交叉验证(Cross Validation)和网格搜索(Grid Search)常结合在一起并用来筛选模型的最优参数。本文将从零开始一步步讲解交叉验证和网格搜索的由来,并基于sklearn实现它们。
交叉验证的方法
1.1 交叉验证法的由来
在机器学习中,我们通常是将已有的数据集(Data Set)一分为二(不一定等分),一部分是训练集(Training Set),一部分是测试集(Test Set)。通常,我们会在训练集上训练模型(Model),然后在测试集上评估模型的性能(Performance)。评估性能需要用到性能度量(Performance Measure),即衡量模型好坏的指标。本文将使用准确率(accuracy)作为性能度量。
以软间隔SVM为例,其中的参数需要事先给定,我们将这种需要事先给定的参数称为超参数(Hyperparameter)。如果选用高斯核、多项式核、Sigmoid核,则其中的参数
也是超参数。我们先只考虑线性核,也就是只有一个超参数的情形。
首先,将数据集分为训练集和测试集。此时,训练集和测试集已经固定:

对于每个固定的,我们在训练集上训练都会得到一个软间隔SVM模型,然后在测试集上评估该模型的分类准确率。如果准确率高,我们就说模型是好的,反之则较差。我们自然是想找到使得分类准确率最高的那个
,因为它对应的模型是最好的。寻找 “最好” 的
的这一过程称为调参(Parameter Tuning),即不断调整参数使得训练出来的模型最优,“最好” 的
也称为最优参数(Best Parameter)。
为了叙述方便起见,我们接下来将模型在测试集上的分类准确率称为得分(Score)。此外,因为当确定参数后,模型也就随之确定了,即参数和模型之间是一个一一对应的关系,所以我们后续也会使用 “参数的得分” 这种说法。
假设我们找到了最优参数:,它对应于得分最高的模型。现在,我们要测试这个最优模型的泛化能力,但是没有数据可供我们测试。如果我们还在测试集上测试这个最优模型的性能,那无疑是重复性的工作,因为我们已经在参数调优过程中测试了每个模型在测试集上的性能。另一方面,因为我们的
是根据模型在测试集上的得分来选择的,也就是说,测试集中的“知识”已经渗入了我们的最优模型,这会导致过拟合,这降低了模型的泛化能力。模型。
解决该问题的一个方法就是,将原先的训练集一分为二,一部分用作训练集,一部分用作验证集(Validation Set)。验证集用来选择最优参数,得到最优参数后再在原先的训练集上重新训练,得到的模型在测试集上评估最终性能(Final Evaluation)。

因为我们在获得最佳参数之前对验证集上的每个模型(参数)进行评分,所以得分最高的模型(参数)成为最佳参数。换句话说,最优参数与验证集有关。验证集与原始训练集分开。这种划分有一定的机率,可能导致我们的最优参数在众多参数中是“幸运的”,即最优参数更适合这个验证集。 ,如果换成另一个验证集,可能不是最优的。
例如,设原训练集为,考虑两种划分方式:
,
,其中
为不同的验证集,
为训练集,则可能有:
- 当验证集为
时,最优参数为
,最差参数为
- 当验证集为
时,最优参数为
,最差参数为
那么如何减少这个机会呢?直观上,应该取多个验证集,参数在每个验证集
上都会有一个分数
,将这些分数的平均值
作为这个参数的分数。
注意,验证集是从原始训练集划分出来的,即,为了进一步减少机会,一个自然的想法是使用所有原始训练集,并要求验证集互斥且大小相等,即:
这样,我们得到训练集
验证集,对于每个参数,它的分数是这个
验证集上的分数的平均值:
最高的参数成为我们的最优参数。下图更形象地展示了这个过程:
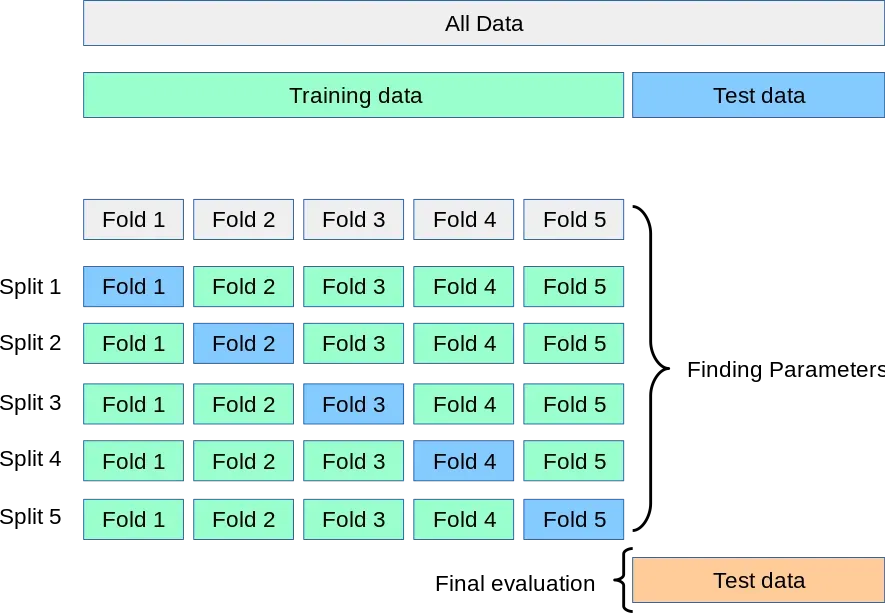
获得最优参数后,我们在原始训练集上重新训练。完整的流程图如下:
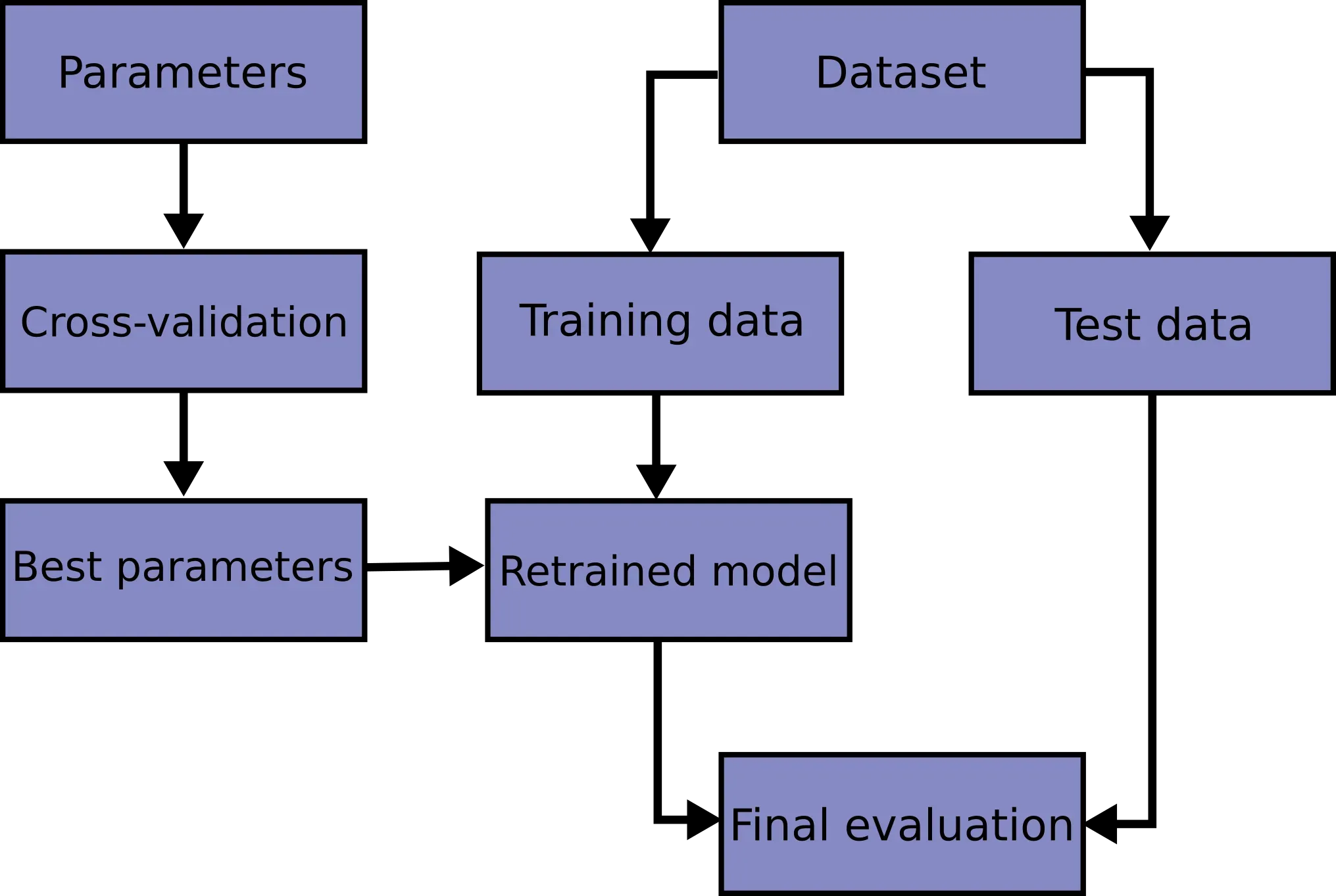
很多时候,我们的不能平分
,所以只能满足于次之。
这是交叉验证方法。
1.2 交叉验证法的定义
将数据集
(原先的训练集)划分为
个大小相似的互斥子集。每个子集
尽可能保持数据分布的一致性,即从
中通过分层采样得到。然后每次用
个子集的并集作为训练集,余下的那个子集作为验证集;这样就可以获得
组训练
验证集,从而可以进行
次训练和验证,最终返回的是这
个结果的均值。 该方法又称为
折交叉验证(k-fold cross validation),
常用的取值为
等。
若
,则得到了交叉验证法的一个特例:留一法(Leave-One-Out,简称LOO)。LOO使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,LOO中被实际评估的模型与期望评估的用
训练出的模型很相似。因此,LOO的评估结果往往被认为比较准确。但LOO也有缺陷:
较大时,训练
个模型的计算开销可能是难以忍受的(这还是在未考虑调参的情况下)。
1.3 sklearn.model_selection.train_test_split()
该函数的主要作用是将现有数据集随机划分为训练集和测试集,其主要参数如下:
| 参数 | 描述 |
|---|---|
| X | 示例矩阵 |
| y | 标签向量 |
| test_size | 可以为浮点数或整数;当为浮点数时,表示测试集在整个数据集中所占的比例。当为整数时,表示测试集的大小;当test_size和train_size都为None时,test_size默认调整至0.25 |
| train_size | 同上;当train_size为None时,默认调整至测试集的补集的大小 |
不熟悉示例矩阵和标签向量的读者可以参考我之前的文章。
函数会返回一个列表,我们只需要使用对应的四个参数来接收即可。
from sklearn.model_selection import train_test_split
X = [[1, 2], [2, 3], [3, 3], [2, 1], [3, 2]]
y = [1, 1, 1, -1, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
print(X_train)
# [[3, 3], [1, 2], [2, 1]]
print(X_test)
# [[2, 3], [3, 2]]
print(y_train)
# [1, 1, -1]
print(y_test)
# [1, -1]
1.4 sklearn.metrics.accuracy_score()
在我们进一步讨论与交叉验证相关的函数之前,让我们先谈谈与性能指标相关的函数。
我们已经知道,SVC类的score方法clf.score()可以用来计算模型在测试集上的分类准确率,例如:
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = SVC(kernel='linear')
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.912
即分类准确率为。
accuracy_score的使用方法:。其中y_true是真实的标签列表,而y_pred是预测的标签列表。
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = SVC(kernel='linear')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
# 0.912
看到这里,可能会有读者疑惑,clf.score和accuracy_score的结果一样,那它们之间到底有什么区别呢?
1.4.1 clf.score 与 accuracy_score 的区别
不严谨地来讲,accuracy_score仅仅是按序比较两个列表(array_like对象),然后返回相同元素的个数所占的比例:
from sklearn.metrics import accuracy_score
A = [1, 2, 3, 4]
B = [2, 2, 3, 5]
C = [4, 3, 2, 1]
print(accuracy_score(A, B))
# 0.5
print(accuracy_score(A, C))
# 0.4
从第二个输出可以看出,虽然两个列表的内容相同,但因为accuracy_score是按序(索引)进行比较的,所以准确率为;从第一个输出可以看出,两个列表只有索引
和
处的元素相同,所以准确率为
。
再来看看clf.score,其底层实现为
def score(self, X, y, sample_weight=None):
from .metrics import accuracy_score
return accuracy_score(y, self.predict(X), sample_weight=sample_weight)
可以看出本质上和accuracy_score没有什么区别,但clf.score使用起来更为方便,因此更加推荐。
1.5 sklearn.model_selection.cross_val_score()
我们已经知道,折交叉验证一共会产生
个得分(这些得分的均值作为交叉验证的得分),而cross_val_score()返回的就是这
个得分。
该函数主要有以下参数:
| 参数 | 描述 |
|---|---|
| estimator | SVM任务下就是SVC实例 |
| scoring | 性能度量;默认值为None,即采用SVC类中的score方法;有关scoring的可选参数请见官方文档 |
| cv |
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
clf = SVC(kernel='linear')
print(cross_val_score(clf, X, y, cv=3))
# [0.94011976 0.94011976 0.93373494]
print(cross_val_score(clf, X, y, cv=3, scoring='accuracy'))
# [0.94011976 0.94011976 0.93373494]
该例子也进一步说明了clf.score和accuracy_score是一样的。
scores = cross_val_score(clf, X, y, cv=3)
print("%.4f accuracy with a standard deviation of %.4f" % (scores.mean(), scores.std()))
# 0.938 accuracy with a standard deviation of 0.003
也就是说,我们的交叉验证分数是。
基于此,我们可以使用cross_val_score来选择最优参数:
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
for C in [1, 10, 100, 1000, 10000, 100000]:
clf = SVC(C=C, kernel='linear')
scores = cross_val_score(clf, X, y, cv=4) # 四折交叉验证
print('C: %d, accuracy: %.3f' % (C, scores.mean()))
# C: 1, accuracy: 0.936
# C: 10, accuracy: 0.936
# C: 100, accuracy: 0.936
# C: 1000, accuracy: 0.938
# C: 10000, accuracy: 0.938
# C: 100000, accuracy: 0.940
从输出结果可以看出,是这六个参数中的最优参数(但需要注意的是,我们直接将原始数据集分为训练集和验证集,并没有划分测试集)。
正确的过程应该是:首先将原始数据集分为训练集和测试集,对训练集进行折交叉验证,选择最优参数,得到最优参数后,在训练集上训练模型,在测试集上测试性能,完整代码如下:
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# 初始化
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
params = [1, 10, 100, 1000, 10000, 100000, 1000000]
params_score = []
# 寻找最优参数
for C in params:
clf = SVC(C=C, kernel='linear')
scores = cross_val_score(clf, X_train, y_train, cv=4)
params_score.append(scores.mean())
best_param = params[params_score.index(max(params_score))]
# 重新训练
clf_best = SVC(C=best_param, kernel='linear')
clf_best.fit(X_train, y_train)
# 测试性能
accuracy = clf_best.score(X_test, y_test)
print(best_param)
# 1000000
print(accuracy)
# 0.95
可以看出,在测试集上用最优参数训练出来的模型的分类精度为。
2.网格搜索方式
网格搜索的本质是遍历。
2.1 网格搜索法的由来
在训练线性核软间隔SVM时,会涉及到超参数,选取合适的
值能够使我们训练出来的模型最优,那么该如何去寻找这个最合适的
值呢?
一个自然的想法是尝试的所有值,并使用交叉验证对
的每个值进行评分,得分最高的
成为我们的最优参数。但在现实中,我们的参数一般都是连续取值的,我们不可能遍历所有的
值,所以只能考虑有限数量的
值。考虑到
一般较大,我们可以假设
的值集为
所以我们只需要遍历集合。
现在考虑高斯核的情况,它涉及两个参数:。因为
的值一般很小,我们可以假设它的值集是
现在取笛卡尔积,集合的大小为
,其元素的形式为
。遍历
等价于遍历
的所有可能组合。注意
也可以用“网格”表示:
因此,遍历相当于遍历上面的网格,并且因为我们需要在网格中找到最优参数,所以这种方法也称为网格搜索法。
不难看出,网格搜索法的本质是蛮力遍历,即尝试每一种情况,找到最优的。
2.2 使用 for 循环实现网格搜索
因为网格搜索的本质是遍历,所以我们完全可以使用for循环来实现这种遍历。
事实上,1.5 节中的最后一个例子就用到了网格搜索法,不过我们当时也仅仅是遍历了一个参数的取值集合。现在我们考虑两个参数的情形,即使用高斯核的软间隔SVM。
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# 初始化
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
best_score = 0
# 寻找最优参数
for C in [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6]:
for gamma in [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1]:
clf = SVC(C=C, gamma=gamma)
cv_scores = cross_val_score(clf, X_train, y_train, cv=4)
current_score = cv_scores.mean()
if current_score > best_score:
best_score = current_score
best_parameters = {'C': C, 'gamma': gamma}
# 重新训练
clf_best = SVC(**best_parameters)
clf_best.fit(X_train, y_train)
# 测试性能
accuracy = clf_best.score(X_test, y_test)
print(best_parameters)
# {'C': 100000.0, 'gamma': 0.01}
print(accuracy)
# 0.94
输出结果表明最优参数为,最终分类精度为
。
2.3 sklearn.model_selection.GridSearchCV()
看到这里可能有读者会想,虽然for循环是可以实现网格搜索,那有没有更简便快捷的方法呢?好在 sklearn 提供了这样的一个类:sklearn.model_selection.GridSearchCV,它结合了网格搜索与交叉验证,能够方便地给出你想要的结果。
2.3.1 参数
创建一个 GridSearchCV 实例常用到以下参数:
在SVM场景下,estimator指的是SVC实例。因为后续我们还需要向GridSearchCV()中传入参数网格,所以创建SVC实例的时候不需要任何参数,即:
estimator = SVC()
clf = GridSearchCV(estimator, ...)
它甚至可以更简单地写成
clf = GridSearchCV(SVC(), ...)
参数网格,可以是字典或字典列表。
例如对于2.2节中的例子,我们的参数网格就是一个字典:
param_grid = {
'C': [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6],
'gamma': [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1],
}
在这种情况下有参数组合。
对于一些复杂的任务,我们可能需要使用字典列表:
param_grid = [
{"kernel": ["rbf"], "gamma": [1e-3, 1e-4], "C": [1, 10, 100, 1000]},
{"kernel": ["linear"], "C": [1, 10, 100, 1000]},
]
在这种情况下有参数组合。
性能度量,默认值为None。常用参数为’accuracy’。
默认值为True。
refit 为True时,程序会使用得到的最优参数在原先的训练集上重新训练,结果会存储在GridSearchCV实例的best_estimator_属性中(注意,best_estimator_是已经拟合了的estimator)。
2.3.2 方法
本节仅列出三种最常用的方法。其他方法可以参考官方文档。
| 方法 | 描述 |
|---|---|
| fit(X, y) | 基于所有参数组合拟合estimator |
| predict(X) | 使用最优模型预测样本;当 refit=True 时才可用 |
| score(X_test, y_test) | 除非 scoring 给定,否则采用 best_estimator_.score 方法计算得分 |
现在,我们将使用GridSearchCV来简化2.2节中的代码。
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
param_grid = {
'C': [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6],
'gamma': [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1],
}
clf = GridSearchCV(SVC(), param_grid, cv=4)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.94
输出结果与2.2节中的一致,但代码大大得到了简化。
2.3.3 属性
这里只列出常用的属性。
| 属性 | 描述 |
|---|---|
| cv_results_ | 以字典形式返回交叉验证的结果 |
| best_estimator_ | 使用最优参数在原先的训练集上重新训练得到的estimator |
| best_score_ | best_estimator的交叉验证的得分(均值) |
| best_params_ | best_estimator中的参数 |
| best_index_ | best_params在 clf.cv_results_['params'] 中的索引 |
让我们通过一些示例进一步熟悉这些属性。
为了简单起见,我们将参数网格设置为“更小”,其他保持不变。
......
param_grid = {
'C': [1e4, 1e5],
'gamma': [1e-2, 1e-1],
}
......
print(clf.cv_results_)
输出是:
{
'mean_fit_time': array([0.00424391, 0.01795793, 0.02118272, 0.12142873]),
'std_fit_time': array([0.00044348, 0.00522967, 0.00470208, 0.01951696]),
'mean_score_time': array([0. , 0.00074494, 0.0007624 , 0.00074446]),
'std_score_time': array([0. , 0.00043013, 0.00044034, 0.00042986]),
'param_C': masked_array(data=[10000.0, 10000.0, 100000.0, 100000.0],
mask=[False, False, False, False], fill_value='?', dtype=object),
'param_gamma': masked_array(data=[0.01, 0.1, 0.01, 0.1],
mask=[False, False, False, False], fill_value='?', dtype=object),
'params': [{'C': 10000.0, 'gamma': 0.01}, {'C': 10000.0, 'gamma': 0.1},
{'C': 100000.0, 'gamma': 0.01}, {'C': 100000.0, 'gamma': 0.1}],
'split0_test_score': array([0.94, 0.94, 0.95, 0.94]),
'split1_test_score': array([0.93, 0.95, 0.94, 0.94]),
'split2_test_score': array([0.97, 0.95, 0.98, 0.95]),
'split3_test_score': array([0.94, 0.94, 0.93, 0.93]),
'mean_test_score': array([0.945, 0.945, 0.95 , 0.94 ]),
'std_test_score': array([0.015 , 0.005 , 0.01870829, 0.00707107]),
'rank_test_score': array([2, 2, 1, 4])
}
注意:
- ‘params’中存储了所有的参数组合。
- mean_fit_time,std_fit_time,mean_score_time和std_score_time的单位均是秒。
print(clf.best_estimator_)
# SVC(C=100000.0, gamma=0.01)
print(clf.best_params_)
# {'C': 100000.0, 'gamma': 0.01}
print(clf.best_index_)
# 2
print(clf.best_score_)
# 0.9500000000000001
不难看出,clf.best_estimator_等价于SVC(**clf.best_params_),且最优参数clf.best_params_在列表clf.cv_results_[‘params’]中的索引为 2,即
print(clf.cv_results_['params'][clf.best_index_] == clf.best_params_)
# True
3.项目实战-虹膜分类
3.1 鸢尾花数据集介绍
sklearn 中有现成的鸢尾花数据集,我们可以从其中的datasets导入加载鸢尾花数据集的函数:
from sklearn.datasets import load_iris
鸢尾花数据集简介:
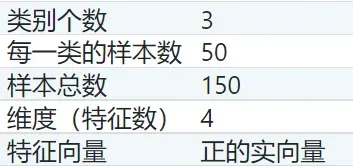
可以看出,我们将面临的问题是多(三)分类问题。
3.2 sklearn.datasets.load_iris()
该函数最主要的参数只有一个:return_X_y。
默认值为False。
当值为True时,load_iris()将返回元组(data, target)(即(X, y)),否则将以Bunch对象(类字典对象)返回。
这里建议将return_X_y设置为True,这样我们就能很方便地使用两个参数进行接收:
X, y = load_iris(return_X_y=True)
如果设置为False(即默认状态),我们就只能:
iris = load_iris()
X, y = iris.data, iris.target
3.3 代码实现
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
param_grid = {
'C': [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6],
'kernel': ['rbf', 'linear'],
'gamma': [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1],
}
clf = GridSearchCV(SVC(), param_grid, cv=5)
clf.fit(X_train, y_train)
print(clf.best_params_)
# {'C': 10.0, 'gamma': 0.1, 'kernel': 'rbf'}
print(clf.score(X_test, y_test))
# 0.9777777777777777
使用五折交叉验证,我们的最优参数为,核为高斯核,最终模型在测试集上的分类精度为
。
References
[1]Cross-validation: evaluating estimator performance.
[2]Tuning the hyper-parameters of an estimator.
[3]sklearn.datasets.load_iris.
[4] 机器学习. 周志华
版权声明:本文为博主serity原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_44022472/article/details/122906860