
知识图谱是一种用图模型来描述知识和建模世界万物之间关联关系的大规模语义网络,是大数据时代知识表示的重要方式之一。近年来,知识图谱在辅助语义搜索、支持智能问答、增强推荐计算、提升语言语义理解和大数据分析能力等越来越多的技术领域得到重视,高效知识图谱构建技术应运而生。
DeepKE是一个开源可扩展的知识图谱抽取工具,可实现命名实体识别、关系抽取和属性抽取三大知识抽取任务,并支持复杂的应用场景,如低资源少样本和文档篇章级抽取场景:
· EMNLP 2022 Demo论文链接:https://arxiv.org/abs/2201.03335
· 在线demo链接:http://deepke.openkg.cn
· Github 链接:https://github.com/zjunlp/DeepKE
· Gitee 链接:https://gitee.com/openkg/deepke
· OpenKG链接:http://openkg.cn/tool/deepke

GitHub主页

Demo演示系统
为支持更多知识图谱构建场景和满足日益增长的用户需求,DeepKE于近期发布更新:
1.新增多模态抽取场景,支持结合图片增强的实体、关系抽取;
2.开源开放支持cnSchema的开箱即用实体和关系抽取模型DeepKE-cnSchema (NER)和DeepKE-cnSchema (RE);
3.增加低资源关系抽取数据增强功能(支持中英双语),支持BiLSTM+CRF实体识别等模型。
4.增加实体识别、关系抽取数据(支持中英双语)标注说明,支持弱监督实体、关系数据标注功能,修复若干bug。
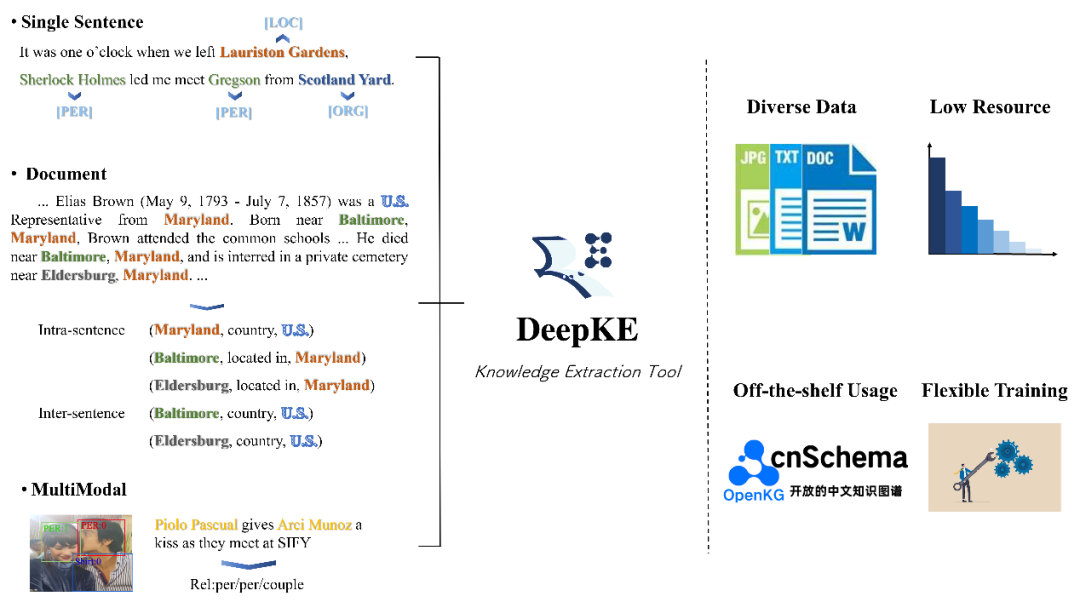
目前,DeepKE已支持单句/多句篇章、多模态、低资源等复杂知识图谱构建场景,包括实体、关系和属性抽取任务,支持多种格式和不同大小的数据规模,并提供开箱即用的实体关系抽取模型,用户可灵活地进行训练、预测和自动调参,并自定义数据集和参数。下面具体介绍更新的内容。
一、多模态
DeepKE新增多模态实体和关系抽取。与文本相关的丰富的图像信号可以起到增强上下文的作用,有助于复杂情境的知识抽取。DeepKE 提供了一个简单的基于Transformer 和前缀(Prefix)注意力增强的多模态实体关系抽取模型 IFAformer 模型。
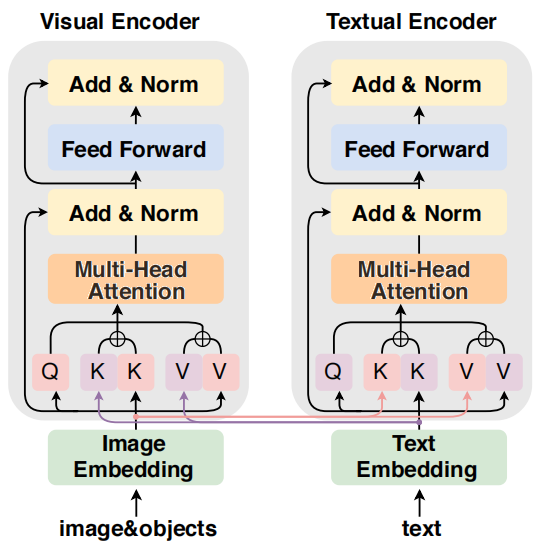
如图所示,IFAformer在每一个Transformer层同时拼接上下文和视觉特征的多头注意力键值,它们可以隐式地对齐文本和相关图像中物体的特征。IFAformer效果如下表所示(因为无合适公开的多模态中文抽取数据集,我们汇报了两个英文数据集的抽取性能):

用户可以使用自定义的图片(包含图片中的目标)和文本训练自定义多模态知识抽取模型,以多模态关系抽取为例,基本用法如下:
1.安装环境
>> git clone https://github.com/zjunlp/DeepKE.git
>> pip install deepke
>> cd example/re/multimodal
2.下载数据集
>> wget 120.27.214.45/Data/re/multimodal/data.tar.gz
>> tar -xzvf data.tar.gz
3.训练
修改conf下的yaml配置文件自定义参数
>> python run.py
4.预测
修改predict.yaml中的load_path为训练好的模型,同时DeepKE提供已经在MNRE数据集上训练好的模型用于直接预测
>> python predict.py
具体可参考GitHub中对应目录下的README详细使用说明。
二、支持cnSchema的开箱即用模型
DeepKE提供已经训练好的支持cnSchema的开箱即用的抽取模型DeepKE-cnSchema(NER)和DeepKE-cnSchema(RE),该模型支持50 种不同的关系类型以及 28 种不同的实体类型,每一种类型都以相应的唯一ID 进行映射,其中实体类型包含了通用的人物、地点、城市、机构等类型,关系类型包括了常见的祖籍、出生地、国籍、朝代等类型。模型抽取的效果如下表所示(未经过调参):
模型 | 准确率 | 召回率 | F1 |
DeepKE-cnSchema(NER) | 0.80 | 0.86 | 0.83 |
DeepKE-cnSchema(RE) | 0.87 | 0.86 | 0.87 |
用户在实际使用时进入GitHub仓库对应任务场景的example目录下,直接下载已经训练好的模型如DeepKE-cnSchema(NER / RE),修改相关配置参数,运行predict.py文件即可进行预测。DeepKE提供了基于cnSchema的实体抽取、关系抽取和联合三元组抽取,以关系抽取为例,基本用法如下:
1.安装环境
>> git clone https://github.com/zjunlp/DeepKE.git
>> pip install deepke
>> cd example/re/standard
2.下载DeepKE-chSchema (RE)
3. 修改 predict.yaml中的参数fp为下载的模型路径,embedding.yaml中num_relations为51(关系个数),config.yaml中的参数model为lm
4.进行预测
>> python predict.py
需要预测的文本及实体对通过终端输入给程序。
具体的使用方式可参考 Github README中的详细介绍。本次版本支持的模型由互联网语料文本训练得到,直接使用到其他领域(不可避免)会存在跨领域泛化问题导致性能下降,这里建议用户收集并标注领域数据重新模型已实现最优性能,敬请谅解。
三、小结和展望
新版本的DeepKE支持低资源、长篇章、多模态和cnSchema的知识抽取工具,支持实体识别、关系抽取和属性抽取任务。我们同时也开发了一个在线demo展示系统,欢迎各位小伙伴提出意见建议(Issue)和支持(PR)。在今后我们还将继续开发和丰富模型(中文模型),支持更多的功能如低资源事件抽取、终身知识抽取,使得DeepKE可以满足更多的知识图谱应用需求。
[1]Zhang, Ningyu, et al. Deepke: A deep learning based knowledge extraction toolkit for knowledge base population[C]. EMNLP 2022 System Demonstration.
[2]Lu D, Neves L, Carvalho V, et al. Visual attention model for name tagging in multimodal social media[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 1990-1999.
[3]Zhang Q, Fu J, Liu X, et al. Adaptive co-attention network for named entity recognition in tweets[C]. Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
[4]Lu J, Batra D, Parikh D, et al. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[J]. Advances in Neural Information Processing Systems, 2019, 32.
[5]UMT: Yu J, Jiang J, Yang L, et al. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer[C]. Association for Computational Linguistics, 2020.
[6]MNRE: Zheng C, Wu Z, Feng J, et al. MNRE: A Challenge Multimodal Dataset for Neural Relation Extraction with Visual Evidence in Social Media Posts[C]. 2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2021: 1-6.
[7]Zheng C, Feng J, Fu Z, et al. Multimodal relation extraction with efficient graph alignment[C]. Proceedings of the 29th ACM International Conference on Multimedia. 2021: 5298-5306.
[8]Xu B, Huang S, Sha C, et al. MAF: A General Matching and Alignment Framework for Multimodal Named Entity Recognition[C]. Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining. 2022: 1215-1223.
[9]Zhang, N., Deng, S., Sun, Z., et al. Attention-Based Capsule Networks with Dynamic Routing for Relation Extraction[C]. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018: 986-992.
[10]Zhang, Ningyu, et al. Long-tail Relation Extraction via Knowledge Graph Embeddings and Graph Convolution Networks[C]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).
[11]Zhang N, Chen X, Xie X, et al. Document-level relation extraction as semantic segmentation[C]. Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence 2021.
[12]Chen, Xiang, et al. Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction[C]. Proceedings of the ACM Web Conference 2022.
[13]Chen X, Zhang N, Li L, et al. Good Visual Guidance Makes A Better Extractor: Hierarchical Visual Prefix for Multimodal Entity and Relation Extraction[C]. NAACL Findings 2022.
[14]Chen X, Zhang N, Li L, et al. Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion[C]. SIGIR 2022.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
文章出处登录后可见!