内容
- 前言
- 0、导入需要的包
- 1、torch_distributed_zero_first
- 2、init_torch_seeds
- 3、git_describe、date_modified、select_device
- 3.1、git_describe
- 3.2、date_modified
- 3.3、select_device
- 4、intersect_dicts
- 5、time_synchronized
- 6、profile、model_info
- 6.1、profile(没用到)
- 6.2、model_info
- 7、initialize_weights
- 8、find_modules(没用到)
- 9、sparsity、prune
- 9.1、sparsity
- 9.2、prune
- 10、fuse_conv_and_bn
- 11、load_classifier
- 12、scale_img
- 13、de_parallel
- 14、is_parallel、copy_attr、ModelEMA类
- 14.1、is_parallel
- 14.2、copy_attr
- 14.3、class ModelEMA
- 总结
前言
源码:YOLOv5源码.
导航:【YOLOV5-5.x 源码讲解】整体项目文件导航.
注释版全部项目文件已上传至GitHub:yolov5-5.x-annotations.
这个文件主要是基于torch的一些实用工具类,整个项目的文件都可能会用到,并不涉及太多的矩阵操作,大多都是一些torch相关工具的使用。废话不多说,下面开始介绍每个函数。
0、导入需要的包
import datetime # 时间模块 基于time进行了封装 更高级
import logging # 日志功能生成模块
import math # 数学函数模块
import os # 与操作系统进行交互的模块
import platform # 提供获取操作系统相关信息的模块
import subprocess # 子进程定义及操作的模块
import time # 时间模块 更底层
from contextlib import contextmanager # 用于进行上下文管理的模块
from copy import deepcopy # 实现深度复制的模块
from pathlib import Path # Path将str转换为Path对象 使字符串路径易于操作的模块
# 以下是一些基本的torch相关的类
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torchvision
try:
import thop # 用于Pytorch模型的FLOPS计算工具模块
except ImportError:
thop = None
logger = logging.getLogger(__name__) # 初始化日志
1、torch_distributed_zero_first
这个函数是用来处理模型进行分布式训练时的同步问题,用在train.py中如:

torch_distributed_zero_first函数代码:
@contextmanager # 这个是上下文管理器
def torch_distributed_zero_first(local_rank: int):
"""train.py
用于处理模型进行分布式训练时同步问题
基于torch.distributed.barrier()函数的上下文管理器,为了完成数据的正常同步操作(yolov5中拥有大量的多线程并行操作)
Decorator to make all processes in distributed training wait for each local_master to do something.
:params local_rank: 代表当前进程号 0代表主进程 1、2、3代表子进程
"""
if local_rank not in [-1, 0]:
# 如果执行create_dataloader()函数的进程不是主进程,即rank不等于0或者-1,
# 上下文管理器会执行相应的torch.distributed.barrier(),设置一个阻塞栅栏,
# 让此进程处于等待状态,等待所有进程到达栅栏处(包括主进程数据处理完毕);
dist.barrier()
yield # yield语句 中断后执行上下文代码,然后返回到此处继续往下执行
if local_rank == 0:
# 如果执行create_dataloader()函数的进程是主进程,其会直接去读取数据并处理,
# 然后其处理结束之后会接着遇到torch.distributed.barrier(),
# 此时,所有进程都到达了当前的栅栏处,这样所有进程就达到了同步,并同时得到释放。
dist.barrier()
2、init_torch_seeds
这个函数用于初始化随机种子并确定训练模式,会被用在general.py中的init_seeds联合一起作几个随机数种子的初始化操作: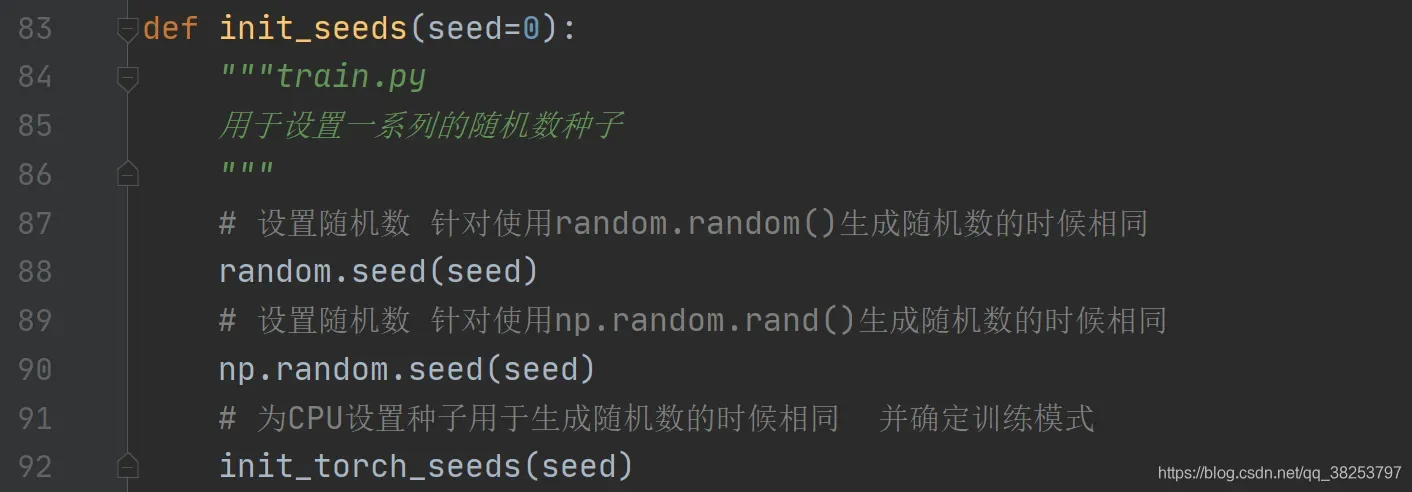
init_torch_seeds函数代码:
def init_torch_seeds(seed=0):
"""用在general.py的init_seeds函数
用于初始化随机种子并确定训练模式
Speed-reproducibility tradeoff https://pytorch.org/docs/stable/notes/randomness.html
"""
# 为CPU设置随机种子,方便下次复现实验结果 to seed the RNG for all devices (both CPU and CUDA)
torch.manual_seed(seed)
# benchmark模式会自动寻找最优配置 但由于计算的随机性 每次网络进行前向传播时会有差异
# 避免这种差异的方法就是将deterministic设置为True(表明每次卷积的高效算法相同)
# 速度与可重复性之间的权衡 涉及底层卷积算法优化
if seed == 0:
# slower, more reproducible 慢 但是具有可重复性 适用于网络的输入数据在每次iteration都变化的话
cudnn.benchmark, cudnn.deterministic = False, True
else:
# faster, less reproducible 快 但是不可重复 适用于网络的输入数据维度或类型上变化不大
cudnn.benchmark, cudnn.deterministic = True, False
3、git_describe、date_modified、select_device
下面三个函数是一起完成自动选择系统设备的操作,在select_device函数中会调用git_describe函数和date_modified函数。下面我依次介绍这三个函数。
3.1、git_describe
这个函数用于返回path文件可读的git描述,用于select_device函数中。
git_describe函数代码:
def git_describe(path=Path(__file__).parent):
"""用在select_device
用于返回path文件可读的git描述 return human-readable git description i.e. v5.0-5-g3e25f1e
https://git-scm.com/docs/git-describe
path: 需要在git中查询(文件描述)的文件名 默认当前文件的父路径
"""
# path must be a directory
s = f'git -C {path} describe --tags --long --always'
try:
# 创建一个子进程在命令行执行 s(git) 命令(返回path文件的描述) 返回执行结果(path文件的描述)
return subprocess.check_output(s, shell=True, stderr=subprocess.STDOUT).decode()[:-1]
except subprocess.CalledProcessError as e:
# 发生异常 path not a git repository 返回''
return ''
3.2、date_modified
这个函数是返回人类可读的修改日期,用于select_device函数中。
date_modified函数代码:
def date_modified(path=__file__):
"""
返回path文件人类可读的修改日期
return human-readable file modification date, i.e. '2021-3-26'
:params path: 文件名 默认当前文件
"""
t = datetime.datetime.fromtimestamp(Path(path).stat().st_mtime)
return f'{t.year}-{t.month}-{t.day}'
3.3、select_device
这个函数才是主角,用于自动选择本机模型训练的设备,并输出日志信息。广泛用于train.py、test.py、detect.py等文件中,如:
select_device函数代码:
def select_device(device='', batch_size=None):
"""广泛用于train.py、test.py、detect.py等文件中
用于选择模型训练的设备 并输出日志信息
:params device: 输入的设备 device = 'cpu' or '0' or '0,1,2,3'
:params batch_size: 一个批次的图片个数
"""
# git_describe(): 返回当前文件父文件的描述信息(yolov5) date_modified(): 返回当前文件的修改日期
# s: 之后要加入logger日志的显示信息
s = f'YOLOv5 🚀 {git_describe() or date_modified()} torch {torch.__version__} ' # string
# 如果device输入为cpu cpu=True device.lower(): 将device字符串全部转为小写字母
cpu = device.lower() == 'cpu'
if cpu:
# 如果cpu=True 就强制(force)使用cpu 令torch.cuda.is_available() = False
os.environ['CUDA_VISIBLE_DEVICES'] = '-1'
elif device:
# 如果输入device不为空 device=GPU 直接设置 CUDA environment variable = device 加入CUDA可用设备
os.environ['CUDA_VISIBLE_DEVICES'] = device
# 检查cuda的可用性 如果不可用则终止程序
assert torch.cuda.is_available(), f'CUDA unavailable, invalid device {device} requested'
# 输入device为空 自行根据计算机情况选择相应设备 先看GPU 没有就CPU
# 如果cuda可用 且 输入device != cpu 则 cuda=True 反正cuda=False
cuda = not cpu and torch.cuda.is_available()
if cuda:
# devices: 如果cuda可用 返回所有可用的gpu设备 i.e. 0,1,6,7 如果不可用就返回 '0'
devices = device.split(',') if device else '0'
# n: 所有可用的gpu设备数量 device count
n = len(devices)
# 检查是否有gpu设备 且 batch_size是否可以能被显卡数目整除 check batch_size is pisible by device_count
if n > 1 and batch_size:
# 如果不能则关闭程序
assert batch_size % n == 0, f'batch-size {batch_size} not multiple of GPU count {n}'
space = ' ' * (len(s) + 1) # 定义等长的空格
# 满足所有条件 s加上所有显卡的信息
for i, d in enumerate(devices):
# p: 每个可用显卡的相关属性
p = torch.cuda.get_device_properties(i)
# 显示信息s加上每张显卡的属性信息
s += f"{'' if i == 0 else space}CUDA:{d} ({p.name}, {p.total_memory / 1024 ** 2}MB)\n" # bytes to MB
else:
# cuda不可用显示信息s就加上CPU
s += 'CPU\n'
# 将显示信息s加入logger日志文件中
logger.info(s.encode().decode('ascii', 'ignore') if platform.system() == 'Windows' else s) # emoji-safe
# 如果cuda可用就返回第一张显卡的的名称 如: GeForce RTX 2060 反之返回CPU对应的名称
return torch.device('cuda:0' if cuda else 'cpu')
4、intersect_dicts
这个函数用于筛选字典中的键值对,将db中的键值对复制给da,但是除了exclude中的键值对。这个函数被用字train.py中载入预训练模型时,筛选预训练权重中的键值对,如下:
intersect_dicts函数代码:
def intersect_dicts(da, db, exclude=()):
"""用于train.py中载入预训练模型时,筛选预训练权重中的键值对
用于筛选字典中的键值对 将db中的键值对复制给da,但是除了exclude中的键值对
"""
# 返回字典da中的键值对 要求键k在字典db中且全部都不在exclude中 同时da中值的shape对应db中值的shape(相同)
return {k: v for k, v in da.items() if k in db
and not any(x in k for x in exclude) and v.shape == db[k].shape}
5、time_synchronized
这个函数用于在进行分布式操作时,精确的获取当前时间。这个函数被广泛的用于整个项目的各个文件中,只要涉及获取当前时间的操作,就需要调用这个函数,如推理的时候计算推理+NMS所花费时间 = t2 – t1:
time_synchronized函数代码:
def time_synchronized():
"""这个函数被广泛的用于整个项目的各个文件中,只要涉及获取当前时间的操作,就需要调用这个函数
精确计算当前时间 并返回当前时间
https://blog.csdn.net/qq_23981335/article/details/105709273
pytorch-accurate time
先进行torch.cuda.synchronize()添加同步操作 再返回time.time()当前时间
为什么不直接使用time.time()取时间,而要先执行同步操作,再取时间?说一下这样子做的原因:
在pytorch里面,程序的执行都是异步的。
如果time.time(), 测试的时间会很短,因为执行完end=time.time()程序就退出了
而先加torch.cuda.synchronize()会先同步cuda的操作,等待gpu上的操作都完成了再继续运行end = time.time()
这样子测试时间会准确一点
"""
if torch.cuda.is_available():
torch.cuda.synchronize()
return time.time()
6、profile、model_info
这两个函数主要用来输出模型的一些信息,比如所有层的层数,模型的参数总数等。
6.1、profile(没用到)
这个函数是用来输出某个网络结构(操作opts)的一些信息:总参数 浮点计算量 前向传播时间 反向传播时间 输入变量的shape 输出变量的shape。但是这个函数貌似没用到,在下面计算model_info时也是调用thop中的profile函数直接执行的,并没用用这里写的这个函数,所以这个函数如果不想看的话关系是不大的。
profile函数代码:
def profile(x, ops, n=100, device=None):
"""
输出某个网络结构(操作ops)的一些信息: 总参数 浮点计算量 前向传播时间 反向传播时间 输入变量的shape 输出变量的shape
:params x: 输入tensor x
:params ops: 操作ops(某个网络结构)
:params n: 执行多少轮ops
:params device: 执行设备
"""
# profile a pytorch module or list of modules. Example usage:
# x = torch.randn(16, 3, 640, 640) # input
# m1 = lambda x: x * torch.sigmoid(x)
# m2 = nn.SiLU()
# profile(x, [m1, m2], n=100) # profile speed over 100 iterations
# 选择设备
device = device or torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 将x变量送入选择的设备上
x = x.to(device)
# 表明需要计算tensor x的梯度
x.requires_grad = True
# 打印当前设备的信息 浮点计算量GFLOPs 前向传播时间 反向传播时间 输入相关时间 输出相关时间
print(torch.__version__, device.type, torch.cuda.get_device_properties(0) if device.type == 'cuda' else '')
print(f"\n{'Params':>12s}{'GFLOPs':>12s}{'forward (ms)':>16s}{'backward (ms)':>16s}{'input':>24s}{'output':>24s}")
for m in ops if isinstance(ops, list) else [ops]:
# 确保ops中所有的操作都是在device设备中运行
# hasattr(m, 'to'): 判断对象m没有to属性
m = m.to(device) if hasattr(m, 'to') else m # device
# 确保操作m和tensor x是处于相同的精度 默认x是Float32的 half可以将精度减半
m = m.half() if hasattr(m, 'half') and isinstance(x, torch.Tensor) and x.dtype is torch.float16 else m # type
# 初始化前向传播时间dtf 反向传播时间dtb 以及t变量用于记录三个时刻的时间(后面有写)
dtf, dtb, t = 0., 0., [0., 0., 0.] # dt forward, backward
try:
# 计算在输入为tensor x, 操作为m条件下的浮点计算量GFLOPs
flops = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2
except:
flops = 0
for _ in range(n): # 执行100次 算平均 更准确
t[0] = time_synchronized() # 操作m前向传播前一时刻的时间
y = m(x) # 操作m前向传播
t[1] = time_synchronized() # 操作m前向传播后一时刻的时间 = 操作m反向传播前一时刻的时间
try:
_ = y.sum().backward() # 操作m反向传播
t[2] = time_synchronized() # 操作m反向传播后一时刻的时间
except: # 如果没有反向传播
t[2] = float('nan')
dtf += (t[1] - t[0]) * 1000 / n # 操作m平均每次前向传播所用时间
dtb += (t[2] - t[1]) * 1000 / n # 操作m平均每次反向传播所用时间
# s_in: 输入变量的shape
s_in = tuple(x.shape) if isinstance(x, torch.Tensor) else 'list'
# s_out: 输出变量的shape
s_out = tuple(y.shape) if isinstance(y, torch.Tensor) else 'list'
# p: m操作(某个网络结构)的总参数 parameters
p = sum(list(x.numel() for x in m.parameters())) if isinstance(m, nn.Module) else 0
# 输出每个操作(某个网络结构)的信息: 总参数 浮点计算量 前向传播时间 反向传播时间 输入变量的shape 输出变量的shape
print(f'{p:12}{flops:12.4g}{dtf:16.4g}{dtb:16.4g}{str(s_in):>24s}{str(s_out):>24s}')
6.2、model_info
这个函数是用来输出模型的所有信息的,这些信息包括:所有层数量, 模型总参数量, 需要求梯度的总参数量, img_size大小的model的浮点计算量GFLOPs。这个函数会被yolo.py文件的Model类的info函数调用,如下: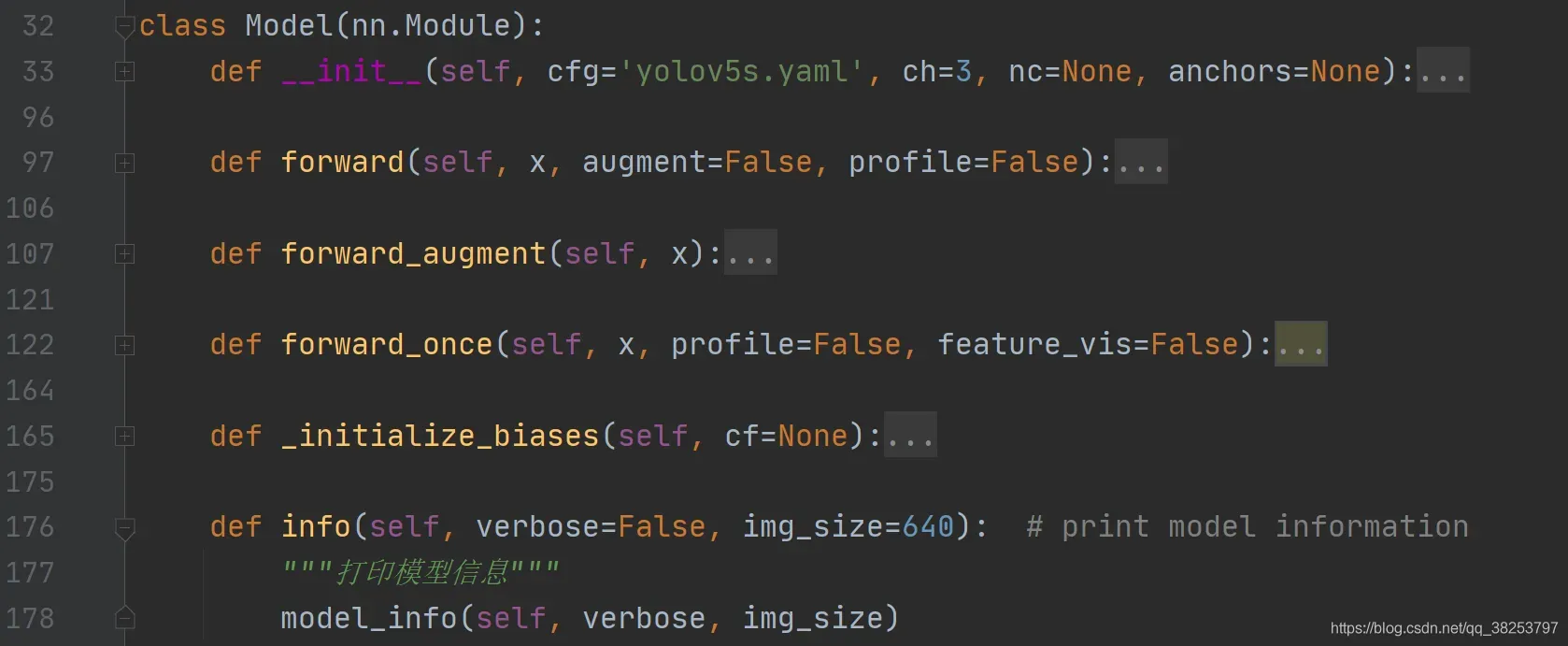
这样需要显示Model相关的信息时,只需要调用self.info即可。而这个函数调用profile的函数并不是上面自己写的,而是直接调的thop包。
model_info函数代码:
def model_info(model, verbose=False, img_size=640):
"""用于yolo.py文件的Model类的info函数
输出模型的所有信息 包括: 所有层数量, 模型总参数量, 需要求梯度的总参数量, img_size大小的model的浮点计算量GFLOPs
:params model: 模型
:params verbose: 是否输出每一层的参数parameters的相关信息
:params img_size: int or list i.e. img_size=640 or img_size=[640, 320]
"""
# n_p: 模型model的总参数 number parameters
n_p = sum(x.numel() for x in model.parameters())
# n_g: 模型model的参数中需要求梯度(requires_grad=True)的参数量 number gradients
n_g = sum(x.numel() for x in model.parameters() if x.requires_grad)
if verbose:
# 表头: 'layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma'
# 第几层 层名 bool是否需要求梯度 当前层参数量 当前层参数shape 当前层参数均值 当前层参数方差
print('%5s %40s %9s %12s %20s %10s %10s' % ('layer', 'name', 'gradient', 'parameters', 'shape', 'mu', 'sigma'))
# 按表头输出每一层的参数parameters的相关信息
for i, (name, p) in enumerate(model.named_parameters()):
name = name.replace('module_list.', '')
print('%5g %40s %9s %12g %20s %10.3g %10.3g' %
(i, name, p.requires_grad, p.numel(), list(p.shape), p.mean(), p.std()))
try: # FLOPs
from thop import profile # 导入计算浮点计算量FLOPs的工具包
# stride 模型的最大下采样率 有[8, 16, 32] 所以stride=32
stride = max(int(model.stride.max()), 32) if hasattr(model, 'stride') else 32
# 模拟一样输入图片 shape=(1, 3, 32, 32) 全是0
img = torch.zeros((1, model.yaml.get('ch', 3), stride, stride), device=next(model.parameters()).device) # input
# 调用profile计算输入图片img=(1, 3, 32, 32)时当前模型的浮点计算量GFLOPs stride GFLOPs
# profile求出来的浮点计算量是FLOPs /1E9 => GFLOPs *2是因为profile函数默认求的就是模型为float64时的浮点计算量
# 而我们传入的模型一般都是float32 所以乘以2(可以点进profile看他定义的add_hooks函数)
flops = profile(deepcopy(model), inputs=(img,), verbose=False)[0] / 1E9 * 2
# expand img_size -> [img_size, img_size]=[640, 640]
img_size = img_size if isinstance(img_size, list) else [img_size, img_size]
# 根据img=(1, 3, 32, 32)的浮点计算量flops推算出640x640的图片的浮点计算量GFLOPs
# 不直接计算640x640的图片的浮点计算量GFLOPs可能是为了高效性吧, 这样算可能速度更快
fs = ', %.1f GFLOPs' % (flops * img_size[0] / stride * img_size[1] / stride)
except (ImportError, Exception):
fs = ''
# 添加日志信息
# Model Summary: 所有层数量, 模型总参数量, 需要求梯度的总参数量, img_size大小的model的浮点计算量GFLOPs
logger.info(f"Model Summary: {len(list(model.modules()))} layers, {n_p} parameters, {n_g} gradients{fs}")
7、initialize_weights
这个函数是用来初始化模型权重的,会在yolo.py的Model类中的init函数被调用,如下:
initialize_weights函数代码:
def initialize_weights(model):
"""在yolo.py的Model类中的init函数被调用
用于初始化模型权重
"""
for m in model.modules():
t = type(m)
if t is nn.Conv2d: # 如果是二维卷积就跳过 或者使用何凯明初始化
pass # nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif t is nn.BatchNorm2d: # 如果是BN层 就设置相关参数: eps和momentum
m.eps = 1e-3
m.momentum = 0.03
elif t in [nn.Hardswish, nn.LeakyReLU, nn.ReLU, nn.ReLU6]:
# 如果是这几类激活函数 inplace插值就赋为True
# inplace = True 指进行原地操作 对于上层网络传递下来的tensor直接进行修改 不需要另外赋值变量
# 这样可以节省运算内存,不用多储存变量
m.inplace = True
8、find_modules(没用到)
这个函数是用于找到模型model中类型是mclass的层结构的索引,但是这个函数没用到,所以大可不看。
find_modules函数代码:
def find_modules(model, mclass=nn.Conv2d):
"""
用于找到模型model中类型是mclass的层结构的索引 Finds layer indices matching module class 'mclass'
:params model: 模型
:params mclass: 层结构类型 默认nn.Conv2d
"""
return [i for i, m in enumerate(model.module_list) if isinstance(m, mclass)]
9、sparsity、prune
这两个函数是用于模型剪枝的,虽然作者并没有在它的代码中使用,但我们自己是可以在test.py和detect.py中进行模型剪枝实验的。
9.1、sparsity
这个函数是用来计算模型的稀疏程度sparsity,返回模型整体的稀疏性。会被prune剪枝函数中被调用。
sparsity函数代码:
def sparsity(model):
"""
用于求模型model的稀疏程度sparsity Return global model sparsity
"""
# 初始化模型的总参数个数a(前向+反向) 模型参数中值为0的参数个数b
a, b = 0., 0.
# model.parameters()返回模型model的参数 返回一个生成器 需要用for循环或者next()来获取参数
# for循环取出每一层的前向传播和反向传播的参数
for p in model.parameters():
a += p.numel()
b += (p == 0).sum()
# b / a 即可以反应模型的稀疏程度
return b / a
9.2、prune
这个函数是用于对模型进行剪枝的,通过调用sparsity函数计算模型的稀疏性进行剪枝,以增加模型的稀疏性。关于函数的用法作者并没有写在它的代码中,不过并不妨碍我们自己实验它,具体用法可以查看下面标注的链接。它主要是可以用在两个地方:
1、test.py: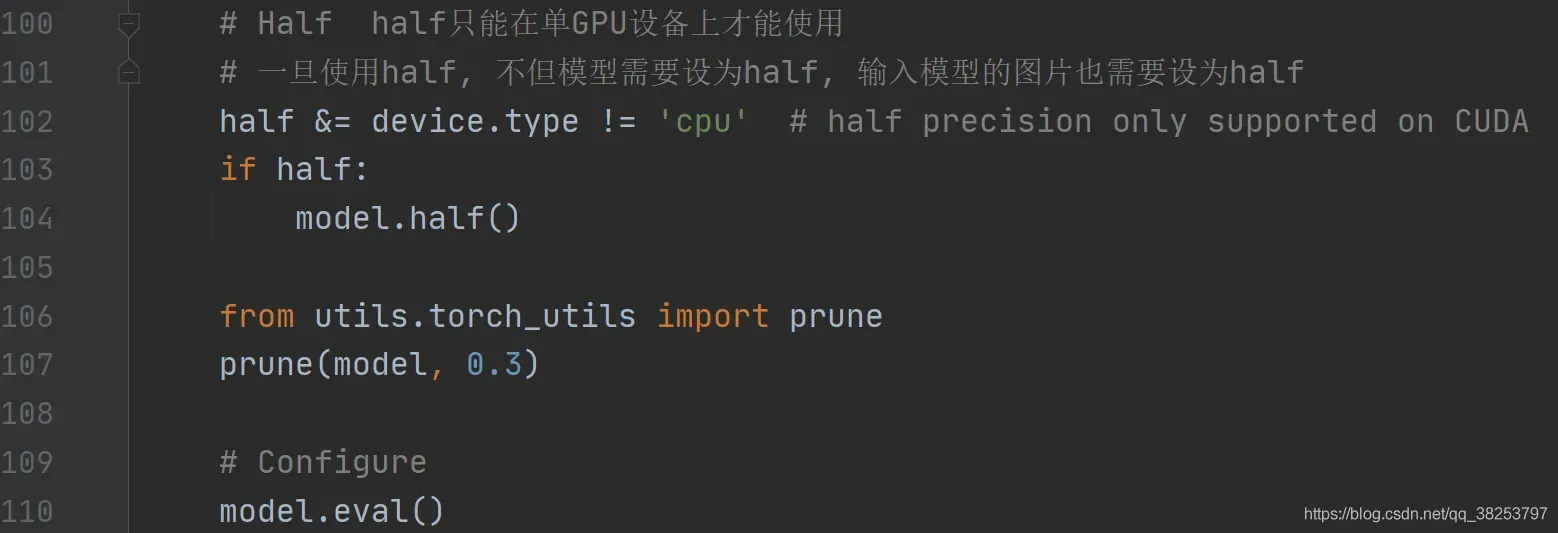 2、detect.py
2、detect.py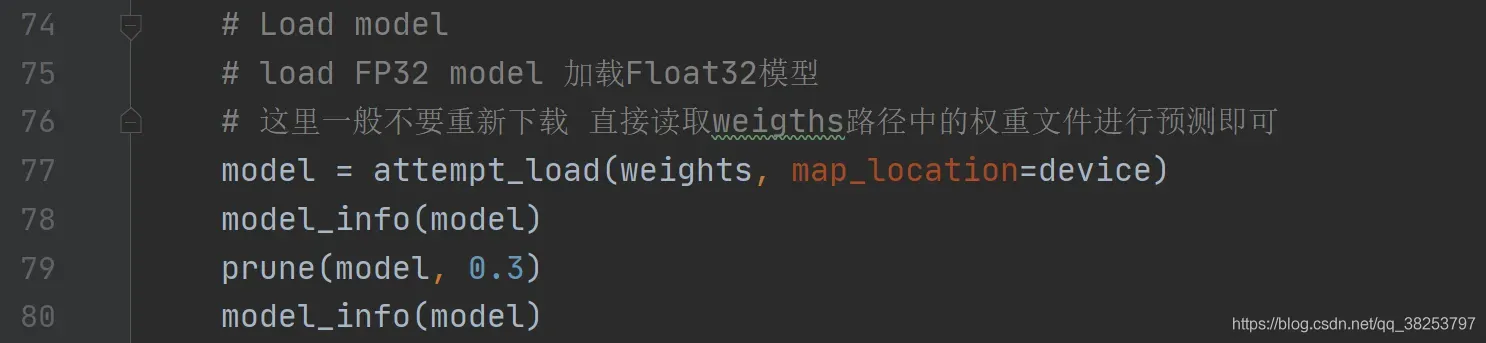
prune函数代码:
def prune(model, amount=0.3):
"""可以用于test.py和detect.py中进行模型剪枝
对模型model进行剪枝操作 以增加模型的稀疏性 使用prune工具将参数稀疏化
https://github.com/ultralytics/yolov5/issues/304
:params model: 模型
:params amount: 随机裁剪(总参数量 x amount)数量的参数
"""
import torch.nn.utils.prune as prune # 导入用于剪枝的工具包
print('Pruning model... ', end='')
# 模型的迭代器 返回的是所有模块的迭代器 同时产生模块的名称(name)以及模块本身(m)
for name, m in model.named_modules():
if isinstance(m, nn.Conv2d):
# 对当前层结构m, 随机裁剪(总参数量 x amount)数量的权重(weight)参数
prune.l1_unstructured(m, name='weight', amount=amount) # prune
# 彻底移除被裁剪的的权重参数
prune.remove(m, 'weight') # make permanent
# 输出模型的稀疏度 调用sparsity函数计算当前模型的稀疏度
print(' %.3g global sparsity' % sparsity(model))
10、fuse_conv_and_bn
这个函数其实是一个增强方式,思想就是:在推理测试阶段,将卷积层和BN层进行融合,以加速推理。具体的证明可以看看下面代码标注的几篇博客/知乎,讲的很清楚,公式证明也不难。这个函数主要会在yolo.py中Model类的fuse函数中调用,如: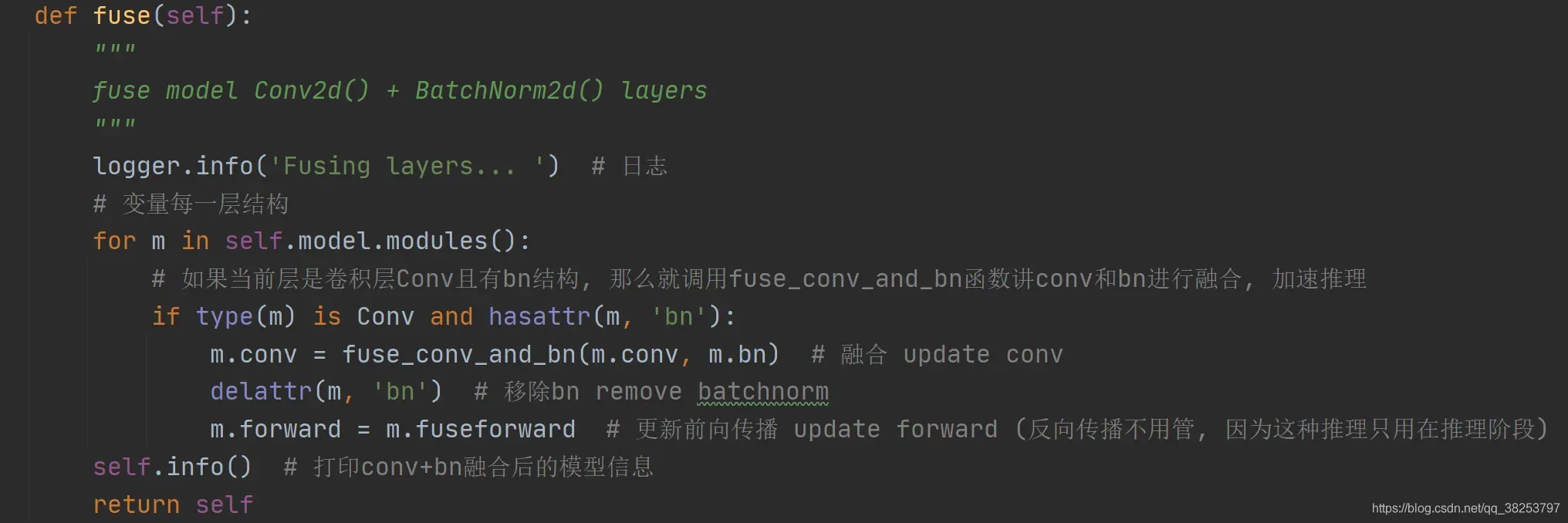
这样在推理阶段,只需要执行 model = model.fuse() ,即可完成融合操作,非常方便简单。
fuse_conv_and_bn函数代码:
def fuse_conv_and_bn(conv, bn):
"""在yolo.py中Model类的fuse函数中调用
融合卷积层和BN层(测试推理使用) Fuse convolution and batchnorm layers
方法: 卷积层还是正常定义, 但是卷积层的参数w,b要改变 通过只改变卷积参数, 达到CONV+BN的效果
w = w_bn * w_conv b = w_bn * b_conv + b_bn (可以证明)
https://tehnokv.com/posts/fusing-batchnorm-and-conv/
https://github.com/ultralytics/yolov3/issues/807
https://zhuanlan.zhihu.com/p/94138640
:params conv: torch支持的卷积层
:params bn: torch支持的bn层
"""
fusedconv = nn.Conv2d(conv.in_channels,
conv.out_channels,
kernel_size=conv.kernel_size,
stride=conv.stride,
padding=conv.padding,
groups=conv.groups,
bias=True).requires_grad_(False).to(conv.weight.device)
# prepare filters
# w_conv: 卷积层的w参数 直接clone conv的weight即可
w_conv = conv.weight.clone().view(conv.out_channels, -1)
# w_bn: bn层的w参数(可以自己推到公式) torch.diag: 返回一个以input为对角线元素的2D/1D 方阵/张量?
w_bn = torch.diag(bn.weight.p(torch.sqrt(bn.eps + bn.running_var)))
# w = w_bn * w_conv torch.mm: 对两个矩阵相乘
fusedconv.weight.copy_(torch.mm(w_bn, w_conv).view(fusedconv.weight.shape))
# prepare spatial bias
# b_conv: 卷积层的b参数 如果不为None就直接读取conv.bias即可
b_conv = torch.zeros(conv.weight.size(0), device=conv.weight.device) if conv.bias is None else conv.bias
# b_bn: bn层的b参数(可以自己推到公式)
b_bn = bn.bias - bn.weight.mul(bn.running_mean).p(torch.sqrt(bn.running_var + bn.eps))
# b = w_bn * b_conv + b_bn (w_bn not forgot)
fusedconv.bias.copy_(torch.mm(w_bn, b_conv.reshape(-1, 1)).reshape(-1) + b_bn)
return fusedconv
11、load_classifier
这个函数用于在检测后可能需要进行二次分类,比如一个场景:在一张图片中有猫和车牌,我们用yolo将车牌和猫分别做好了分类和定位,但是如果我接下来还要分出是什么猫或者车牌数字是什么,这些都是二次任务,需要再写函数才能实现。这个函数会在detect.py中调用:
load_classifier函数代码:
def load_classifier(name='resnet101', n=2):
"""在detect.py中调用
用于检测结束后可能需要第二次分类 直接修改torchvision中的预训练模型的分类类别即可
:params name: 分类模型名字 默认resnet101
:params n: 分类模型的分类类别数 需要在加载了预训练模型后将model的最后一层的类别数改为n
"""
#
# 加载torchvision中已经写好的pretrained模型 reshape为n类输出
model = torchvision.models.__dict__[name](pretrained=True)
# ResNet model properties
# input_size = [3, 224, 224]
# input_space = 'RGB'
# input_range = [0, 1]
# mean = [0.485, 0.456, 0.406]
# std = [0.229, 0.224, 0.225]
# 将加载的预训练模型的最后一层的分类类别数改为n Reshape output to n classes
# 总体的过程 = 将fc层的权重和偏置清0 + 修改类别个数为n
filters = model.fc.weight.shape[1]
model.fc.bias = nn.Parameter(torch.zeros(n), requires_grad=True)
model.fc.weight = nn.Parameter(torch.zeros(n, filters), requires_grad=True)
model.fc.out_features = n
# 返回reshape后的模型 进行二次分类
return model
这里只是简单的改了一下分类类别,实际上如果改了这个的话,肯定还需要修改loss函数优化它的,我就不往下延申了。
12、scale_img
这个函数是用于对图片进行缩放操作。第一时间比较奇怪,这种数据增强的操作怎么会写在这里呢?不是应该写在datasets.py中吗?其实这里的scale_img是专门用于yolo.py文件中Model类的forward_augment函数中的。为什么模型部分需要对输入图片进行scale shape呢?作者有提到,这是一种Test Time Augmentation(TTA)操作,就是在测试时也使用数据增强,也算是一种增强的方式吧,但是这种方式感觉用的并不多,需要多多实验。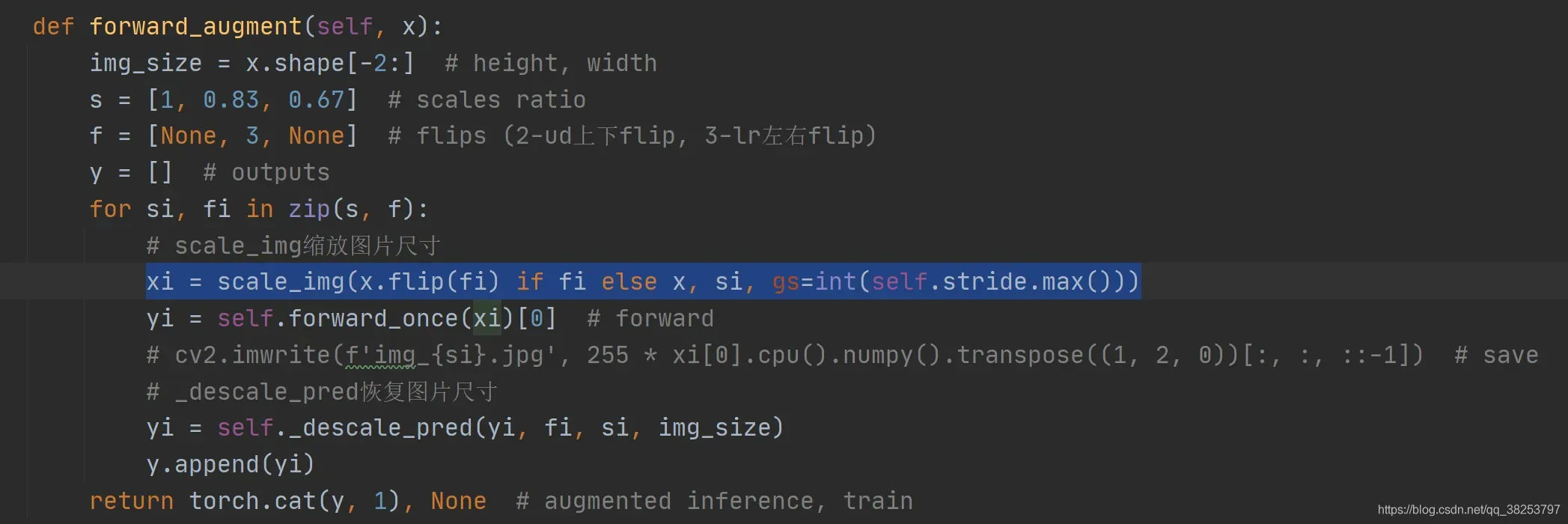
scale_img函数代码:
def scale_img(img, ratio=1.0, same_shape=False, gs=32):
"""用于yolo.py文件中Model类的forward_augment函数中
实现对图片的缩放操作
:params img: 原图
:params ratio: 缩放比例 默认=1.0 原图
:params same_shape: 缩放之后尺寸是否是要求的大小(必须是gs=32的倍数)
:params gs: 最大的下采样率 32 所以缩放后的图片的shape必须是gs=32的倍数
"""
# img(16,3,256,416)
# scales img(bs,3,y,x) by ratio constrained to gs-multiple
if ratio == 1.0: # 如果缩放比例ratio为1.0 直接返回原图
return img`在这里插入代码片`
else: # 如果缩放比例ratio不为1.0 则开始根据缩放比例ratio进行缩放
# h, w: 原图的高和宽
h, w = img.shape[2:]
# s: 放缩后图片的新尺寸 new size
s = (int(h * ratio), int(w * ratio))
# 直接使用torch自带的F.interpolate(上采样下采样函数)插值函数进行resize
# F.interpolate: 可以给定size或者scale_factor来进行上下采样
# mode='bilinear': 双线性插值 nearest:最近邻
# align_corner: 是否对齐 input 和 output 的角点像素(corner pixels)
img = F.interpolate(img, size=s, mode='bilinear', align_corners=False)
if not same_shape:
# 缩放之后要是尺寸和要求的大小(必须是gs=32的倍数)不同 再对其不相交的部分进行pad
# 而pad的值就是imagenet的mean
# Math.ceil(): 向上取整 这里除以gs向上取整再乘以gs是为了保证h、w都是gs的倍数
h, w = [math.ceil(x * ratio / gs) * gs for x in (h, w)]
# pad img shape to gs的倍数 填充值为 imagenet mean
return F.pad(img, [0, w - s[1], 0, h - s[0]], value=0.447)
13、de_parallel
这个函数用于判断单卡还是多卡(能否并行) 多卡返回model.module 单卡返回model(具体原因看下面代码注释)。这个函数用在train.py中, 用于加载和保存模型(参数),如: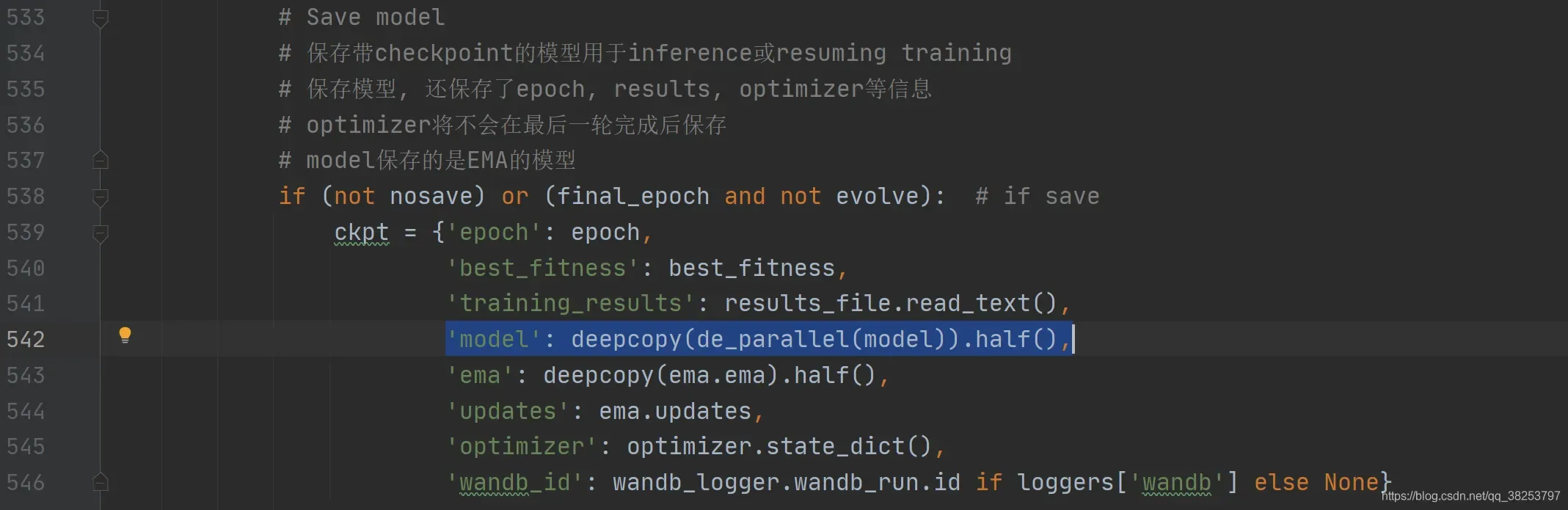
de_parallel函数代码:
def de_parallel(model):
"""用在train.py中, 用于加载和保存模型(参数)
判断单卡还是多卡(能否并行) 多卡返回model.module 单卡返回model
"""
# De-parallelize a model: returns single-GPU model if model is of type DP or DDP
# 如果model支持并行(多卡)就返回model.module 不支持并行就返回model
# 用在tain中保存模型 因为多卡训练的时候直接用model.state_dict()进行保存的模型, 每个层参数的名称前面会加上module,
# 这时候再用单卡(gpu) model_dict加载model.state_dict()参数时会出现名称不匹配的情况,
# 因此多卡保存模型时注意使用model.module.state_dict() 即返回model.module 单卡返回model即可
return model.module if is_parallel(model) else model
14、is_parallel、copy_attr、ModelEMA类
14.1、is_parallel
这个函数用于判断模型是否支持并行,在ModelEMA类中调用。
is_parallel函数代码:
def is_parallel(model):
"""在ModelEMA类中调用
用于判断模型是否支持并行 Returns True if model is of type DP or DDP
"""
return type(model) in (nn.parallel.DataParallel, nn.parallel.DistributedDataParallel)
14.2、copy_attr
这个函数可以将b对象的属性值赋值给a对象(key键必须相同,然后才能赋值),常用于模型赋值,如 model -> ema(ModelEMA类就是这么干的)。这个函数会在两个地方用到,一个是ModelEMA类中,另一个是yolo.py文件中的Model类的autoshape函数 如:
copy_attr函数代码:
def copy_attr(a, b, include=(), exclude=()):
"""在ModelEMA函数和yolo.py中Model类的autoshape函数中调用
复制b的属性(这个属性必须在include中而不在exclude中)给a
:params a: 对象a(待赋值)
:params b: 对象b(赋值)
:params include: 可以赋值的属性
:params exclude: 不能赋值的属性
"""
# Copy attributes from b to a, options to only include [...] and to exclude [...]
# __dict__返回一个类的实例的属性和对应取值的字典
for k, v in b.__dict__.items():
if (len(include) and k not in include) or k.startswith('_') or k in exclude:
continue
else:
# 将对象b的属性k赋值给a
setattr(a, k, v)
14.3、class ModelEMA
最后一个类 ModelEMA的定义,这个类非常重要,是一种非常常见的提高模型鲁棒性的增强trock,被广泛的使用。全名:Model Exponential Moving Average 模型的指数加权平均方法,是一种给予近期数据更高权重的平均方法 ,利用滑动平均的参数来提高模型在测试数据上的健壮性/鲁棒性 ,一般用于测试集。
这个类的定义用到了很多数学知识,包括公式的推导,我这里几句话都解释不了。在下面代码的注释中,我收集了几个关于这个方法的吴恩达视频、博客、知乎。原理的解释,如果你仔细看,再看这段代码,应该差不多吧。
这个函数被用在train.py中的test.run(测试)阶段:
更新参数也需要更新ema: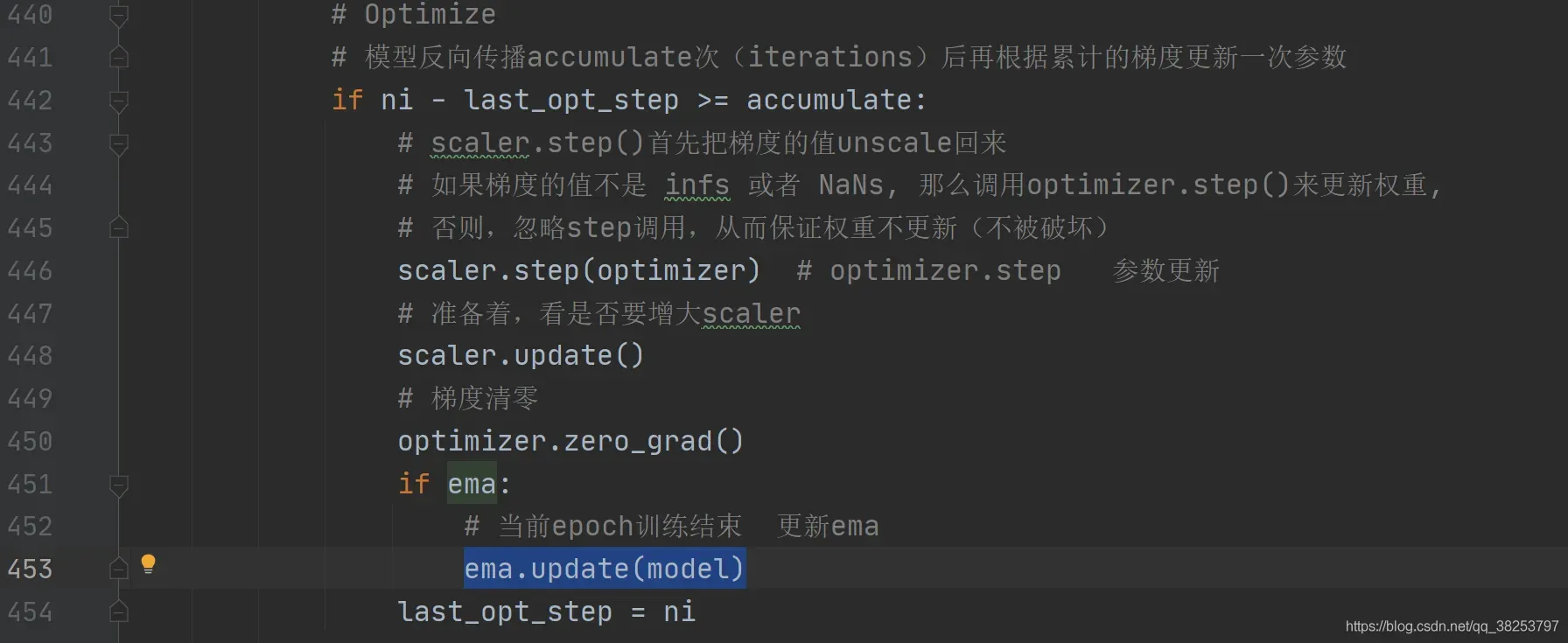
class ModelEMA类代码:
class ModelEMA:
"""用在train.py中的test.run(测试)阶段
模型的指数加权平均方法(Model Exponential Moving Average)
是一种给予近期数据更高权重的平均方法 利用滑动平均的参数来提高模型在测试数据上的健壮性/鲁棒性 一般用于测试集
https://www.bilibili.com/video/BV1FT4y1E74V?p=63
https://www.cnblogs.com/wuliytTaotao/p/9479958.html
https://zhuanlan.zhihu.com/p/68748778
https://zhuanlan.zhihu.com/p/32335746
https://github.com/ultralytics/yolov5/issues/608
https://github.com/rwightman/pytorch-image-models/blob/master/timm/utils/model_ema.py
"""
def __init__(self, model, decay=0.9999, updates=0):
"""train.py
model:
decay: 衰减函数参数
默认0.9999 考虑过去10000次的真实值
updates: ema更新次数
"""
# 创建ema模型 Create EMA
self.ema = deepcopy(model.module if is_parallel(model) else model).eval() # FP32 EMA
# if next(model.parameters()).device.type != 'cpu':
# self.ema.half() # FP16 EMA
self.updates = updates # ema更新次数 number of EMA updates
# self.decay: 衰减函数 输入变量为x decay exponential ramp (to help early epochs)
self.decay = lambda x: decay * (1 - math.exp(-x / 2000))
# 所有参数取消设置梯度(测试 model.val)
for p in self.ema.parameters():
p.requires_grad_(False)
def update(self, model):
# 更新ema的参数 Update EMA parameters
with torch.no_grad():
self.updates += 1 # ema更新次数 + 1
d = self.decay(self.updates) # 随着更新次数 更新参数贝塔(d)
# msd: 模型配置的字典 model state_dict msd中的数据保持不变 用于训练
msd = model.module.state_dict() if is_parallel(model) else model.state_dict()
# 遍历模型配置字典 如: k=linear.bias v=[0.32, 0.25] ema中的数据发生改变 用于测试
for k, v in self.ema.state_dict().items():
# 这里得到的v: 预测值
if v.dtype.is_floating_point:
v *= d # 公式左边 decay * shadow_variable
# .detach() 使对应的Variables与网络隔开而不参与梯度更新
v += (1. - d) * msd[k].detach() # 公式右边 (1−decay) * variable
def update_attr(self, model, include=(), exclude=('process_group', 'reducer')):
# 调用上面的copy_attr函数 从model中复制相关属性值到self.ema中
copy_attr(self.ema, model, include, exclude)
总结
好了,torch_utils.py文件就介绍到这里了。如果有看注释还是不懂的函数建议百度查一下,有查的这个过程会印象更深一点。如果是逻辑上的问题建议debug调试一下。
写于2021-07-29晚20:00
版权声明:本文为博主满船清梦压星河HK原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_38253797/article/details/119214728