1.论文作者介绍
(1)Jeff Dean:天才程序员,谷歌搜索索引技术的幕后大脑(编译器不警告Jeff Dean,Jeff Dean警告编译器)谷歌大规模分布式计算系统的设计师,例如:站点爬行,索引与搜索,在线广告,MapReduce,BigTable 以及 Spanner(分布式数据库)。
(2)Geoffrey Hinton:人工智能领域三巨头之一(在人工智能研究领域,Yann LeCun、Geoffrey Hinton 和 Yoshua Bengio一直被公认为深度学习三巨头。)直至目前一直在 Google Brain 中担任要职。在他的带领下,谷歌的图像识别和安卓系统音频识别的性能得到大幅度提升。他将神经网络带入到研究与应用的热潮,将“深度学习”从边缘课题变成了谷歌等互联网巨头仰赖的核心技术,并将反向传播算法应用到神经网络与深度学习。
(3)Oriol Vinyals几乎可以和人工智能画上等号了,此前在GoogleBrain工作时,机器学习、神经网络、强化学习领域都有他提出的新式研究方法。而现在。
2.论文地址
https://arxiv.org/pdf/1503.02531.pdf
3.什么是知识蒸馏
训练复杂表达能力更强的模型,并且很容易从中提取出结构,这个复杂的模 型可以是独自训练出来的,也可以是通过如dropout正则化之后的单个大模型。将训练 完毕之后的大模型使用一种不同的训练方式,将知识从该复杂的大模型(teacher model) 中转移容易部署的小模型(student model)上,这个过程称之为“知识蒸馏”。
4.为什么要提出知识蒸馏
为了能表达更加丰富的内容,我们需要更加复杂的模型,并且需要更大的数据集和算力从中提取特征。在前面的所有讲述图片分类的论文中都提到,模型越复杂,提取的特征也就越多,模型的表达能力也就更强,预测结果也就越准确,但是同时也需要更大的算力和资源;并且训练的大模型很难部署到边缘设备上,所以需要更加轻量化并且表达能力也强的模型。但是有研究表示,将集成模型中的知识压缩到易于部署到单个模型是有可能的,该论文使用不同的技术进一步发展这种方法。
5.知识蒸馏中Teacher model和Student model
Teacher model(教师模型)作为知识的输出者;Student model(学生模型)作为知识的吸收着。
Teacher model(教师模型):是一个比较大和复杂的模型(表达能力更强),或者由多个模型集成而来,最后通过softmax输出相应的类别概率。
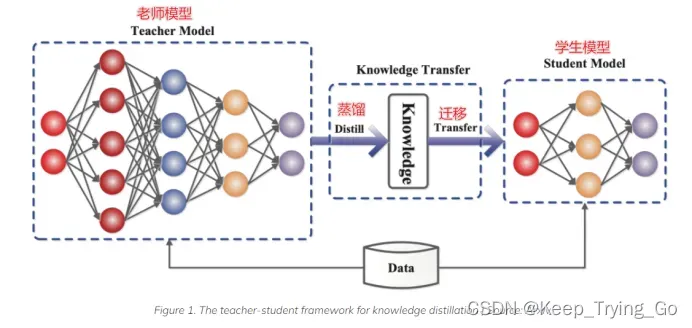
注:由于大的模型是非常臃肿的,导致在边缘设备,像手机,终端,手表等边缘设备算力是非常受限的,所以需要一个更加轻量化的模型来实现和部署。
https://neptune.ai/blog/knowledge-distillation
Student model(学生模型):参数量少,模型结构比较简单(表达能力较弱),最后通过softmax输出相应的类别概率。
正是通过Teacher model(泛化能力较强)来distilling训练Student model,最后的Student model泛化能力也表现较强。
https://peerj.com/articles/cs-474/
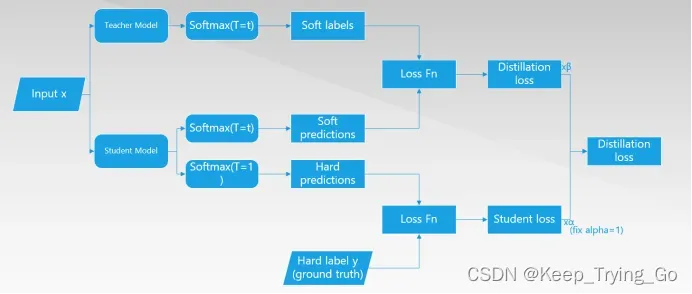
已经训练好的Teacher model和Student model在T相同的清况下,计算他们之间的预测类别损失函数loss1,计算Student model和ground truth(hard label)之间的损失函数loss2;总的损失函数为loss=loss1+loss2.
6.采用soft targets和hard targets
(1)对于传统的hard targets
正确类别的概率为1,错误类别的概率为0,论文中提出,这样做是不合理的,比如一辆宝马车有很小的概率被认为是垃圾车,但是却比错误认为一根胡萝卜的概率大很多,在错误类别上的相对概率可以反映出模型是如何进行泛化的,因为错误类别概率的大小表名了宝马车有多不像垃圾车,有多不像一个胡萝卜,所以传统的hard targets需要进行改进。
(2)Soft targets
有teacher model模型的类别概率作为soft targets,用于训练student model,使用soft targets训练student model,比hard targets能够提供更多的信息并且训练的每一个样本时梯度差异也较小,所以训练student model时的数据比teacher model时的数据要少,泛化出来的模型也比较好。
7.公式解释
神经网络通常使用softmax输出层来生成类概率,该输出层将每一个logits 生成对应的概率:
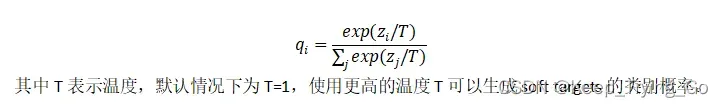
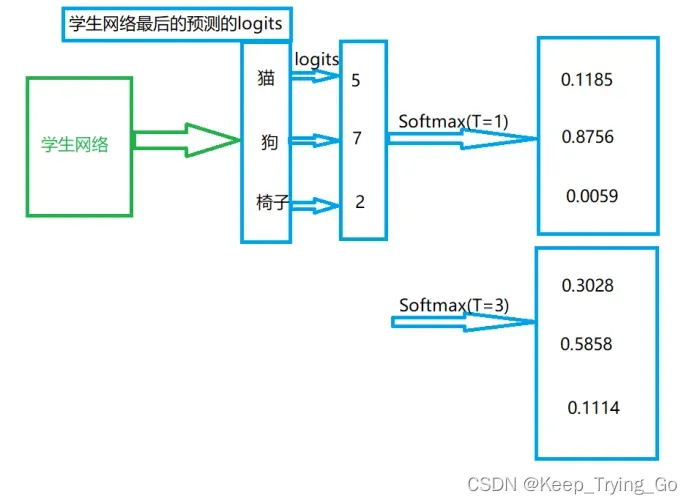
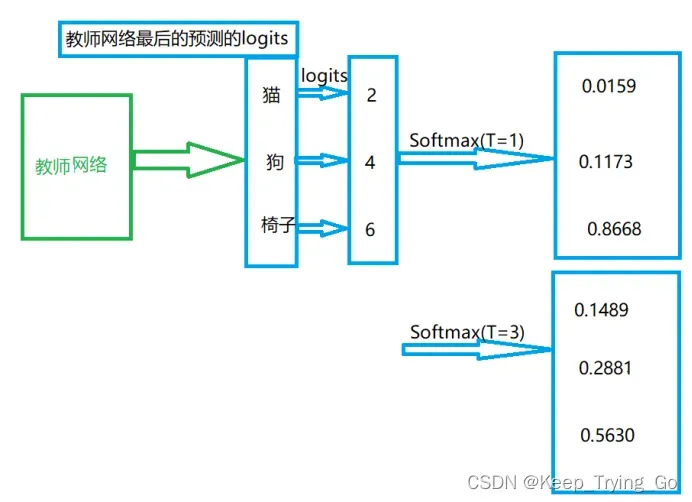


当温度很高的时候,知识蒸馏就等价于均方误差:.但是当温度很高的时候,预测的结果概率就差不多了,达不到想要的结果,所以需要进行平衡。
8.知识蒸馏的应用场景
(1)模型压缩;
(2)优化训练,防止过拟合(潜在的正则化);
(3)无限大,无监督数据集的数据挖掘;
(4)少样本,零样本学习;
迁移学习:将一个领域的模型泛化到另一个领域;
知识蒸馏:把一个模型的知识迁移到另一个模型上(大模型到小模型的迁移);
9.实验过程
(1)在MNIST手写体数字识别数据集上进行了训练
教师网络使用两层隐藏层1200个神经元并且经过Dropout正则化之后,在测试集上预测的结果是67张预测错误;
使用更小的网络(学生网络)并且只有两层隐藏层800个神经元的情况下,预测错误有146张,但是当使用教师网络预测的soft target作为标签进行时,并且温度T=20,最后预测结果为74张预测错误。说明了知识蒸馏对于学生网络是很有效的。
注:当只有两层隐藏层并且只有300个神经元的话,温度可以调到T=8;当只有两层隐藏层并且只有30个神经元的话,温度可以调到T=2.5到4.
(2)零样本学习
当把样本中的所有3去掉之后来训练学生网络,最后的测试错误数206个,其中133个是“3”,但是原样本中有1010个数字“3”,说明剩下的部分“3”是预测正确的,进一步说明了知识蒸馏的效果很不错;但是将“3”的偏置项调高到3.5的话,那么最后有106预测错误,经过学生模型从没有见过“3”。所以当样本中中没有该类别的时候,那么该类别的偏置项就很低(因为从教师模型那里学习到的知识有限)。
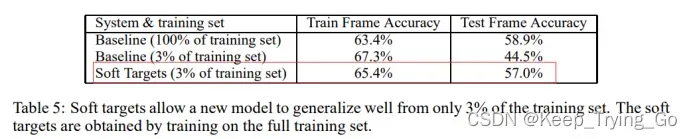
经过使用3%的数据集进行训练,最后的效果很不错,并且没有出现过拟合。
文章出处登录后可见!