第一步:搜集数据集,由于我想做一个口罩识别的小demo,所以我的数据集是口罩,一共两类。
掩码数据集
链接:https://pan.baidu.com/s/1ow4mjnEmr41Xuuzyci8EaA?pwd=mr0v
提取码:mr0v
第二步:找一个yolo的模型,B站上有很多大佬。个人推荐这个大佬。他就有教程,可以跟着自己做,我写的是一些注意事项,自己遇到的。
Tensorflow2 搭建自己的yolo3目标检测平台(Bubbliiiing 深度学习 教程)_哔哩哔哩_bilibili
源代码下载
https://github.com/bubbliiiing/yolo3-tf2
喜欢的可以点个star噢。
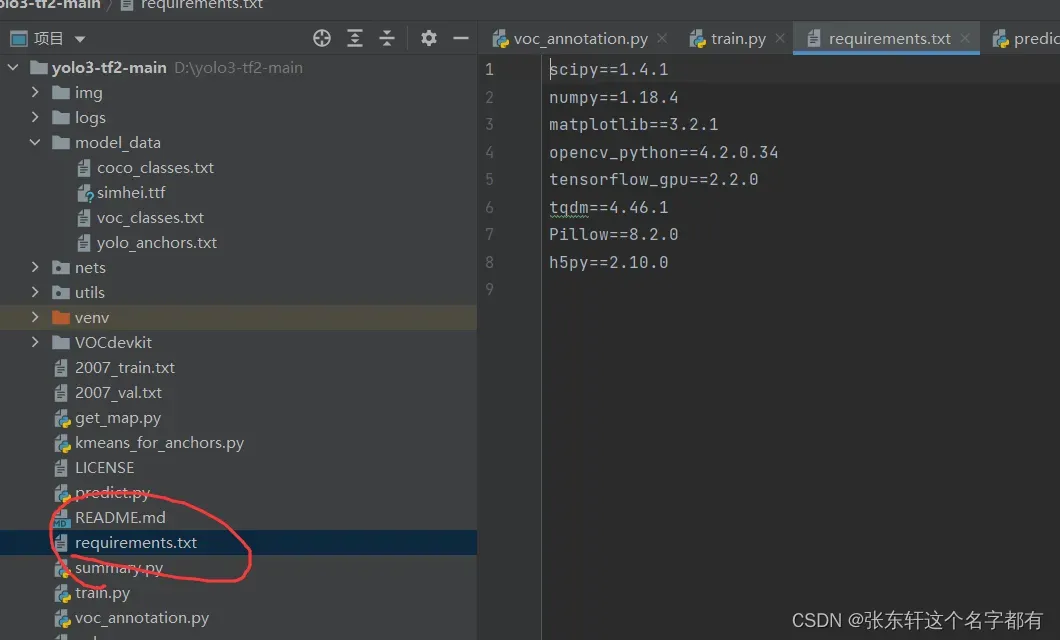
第三步:环境的配置,这个直接pip安装就可以。B站的大佬已经帮你找好环境了。 如果有环境安装的问题可以留言一起讨论。
第四步:训练模型,在这里有一些小的心得,B站的大佬用的voc数据集,我python基础不好,写不出对xml文件内容提取,所以就把我的数据集格式转变为voc的格式了。意思就是数据集重命名,这里有python现成的工具。代码如下
import os
path = "D:\\BaiduNetdiskDownload\\mask_dataset\\label_nomask"
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=515#设置图片编号从1开始
for file in filelist:#打印出所有图片原始的文件名
print(file)
for file in filelist: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] #文件名
filetype=os.path.splitext(file)[1] #文件扩展名
Newdir=os.path.join(path,str(count).zfill(6)+filetype) #用字符串函数zfill 以0补全所需位数
os.rename(Olddir,Newdir)#重命名
count += 1
"""
import os
path = 'E:/CSRNet-pytorch-master/data/original/shanghaitech/part_B_final/train_data/images'
num = 1
for file in os.listdir(path):
os.rename(os.path.join(path,file),os.path.join(path,'IMG_'+str(num)+".jpg"))
num+=1
"""
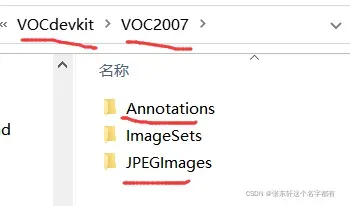
效果如下图。

这里有一个注意的地方,就是如果你数据集有很多不同地方来的,记得注意图片和xml文件一一对应。
只需将重命名的数据放入其中即可。
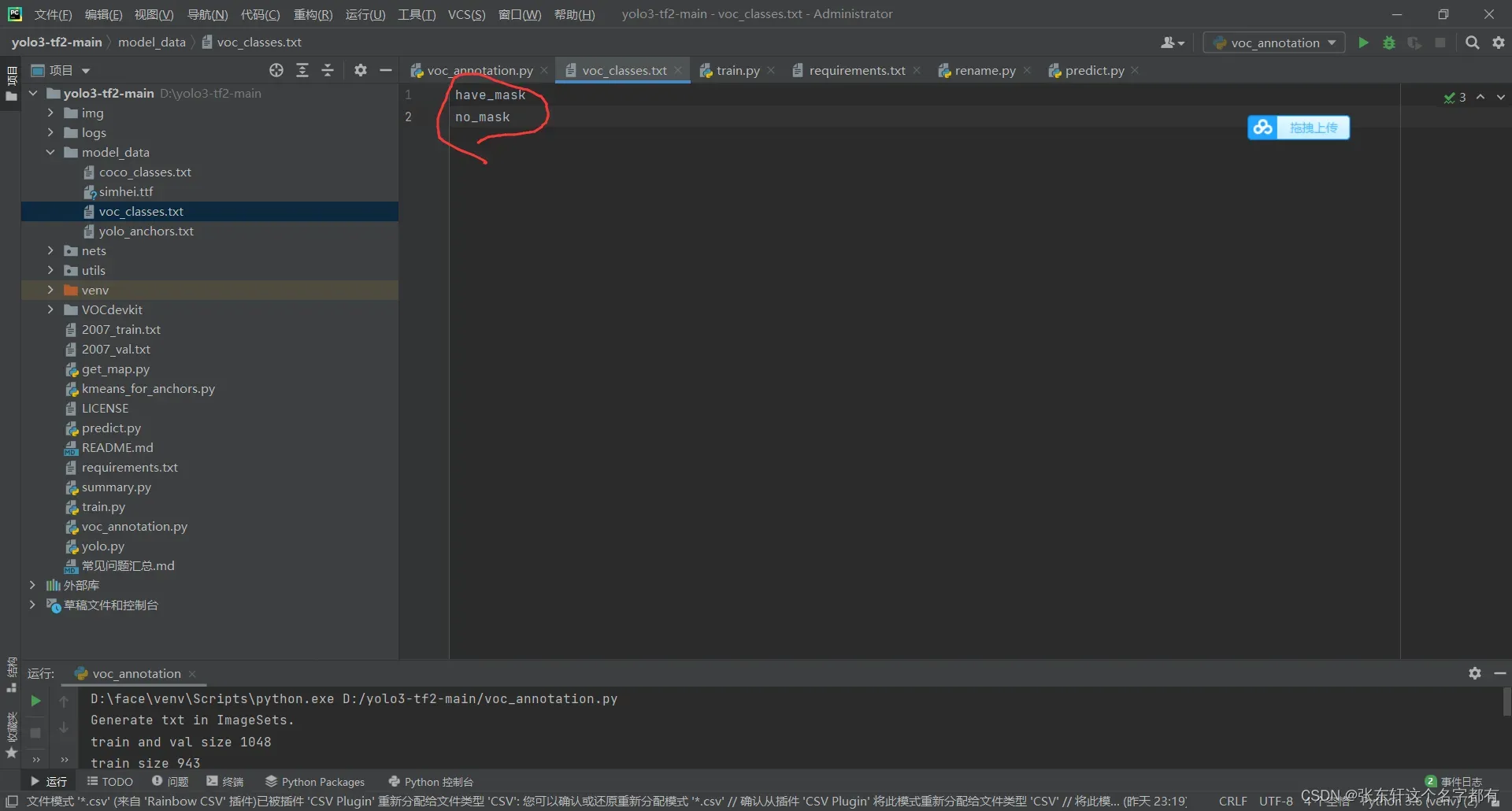
在运行大佬这个代码的时候,这个voc_classes.txt文件里面是你分类的东西。
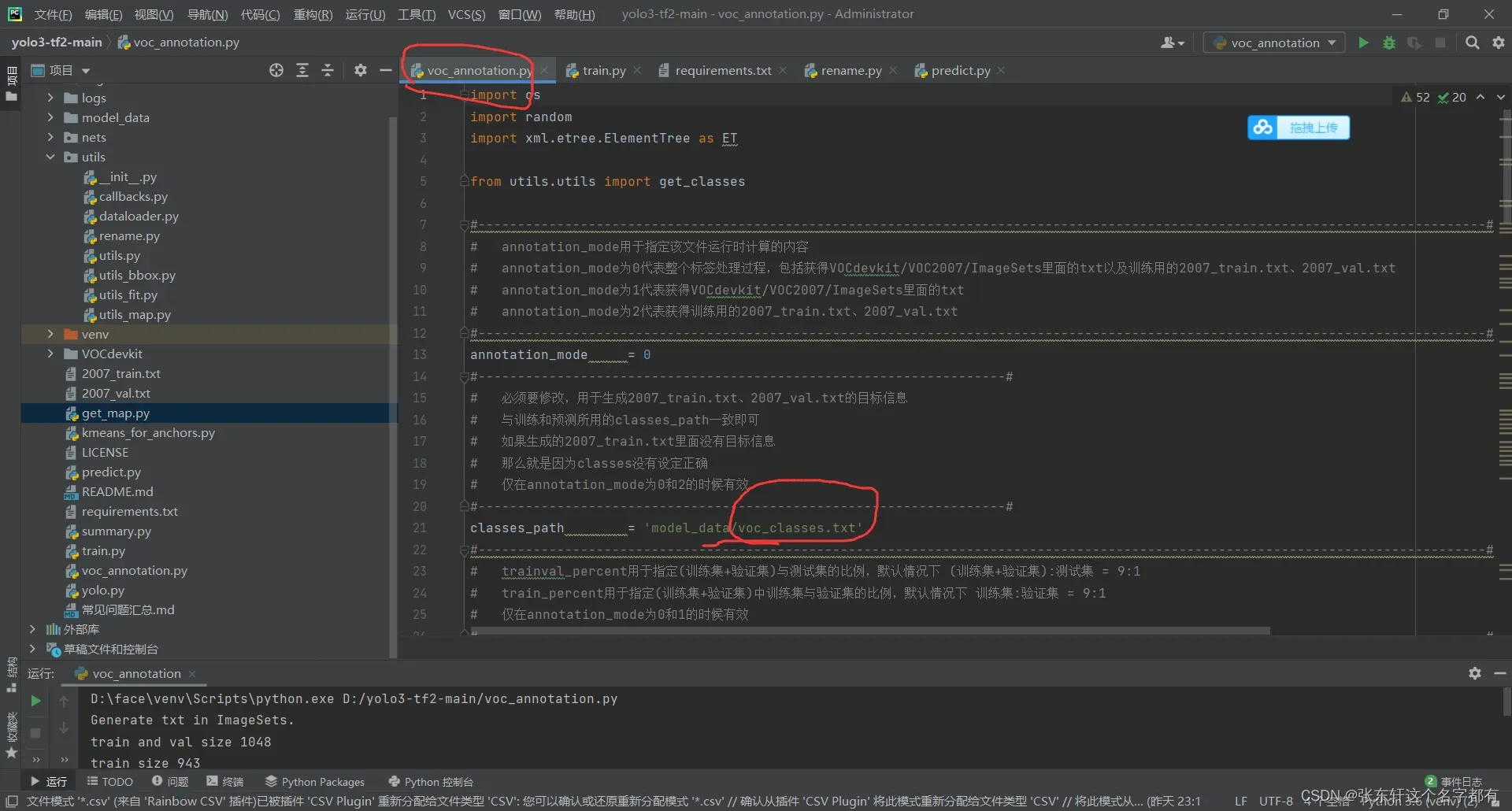
下图是你分类内容,在这里有一个注意点。就是你分类的内容必须与你进行标注的标签一致。就是你xml文件里面的名字。
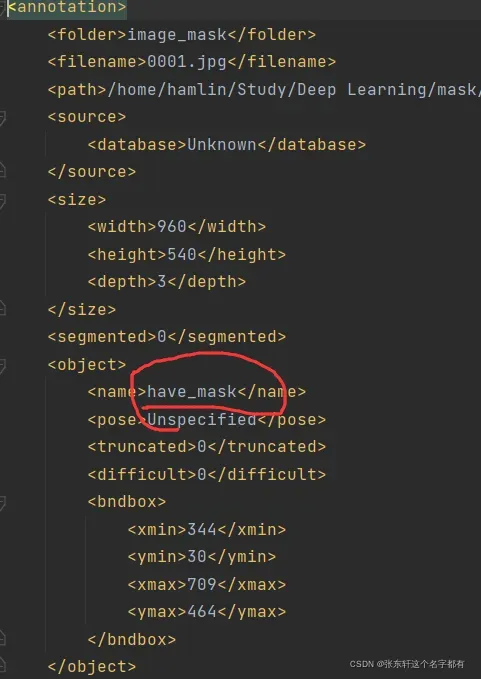
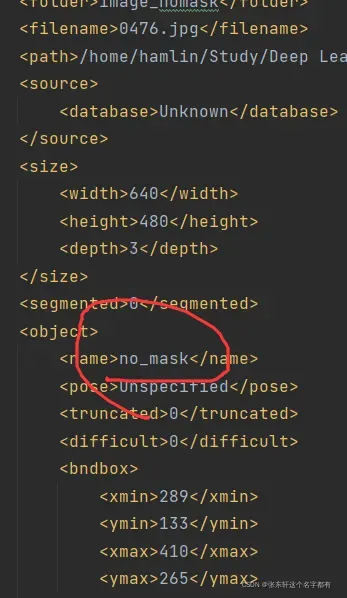
这样就成功了,还有路径和位置信息。
然后进行训练就可以了,B站大佬讲的很详细。
版权声明:本文为博主张东轩这个名字都有原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_57596462/article/details/123038489