
🔥博客主页:真的睡不醒
🚀系列专栏:深度学习环境搭建、环境配置问题解决、自然语言处理、语音信号处理、项目开发
💘每日语录:眼里有不朽的光芒 心里有永恒的希望。
🎉感谢大家点赞👍收藏⭐指正✍️

前言
百度开放平台允许开发者访问和利用百度的各种服务和功能,包括语音识别、人脸识别、文字识别、自然语言处理等等。这些API能够满足我们绝大部分需求,来供我们学习和使用。本文就OCR文字识别为例,详细介绍新手小白如何调用百度开放平台的API。
前期准备工作
1、注册一个百度AI开放平台的账号
网址:百度AI开放平台-全球领先的人工智能服务平台 (baidu.com)
2、编译器:Pycharm
搜索 OCR文字识别,点击立即使用。

进入到OCR文字识别的界面,点击“去领取”。
百度开放平台是可以免费试用的,一个月可以调用几千次,足够我们用来学习和使用。
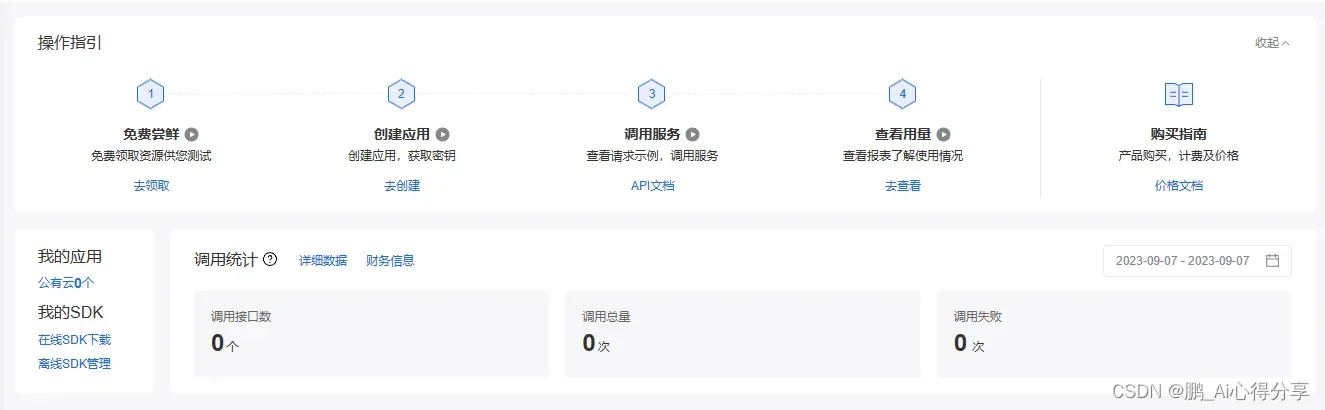
直接点击全部领取。
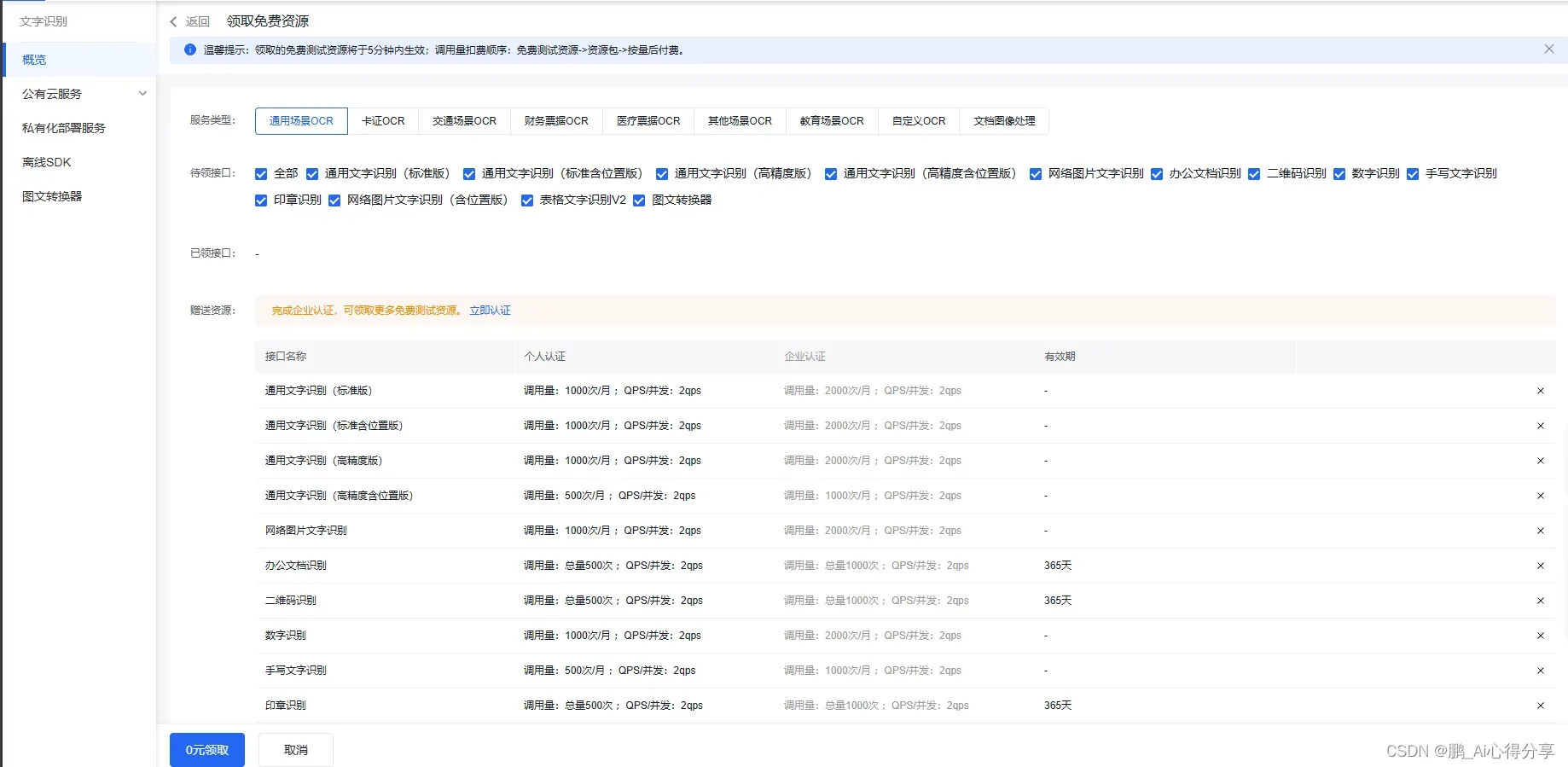
点击应用列表,进行创建应用(信息随便填,但也不要太离谱,SDK不要选择)
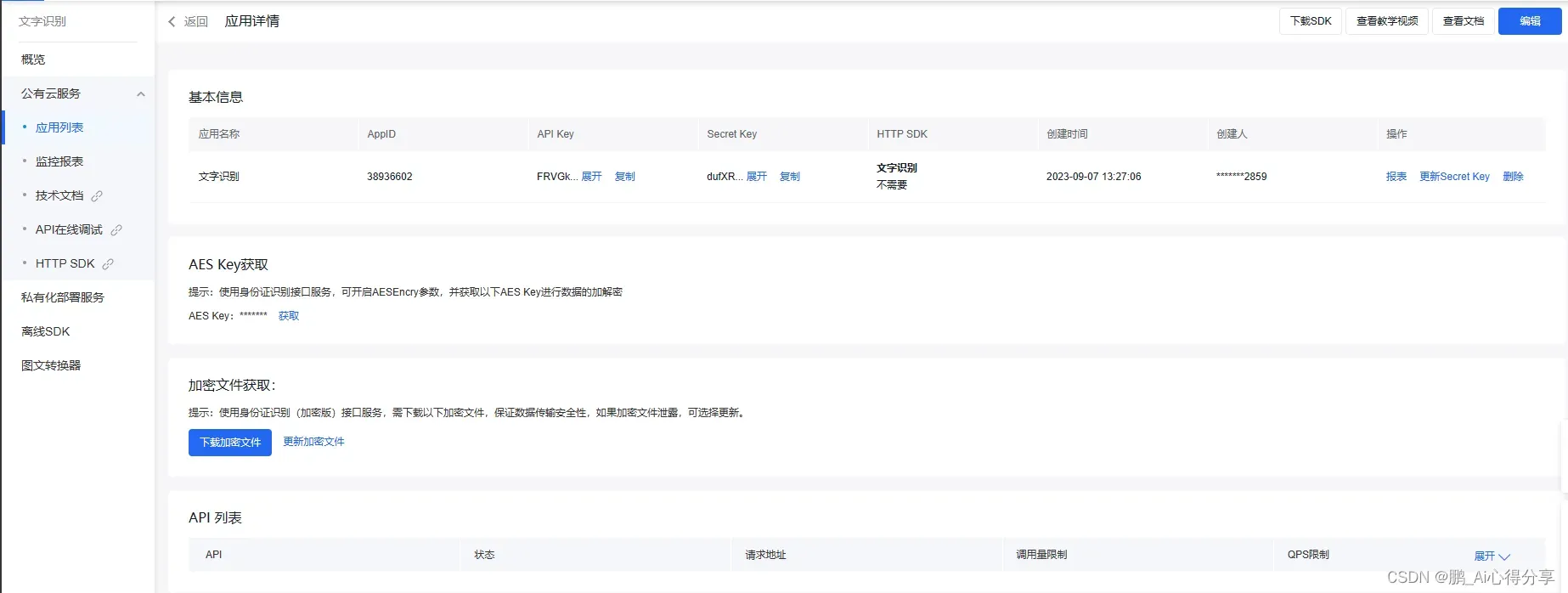
这里特别需要注意的是,你需要保管好API Key 和Secret Key,后边会使用到。
正式调用环节(仅需两步)
获取你的access_token
首先,我们获得access_token,具体的方法是通过百度的API文档中获得,很简单,上图!
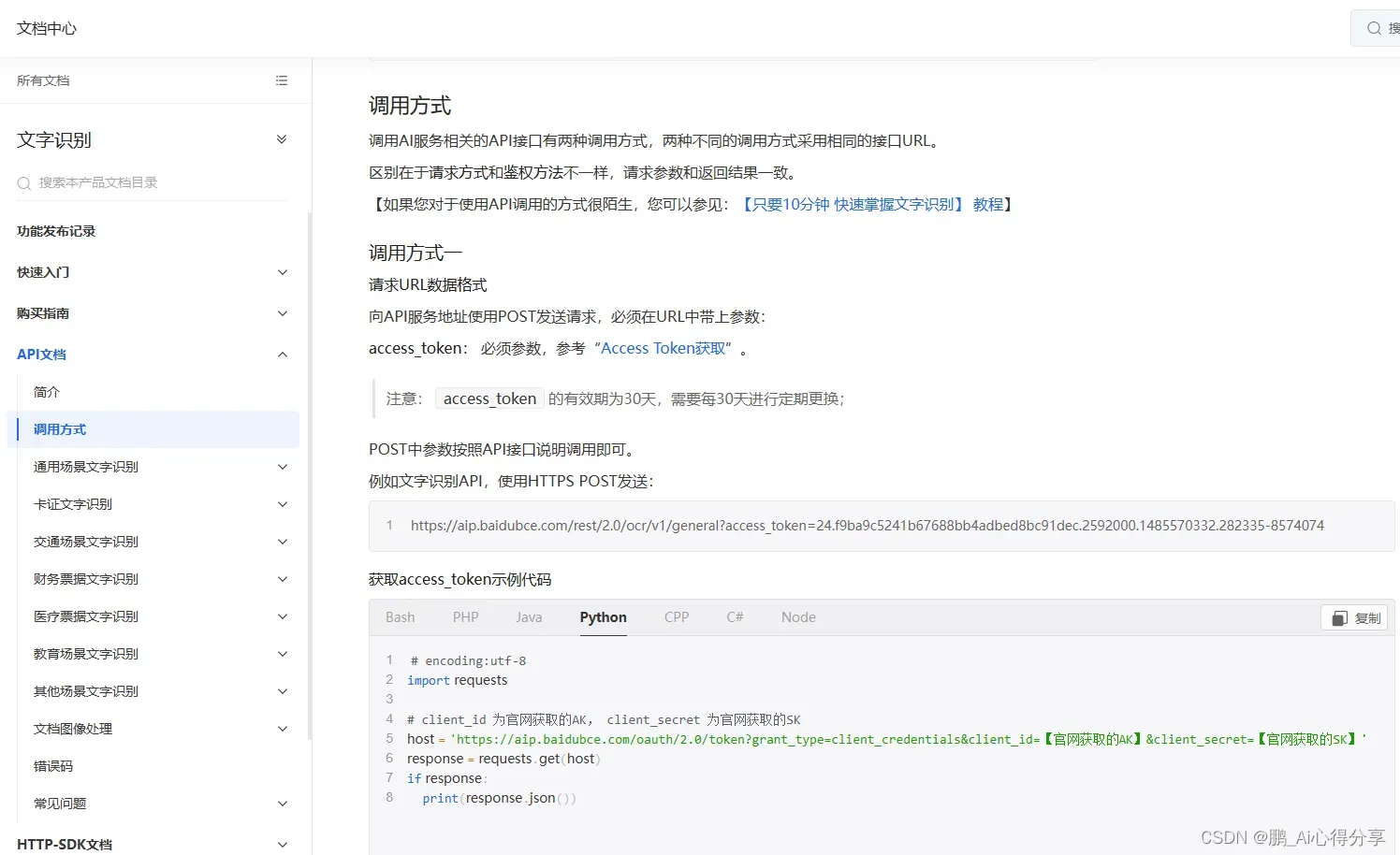
搜索文字识别,选择“调用方式这一栏”,可以看到,官方给出了多种语言用来获取access_token,这里我选择python。将代码复制到pycharm,并将你的API Key 和Secret Key分别替换掉host中的“【官网获取的AK】”和“【官网获取的SK】”,运行代码就可以拿到你的access_token了。
为了方便大家,这里直接附上代码。我对代码进行了部分修改,大家可以直接替换掉client_id和client_secret即可。
# encoding:utf-8
import requests
# 替换下面的【官网获取的AK】和【官网获取的SK】为你的实际API密钥和密钥
client_id = 'YOUR_CLIENT_ID'
client_secret = 'YOUR_CLIENT_SECRET'
# 构建获取访问令牌的URL
token_url = f'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={client_id}&client_secret={client_secret}'
# 发送请求获取访问令牌
response = requests.get(token_url)
# 检查响应状态码
if response.status_code == 200:
access_token = response.json()['access_token']
print(f"Access Token: {access_token}")
else:
print("Failed to obtain Access Token")
正式开始调用
随机选择一个文字识别场景,这里我选择了通用文字识别(高精度版本)。
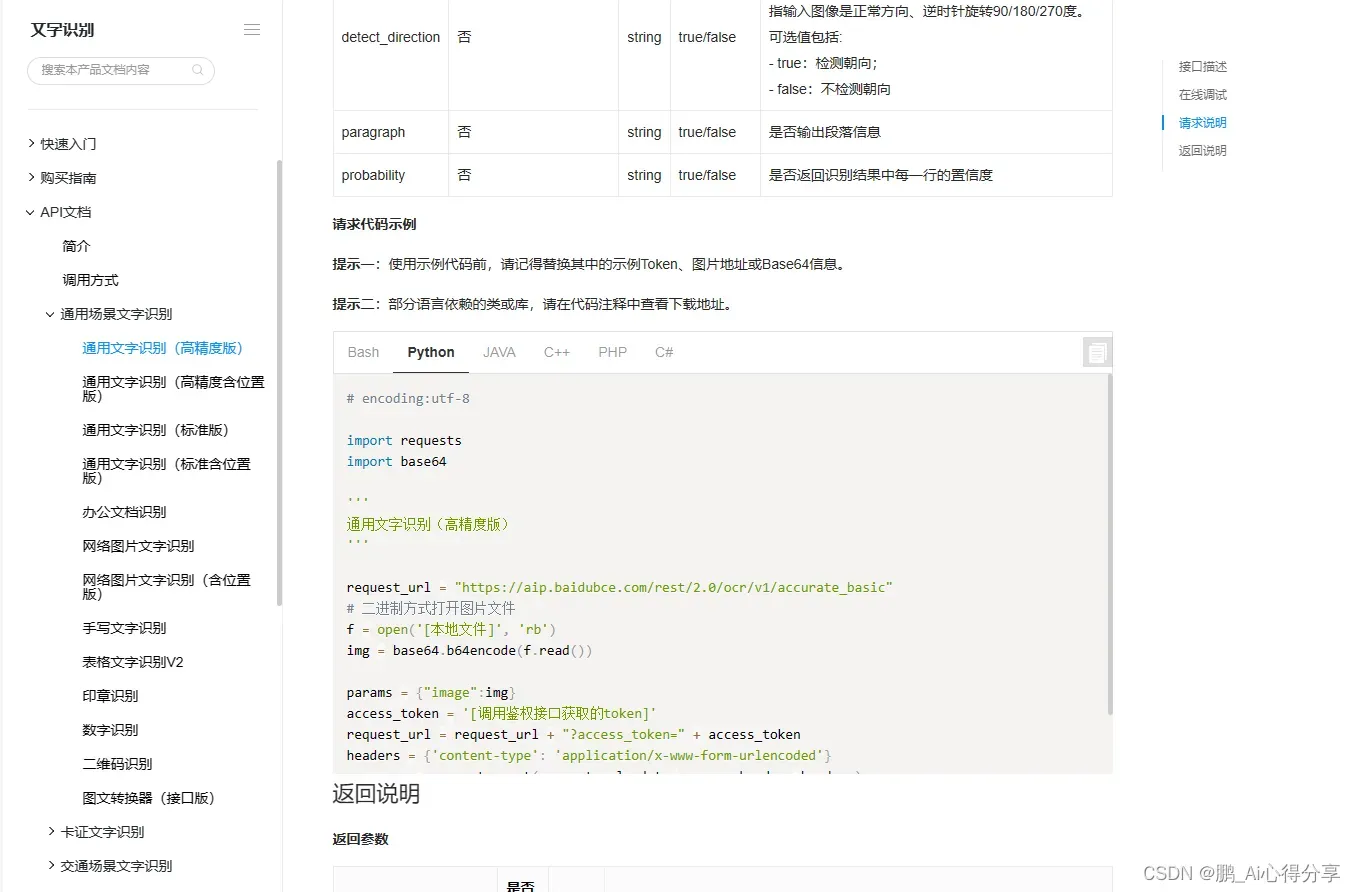
复制里边的代码,并将自己的access_token添加上去,就可以进行文字识别了!
测试
随机截取了一张图片,来测试一下效果如何。
部分结果展示:

可以看到效果还是非常好的。
经验之谈(点赞、收藏、关注、不迷路)
需要特别注意的是,我们获得到的 access_token 具有时效性,通常在30天后会失效,因此需要定期重新获取。并且,官方给的代码,我们每次需要识别图片的时候,都需要更改图片的途径,这样非常麻烦,为了一劳永逸,这里建议将代码进行打包封装。这样在我们的项目中,如果需要识别图片中的文字,只需要调用相应的函数就行了。这里我直接贴出封装后的代码,需要进行文字识别的时候只需要调用ocr_image()函数即可。
# coding=utf-8
import sys
import json
import base64
import requests
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
API_KEY = '你的API Key'
SECRET_KEY = '你的Secret Key'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取access token
"""
def fetch_token():
params = {'grant_type': 'client_credentials', 'client_id': API_KEY, 'client_secret': SECRET_KEY}
response = requests.post(TOKEN_URL, params=params)
result = response.json()
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
读取文件
"""
def read_file(image_path):
with open(image_path, 'rb') as f:
return f.read()
"""
调用远程服务
"""
def request(url, data):
response = requests.post(url, data=data.encode('utf-8'))
if response.status_code == 200:
return response.text
else:
print("Error response {}".format(response.status_code))
def ocr_image(image_path, access_token):
# 调用OCR服务
headers = {'Content-Type': 'application/x-www-form-urlencoded'}
with open(image_path, 'rb') as f:
image_data = f.read()
params = {'access_token': access_token, 'image': base64.b64encode(image_data)}
response = requests.post(OCR_URL, headers=headers, data=params)
# 解析OCR结果
result = ''
result_json = response.json()
for words_result in result_json["words_result"]:
result += words_result["words"] + '\n'
return result
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 调用文字识别服务
result = ocr_image(r"runs/detect/exp160/crops/plate/2.jpg", token)
# 打印文字
print(result)

看到这里,相信你已经能够掌握如何调用百度开放平台的API,关注我,后续会有更多的人工智能相关的保姆级教程。
文章出处登录后可见!