 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。 如果文章对你有帮助,欢迎
如果文章对你有帮助,欢迎
关注、
点赞、
命名实体识别的背景
命名实体识别(Named Entity Recognition, 简称NER)(也称为实体识别、实体分块和实体提取)是信息提取的一个子任务,旨在将文本中的命名实体定位并分类为预先定义的类别,如人员、组织、位置、时间表达式、数量、货币值、百分比等。命名实体识别是自然语言处理中的热点研究方向之一, 目的是识别文本中的命名实体并将其归纳到相应的实体类型中。
命名实体识别是NLP中一项非常基础的任务,是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具。
从自然语言处理的流程来看,NER可以看作词法分析中未登录词识别的一种,是未登录词中数量最多、识别难度最大、对分词效果影响最大问题。同时NER也是关系抽取、事件抽取、知识图谱、机器翻译、问答系统等诸多NLP任务的基础。
命名实体识别的方法
从模型的层面,可以分为基于规则的方法、无监督学习方法、有监督学习方法,从输入的层面,可以分为基于字(character-level)的方法、基于词(work-level)的方法、两者结合的方法。
基于规则的方法:依赖人工制定的规则,规则的设计一般基于句法、语法、词汇的模式,以及特定领域的知识。当词典的大小有限时,基于规则的方法可以达到很好的效果。这种方法通常具有高精确率和低召回率的特点。但是这种方法无法难以迁移到别的领域,对于新的领域需要重新制定规则。
无监督学习方法:利用语义相似性进行聚类,从聚类得到的组当中抽取命名实体,通过统计数据推断实体类别。
基于特征的监督学习方法:可以表示为多分类任务或者序列标注任务,从数据中学习。
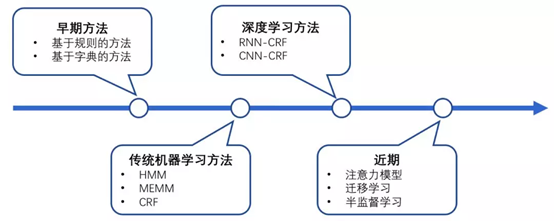
图1 NER识别算法发展历程
下面介绍几种常见的命名实体识别算法:
BiLSTM-CRF算法
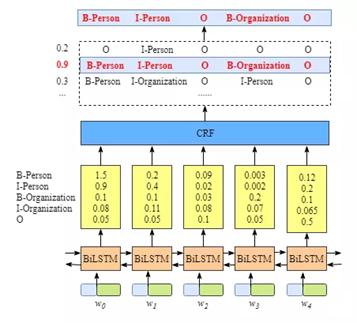
图2 BiLSTM-CRF结构图
论文名称:Neural Architectures for Named Entity Recognition
论文链接:https://arxiv.org/pdf/1603.01360.pdf
应用于NER中的BiLSTM-CRF模型主要由Embedding层(主要有词向量,字向量以及一些额外特征),双向LSTM层,以及最后的CRF层构成。实验结果表明BiLSTM-CRF已经达到或者超过了基于丰富特征的CRF模型,成为目前基于深度学习的NER方法中的最主流模型。在特征方面,该模型继承了深度学习方法的优势,无需特征工程,使用词向量以及字符向量就可以达到很好的效果,如果有高质量的词典特征,能够进一步获得提高。
如果读者想要更进一步了解BiLSTM-CRF算法,可以转到之前笔者写的《深入浅出讲解BiLSTM-CRF》文章进一步阅读。
IDCNN-CRF算法
论文名称:Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
论文链接:https://arxiv.org/abs/1702.02098
论文提出在NER任务中,引入膨胀卷积,一方面可以引入CNN并行计算的优势,提高训练和预测时的速度;另一方面,可以减轻CNN在长序列输入上特征提取能力弱的劣势。具体使用时,dilated width会随着层数的增加而指数增加。这样随着层数的增加,参数数量是线性增加的,而感受野却是指数增加的,这样就可以很快覆盖到全部的输入数据。IDCNN对输入句子的每一个字生成一个logits,这里就和BiLSTM模型输出logits之后完全一样,再放入CRF Layer解码出标注结果。
Bert算法
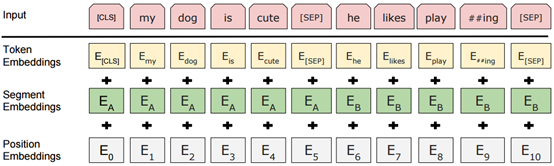
图3 Bert算法的结构图
Bert(Bidirectional Encoder Representations from Transformers)算法,顾名思义,是基于Transformer算法的双向编码表征算法,Transformer算法基于多头注意力(Multi-Head attention)机制,而Bert又堆叠了多个Transfromer模型,并通过调节所有层中的双向Transformer来预先训练双向深度表示,而且,预训练的Bert模型可以通过一个额外的输出层来进行微调,适用性更广,而不需要做更多重复性的模型训练工作。
Bert算法的论文:https://arxiv.org/abs/1810.04805
Bert算法的开源代码:https://github.com/google-research/bert
读者如果想进一步了解Bert算法,可以前往笔者之前写的《深入浅出讲解Bert算法》进一步阅读。
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!
文章出处登录后可见!