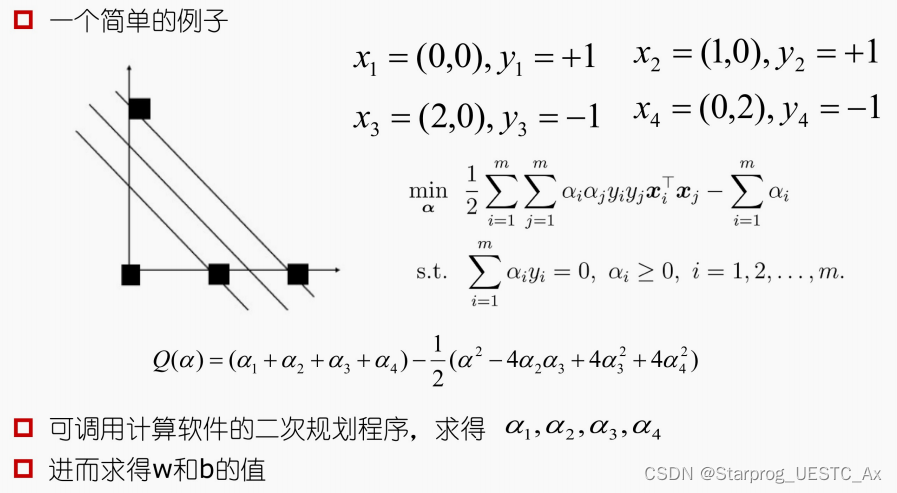
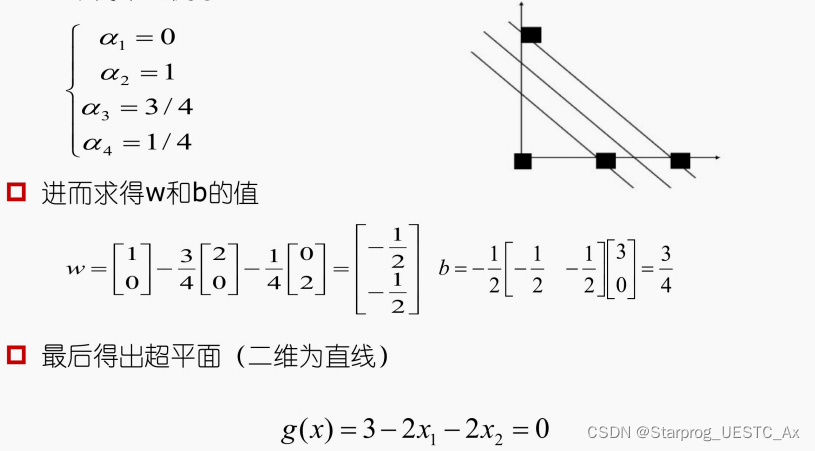
这种方法好多同学也是真没算出来,下边是我的解法,线性规划对简单的计算还是很香的:
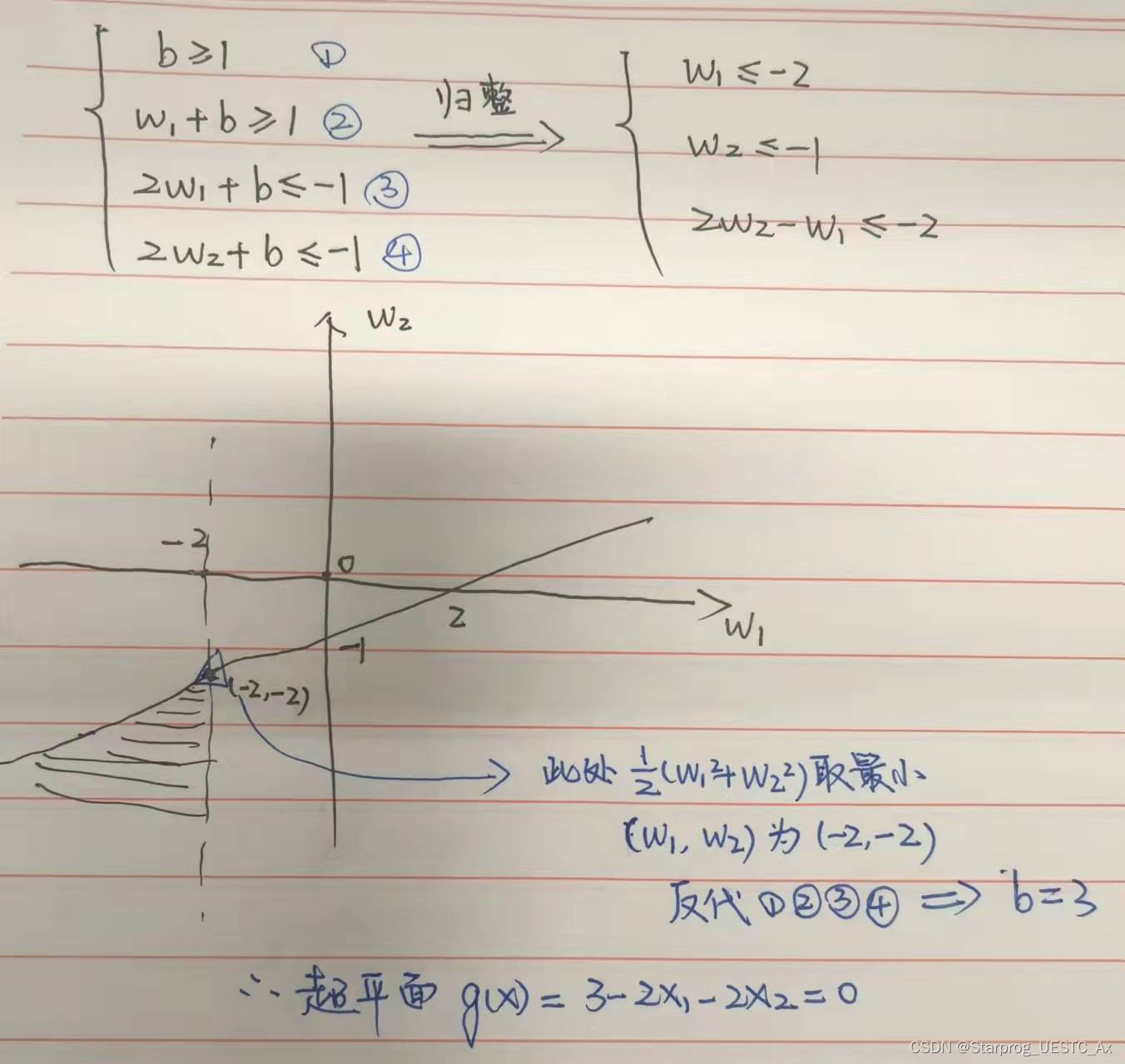
例三【证明题】

18、Adaboost
例题【来源于李航《统计学习方法》】



文章出处登录后可见!