目录
正则化(Regularization)和偏差(Bias 偏置 )、方差
改变λ验证误差和训练误差(Training error)会怎么变?
单变量线性回归(Regression)(Linear Regression)
多变量线性回归(Regression)(Linear Regression)
评估假设(Hypothesis)

评价假设(Hypothesis)的标准方法
将一大批数据分成两部分,第一部分成为我们的训练集,第二部分成为我们的训练集一种比较典型的分割是按7:3的比例,7–>训练集,3–>测试集;如果数据是有某种规律的,那么选择的时候最好随机选择。下面是标准方法在线(online)性回归(Regression)(Linear Regression)和逻辑回归(Logistic Regression )(Regression)的应用过程。


线性回归(Regression)(Linear Regression)先通过训练集训练出θ,在通过测试集计算平方误差。对于分类的逻辑回归(Logistic Regression )(Regression)还有另一种形式的测试度量可能更易于理解:叫做“错误分类”又叫“0/1分类错误”0:代表预测分类错误,1:代表预测分类正确。
模型选择和训练、验证、测试集
模型选择问题
你需要选择一个什么样的多项式(或者说选择那些特征)来拟合数据,这类问题叫模型选择。
假如你现在要选择能最好拟合数据的多项式次数(用d表示)
选择一个模型时,我们可以先选择多种模型来训练,最终比较他们的测试误差(test error),选择最小的。但这样却不能很公平的进行评估,因为越高次的模型,对测试集的拟合(d)效果可能很好但很有可能出现过拟合(Overfitting)现象(即范化能力差)。因为我们用测试集拟合得到的参数,再用它在测试集选择多项式的次数,就不公平了。

未解决这一不公平评估的问题,我们不把数据分成两部分,我们把它分成3部分:第一部分和之前一样叫训练集;第二部分叫交叉验证(Cross validation)集(简记为cv);第三部分叫测试集。典型的比例为6:2:2。

因此当我们进行模型选择时,我们要用验证集(validation set)(或交叉验证(Cross validation)集)来选择模型。具体地说就是首先选取第一种假设(Hypothesis)。我们不用测试集去测试,而是用(交叉)验证集(validation set)来测试,选则交叉验证(Cross validation)误差最小的模型;然后用测试集来评估选择的模型的泛化(Generalization)误差。

诊断偏差(Bias 偏置 )与方差
当你运行一个学习算法时,如果结果表现的不理想,那么很可能是两个原因:偏差(Bias 偏置 )或方差比较大。换句话说就是,要么欠拟合(Underfitting),要么过拟合(Overfitting)。
通过观察判断是偏差(Bias 偏置 )还是方差的问题
这对如何改进算法很重要。
下图:粉色的线表训练误差(Training error) 随着d的增加逐渐减小(可能为0);红色的线表交叉验证(Cross validation)误差:随着d先减后增(因为如果d太大就过拟合(Overfitting)了)
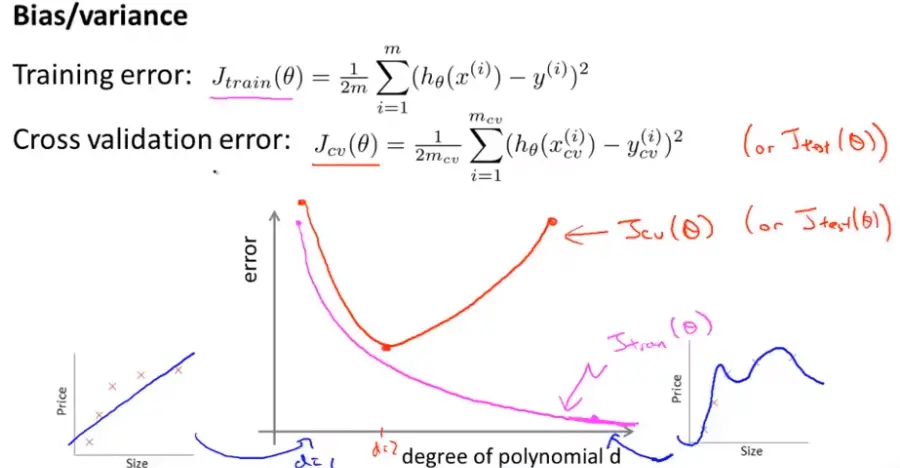
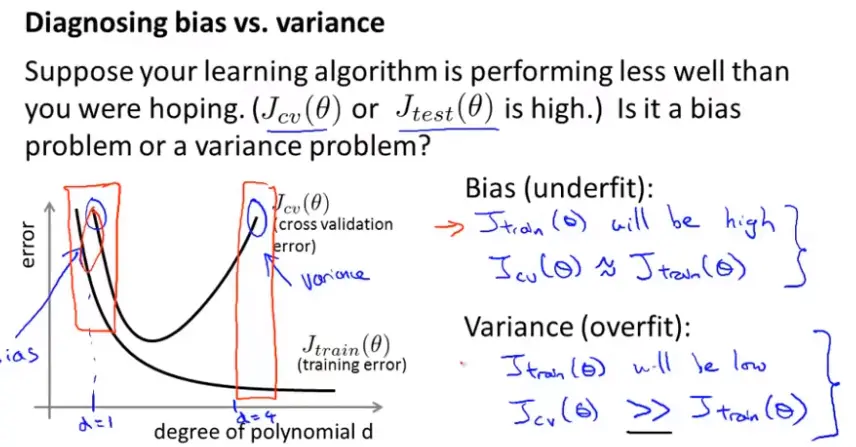
下图,说明如果d很小,对应的是高偏差(Bias 偏置 ),此时训练误差(Training error)和验证误差都很大;(欠拟合(Underfitting))
而如果d很大,对应的是高方差(次方高),此时验证误差远远大于训练误差(Training error);(过拟合(Overfitting))
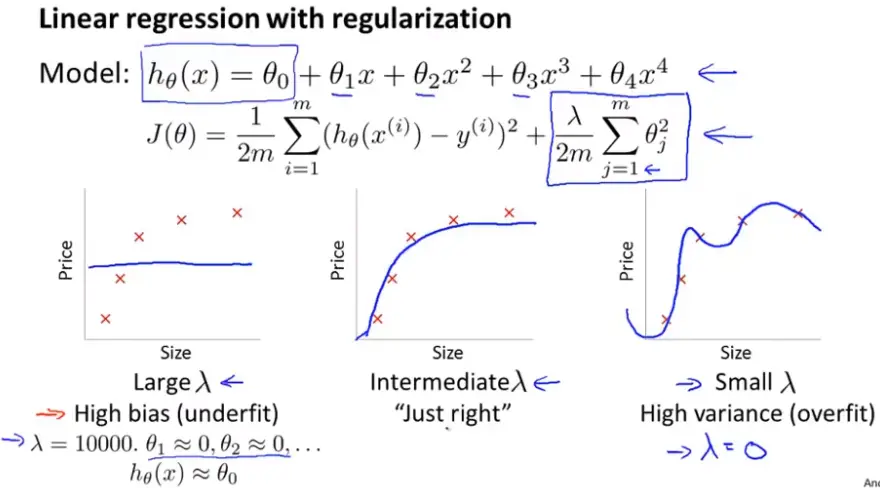
正则化(Regularization)和偏差(Bias 偏置 )、方差
如何选择正则化(Regularization)参数
自动选择
定义J_train(θ)为训练集的平方误差之和,不考虑正则项;相似的定义J_cv(θ)和J_test(θ)

手动选择
先不考虑正则化(Regularization),去不同的λ值一个一个试,最小化代价(cost)函数确定θ然后用交叉验证(Cross validation)集来评价(即算出每组θ在验证集(validation set)上的平均平方误差),最后用测试集测试向量θ的泛化(Generalization)能力。

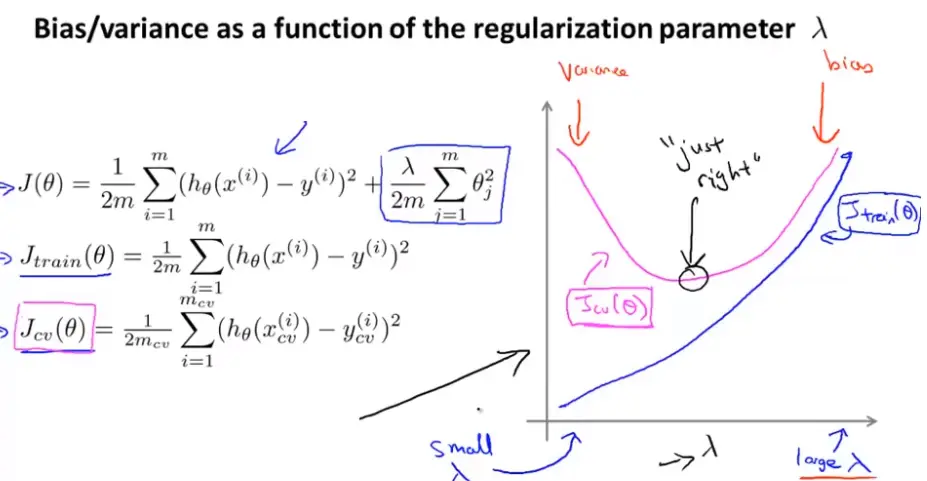
改变λ验证误差和训练误差(Training error)会怎么变?
如下图所示,如果λ很大则说明此时你可能连训练集拟合的不好出现高偏差(Bias 偏置 ),因此J_train(θ)很大;相反如果λ很小,则此时你可以用高阶的很好的拟合训练集,因此J_train(θ)很小;对于交叉验证(Cross validation)集,λ无论很大或者很小时,J_cv(θ)都很大。这里的图(包括下面的)都假设(Hypothesis)的过于简单,真实的数据的线可能比下图更杂乱,会有更多噪音点
学习曲线
查看你的学习算法执行是否一切正常或者你想改进你的算法的表现。可以用来判断是否处于高偏差(Bias 偏置 )或者高方差或者二者都有的问题。
画出学习曲线之前,先画出J_train(θ)和J_cv(θ)关于训练样本数的曲线。我们通常要人为的减小我们用的训练样本的数量。对J_train(θ):当训练样本很小的时候(1,2,3)能够拟合的很好(甚至可以拟合的天衣无缝)随着样本数越来越多,拟合就显得有些"吃力"了。对J_cv(θ):当样本很少时,泛化(Generalization)能力不会很好,样本越多,越能得到更好的泛化(Generalization)表现。因此,如下图所示。
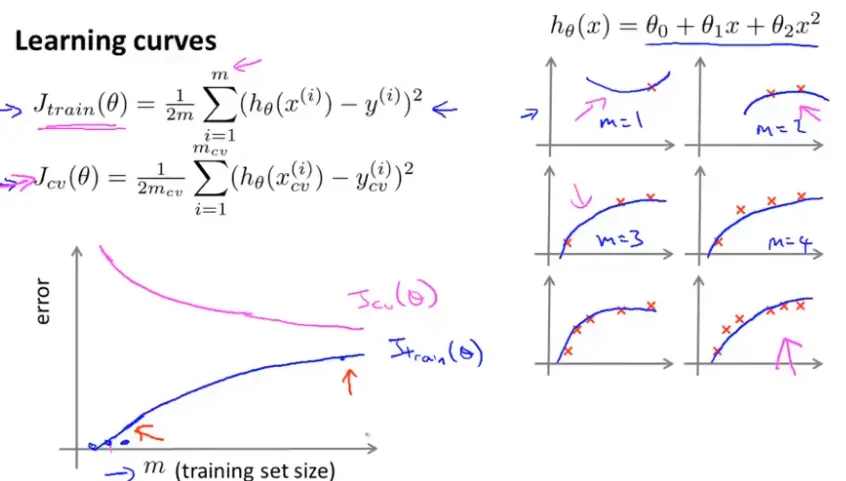
高偏差(Bias 偏置 )的情况
如下图,结论:如果一个学习算法有高偏差(Bias 偏置 ),随着训练样本的增加,交叉验证(Cross validation)误差不会有明显的下降;如果学习算法处于高偏差(Bias 偏置 )的情况时,给它再多的训练样本都是无用的(不能让两个误差减小多少)这个可以用来判断我们的学习算法是否处于高偏差(Bias 偏置 )。
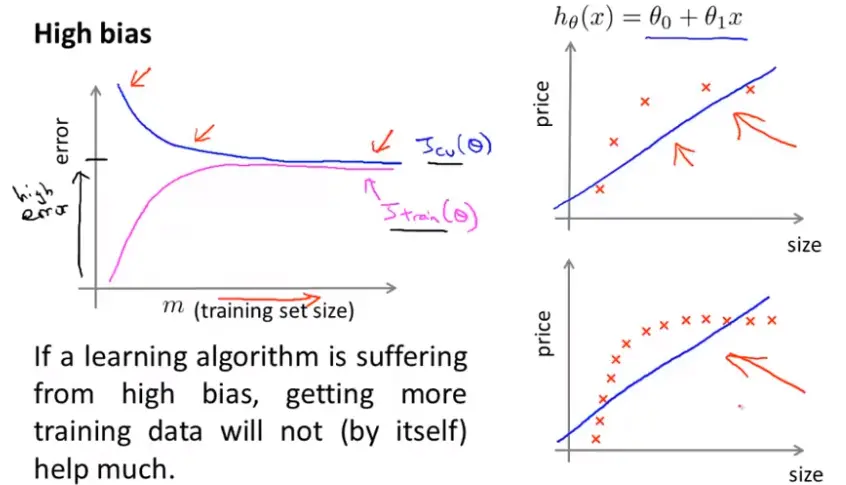
高方差的情况
如下图,当训练样本逐渐增多,也不好控制每个都能拟合,因此训练误差(Training error)越来越大但不会很大;由于算法处于高方差的情况即过拟合(Overfitting),所以它的交叉验证(Cross validation)误差会一直较大。结论:高方差时,两条曲线相差很大。但可以推测当样本越来越多的时候,两者在慢慢靠近,因此,增加训练样本量对高方差的算法改进有帮助。
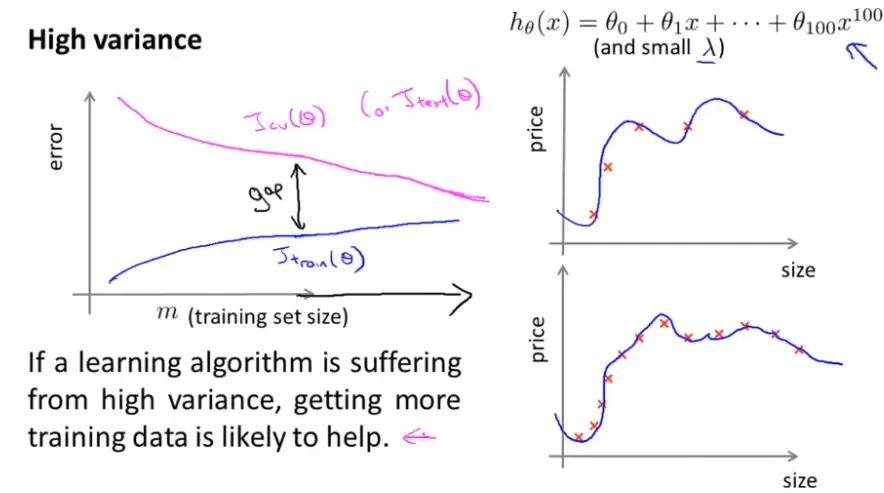
当我们想要改进我们的学习算法时,通常绘画出学习曲线先来判断
以上提到的东西怎么帮助我们弄清取那些方法有助于改进?
回到最初的例子,下图中改进的方法有:
1.收集更多的训练样本(有助于解决高方差的情况);
2.减少特征数量(同样的对高方差的情况有效);
3.增加特征数量(通常对高偏差(Bias 偏置 )有效);
4.增加多项式特征(同样通常对高偏差(Bias 偏置 )有效);
5.减小λ值(修正高偏差(Bias 偏置 ))
6.增加λ值(修正高方差)
为神经网络选择结构或连接形式
当你在用神经网络进行拟合时,一种选择是较简单的网络模型(只有少量隐藏层(Hidden layer)单元)而这样的神经网络容易出现欠拟合(Underfitting)的情况,优势是计算量小。另一种是较大型的神经网络结构,隐藏单元(hidden unit)数较多或者有很多隐藏层(Hidden layer),而这种参数比较多容易出现过拟合(Overfitting)现象,劣势是,当网络有大量神经元时,计算量很大(但通常来讲也不是问题)最主要的问题是过拟合(Overfitting)现象。性能较好,如果出现过拟合(Overfitting)可以用正则化(Regularization)修正。你还需要确定隐藏层(Hidden layer)数,通常选择使用一个隐藏层(Hidden layer)是比较合理的默认选项。当然如果想尝试其他层数的,可以将数据分成三份,然后训练不同层隐藏函数的模型,最后比较那个网络在验证集(validation set)上效果最理想。
机器学习(machine learning)系统设计
确定执行的优先级
以垃圾邮件分类为例,如何通过有监督学习(Supervised learning)构建一个分类器(Classifier),区分是否为垃圾邮件。
首先,需要要想的是如何表示邮件的特征向量(Feature vector)x,通过x和分类标签y训练一个分类器(Classifier)。
其中一种选择邮件特征向量(Feature vector)的方法是,我们可以提出 一个包含很多单词的列表 ,通过这些单词来区分。

如何在有限的时间下让分类器(Classifier)具有高准确率(Precision)和低错误率(Error rate)?
你可能会觉得收集足够多的样本训练可能可以做到,(但由上面的知识可知,训练集多有时候有用,但大多数时候是没有用的);
你还可能想到用更复杂的特征变量来描述邮件,等等一系列方法。

如何更有系统的选择你想到的不同的方法来改进算法呢?
误差分析
误差分析是一种手动的去检查所出现的失误的过程。在交叉验证(Cross validation)集上做误差分析,而不是测试集!
拿到一个数据集(Dataset)时,先快速粗暴的写出一个算法实现功能,可以很快找出这个分类算法最难区分的样本类型和不足所在。不要花费大量时间在构造上。训练验证,画出它的学习曲线后判断是否需要更多数据或者更多特征,避免过早优化。除了画学习曲线外,还可以进行误差分析。
以垃圾分类为例,我们可以通过观察交叉验证(Cross validation)集中被错误分类的邮件有什么共同的特征来构建新的特征更好的改进算法,使结果更准确。

在改进算法时另外一个技巧:保证有一种数值估计的方法。(即一个数值最终能告诉你算法好坏)
下图是一个特定例子,交叉验证(Cross validation)错误率(Error rate)即为数值估计
如果选择词干提取软件它的缺点是会把意义完全不同但拼写很像的词分在一起。

不对称性分类的误差估计
偏斜类
比如二元分类的数据中,得癌症的即y=1的数量远远小于y=0的数量:这个时候,如果让预测值一直等于数量多的那个值,这时候错误率(Error rate)是很小的,但效果绝对是差的。
当你的数据是偏斜类是,用分类准确率(Precision)作为评估标准就不合适了。你可能得到了一个很高的精确率或者很低的错误率(Error rate),但我们并不知道这个改进是否真正提升了模型的质量。这时,我们就需要新的数值来进行估计:查准率和召回率(Recall)。
下图中表格的解释:如果预测为1而本身就是1,则叫做真阳性;如果预测为0而本身就是0,叫做真阴性;预测为1而实际是0,则叫做假阳性;预测为0而实际是1,叫做假阴性。
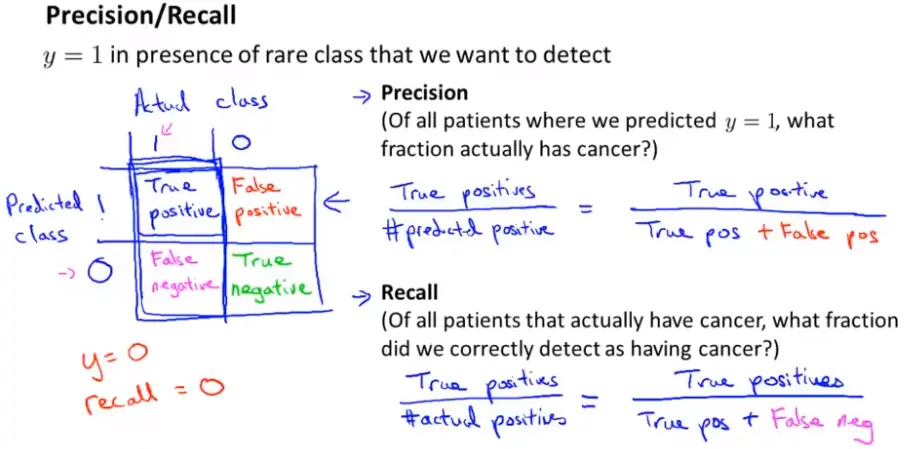
查准率=真阳性/预测为阳性的数量=真阳性/(真阳性+假阳性)
召回率(Recall)=真阳性/预测为阳性的数量=真阳性/(真阳性+假阴性)
有了召回率(Recall),如果我们预测y一直等于0,这时recall率就会为0,将会被我们可以快速判断这不是一个好的模型。另外我们希望较少的设为y=1,比如癌症的分类,我们希望的是患癌症非常少。
查准率与召回率(Recall)的权衡
继续以癌症为例,患癌症y=1;如果线性回归(Regression)(Linear Regression)的阈值(Threshold)为0.5,似乎不太合理,因为你只有50%的把握就判断病人患了癌症,所以这时的查准率是很低的,改为0.9,这时就比较合理了,这时就会有一个很高的查准率和一个较低的召回率(Recall)。
假设(Hypothesis)我们现在希望避免假阴性,这时我们会将阈值(Threshold)设的比较低,如0.3(有点宁可错杀100也不放过1个的意思)这时我们会得到一个较高的召回率(Recall)和一个较低的查准率。
对于大多数回归(Regression)问题两者的平衡,可根据下图中的某条曲线来权衡

假设(Hypothesis)我们有几个不同的模型,我们怎么比较他们的查准率和召回率(Recall)?评估度量值很重要!
取两者的平均不是一个好的决定:因为对于两种极端情况是不可取的。通过下图中的F判断,F公式会考虑一部分两者的平均值但它会给两者中较低的值更高的权重。

如果希望自动的选择临界值(即阈值(Threshold)),一个比较理想的方法就是试试不同的临界值,然后评估这些临界值,在交叉验证(Cross validation)集上进行测试,然后选择能在交叉验证(Cross validation)集上得到最高的F值得临界值。
机器学习(machine learning)数据

对于上图提到的容易混淆的词的分类问题中,假设(Hypothesis)它有足够多的特征能够精准的预测;在假设(Hypothesis)我们预测房价的例子中,如果只给你一个房子的大小作为输入(input),即使是一个人类专家都不能只根据这一个特征很好的预测出准确的价格。首先想一个人类专家看到这些特征值(eigenvalue)能否很好的预测,其次再考虑我们是否能得到一组庞大的数据集(Dataset),并在这个训练集上训练出一个有很多参数的学习算法。如果这两者都能做到,那么也可以得到一个较好的学习算法。

假设(Hypothesis)我们有足够多的特征来预测y,这时我们会用一个很多参数的回归(Regression)或逻辑回归(Logistic Regression )(Regression)算法,当然更多的是有很多个隐藏神经元的神经网络这些强大的算法,再加上很大量的训练数据(远远大于参数的数量)来训练,这时不太可能出现过拟合(Overfitting)的现象。并且,很多的参数保证了不会出现高偏差(Bias 偏置 ),很多的数据保证了不会出现高方差,这样就得到了一个低偏差(Bias 偏置 )低方差的学习算法。
实例ex5
要求
- 通过正则线性回归(Regression)(Linear Regression),利用水库的水位的变化预测从大坝流(stream)出的水量。
- 通过调试学习算法来学习偏差(Bias 偏置 )和方差的对于模型的影响。
单变量线性回归(Regression)(Linear Regression)
# 需要先对一个水库的流(stream)出水量以及水库水位进行正则化(Regularization)线性回归(Regression)(Linear Regression)。然后将会探讨方差-偏差(Bias 偏置 )的问题
# 数据可视化
import numpy as np
import scipy.io as sio
import scipy.optimize as opt
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = sio.loadmat('E:/Python/machine learning/data/ex5data1.mat')
X, y, Xval, yval, Xtest, ytest = map(np.ravel,[data['X'], data['y'], data['Xval'], data['yval'], data['Xtest'], data['ytest']])
print(X.shape, y.shape, Xval.shape, yval.shape, Xtest.shape, ytest.shape)
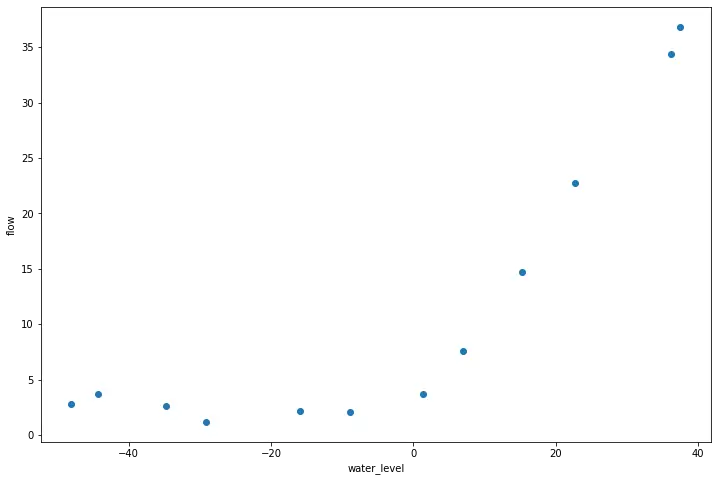
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(X, y)
ax.set_xlabel('water_level')
ax.set_ylabel('flow')
plt.show()(12,) (12,) (21,) (21,) (21,) (21,)
# 正则化(Regularization)线性回归(Regression)(Linear Regression),下面完成计算正则化(Regularization)线性回归(Regression)(Linear Regression)代价(cost)函数的代码
X, Xval, Xtest = [np.insert(x.reshape(x.shape[0], 1), 0, np.ones(x.shape[0]), axis=1) for x in (X, Xval, Xtest)]
# 代价(cost)函数
def cost(theta, X, y):
"""
X: R(m*n), m records, n features
y: R(m)
theta : R(n), linear regression parameters
"""
m = X.shape[0]
inner = X @ theta - y # R(m*1)
# 1*m @ m*1 = 1*1 in matrix multiplication
# but you know numpy didn't do transpose in 1d array, so here is just a
# vector inner product to itselves
square_sum = inner.T @ inner
cost = square_sum / (2 * m)
return cost
#正则项
def costReg(theta, X, y, reg = 1):
m = X.shape[0]
regularized_term = (reg / (2 * m)) * np.power(theta[1:], 2).sum()
return cost(theta, X, y) + regularized_term
# theta初始值为[1,1],输出应该为303.993
theta = np.ones(X.shape[1])
print(costReg(theta, X, y, 1))303.9931922202643
def gradient(theta, X, y):
m = X.shape[0]
inner = X.T @ (X @ theta - y) # (m,n).T @ (m, 1) -> (n, 1)
return inner / m
# # 正则化(Regularization)线性回归(Regression)(Linear Regression)的梯度(gradient)
def gradientReg(theta, X, y, reg):
m = X.shape[0]
regularized_term = theta.copy() # same shape as theta
regularized_term[0] = 0 # don't regularize intercept theta
regularized_term = (reg / m) * regularized_term
return gradient(theta, X, y) + regularized_term
#设定θ初始值为[1,1],输出应该为[-15.30, 598.250]
print(gradientReg(theta, X, y, 1))[-15.30301567 598.25074417]
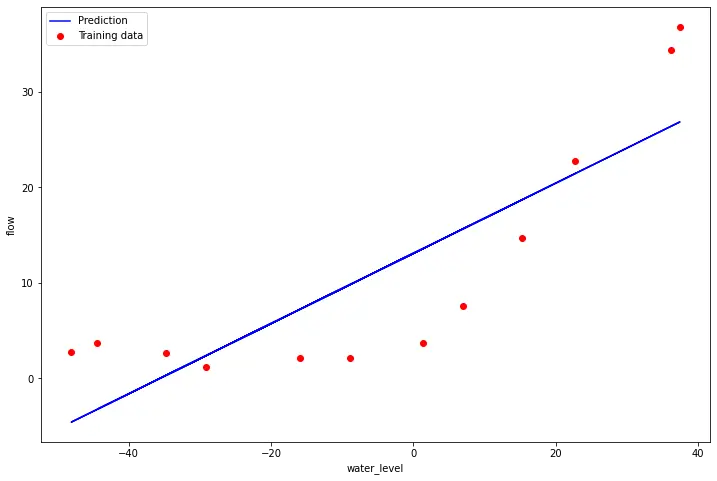
# 拟合线性回归(Regression)(Linear Regression)
# 调用工具库找到最优解,令λ=0 由于现在训练的是2维的θ,所以正则化(Regularization)不会对这种低维的θ有很大的帮助。
theta = np.ones(X.shape[1])
final_theta = opt.minimize(fun=costReg, x0=theta, args=(X, y, 0), method='TNC', jac=gradientReg, options={'disp': True}).x
print(final_theta)
# 画出拟合曲线
b = final_theta[0] # intercept
m = final_theta[1] # slope
fig, ax = plt.subplots(figsize=(12,8))
plt.scatter(X[:,1], y, c='r', label="Training data")
plt.plot(X[:, 1], X[:, 1]*m + b, c='b', label="Prediction")
ax.set_xlabel('water_level')
ax.set_ylabel('flow')
ax.legend()
plt.show()[13.08790362 0.36777923]
# 画学习曲线
# 线性回归(Regression)(Linear Regression)
def linear_regression(X, y, l=1):
"""linear regression
args:
X: feature matrix, (m, n+1) # with incercept x0=1
y: target vector, (m, )
l: lambda constant for regularization
return: trained parameters
"""
# init theta
theta = np.ones(X.shape[1])
# train it
res = opt.minimize(fun=costReg,
x0=theta,
args=(X, y, l),
method='TNC',
jac=gradientReg,
options={'disp': True})
return res
# 训练误差(Training error)与交叉验证(Cross validation)误差
training_cost, cv_cost = [], []
m = X.shape[0]
for i in range(1, m+1):
res = linear_regression(X[:i, :], y[:i], 0)
tc = costReg(res.x, X[:i, :], y[:i], 0)
cv = costReg(res.x, Xval, yval, 0)
training_cost.append(tc)
cv_cost.append(cv)
fig, ax = plt.subplots(figsize=(12,8))
plt.plot(np.arange(1, m+1), training_cost, label='training cost')
plt.plot(np.arange(1, m+1), cv_cost, label='cv cost')
plt.legend()
plt.show()
# 这个模型拟合不太好, 欠拟合(Underfitting)了 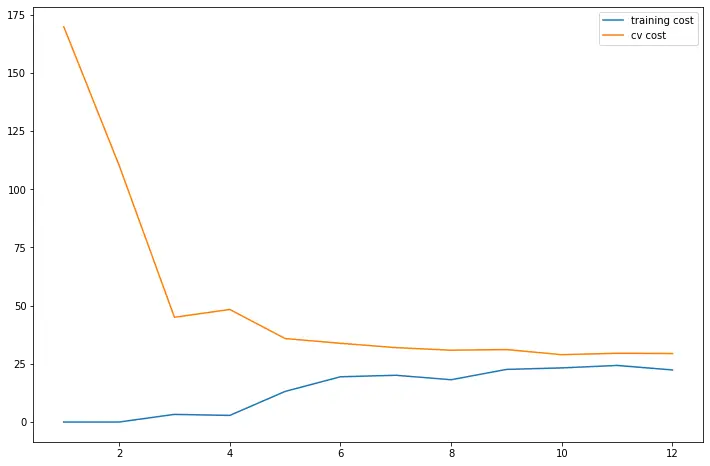
多变量线性回归(Regression)(Linear Regression)
# 多项式回归(Regression)
#输入(input)原始X,和幂的次数p,返回X的1到p次幂
def poly_features(x, power, as_ndarray=False):
data = {'f{}'.format(i): np.power(x, i) for i in range(1, power + 1)}
df = pd.DataFrame(data)
return df.values if as_ndarray else df
data = sio.loadmat('E:/Python/machine learning/data/ex5data1.mat')
X, y, Xval, yval, Xtest, ytest = map(np.ravel,[data['X'], data['y'], data['Xval'], data['yval'], data['Xtest'], data['ytest']])
print(poly_features(X, power=3))f1 f2 f3 0 -15.936758 253.980260 -4047.621971 1 -29.152979 849.896197 -24777.006175 2 36.189549 1309.683430 47396.852168 3 37.492187 1405.664111 52701.422173 4 -48.058829 2309.651088 -110999.127750 5 -8.941458 79.949670 -714.866612 6 15.307793 234.328523 3587.052500 7 -34.706266 1204.524887 -41804.560890 8 1.389154 1.929750 2.680720 9 -44.383760 1969.918139 -87432.373590 10 7.013502 49.189211 344.988637 11 22.762749 518.142738 11794.353058
def normalize_feature(df):
"""Applies function along input axis(default 0) of DataFrame."""
return df.apply(lambda column: (column - column.mean()) / column.std())
def prepare_poly_data(*args, power):
"""
args: keep feeding in X, Xval, or Xtest
will return in the same order
"""
def prepare(x):
# expand feature
df = poly_features(x, power=power)
# normalization
ndarr = normalize_feature(df).values
# add intercept term
return np.insert(ndarr, 0, np.ones(ndarr.shape[0]), axis=1)
return [prepare(x) for x in args]
X_poly, Xval_poly, Xtest_poly= prepare_poly_data(X, Xval, Xtest, power=8)
print(X_poly[:3, :])[[ 1.00000000e+00 -3.62140776e-01 -7.55086688e-01 1.82225876e-01 -7.06189908e-01 3.06617917e-01 -5.90877673e-01 3.44515797e-01 -5.08481165e-01] [ 1.00000000e+00 -8.03204845e-01 1.25825266e-03 -2.47936991e-01 -3.27023420e-01 9.33963187e-02 -4.35817606e-01 2.55416116e-01 -4.48912493e-01] [ 1.00000000e+00 1.37746700e+00 5.84826715e-01 1.24976856e+00 2.45311974e-01 9.78359696e-01 -1.21556976e-02 7.56568484e-01 -1.70352114e-01]]
# 画出学习曲线
def plot_learning_curve(X, Xinit, y, Xval, yval, l=0):
training_cost, cv_cost = [], []
m = X.shape[0]
for i in range(1, m + 1):
# regularization applies here for fitting parameters
res = linear_regression(X[:i, :], y[:i], l=l)
# remember, when you compute the cost here, you are computing
# non-regularized cost. Regularization is used to fit parameters only
tc = cost(res.x, X[:i, :], y[:i])
cv = cost(res.x, Xval, yval)
training_cost.append(tc)
cv_cost.append(cv)
fig, ax = plt.subplots(2, 1, figsize=(12, 12))
ax[0].plot(np.arange(1, m + 1), training_cost, label='training cost')
ax[0].plot(np.arange(1, m + 1), cv_cost, label='cv cost')
ax[0].legend()
fitx = np.linspace(-50, 50, 100)
fitxtmp = prepare_poly_data(fitx, power=8)
fity = np.dot(prepare_poly_data(fitx, power=8)[0], linear_regression(X, y, l).x.T)
ax[1].plot(fitx, fity, c='r', label='fitcurve')
ax[1].scatter(Xinit, y, c='b', label='initial_Xy')
ax[1].set_xlabel('water_level')
ax[1].set_ylabel('flow')
plot_learning_curve(X_poly, X, y, Xval_poly, yval, l=0)
plt.show()
# 看到训练的代价(cost)太低了,不真实,过拟合(Overfitting)了。 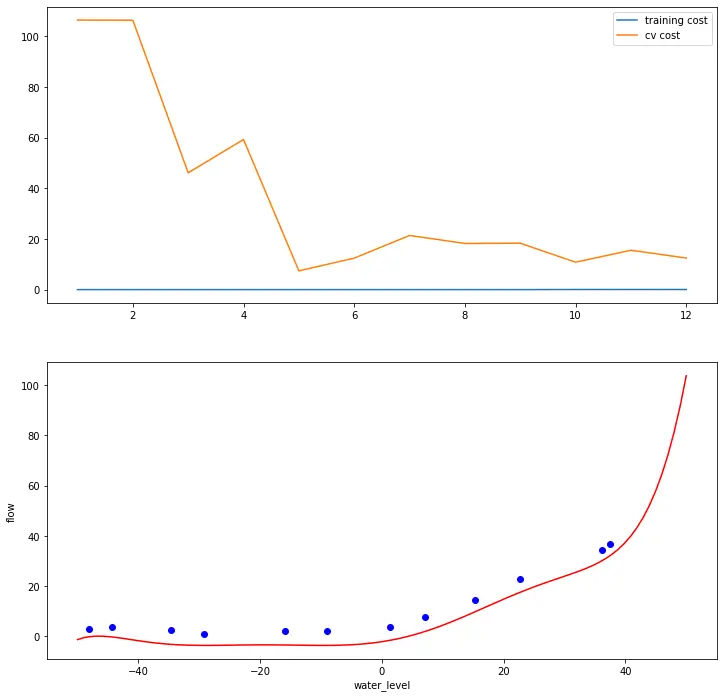
# 调整正则化(Regularization)系数λ=1
plot_learning_curve(X_poly, X, y, Xval_poly, yval, l=1)
plt.show()
# 训练代价(cost)不再是0了 减轻过拟合(Overfitting) 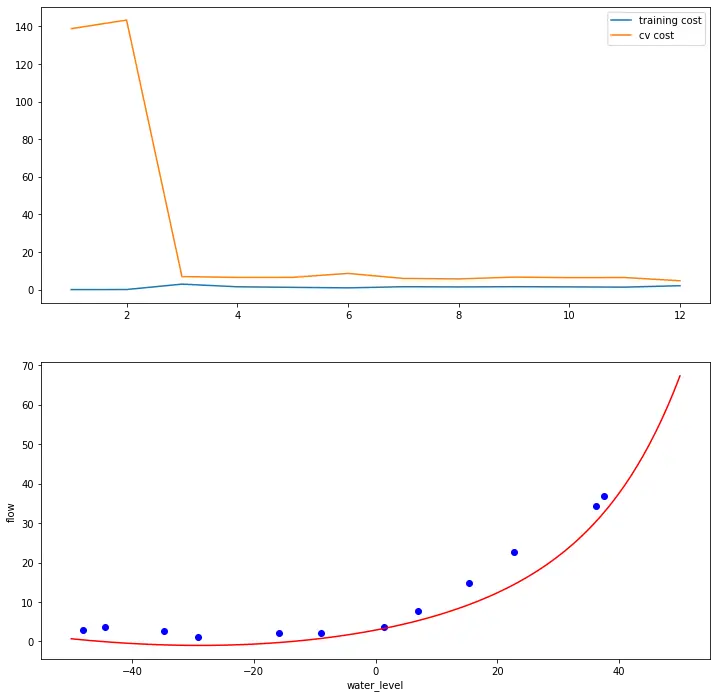
#令λ=100
plot_learning_curve(X_poly, X, y, Xval_poly, yval, l=100)
plt.show()
# 太多正则化(Regularization)惩罚太多,变成 欠拟合(Underfitting)状态 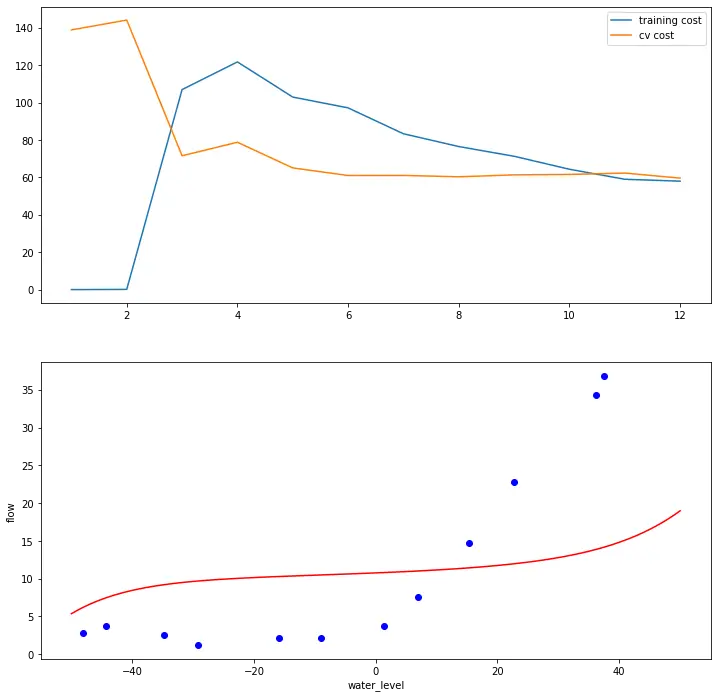
# 找最佳的λ取值
l_candidate = [0, 0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1, 3, 10]
training_cost, cv_cost = [], []
for l in l_candidate:
res = linear_regression(X_poly, y, l)
tc = cost(res.x, X_poly, y)
cv = cost(res.x, Xval_poly, yval)
training_cost.append(tc)
cv_cost.append(cv)
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(l_candidate, training_cost, label='training')
ax.plot(l_candidate, cv_cost, label='cross validation')
plt.legend()
plt.xlabel('lambda')
plt.ylabel('cost')
plt.show()
# 最小值在4左右,对应的λ的值约为1 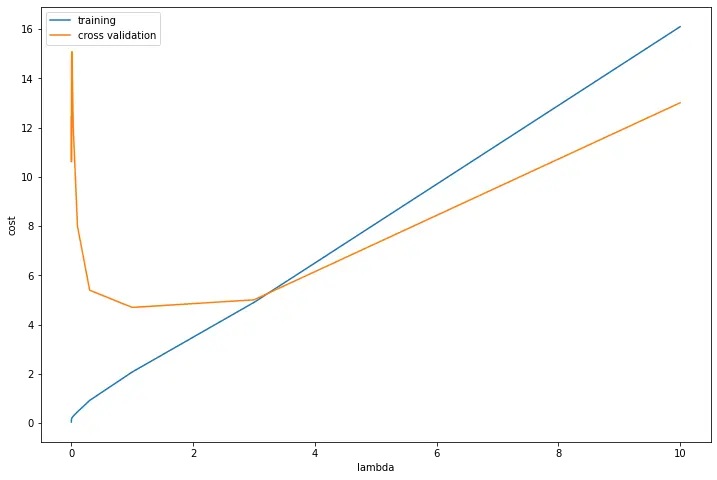
# use test data to compute the cost计算测试集上的误差
for l in l_candidate:
theta = linear_regression(X_poly, y, l).x
print('test cost(l={}) = {}'.format(l, cost(theta, Xtest_poly, ytest)))
# 调参(Parameter tuning)后,λ=0.3是最优选择,这个时候测试代价(cost)最小test cost(l=0) = 10.055426362410126 test cost(l=0.001) = 11.001927632262907 test cost(l=0.003) = 11.26474655167747 test cost(l=0.01) = 10.880780731411715 test cost(l=0.03) = 10.022100517865269 test cost(l=0.1) = 8.63190793331871 test cost(l=0.3) = 7.3366077892272585 test cost(l=1) = 7.466283751156784 test cost(l=3) = 11.643941860536106 test cost(l=10) = 27.715080254176254
版权声明:本文为博主-小透明-原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/qq_54809548/article/details/121303911