导读
深度学习中模型的计算图可以被分为两种,静态图和动态图,这两种模型的计算图各有优劣。
静态图需要我们先定义好网络的结构,然后再进行计算,所以静态图的计算速度快,但是debug比较的困难,因为只有当给计算图输入数据之后模型的参数才会有值。
而动态图则是边运行边构建,动态图的优点在于可以在搭建网络的时候看见变量的值便于检查,缺点就是前向计算不方便优化,因为不知道下一步计算是做什么。
针对于这两种不同的计算图,paddlepladdle提供了多种不同的方式来保存和加载
模型保存和加载
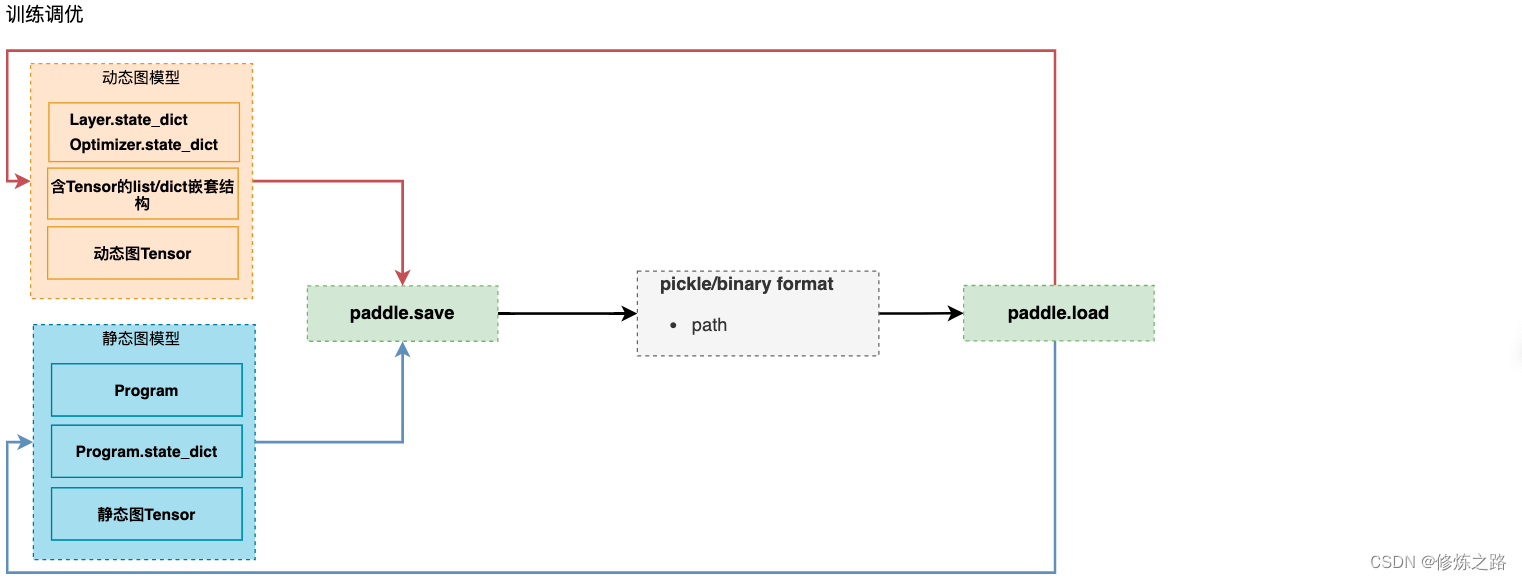
- paddle.save:模型参数和超参的保存,支持
动态图和静态图 - paddle.load:模型参数和超参的加载,支持
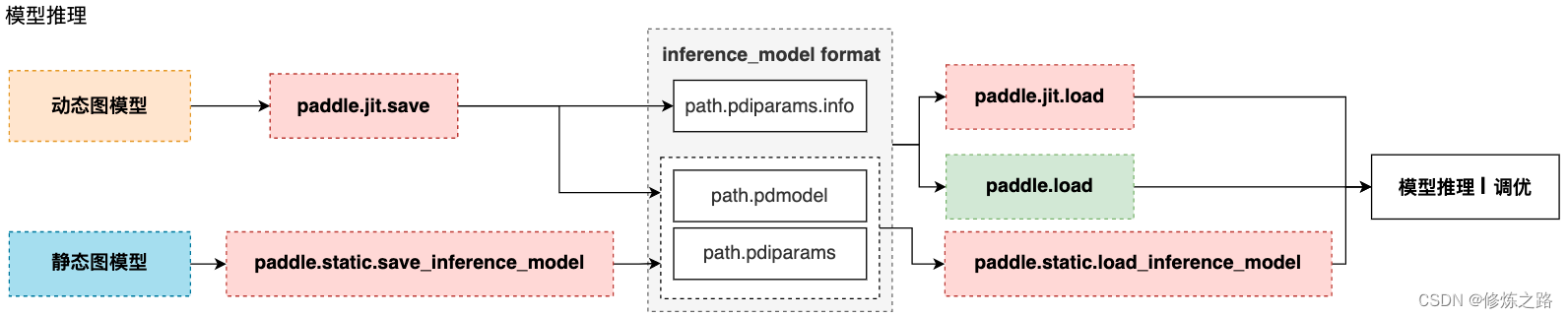
动态图和静态图 - paddle.jit.save:
动态图模型参数和结构的保存 - paddle.jit.load:
动态图模型参数和结构的加载 - paddle.static.save_inference_model:
静态图模型参数和结构的保存 - paddle.static.load_inference_model:
静态图模型参数和结构的加载
除此之外,paddlepaddle还提供了动态图转静态图来训练和保存模型,用来加快模型的训练效率。
模型参数的保存和加载
- 模型训练
定义一个线程的二元一次方程,通过随机生成一些输入数据来计算输出,来训练模型
import paddle
import numpy as np
from paddle import optimizer,nn
np.random.seed(28)
#设置样本的数量
num_samples = 1000
#模型训练的超参数设置
epoch = 10
batch_size = 512
class_num = 1
input_size = 2
learing_rate = 0.01
class LinearData(paddle.io.Dataset):
def __init__(self,num_samples,input_size):
super(LinearData, self).__init__()
self._num_samples = num_samples
# 生成一个线性方程的数据
# 设置线程方程的w和b
w = np.random.rand(input_size)
b = np.random.rand()
#随机生成输入数据,根据线程方程的参数来生成输出
self._x = np.random.rand(num_samples,2).astype("float32")
self._y = np.sum(w * self._x,axis=1) + b
self._y = self._y.reshape(-1,class_num).astype("float32")
def __getitem__(self, idx):
return self._x[idx],self._y[idx]
def __len__(self):
return self._num_samples
#构建模型
class SimpleNet(nn.Layer):
def __init__(self,input_size,num_classes=class_num):
super(SimpleNet, self).__init__()
self._linear = nn.Linear(input_size,class_num)
def forward(self, x):
output = self._linear(x)
return output
def train(data_loader,model,loss_fn,opt):
#开始训练模型
for epoch_idx in range(epoch):
for batch_idx,batch_data in enumerate(data_loader):
batch_x, batch_y = batch_data
pred_batch_y = model(batch_x)
#计算Loss
batch_loss = loss_fn(pred_batch_y,batch_y)
#更新参数
batch_loss.backward()
opt.step()
opt.clear_grad()
#打印日志
print("epoch:{},batch idx:{},loss:{:.4f}".format(epoch_idx,batch_idx
,np.mean(batch_loss.numpy())))
#加载数据集
dataset = LinearData(num_samples,input_size)
data_loader = paddle.io.DataLoader(dataset,shuffle=True,batch_size=batch_size)
#初始化模型
model = SimpleNet(input_size,class_num)
#定义loss函数
loss_fn = paddle.nn.loss.MSELoss()
#优化器设置
opt = paddle.optimizer.sgd.SGD(learning_rate=learing_rate,
parameters=model.parameters())
#训练模型
train(data_loader,model,loss_fn,opt)
- 动态图的参数保存
通过paddle.save函数来保存模型的参数和优化器的参数
#保存模型的参数
paddle.save(model.state_dict(),"model.pdparams")
#保存优化器的参数
paddle.save(opt.state_dict(),"opt.pdparams")
- 参数的加载
通过paddle.load来从磁盘中加载模型和优化器的参数
#加载模型的参数
model.set_state_dict(paddle.load("model.pdparams"))
#加载优化器的参数
opt.set_state_dict(paddle.load("opt.pdparams"))
静态图模型参数和结构的保存
- 构建一个静态图模型
构建了一个简单的静态图模型,只包含了输入和输出
import paddle
#开启静态图模型
paddle.enable_static()
#设置静态图模型的输入
input = paddle.static.data(name="input",shape=[None,10],dtype="float32")
#设置模型的输出
output = paddle.static.nn.fc(input,2)
#将模型放在CPU上执行
place = paddle.CPUPlace()
#静态图的执行器
exe = paddle.static.Executor(place)
#获取到静态图模型并且运行
exe.run(paddle.static.default_startup_program())
- 保存静态图的模型和参数
prog = paddle.static.default_startup_program()
#保存静态图的参数
paddle.save(prog.state_dict(),"static.pdparams")
#保存静态图的模型
paddle.save(prog,"static.pdmodel")
- 静态图模型的加载和初始化
#加载静态图的模型
prog = paddle.load("static.pdmodel")
#加载模型的参数
params = paddle.load("static.pdparams")
#初始化模型的参数
prog.set_state_dict(params)
动态图转静态图的模型保存和加载
为了便于构建模型和调试,我们通常会选择动态图的方式来构建模型,如果想要加快模型的训练效率以及方便在训练完成之后保存模型的结构,这时候我们可以将动态图转换成为静态图来解决这两个问题。
针对这种情况paddlepaddle提供了两种方式来实现:
- 先将动态图转换成为静态图模型进行训练,然后再保存
- 采用动态图进行训练,训练完成之后再保存模型
- 动态图转静态图进行训练
这种方法的优点就是通过将动态图转换为静态图进行训练,可以提升模型的训练效率,缺点就是不方便调试
paddle提供了一种比较简单的方法,只需要通过paddle.jit.to_static来装饰forward方法即可,非常简单
#构建模型
class SimpleNet(nn.Layer):
def __init__(self,input_size,num_classes=class_num):
super(SimpleNet, self).__init__()
self._linear = nn.Linear(input_size,num_classes)
@paddle.jit.to_static
def forward(self, x):
output = self._linear(x)
return output
然后保存模型的时候使用paddle.jit.save方法即可
paddle.jit.save(model,"model")
保存成功之后会生成三个文件model.pdiparams、model.pdiparams.info、model.pdmodel,如果使用paddle.jit.to_static装饰了多个forward方法,则会生成多个模型文件。
如果想要让保存的模型能够支持动态输入,只需要指定InputSepc参数即可
from paddle.static import InputSpec
#构建模型
class SimpleNet(nn.Layer):
def __init__(self,input_size,num_classes=class_num):
super(SimpleNet, self).__init__()
self._linear = nn.Linear(input_size,num_classes)
@paddle.jit.to_static(input_spec=[InputSpec(shape=[None, input_size], dtype='float32')])
def forward(self, x):
output = self._linear(x)
return output
模型的加载和预测
#加载模型
model = paddle.jit.load("model")
#输出模型参数
print(model.state_dict())
#构建一个模型的输入数据
input_array = np.array([[1,2],[3,4],[5,6]],dtype=np.float32)
inputs = paddle.to_tensor(input_array,place=paddle.CUDAPlace(0),stop_gradient=False,dtype=paddle.float32)
print(inputs)
#模型预测
predit = model(inputs)
print(predit)
- 动态图训练保存模型
相比于动态图转静态图进行训练而言,我们不需要给模型添加装饰方法,只需要使用paddle.jit.save来保存模型即可,在保存模型的时候只需要指定一下模型输入的shape即可
paddle.jit.save(model,"model",input_spec=[InputSpec(shape=[None,input_size],dtype="float32")])
注意:在使用Layer构建模型的时候,不要把loss的计算写到forward方法中
文章出处登录后可见!
已经登录?立即刷新